一文学会calico及k8s网络策略入门
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文学会calico及k8s网络策略入门相关的知识,希望对你有一定的参考价值。
参考技术A calico网络策略提供了一系列的策略能力,其中包括策略的顺序/优先级,拒绝规则和其它更灵活的匹配规则。kubernetes网络策略仅应用于Pod,而Calico网络策略可以应用于多种类型的终端,比如pods, VMs和主机接口等。 而且,当使用istio service mesh的话,那么Calico network policy还支持应用的5-7层的网络策略。你可以使用Calico 网络策略附加到Kubernetes网络策略,也可单独使用。 比如,你可以 允许开发者针对他们的微服务定义kubernetes网络策略,而允许安全团队或ops团队定义它们的calico 网络策略。
Calico 网络策略支持以下功能:
请记住一点:calico network policy和calico global network policies是使用calicoctl应用的。
下面是应用的关系表:
Kubernetes网络政策规范定义了以下行为:
为了和kuberneres兼容,calico network policy遵循善存 kubernetes pods相同的行为。针对其它endpoints的类型(VMs, host interfaces),Calico network policy是默认的拒绝。
案例如下:
应用的顺序数字从小到大:
Kubernetes网络政策允许开发人员获得和他们的应用程序使用相同的简单的语言使用部署它们。开发人员可以专注于他们的应用程序不了解底层网络的概念。使开发人员能够轻松地使用网络政策确保他们的应用程序DevOps环境。
kubernetes Network Policy API 支持如下功能:
kubernetes网络策略 API提供一个方式,让用户定义网络策略去控制流量 。然后,kubernetes是没有内置的网络策略的,因此,你必须使用插件的方式,比如Calico插件。
案例1:
案例2:
kubernetes NetworkPolicy API 允许用户基于 labels 和 port 定义kubernetes pods ingress 和 egress.
我们经过以下步骤测试:
通过部署一个默认的所有Ingress流量策略,在名称空间中开启ingress 隔离。
(1) 访问nginx服务
(2)尝试访问baidu.com
(2)尝试访问baidu.com
运行下面的命令在 kube-system 名称空间上创建一个 name: kube-system 标签, 并且创建一个网络策略允许 advanced-policy-demo 名称空间中的任何pods到 kube-system DNS egress流量。
创建egress 流量策略允许在 advanced-policy-demo 名称空间的任何pods到相同名称空间中的匹配标签 run: nginx 的pods.
这包含构建fronted 和 backend service的demo,.
此时应该可以通过 http://<k8s-node-ip>:30002 进行访问了。
刷新管理UI,现在我们开启隔离,这个UI将不能够再次访问。
几秒钟后,刷新UI——它现在应该显示服务,但他们不能互相访问
现在客户端可以访问前端,而不是后端。前端和后端都无法启动连接客户端。前端仍然能够访问后端。
Calico的入门和网络优化
文章目录

Kubernetes Calico
1.简介
Calico是一个非常流行的Kubernetes网络插件和解决方案.Calico是一个开源虚拟化网络方案,用于为云原生应用实现互联及策略控制。与Flannel相比,Calico的一个显著优势是对网络策略(network policy)的支持,它允许用户动态定义ACL规则控制进出容器的数据报文,实现为Pod间的通信按需施加安全策略。事实上,Calico可以整合进大多数主流的编排系统,如Kubernetes、Apache Mesos、Docker和OpenStack等。
Calico本身是一个三层的虚拟网络方案,它将每个节点都当作路由器(router),将每个节点的容器都当作是“节点路由器”的一个终端并为其分配一个IP地址,各节点路由器通过BGP(Border Gateway Protocol)学习生成路由规则,从而将不同节点上的容器连接起来。因此,Calico方案其实是一个纯三层的解决方案,通过每个节点协议栈的三层(网络层)确保容器之间的连通性,这摆脱了flannel host-gw类型的所有节点必须位于同一二层网络的限制,从而极大地扩展了网络规模和网络边界。
Calico利用Linux内核在每一个计算节点上实现了一个高效的vRouter(虚拟路由器)进行报文转发,而每个vRouter都通过BGP负责把自身所属的节点上运行的Pod资源的IP地址信息基于节点的agent程序(Felix)直接由vRouter生成路由规则向整个Calico网络内进行传播.
Calico承载的各Pod资源直接通过vRouter经由基础网络进行互联,它非叠加、无隧道、不使用VRF表,也不依赖于NAT,因此每个工作负载都可以直接配置使用公网IP接入互联网,当然,也可以按需使用网络策略控制它的网络连通性。
Calico官网介绍: projectcaclico.org
2.重要特性
2.1 经IP路由直连
Calico中,Pod收发的IP报文由所在节点的Linux内核路由表负责转发,并通过iptables规则实现其安全功能。某Pod对象发送报文时,Calico应确保节点总是作为下一跳MAC地址返回,不管工作负载本身可能配置什么路由,而发往某Pod对象的报文,其最后一个IP跃点就是Pod所在的节点,也就是说,报文的最后一程即由节点送往目标Pod对象,如下图所示。

需为某Pod对象提供连接时,系统上的专用插件(如Kubernetes的CNI)负责将需求通知给Calico Agent。收到消息后,Calico Agent会为每个工作负载添加直接路径信息到工作负载的TAP设备(如veth)。而运行于当前节点的BGP客户端监控到此类消息后会调用路由reflector向工作于其他节点的BGP客户端进行通告。
2.2 简单、高效、易扩展
Calico未使用额外的报文封装和解封装,从而简化了网络拓扑,这也是Calico高性能、易扩展的关键因素。毕竟,小的报文减少了报文分片的可能性,而且较少的封装和解封装操作也降低了对CPU的占用。此外,较少的封装也易于实现报文分析,易于进行故障排查。
创建、移动或删除Pod对象时,相关路由信息的通告速度也是影响其扩展性的一个重要因素。Calico出色的扩展性缘于与互联网架构设计原则别无二致的方式,它们都使用了BGP作为控制平面。BGP以高效管理百万级的路由设备而闻名于世,Calico自然可以游刃有余地适配大型IDC网络规模。另外,由于Calico各工作负载使用基IP直接进行互联,因此它还支持多个跨地域的IDC之间进行协同。
3.Calico系统架构
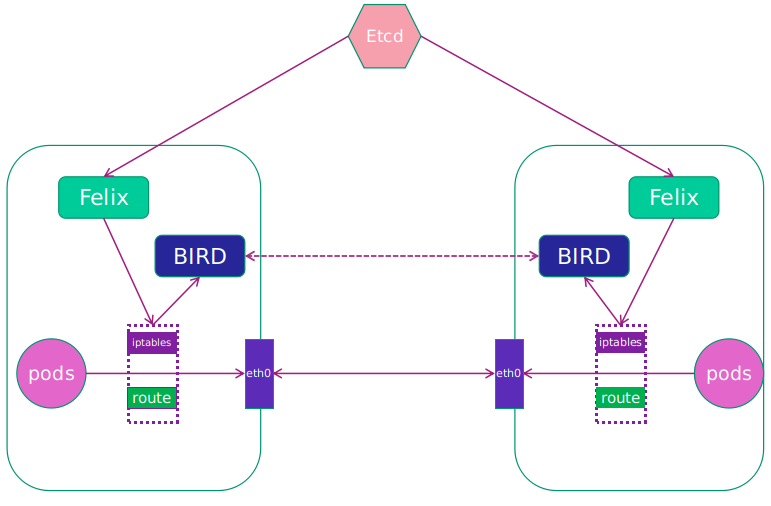
各组件介绍如下:
- Felix:Calico Agent,运行于每个节点。主要负责网络接口管理和监听、路由、ARP 管理、ACL 管理和同步、状态上报等。
- etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与kubernetes共用;
- BGP Client(BIRD):Calico 为每一台 Host 部署一个 BGP Client,使用 BIRD 实现,BIRD 是一个单独的持续发展的项目,实现了众多动态路由协议比如 BGP、OSPF、RIP 等。在 Calico 的角色是监听 Host 上由 Felix 注入的路由信息,然后通过 BGP 协议广播告诉剩余 Host 节点,从而实现网络互通。
- BGP Route Reflector:在大型网络规模中,如果仅仅使用 BGP client 形成 mesh 全网互联的方案就会导致规模限制,因为所有节点之间俩俩互联,需要 N^2 个连接,为了解决这个规模问题,可以采用 BGP 的 Router Reflector 的方法,使所有 BGP Client 仅与特定 RR 节点互联并做路由同步,从而大大减少连接数。
3.1 Felix
Felix运行于各节点的用于支持端点(VM或Container)构建的守护进程,它负责生成路由和ACL,以及其他任何由节点用到的信息,从而为各端点构建连接机制。Felix在各编排系统中主要负责以下任务。
首先是接口管理(Interface Management)功能,负责为接口生成必要的信息并送往内核,以确保内核能够正确处理各端点的流量,尤其是要确保各节点能够响应目标MAC为当前节点上各工作负载的MAC地址的ARP请求,以及为其管理的接口打开转发功能。另外,它还要监控各接口的变动以确保规则能够得到正确的应用。
其次是路由规划(Route Programming)功能,其负责为当前节点运行的各端点在内核FIB(Forwarding Information Base)中生成路由信息,以保证到达当前节点的报文可正确转发给端点。
再次是ACL规划(ACL Programming)功能,负责在Linux内核中生成ACL,用于实现仅放行端点间的合法流量,并确保流量不能绕过Calico的安全措施。
最后是状态报告(State Reporting)功能,负责提供网络健康状态的相关数据,尤其是报告由其管理的节点上的错误和问题。这些报告数据会存储于etcd,供其他组件或网络管理员使用。
3.2 编排系统插件
编排系统插件(Orchestrator Plugin)依赖于编排系统自身的实现,故此并不存在一个固定的插件以代表此组件。编排系统插件的主要功能是将Calico整合进系统中,并让管理员和用户能够使用Calico的网络功能。它主要负责完成API的转换和反馈输出。
编排系统通常有其自身的网络管理API,网络插件需要负责将对这些API的调用转为Calico的数据模型并存储于Calico的存储系统中。如果有必要,网络插件还要将Calico系统的信息反馈给编排系统,如Felix的存活状态,网络发生错误时设定相应的端点为故障等。
3.3 etcd存储系统
Calico使用etcd完成组件间的通信,并以之作为一个持久数据存储系统。根据编排系统的不同,etcd所扮演角色的重要性也因之而异,但它贯穿了整个Calico部署全程,并被分为两类主机:核心集群和代理(proxy)。在每个运行着Felix或编排系统插件的主机上都应该运行一个etcd代理以降低etcd集群和集群边缘节点的压力。此模式中,每个运行着插件的节点都会运行着etcd集群的一个成员节点。
etcd是一个分布式、强一致、具有容错功能的存储系统,这一点有助于将Calico网络实现为一个状态确切的系统:要么正常,要么发生故障。另外,分布式存储易于通过扩展应对访问压力的提升,而避免成为系统瓶颈。另外,etcd也是Calico各组件的通信总线,可用于确保让非etcd组件在键空间(keyspace)中监控某些特定的键,以确保它们能够看到所做的任何更改,从而使它们能够及时地响应这些更改。
3.4 BGP客户端(BIRD)
Calico要求在每个运行着Felix的节点上同时还要运行一个BGP客户端,负责将Felix生成的路由信息载入内核并通告到整个IDC。在Calico语境中,此组件是通用的BIRD,因此任何BGP客户端(如GoBGP等)都可以从内核中提取路由并对其分发对于它们来说都适合的角色。
BGP客户端的核心功能就是路由分发,在Felix插入路由信息至内核FIB中时,BGP客户端会捕获这些信息并将其分发至其他节点,从而确保了流量的高效路由。
3.5 BGP路由反射器(BRID)
在大规模的部署场景中,简易版的BGP客户端易于成为性能瓶颈,因为它要求每个BGP客户端都必须连接至其同一网络中的其他所有BGP客户端以传递路由信息,一个有着N个节点的部署环境中,其存在网络连接的数量为N的二次方,随着N值的逐渐增大,其连接复杂度会急剧上升。因而在较大规模的部署场景中,Calico应该选择部署一个BGP路由反射器,它是由BGP客户端连接的中心点,BGP的点到点通信也就因此转化为与中心点的单路通信模型,如图11-18所示。出于冗余之需,生产实践中应该部署多个BGP路由反射器。对于Calico来说,BGP客户端程序除了作为客户端使用之外,还可以配置成路由反射器。
4.Calico网络工作模式
4.1 BGP模式
边界网关协议(Border Gateway Protocol, BGP)是互联网上一个核心的去中心化自治路由协议,它通过维护IP路由表或“前缀”表来实现自治系统(AS)之间的可达性,属于矢量路由协议。不过,考虑到并非所有的网络都能支持BGP,以及Calico控制平面的设计要求物理网络必须是二层网络,以确保vRouter间均直接可达,路由不能够将物理设备当作下一跳等原因,为了支持三层网络
4.2 IPIP模式
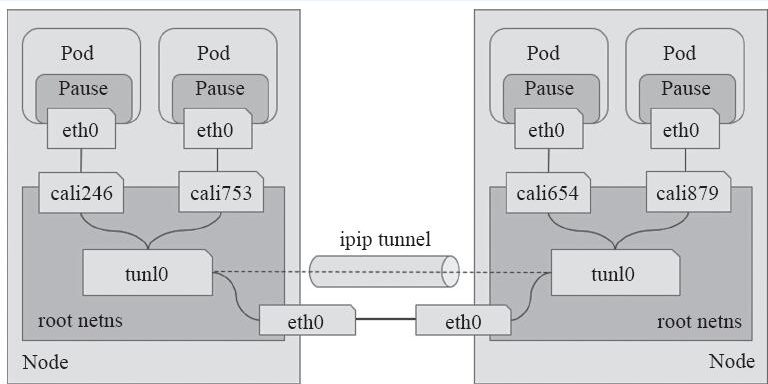
BGP模式要求Kubernetes的所有物理节点网络必须是二层网络.为了支持三层网络,Calico还推出了IP-in-IP叠加的模型,它也使用Overlay的方式来传输数据。IPIP的包头非常小,而且也是内置在内核中,因此理论上它的速度要比VxLAN快一点,但安全性更差。Calico 3.x的默认配置使用的是IPIP类型的传输方案而非BGP。
工作于IPIP模式的Calico会在每个节点上创建一个tunl0接口(TUN类型虚拟设备)用于封装三层隧道报文。节点上创建的每一个Pod资源,都会由Calico自动创建一对虚拟以太网接口(TAP类型的虚拟设备),其中一个附加于Pod的网络名称空间,另一个(名称以cali为前缀后跟随机字串)留置在节点的根网络名称空间,并经由tunl0封装或解封三层隧道报文。Calico IPIP模式如下图所示。
5. Calico 网络通信方式
5.1 Calico网络环境介绍
当前k8s集群使用的是v1.17.3的版本.有2个node节点.IP地址分别如下
[root@k8s-master ~]$kubectl get nodes -o wide | awk 'print $1,$6' | sed 1,2d
k8s-node1 172.16.20.252
k8s-node2 172.16.20.253
每个node节点都启动一个tunl0 的虚拟路由器.和许多calixxx 开头的虚拟网卡设备
[root@k8s-node1 ~]# ifconfig
cali42b086c8543: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1440
inet6 fe80::ecee:eeff:feee:eeee prefixlen 64 scopeid 0x20<link>
ether ee:ee:ee:ee:ee:ee txqueuelen 0 (Ethernet)
RX packets 13335563 bytes 928478769 (885.4 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 13335563 bytes 928478769 (885.4 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
tunl0: flags=193<UP,RUNNING,NOARP> mtu 1440
inet 10.100.36.64 netmask 255.255.255.255
tunnel txqueuelen 1000 (IPIP Tunnel) #默认是IPIP模式
RX packets 3978810 bytes 345003038 (329.0 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3674392 bytes 613045453 (584.6 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions
Calico的CNI插件会为每个容器设置一个veth pair设备,然后把另一端接入到宿主机网络空间,由于没有网桥,CNI插件还需要在宿主机上为每个容器的veth pair设备配置一条路由规则,用于接收传入的IP包.
了这样的veth pair设备以后,容器发出的IP包就会通过veth pair设备到达宿主机,这些路由规则都是Felix维护配置的,而路由信息则是calico bird组件基于BGP分发而来。Calico实际上是将集群里所有的节点都当做边界路由器来处理,他们一起组成了一个全互联的网络,彼此之间通过BGP交换路由,这些节点我们叫做BGP Peer。
为了下面试验Calico的网络工作.当前集群使用daemonSet控制器运行了2个busybox:1.28.4 镜像的容器
[root@k8s-master ~]$kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox-g5rkr 1/1 Running 0 130m 10.100.36.103 k8s-node1 <none> <none>
busybox-zdwsc 1/1 Running 0 130m 10.100.169.176 k8s-node2 <none> <none>
在k8s-node1节点上可以看到两条相关路由
10.100.36.103 0.0.0.0 255.255.255.255 UH 0 0 0 cali96df9f67b52
10.100.169.128 172.16.20.253 255.255.255.192 UG 0 0 0 tunl0
第一条路由是访问该节点下的Busybox容器.它的下一跳是calixxxx开头的虚拟网卡.这种通信方式和docker的Bridge网桥模式其实并没有任何区别.
第二条路由的目的网络是10.100.169.128,子网掩码是255.255.255.192.它代表了IP范围为10.100.169.128-190的地址.而运行于另外一个节点下的busybox-zdwscPod的IP地址就位于这个范围之内.所以这条路由可以使node1节点借助于tunl0可以直接和node2节点下的pod进行通信.
在
k8s-node2服务器可以看到类似的这2条路由
5.2 Calico网络模型解密
登录k8s-node1节点下的Pod容器内部.查看Pod容器的IP地址,以及路由条目.
[root@k8s-master ~]$kubectl exec -it busybox-g5rkr -- sh
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 4A:7C:E7:FA:4B:CC
inet addr:10.100.36.103 Bcast:0.0.0.0 Mask:255.255.255.255
UP BROADCAST RUNNING MULTICAST MTU:1440 Metric:1
RX packets:14 errors:0 dropped:0 overruns:0 frame:0
TX packets:6 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1322 (1.2 KiB) TX bytes:426 (426.0 B)
/ # route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 169.254.1.1 0.0.0.0 UG 0 0 0 eth0
169.254.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
通过k8s-node节点上的下面的路由条目,我们可以知道节点主机和Pod容器的IP地址10.100.36.103通信使用的是cali96df9f67b52这个虚拟网卡
10.100.36.103 0.0.0.0 255.255.255.255 UH 0 0 0 cali96df9f67b52
路由条目显示169.254.1.1 是Pod容器的默认网关.但是有网络常识的我们都知道这个IP是个保留的IP地址,不存在于互联网或者任何设备中.那Pod如何和网关通信呢?
回顾一下网络课程,我们知道任何网络设备和网关设备都是在一个二层局域网中,而二层数据链路层使用MAC地址进行通信,不需要双方的IP地址信息.通信方(这里是Pod容器)会通过ARP协议获取网关的MAC地址,然后通过MAC地址将数据包发送给网关…也就是说网络设备不关心对方的IP是否可达,只要能找到对应的MAC地址就可以.
通过ip neigh命令查看Pod容器的ARP缓存
/ # ip neigh
169.254.1.1 dev eth0 lladdr ee:ee:ee:ee:ee:ee ref 1 used 0/0/0 probes 4 REACHABLE
如果是新的Pod容器可能无法获得ARP缓存,此时只需要随便发生一个网络交互(例如ping百度)即可
这个MAC地址(ee:ee:ee:ee:ee:ee)也是Calico的虚拟cali96df9f67b52网卡的虚拟MAC地址.下放是宿主机网卡信息:
cali96df9f67b52: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1440
inet6 fe80::ecee:eeff:feee:eeee prefixlen 64 scopeid 0x20<link>
ether ee:ee:ee:ee:ee:ee txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
所有虚拟网卡默认开启了ARP代理协议
[root@k8s-node1 ~]# cat /proc/sys/net/ipv4/conf/cali96df9f67b52/proxy_arp
1
所以Calico 通过一个巧妙的方法将 Pod 的所有流量引导到一个特殊的网关 169.254.1.1,从而引流到主机的 calixxx 网络设备上,最终将二三层流量全部转换成三层流量来转发。
6.Calico IPIP网络模式
登录busybox-g5rkrPod容器内部.ping位于另外一台k8s-node2 下的busybox-zdwscPod容器
[root@k8s-master ~]$kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox-g5rkr 1/1 Running 0 130m 10.100.36.103 k8s-node1 <none> <none>
busybox-zdwsc 1/1 Running 0 130m 10.100.169.176 k8s-node2 <none> <none>
两个Pod之前可以直接访问对方的IP地址.而不需要像Docker容器那样暴露端口,然后利用对方宿主机的IP进行通信
[root@k8s-master ~]$kubectl exec -it busybox-g5rkr -- sh
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 4A:7C:E7:FA:4B:CC
inet addr:10.100.36.103 Bcast:0.0.0.0 Mask:255.255.255.255
UP BROADCAST RUNNING MULTICAST MTU:1440 Metric:1
RX packets:14 errors:0 dropped:0 overruns:0 frame:0
TX packets:6 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1322 (1.2 KiB) TX bytes:426 (426.0 B)
/ # ping 10.100.169.176
PING 10.100.169.176 (10.100.169.176): 56 data bytes
64 bytes from 10.100.169.176: seq=0 ttl=62 time=0.622 ms
64 bytes from 10.100.169.176: seq=1 ttl=62 time=0.552 ms
64 bytes from 10.100.169.176: seq=2 ttl=62 time=0.597 ms
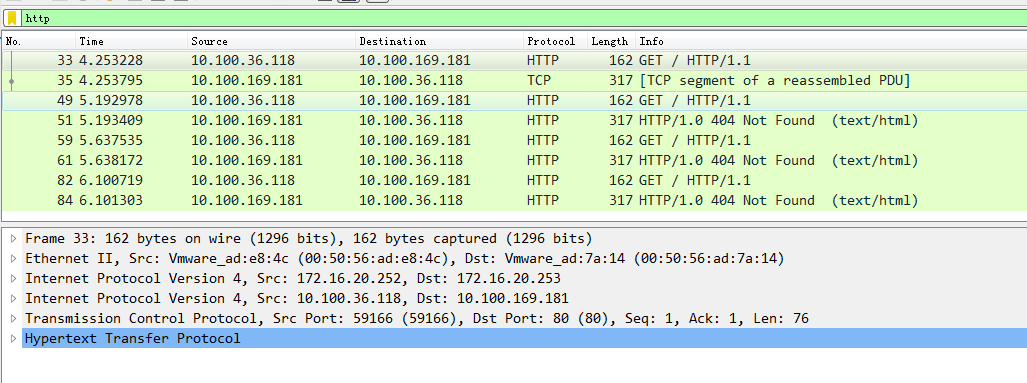
在k8s-node2 节点抓包
[root@k8s-node2 ~]# tcpdump -i ens192 -nn -w imcp.cap
用wireshark软件打开抓包文件.发现如下ICMP的报文
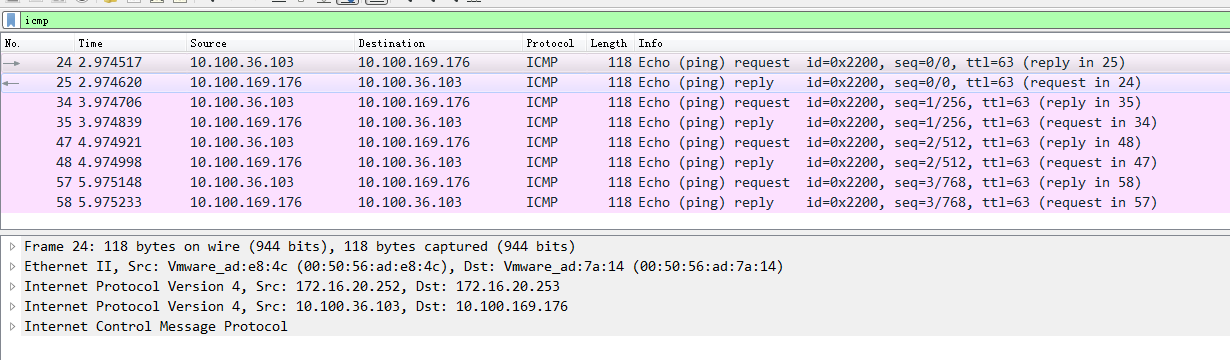
可以看到每个数据报文共有两个IP网络层,内层是Pod容器之间的IP网络报文,外层是宿主机节点的网络报文(2个node节点).之所以要这样做是因为tunl0是一个隧道端点设备,在数据到达时要加上一层封装,便于发送到对端隧道设备中。
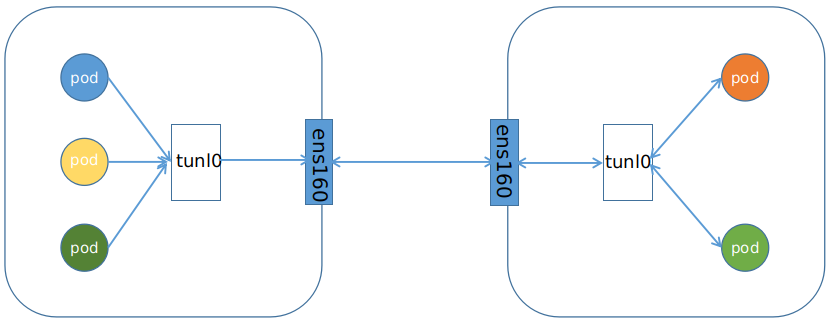
Pod间的通信经由IPIP的三层隧道转发,相比较VxLAN的二层隧道来说,IPIP隧道的开销较小,但其安全性也更差一些。
IPIP的通信方式如下:
6.1 Pod和Service网络通信
经过测试.在k8s集群内部物理节点和pod容器内部访问Service的http服务.仍然使用的是Ipip通信模式.
下面是在容器内部通过Service访问busybox pod容器的http服务的抓包报文
[root@k8s-master ~]$kubectl exec -it busybox-6hnvc -- sh
/ # curl http://10.96.166.242
sh: curl: not found
/ # wget -O - -q http://10.96.166.242
wget: server returned error: HTTP/1.0 404 Not Found
/ # wget -O - -q http://10.96.166.242
wget: server returned error: HTTP/1.0 404 Not Found
7. BGP网络模式
Calico网络部署时,默认安装就是IPIP网络.通过修改calico.yaml部署文件中的CALICO_IPV4POOL_IPIP 值修改成off 就切换到BGP网络模式
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Always" #改成Off
重新部署calico
[root@k8s-master ~]$kubectl apply -f calico-3.10.2.yaml
然后关闭ipipMode.把ipipMode从Always修改成为Never
[root@k8s-master1 target]# kubectl edit ippool
ipipMode: Never
7.1 和Ipip的区别
BGP网络相比较IPIP网络,最大的不同之处就是没有了隧道设备 tunl0。 前面介绍过IPIP网络pod之间的流量发送tunl0,然后tunl0发送对端设备。BGP网络中,pod之间的流量直接从网卡发送目的地,减少了tunl0这个环节。
7.2 通信方式
删除原来的pod.重新启动新的
[root@k8s-master ~]$kubectl create -f deployment-kubia-v1.yaml
daemonset.apps/busybox created
service/busybox created
[root@k8s-master ~]$kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox-bd566 1/1 Running 0 16s 10.100.36.97 k8s-node1 <none> <none>
busybox-fntv9 1/1 Running 0 16s 10.100.169.129 k8s-node2 <none> <none>
再次查看路由表.发现节点和pod容器通信直接通过宿主机的物理网卡,而不是tunl0设备了
[root@k8s-master ~]$route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.16.20.254 0.0.0.0 UG 100 0 0 ens192
10.100.36.64 172.16.20.252 255.255.255.192 UG 0 0 0 ens192
10.100.169.128 172.16.20.253 255.255.255.192 UG 0 0 0 ens192
此时,再次2个Pod容器互ping抓包分析.发现两个Pod像物理机一样直接通信,而不需要进行任何数据包封装和解封装.并且数据报文的MAC地址也是node1和node2物理网卡的MAC地址
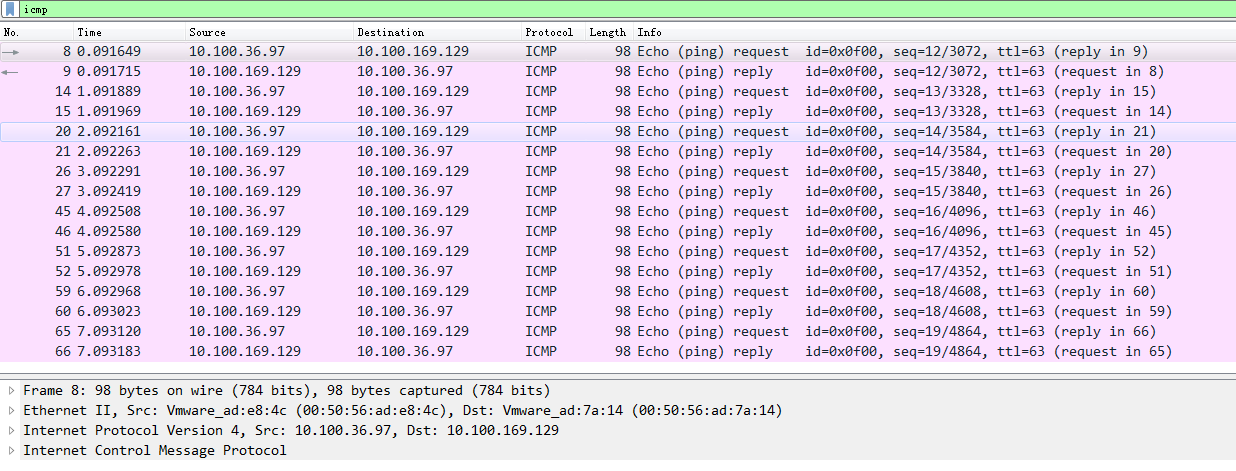
BGP的网络连接方式:

8. BGP和ipip网络模式对比
-
IPIP:
特点: tunl0封装数据.形成隧道.所有Pod和pod.pod和节点之间进行三层网络传输
优点: 适用所有网络类型.能够解决跨网段的路由问题.
-
BGP:
特点: 适用BGP路由导向流量
优点: Pod之间直接通信.省去了隧道,封装,解封装等任何中间环节,传输效率非常高.
缺点: 需要确保所有物理节点在同一个二层网络,否则Pod无法跨节点网段通信
9. Calico网络优化
9.1 MTU
Calico 的IPIP网络模型下tunl0接口的MTU默认为1440,这种设置主要是为适配Google的GCE环境,在非GCE的物理环境中,其最佳值为1480。因此,对于非GCE环境的部署,建议将配置清单calico.yaml下载至本地修改后,再将其应用到集群中。要修改的内容是DaemonSet资源calico-node的Pod模板,将容器calico-node的环境变量“FELIX_INPUTMTU”的值修改为1480即可
因为IPIP多了一层IP报文封装,而IP报文头部一般是20个字节.所以MUT的值应该是最大1500-20.
9.2 Calico-typha
对于50个节点以上规模的集群来说,所有Calico节点均基于Kubernetes API存取数据会为API Server带来不小的通信压力,这就应该使用calico-typha进程将所有Calico的通信集中起来与API Server进行统一交互。calico-typha以Pod资源的形式托管运行于Kubernetes系统之上,启用的方法为下载前面步骤中用到的Calico的部署清单文件至本地,修改其calico-typha的Pod资源副本数量为所期望的值并重新应用配置清单即可:
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: calico-typha
...
spec:
...
replicas: <number of replicas>
每个calico-typha Pod资源可承载100到200个Calico节点的连接请求,最多不要超过200个。另外,整个集群中的calico-typha的Pod资源总数尽量不要超过20个。
9.3 BGP路由模型
默认情况下,Calico的BGP网络工作于点对点的网格(node-to-node mesh)模型,它仅适用于较小规模的集群环境。中级集群环境应该使用全局对等BGP模型(Global BGP peers),以在同一二层网络中使用一个或一组BGP反射器构建BGP网络环境。而大型集群环境需要使用每节点对等BGP模型(Per-node BGP peers),即分布式BGP反射器模型,一个典型的用法是将每个节点都配置为自带BGP反射器接入机架顶部交换机上的路由反射器。
9.4 使用BGP而非IPIP
事实上,仅在那些不支持用户自定义BGP配置的网络中才需要使用IPIP的隧道通信类型。如果有一个自主可控的网络环境且部署规模较大时,可以考虑启用BGP的通信类型降低网络开销以提升传输性能,并且应该部署BGP反射器来提高路由学习效率。
参考资料
Calico官网: www.projectcalico.org
k8s网络之Calico网络: https://www.cnblogs.com/goldsunshine/p/10701242.html#mxAMjXzT
kubernetes容器网络: https://tech.ipalfish.com/blog/2020/03/06/kubernetes_container_network/ (伴鱼团队)
以上是关于一文学会calico及k8s网络策略入门的主要内容,如果未能解决你的问题,请参考以下文章
Kubernetes_CNI_Calico_04_Calico的网络策略NetworkPolicy