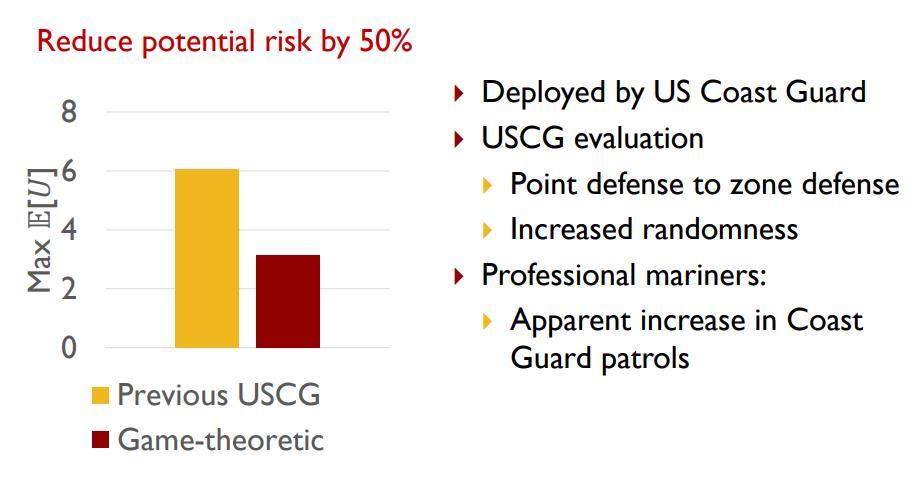
导语:去年 9 月,「外卖骑手,困在系统里」一文,使 AI 算法成为被大多数人诟病的反人性工具。但事实上,如今有许多 AI 研究可以用于解决社会问题。AI 向善还是向恶,本质上是取决于模型设计者的价值观。
作者 | 陈彩娴许多人对象牙被残忍盗猎的第一印象,也许是来自 2018 年由腾讯打造的国内首档明星纪录片《奇遇人生》。在节目上映的第一期中,知名影星小 S 与阿雅到非洲赞比亚探望一家大象孤儿院。在这家孤儿院中的所有大象都有一个共同点:即它们的母亲都被想要贩卖象牙的盗猎者残忍杀害。其中,一只名为 Chamilando 的大象因为目睹母亲被杀害,每天晚上睡觉都会尖叫,做噩梦。“很难想象,有些人夺取象牙,只是为了想要一点首饰。”而在短短几天的拍摄中,节目便在一个国家公园边界亲眼目睹了大象被猎杀的情景:由于有三分之一的象牙长在头部,盗猎者将大象的鼻子从头部连根割掉,取走完整的象牙,随之将象鼻抛在一边,让无辜的大象尸首无存,暴露在炎炎烈日下,由秃鹫任意蚕食。根据大象孤儿院管理员 Rachael 的介绍,在非洲,每天大约有100只大象因为象牙盗猎而丧命。除了大象,对老虎、雪豹、羚羊、犀牛、穿山甲等等野生动物的捕杀也仍在继续。比如,根据 WWF 的统计,100年前,世界上大约有 60,000 只老虎,而今天只剩下 3,200 只。针对严重的盗猎现象,我们可以做什么?想必关注该现象的读者有时会感到无能为力。而更为大众鲜闻的是:人工智能技术居然可以用于辅助巡逻,对付凶残的盗猎者,从而保护野生动物。来自卡内基梅隆大学计算机科学系的助理教授方飞是一名坚定的“AI向善”践行者。自 2015 年起,她便结合博弈论与机器学习开发了 PAWS (Protection Assistant for Wildlife Security,“野生动物安全的保护助手”) 系统,帮助动物保护区制定随机巡逻路线,提高搜捕盗猎痕迹销量,从而大幅降低了盗猎比率。除了反盗猎,方飞在将博弈论与机器学习相结合的研究过程中,还将基础模型进行优化,应用于保护渡轮线路、保护树林、减少食品浪费、降低高利贷危害、帮助流浪少年等等。近年,她还基于“博弈论+机器学习”进行多智能体互动研究,用于优化共享乘车平台的出行效率。方飞始终坚信:“AI 是可以用于解决我们当前所面临的许多社会问题的。”1
南加州大学读博:初入博弈论
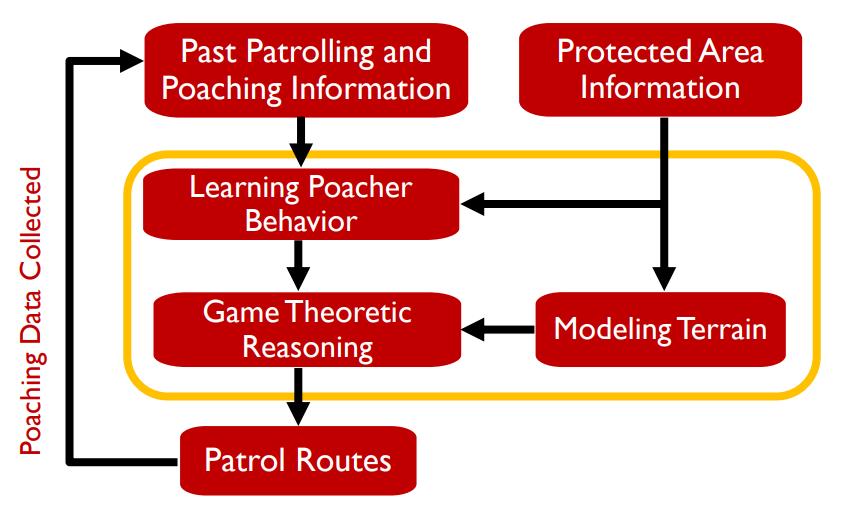
在清华就读本科期间,方飞开始接触 AI 研究,但研究方向并非博弈论。方飞在上海周边长大,从初一开始学习 Pascal 语言,并对计算机产生了浓厚的兴趣。2007年,方飞考入清华大学电子工程系攻读本科。在清华学习期间,她很快认识到,自己更喜欢软件应用,而不是硬件研究,于是开始从事计算机视觉相关的研究工作。在申请读博时,她也投递了许多计算机视觉方向的博士项目。一次偶然的机会,她通过清华电子系的学姐杨蓉和学长王言治(现任东北大学教授)了解到南加州大学 Milind Tambe 教授团队所进行的安全博弈研究工作。此前,方飞一直以为博弈论是偏理论的,距离她“所学即所用”的期望较远,而 Milind Tambe 团队的工作直接被应用于保护洛杉矶国际机场、防范飞机上的暴力行为等,令她看到了博弈论的应用潜力与影响力,觉得很有趣,于是便主动联系了 Milind Tambe,毛遂自荐,并顺利拿到读博的 offer。2011年,方飞赴南加州大学(USC)攻读博士,师从 Milind Tambe。当时,Milind Tamber 在南加州大学工程系担任 Helen N. 教授 与 Emmett H. Jones 教授,社会人工智能中心主任,是安全博弈领域的权威专家(现在哈佛大学担任教授)。自此,她开始应用博弈论来解决当下社会所面临的三大挑战:安全性、可持续性与流动性。2012年,方飞在 AAAI 上发表了第一篇文章,将博弈论用于防止森林过度砍伐。2013年,方飞发表的工作被美国海关应用于保护纽约市的斯塔滕岛渡轮线路(该渡轮每天搭乘超过6万名乘客)。2014年,方飞开始在博弈论中引入机器学习,开发了 PAWS 系统,用于帮助野生动物保护区制定随机巡逻路线,寻找盗猎陷阱,对付盗猎分子。目前,PAWS 系统已在非洲、东南亚多个国家与中国等应用。读博期间,方飞发表了 12 篇论文,将博弈论与机器学习广泛应用于解决社会问题,获得了 IJCAI 2015 杰出论文奖,IAAI 2016 创新应用奖(PAWS),南加州大学最佳博士论文奖。图注:PAWS 的大致工作流程从USC毕业后,2016年6月,方飞到哈佛大学计算与社会研究中心(CRCS)担任博士后研究员,又开始从事多智能体的研究应用(如共享汽车平台派单优化)。在践行“AI向善”的过程中,方飞感受到:当下的许多社会挑战可以应用 AI 来解决,比如贫穷、食品安全、流浪者群体等。比如,在发展中国家,农民想要销售农作物,但难以接触到大型的高度自动运转的贸易平台,于是他们一般是在当地市场销售农产品。有时候,他们的定价特别低,因为整个村庄都在销售同样的产品。针对这个问题,加拿大的研究人员(由Kevin Leyton-Brown教授领导)帮助开发了一个基于文本(text-based)的贸易平台,你可以给平台发消息,告知平台你想以怎样的价格销售哪一种农产品,平台会自动匹配买家与卖家。在帮助流浪人群方面,Milind Tambe 所领导的USC研究小组通过设计算法来改进社会帮助流浪者的的效率,提高年轻的流浪者群体防范 HIV 的意识。据方飞介绍,博导 Milind Tambe 是令她非常敬佩的一位老师。从他身上,方飞认识到,AI 研究(如博弈论)真的能够用于解决社会问题,“AI 向善”是可行的:“首先,他是真的关心实际问题。他会非常积极地与不同政府组织和非政府组织的人进行交流,向他们介绍我们团队的研究,AI 研究可能以怎样的方式帮助他们,或者询问他们在工作当中遇到哪些困难需要解决,看看有哪些方面可以合作。他的积极态度深深地影响了我。另一方面,他经常跟我们说,安全博弈的研究要从实际问题中出发。他非常鼓励我们从事有实际应用场景的研究。”除了学术研究,导师 Milind Tambe 也非常关心学生的就业发展。比如,他会经常催促学生去主动参加和组织各种各样的研讨会与学术论坛。当时,方飞并不能理解导师的用意:“我觉得我只要做好我的研究就行了,为什么要去揽这些乱七八糟的事。”“但是后来,我慢慢意识到这是非常重要的。通过这样的方式,你可以接触到更多圈内人,你是为你的整个研究领域提供服务,帮助该领域的成长,而且你也从中锻炼了自己各方面的能力。” 2
CMU:博弈论+机器学习
2017年8月,方飞入职卡内基梅隆大学计算机科学系软件研究所(Institute for Software Research)担任助理教授。据统计,当前卡内基梅隆大学的计算机科学系中共有 29 位华人教职员工(含兼职),ISR 占 2 名(ISR 共有 44 名核心教职人员),方飞便是其中之一。在担任教职的这几年,方飞团队的工作揽获多项 AI 顶会大奖,包括 AAMAS 2019最佳应用系统演示奖、IJCAI-ECAI-18 杰出论文奖。方飞的主要研究方向是将博弈论与机器学习相结合。最早,人们对博弈论的讨论仅仅局限于在玩游戏时如何制定最佳策略。玩游戏时不能按固定的套路出牌,而是要将招数尽可能随机化。比如,如果你正在玩“剪刀、石头、布”的游戏,最好的玩法是随机出剪刀、石头、布。如今,博弈论(Game Theory)研究开始针对实际问题的策略行为进行建模(如政策经济学),如何计算或规定人们或智能体最终会使用的策略。虽然博弈论的起源很简单,但目前已发展为在不同领域将策略行为建模为一个博弈的研究方向。“只要一个情景包含多个利己主义的智能体,且这些智能体彼此之间有策略的交互,那么我们就可以使用博弈论对这个场景进行建模。”方飞介绍道。入职 CMU 后,方飞继续将“博弈论+机器学习”的研究应用于解决社会问题。她所参与的论文“Computational Sustainability: Computing for a Better World and a Sustainable Future”曾登上 CACM 2019年9月的封面;她所参与撰写的书籍 《Artificial Intelligence and Conservation》(《AI与野生动物保护》)被列入“AI向善”丛书系列。
许多野生动物保护区都面临保护大象、老虎、犀牛等珍稀动物的任务,但资源有限,只能雇佣少数执法人员在保护区进行巡逻。如果有偷猎者,这些执法人员的生命安全很可能会受到伤害。“你可以想象,如果执法人员(智能体)按照固定的方法巡逻,比如周一早上的巡逻路线固定,那就很容易被偷猎者(攻击者)发现。因此,我们必须帮助他们将巡逻方法随机化。”在 PAWS 的项目中,方飞与团队对执法人员与偷猎者的行为进行建模,应用博弈论帮助制定执法人员的最优巡逻路线。但这些模型并不能有效帮助巡逻人员执行任务。方飞解释,博弈论模型通常是假设人是完全理性的,并会选择能够取得最高效用的行为。但我们都知道,人不可能是完全理性的。因此,方飞与团队需要从他们所收集的数据中对人类“玩家”进行实际学习。这时,机器学习就派上了用场。方飞的团队使用他们的合作者从多个野生动物保护机构(如世界野生动物联合会和野生动物保护协会)收集的巡逻与偷猎活动数据来建立有助于预测未来情况的行为模型。然后,他们在这些数据中应用博弈论创建最佳巡逻策略。随着巡逻人员遵循随机路线、并向研究人员提供有关偷猎证据的反馈,越来越多数据进入模型,该模型将开始学习偷猎者的行为,并开发出最佳的随机巡逻路线来阻止他们偷猎。方飞希望,通过结合机器学习技术与博弈论,可以帮助改变野生动物的保护现状。在偷猎路径上阻止偷猎者,只是方飞使用博弈论与机器学习来促进社会良好发展的应用之一。她的研究还用于帮助制定美国海关守卫的随机巡逻路线,保护斯塔滕岛渡轮免受攻击,从卫星图像中检测非法挖矿地点,保护渔业等。图注:2019年12月,方飞在清华大学交叉信息院作学术报告除了课题研究,方飞还在 CMU 开设了一门面向本科生与研究生的课程,名为《Artificial Intelligence Methods for Social Good》(为社会造福的 AI 方法),向课上的学生传授机器学习、博弈论和机制设计、顺序决策、计划与优化等基础知识。此外,该门课还着重向学生介绍了医疗体系、社会福利、安全和隐私,以及环境可持续性等领域所面临的挑战,以及 AI 技术可以如何应用于解决这些挑战。方飞提到:“有很多人虽然掌握了一定的 AI 技术,但没有用这些技术来应对当今世界面临的真正挑战。我希望通过本课程,学生可以掌握能够广泛应用于为社会造福的 AI 方法。”因其在“AI 向善”上的深入研究,方飞入选 2020年 IEEE System 所评选出的“AI 十大潜力人物”。此外,在 Iridescent 于 2019 年 所评选出“AI领域最值得关注的5位女性”(“5 Women You Should Know Working in AI”),方飞是唯一入选的华人学者。其余入选者均是 AI 领域的知名研究员,包括 CMU机器学习系主任兼计算机科学系教授 Manuela Veloso,密歇根大学计算机科学系教授Rada Mihalcea,CMU语言技术研究所教授Carolyn Rosé 以及 斯坦福大学计算机科学与电子工程系助理教授Chelsea Finn。
3
研究探讨 Q& A
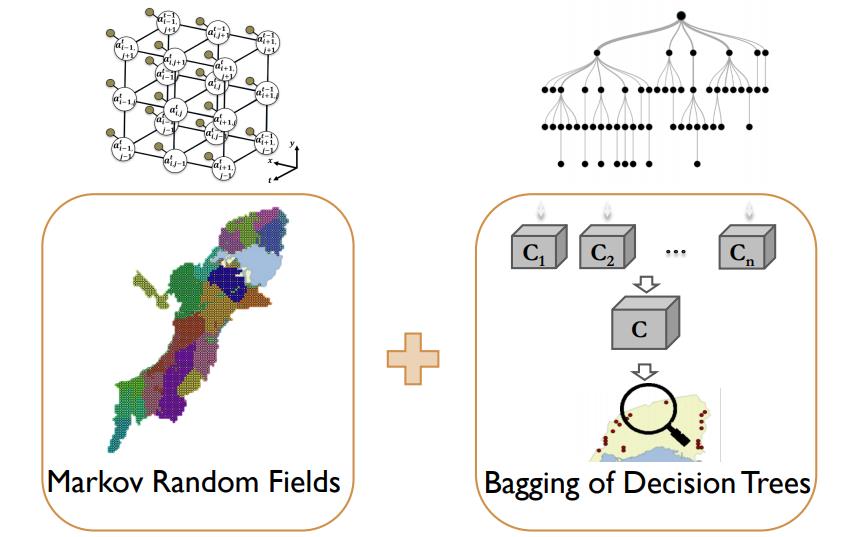
1、您是如何想到结合博弈论与机器学习来解决社会问题?读博期间,我们组在做安全博弈的研究,研究如何保护机场、保护码头等建筑物。在与动物保护组织、世界银行等机构的工作人员与其他研究学者介绍工作时,他们谈到,我们所做的工作本质上是设计一种随机化的巡逻或安保方案,以此来提高对目标物的保护程度。那么,这些研究也可以用于设计巡逻路线,保护动物,防止盗猎;或设计护林人员的巡逻路线,防止过度砍伐。因此,我们便进一步了解这方面的工作,与一些动物保护组织取得联系,联系后,发现他们的确是有派出巡逻人员在保护区里面进行巡逻,以此来阻止盗猎行动。但是,跟很多安全问题一样,他们没有那么多巡逻人员,人手很紧张,他们需要更好地规划人手的布局和巡逻方案。跟以前研究的那些安全问题不同的是,在反盗猎的研究课题上,动物保护区的数据记录和保存做得比较好,有的保护区能提供十几年的巡逻观察数据,如每一天所采取的巡逻路线,巡逻时在哪个地点发现了什么。图注:从现实数据对偷猎行为进行建模在研究数据的过程中,我们意识到,单纯用博弈论的模型去研究是不现实的,因为基础的博弈论模型都有一个假设,就是:人是理性的,会采取能够将他们的预期收益最大化的行动。而在反盗猎的问题中,盗猎者并不会进行精确的计算,如在某个特定地点布下陷阱、设下猎套,预期收益最大,便在某个地点设陷阱。因此,我们需要先通过数据学习盗猎者的行为模型,基于这个行为模型,为巡逻人员设计巡逻路线,使巡逻的效率最大化。2、在现在的研究中,您主要用到的博弈论基础模型有哪些?最基础的模型还是斯塔克伯格安全博弈(Stackelberg Security Game, 简称SSG) 模型,然后基于这个模型增加新的内容。就拿反盗猎来说。盗猎者的行为并不是完全理性的,我们要针对他们的行为进行建模,然后与SSG模型相结合。原先的模型中,主要有两个玩家在博弈,一个玩家是领导者,或者保护者(需要规划防御资源的防御者,或巡逻人员,有需要保护的目标;另外一个玩家是跟随者,通常也被称为攻击者(比如在反盗猎问题中的盗猎者),能够了解保护者的策略后再决定去攻击哪些目标。攻击者对每个目标的攻击重要程度可能不一样,每个目标对攻击者的重要程度也不一定一样,玩家最后的收益是根据攻击者攻击了哪个目标,且成功与否。如果成功,玩家可以得到一个比较好的收益;如果失败,则得到一个非常差的收益。在这个基础模型中,有一些假设,比如攻击者会找到他们来说收益期望最大的目标进行攻击,而保护者需要了解攻击者的行为后,去思考如何分配安保资源,使保护者的预期收益最大。此外,还有一些比较特殊或更简单的模型,就是当这个模型是一个完全零和游戏时,即使有保护者和攻击者的区分,它的斯塔克伯格均衡、纳什均衡和最大最小策略(maximin strategy)应该是一致的。在这种情况下,我就要在假设两边都是完全理性的情况下,找到保护者的最佳策略,即极小极大(minimax)策略。3、机器学习与博弈论能够在哪些层面进行很好的结合?1)当人作为行为主体时,Ta 可能不是完全理性的。那么,我们就需要用机器学习去学 Ta 的行为模型,然后把这个行为模型嵌入到博弈论的模型当中。2)在很多问题中,玩家之间的互动是非常复杂的。比如反盗猎的例子。在实际中,巡护员要走一条完整的巡护路线,期间会遇到很多实际情况,比如看到某处有个脚印,这个脚印不是护林员的,而有可能是盗猎者的。那么,他们会考虑要不要追着脚印走。有时候他们在树上看到一些标记,如文字、箭头,也会想是不是要跟着箭头去追盗猎者。甚至有的时候,他听到一些声音,也会想要不要改变巡逻路线。在这样的情况下,他并不是在巡逻之前定好一条路线,然后期间遇到什么事都不管,就顺着路线走就行。他是根据他所观察到的情况进行应变,相当于连续性做决策。这跟强化学习的场景很像,也是连续性做决策。但是,它跟最基础的强化学习不一样的地方在于,我们会遇到能适应巡逻策略的对手。比如巡逻人员可能看到脚印就会去追着脚印跑,但如果他每次都这么做的话,盗猎者就会掌握巡护员的行为,依此采取措施。比如,盗猎者每次走路的时候,就故意往多个方向踩出一个脚印来迷惑护林员,或者想办法把脚印全部都抹掉。这就变成了一个双方在进行博弈的过程。在这样的问题中,如果我们建一个博弈论的模型,游戏就会非常复杂,有很多个采取行动的时间点,玩家在每个时间点都有很多可能采取的动作。这时候,我们就可以考虑使用强化学习中多智能体的方法来帮助找到比较接近平衡的值。从这个角度看,未来很多场景可能都是如此,比如智能车也是多智能体,它们在某种意义上也是一个在不断进行决策的过程,同时彼此之间又在博弈。如果将这类问题作为一个游戏,用传统博弈论里的解法是非常困难的,因为在传统的博弈论中,大家会用各种各样的数学规划进行求解,如线性规划,整数规划等等。这些方法在大型的博弈中无法解答。这时候,用强化学习的方法至少能够帮助找到这些复杂问题的较好策略。在我们之前的研究中,实际生活中遇到的博弈问题往往有一个难点,即我们不了解每个玩家的收益函数和训练方式。如果我们知道这些行为体/玩家之前的互动,互动中所采取的行动数据,我们就可以通过他们以前的行动来推导,相当于“逆向工程”,找出他们的训练方式。近年来,我们也在讨论如何通过机器学习的方法来求解支付函数(payoff function)。1月初,我和哈佛大学的 Andrew Parrot、UIUC的李博老师在IJCAI一起给了一个学术教程,关于机器学习和博弈论(Machine learning and game theory),他们也做了很多博弈论和强化学习相结合的工作,比如李博老师团队的对抗机器学习,他们会思考如果把从数据中学习机器学习模型的问题当成一个斯塔克伯格博弈,保护者在设计模型及参数,攻击者想要让这个模型无法输出正确的结果,那么如何求解。这也是另外一个可能的结合方式。4、在所解决的社会问题中,您认为最有代表性的是哪一项工作?我觉得这些研究在本质上都是我们设计的这些算法的应用,这些问题有一些共性:即多个智能体的策略行为。比如,保护野生动物不被偷猎在某种程度上与保护渡轮线路不受攻击有些相似:都有一个保护者和一个攻击者,然后我们是帮助保护者找到他们和攻击者的博弈中最好的策略。这都在博弈论的框架里。除了保护者和攻击者的安全博弈,我现在比较感兴趣的还有平台和用户的多智能体问题,如共享汽车平台。类似滴滴这样的平台是博弈中的领导者,是制定策略的一方,司机的接单数量与对应的奖励,如何派单,等等,都是策略的一部分。平台上的用户则相当于跟随者,当平台制定好策略后,用户在这些平台上采取自己的行动。但与安全博弈类问题不同的是,在共享汽车平台上,跟随者不止一个。除了平台,所有接单司机都有在进行互动和做决策。最近两年,我们有在和匹兹堡的一个食物拯救平台 412 Food Rescue 合作做一些研究。图注:412 Food Rescue官网首页 有些饭店和超市会有不适合售卖但是还没有过期的食物需要赶快处理,不然食物会浪费,他们就会去联系这个平台,让平台帮忙及时将这些食物送给需要食物的群体,比如低保家庭等。这个平台要对接餐馆、超市、需要食物的人和帮忙送食物的志愿者等。这个平台本质上是一个领导者,它制定了一系列的手机消息推送策略来联系志愿者。然后,平台上的志愿者是跟随者,会基于收到的推送和他们自己的喜好来决定是否帮忙送食物。我们帮助这个平台预测志愿者的行动,并且设计推送通知的方案。5、除了从保护区提供的数据,您还会通过哪些途径去获取您所需要的数据?首先我们是需要当地保护区的巡护团队所记录的以往数据,否则很难去做预测。然后,我们还需要很多地理数据,比如保护区里面的海拔变化,河流的位置,山脊线的位置,附近的村庄,附近的道路,甚至是附近的农田,哪一块树林是什么样的树林,等等。我们现在获取这一类数据的方式有两种:1)和保护区合作,由保护区的工作人员提供保护区附近的地理信息;2)去网上找可能公开的信息,比如很多公开的数据集、卫星图片上有海拔信息,或者我们半自动地去标定河流与道路,通过这样的方式额外得到一些地理信息相关的数据。根据这些数据,我们可以使用机器学习技术来预测偷猎者可能在哪里设置陷阱。但这还不够,因为偷猎者会根据巡逻策略的变化来改变行动。如果巡逻者总是去偷猎者常去的地点巡逻,那么偷猎者很大概率会变换他们的地点。这时博弈论就派上了用场:研究人员需要考虑巡逻人员与偷猎者如何相互影响对方的行为,最终策划出最优的巡逻策略。6、您的主页上有提到您在研究中进行实地考察,谈谈实地考察的意义。一开始,在对这个领域不熟悉的情况下,我们首先是用一个简单的理论模型,比如我们当时设计路线,把整个区域划分成 1km * 1km 的格子,让巡逻人员从格子 A 走到格子 B。后来保护区向我们反馈,说我们规划的路线没法走,因为从格子 A 到格子 B 之间隔了一座大山,根本走不过去。因此,他们就邀请我们去当地巡逻,感受一下实际的情况。我们去了当地之后,发现地形的确是一个非常重要的因素,中间有很多我们忽略的实际问题。我们一开始所提出的很整洁的博弈模型没有考虑到这些实际因素。所以我们在实地考察后,针对应用场景做了一系列的改变,创立了能够更好处理实际地貌信息与生成符合地貌的巡逻路线的算法,使得最后设计的巡逻路线能够起作用。我本人是在2015年去了马来西亚的热带雨林保护区,2017年去了中国东北的黄泥河保护区。我们论文的其他合作者还去了其他的一些保护区进行考察。图注:2015年7月在Rimba Panthera的邀请下到马来西亚实地考察,地貌复杂7、PAWS 这个项目您从读博开始就已进行研究,现在还有在继续吗?在保护野生动物这一块,我们不仅仅是设计巡逻路线,因为你可以想象,整个链条上有各个环节,每个环节都有很多值得去做的问题。我在博士毕业以后,继续沿着这个方向做了很多方面的尝试。盗猎者为什么要盗猎?原因可能是因为这件事有利可图,即使被抓住了,可能受到的惩罚也不是很大。然后我们就考虑,如何设计一个合理的奖惩机制,能最大化地减少盗猎者想要盗猎的意图,以及最后成果的可能性。后来,我们又探索了如何发动当地群众一起来帮助解决盗猎问题。有些地区的群众会向护林员汇报一些线索,比如他们看到或听说盗猎者可能会在哪些地方进行盗猎,那么作为护林员,得到了这些线索后,我们要如何去利用这些线索?如果这些线索是假的,又怎么办?所以,我们从研究者的角度,基于一个实际的问题,提炼了一个新的博弈模型:保护者-攻击者-信息提供者的三方博弈模型,然后探讨在这个模型里,均衡策略或最佳策略会是什么样的。8、目前 PAWS 取得了哪些具体成果?我们现在得到的数据是:在每个区域,他们用我们的算法进行辅助巡逻期间,他们找到了多少盗猎的线索。我们的论文里面也提到,在我们进行实验的这些区域里面,找到的猎套数量远远高于使用优化巡逻路线之前的猎套数量。我们现在能够分析的都是相对微观的结果,比如在这个区域里面,我们在同样的时间内,跟往年相比,通过我们设计的巡逻方案,找到了多少猎套?结果是比同时期的多很多。9、在反盗猎这一块,您希望您的研究最终取得怎样的成果?对于反盗猎这一块,之前WWF也提出了一个目标,就是零偷猎。他们也提到,为了实现零盗猎的目标,有6个方面的工作需要去做,其中一个方面是如何能够通过巡回的方式来减少盗猎,还有另一个方面是发动群众,比如我刚才所说的由群众来报告关于盗猎的线索。我是希望能够跟这些动物保护组织一起能够在多个方面合作,为他们提供计算工具,以帮助他们更好地实现或接近 零盗猎的目标。我们现在所开发的算法,有一部分已经被整合进更大的平台里面,还有一些是正在整合中。我所知道的情况是 Microsoft Azure那边的团队已经基于 PAWS 开发了一个API,希望给各个动物保护区提供云服务,让他们可以直接通过 Microsoft Azure的平台,利用这些算法来帮助他们进行盗猎活动的预测,甚至是盗猎路线的设计。据我所知,API 的部分已经完成,但我还不知道他们现在是不是已经完全上线或是否已经被使用。此外,有一个叫做 SMART 的软件,是多个动物保护组织一起出钱出力支持的软件。在全世界范围内有600~800个保护区都在用这个软件进行数据的记录和整理,SMART 软件也在把 PAWS的相关算法整合到软件中。整合完成后,原本在用 SMART 软件的600-800个保护区就可以直接使用 PAWS 的功能。10、您在平时的研究当中会跟不同领域的学者合作吗?会。我们之前去学盗猎者的行为模型时,跟心理学的学者合作过;我们最近有一篇关于流浪青年的工作是跟社会学的老师合作的。我们之前还有一篇论文是关于民间高利贷的内容,是跟法学系的老师合作的。像反盗猎的这一块的内容,我们因为要跟 动物保护组织 的人合作,他们中的一些人有 conservation biology (保护生物学)这方面的背景。11、您觉得如何能够发动更多的人参与到其中?我是非常希望我们的算法能够被应用。我自己的感受是,首先你需要去跟相关的机构合作,主动去寻找他们,包括会议上遇到的,我们做演讲时听众给我们的提示与灵感,我觉得可能有用的都会去联系。此外,我也会积极参加其他组织所举办的会议,比如最近准备去参加谷歌举办的“AI for social good”的研讨会,希望能够通过他们这个项目接触更多NGO组织。12、对于那些想要应用AI解决社会问题的学生,您会给出哪些科研建议呢?这个要看他处在科研的哪个阶段。如果是本科生阶段的话,我会非常建议他们去跟他们感兴趣的机构去接触,去实地做一些工作,比如我自己在 412 Food Rescue 平台上也做过志愿者。亲身经历后,你自己会有一些体会。此外,技术部分的基础要打牢。对于博士生,我建议感兴趣的学生从一年级开始就可以去主动联系这些机构。从建立信任,到建立一个稳定深入的合作关系,需要很长的时间。你要提出好的研究问题,并实际应用一些算法,收集实践数据,然后进行分析,这个过程可能就需要好几年。13、您现在有招收学生的需求吗?我今年至少会招一个学生。我现在主要是想招一个比较熟悉多智能体与强化学习的学生,同时也熟悉博弈论。像我刚刚说的,我最近比较感兴趣的课题是在平台和用户之间的多智能体系统里寻找好的沟通和协作策略。