新星JAX :双挑TensorFlow和PyTorch!有望担纲Google主要科学计算库和神经网络库
Posted 新智元
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了新星JAX :双挑TensorFlow和PyTorch!有望担纲Google主要科学计算库和神经网络库相关的知识,希望对你有一定的参考价值。
编辑:SHAO,元子
【新智元导读】JAX是机器学习框架领域的新生力量,它具有更快的高阶渐变,它建立在XLA之上,可以更快或在将来具有其他优势,具有其他有趣的转换和更好的TPU支持,甚至将来可能会成为Google的主要科学计算/NN库。「新智元急聘主笔、编辑、运营经理、客户经理,添加HR微信(Dr-wly)或扫描文末二维码了解详情。」
JAX是机器学习框架领域的新生力量,尽管这个Tensorflow的竞争对手从2018年末开就已经出现,但直到最近,JAX才开始在更广泛的机器学习研究领域中获得关注。
JAX官方文档是这样解释的:
“JAX是CPU、GPU和TPU上的NumPy,具有出色的自动差异化功能,可用于高性能机器学习研究。”
就像文档上说的那样,最简单的JAX是加速器支持的numpy,它具有一些便利的功能,用于常见的机器学习操作。
从2006年开始,你就可以得到numpy精心设计的API,它具有像Tensorflow和PyTorch这样的现代机器学习工具的性能特征。
通过 jax.scipy,JAX还包括scipy项目的很大一部分。
尽管加速器支持的numpy + scipy版本已经非常有用,但JAX还有一些其他的妙招。
首先让我们看看JAX对自动微分的支持。
Autograd是一个用于通过numpy和本机python代码高效计算梯度的库。
Autograd也恰好是JAX的(很大程度上是字面意义)前身。
尽管原始的autograd存储库已经不再重点开发 ,但是许多从事autograd工作的核心团队已全职转向于JAX项目。
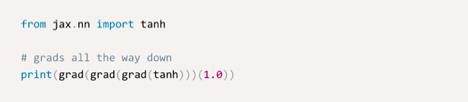
就像autograd的名字一样,JAX允许通过简单地调用grad来获取python函数输出导数:
您还可以通过本机python控制结构进行微分 —— 不需要与tf.cond较劲。
JAX支持求解高阶导数,grad函数可以任意嵌套使用
默认情况下,grad为您提供了反向模式梯度,这是计算梯度的最常见模式,它依赖于缓存激活来使反向传递高效。
反向模式差分通常是计算参数更新的最有效方法。
但是,尤其是在实施依赖于高阶导数的优化方法时,它并不总是最佳选择。
JAX通过jacfwd和jacrev对反向和正向模式自动微分提供优异的支持:
除了grad、jacfwd和jacrev之外,JAX还提供了计算函数的线性近似值、定义自定义梯度操作等实用程序,作为其自动微分支持的一部分。
XLA(加速线性代数)是一个线性代数代码的特定领域编译器,它是允许JAX将python和numpy表达式,转化为加速器支持的操作的中坚力量。
除了允许JAX将python + numpy代码转换为可以在加速器上运行的操作(如我们在第一个示例中看到的那样)之外,XLA还允许JAX将几个操作融合到一起。
它在计算图中寻找节点的簇,以减少计算或变量的中间存储。
Tensorflow关于XLA的文档中,使用下面的例子来解释会从XLA编译中受益的实例。
在没有XLA的情况下运行,这将作为3个独立的内核运行——乘法、加法和加法归约。
在有XLA运行的时候,这变成了一个负责这三者的单一内核,因为不需要存储中间变量,从而节省了时间和内存。
启用对此操作重写的支持与使用就像用@jax.jit来修饰一个函数一样简单:
像所有其他JAX函数一样,jax.jit是完全可组合的:
尽管Autograd和XLA构成了JAX库的核心,但是还有另外两个JAX函数脱颖而出。
您可以使用jax.vmap和jax.pmap进行矢量化和基于SPMD的(单程序多数据)并行。
为了说明vmap的好处,我们将返回简单密集层的示例,该层在向量x表示的单个示例上运行。
我们已经将隐藏层编写为接受单个向量输入,但是实际上,我们几乎总是将输入分批处理以利用向量化计算。
使用JAX,您可以使用任何接受单个输入并允许其接受一批输入的函数jax.vmap:
这其中的美妙之处在于,它意味着你或多或少地忽略了模型函数中的批处理维度,并且在你构建模型的时候,在你的头脑中总是少了一个张量维度。
如果您有多个应该全部矢量化的输入,或者要沿除轴0以外的其他轴矢量化,则可以使用in_axes参数指定此输入。
JAX的SPMD并行处理实用程序遵循非常相似的API。
如果您有一台4-gpu的计算机,并且有一批4个示例,则可以使用pmap每个设备运行一个示例。
相比TensorFlow和PyTorch,JAX的优势是什么?
我们使用的工具对我们探索的研究领域有着不相称的影响。
无论是有意识的,还是在潜意识里,我们把想法限制在我们知道如何有效实施的想法空间里。
正如罗曼·林(Roman Ring)在他探索下一代机器学习工具的博客文章中指出的那样,AlexNet主要是一项软件工程成就,它使得几十年来的好的机器学习想法能够得到正确的测试。
JAX向前迈出了重要的一步,不是因为它比现有的机器学习框架具有更简洁的API,或者因为它比Tensorflow和PyTorch在做它们被设计的事情上做得更好,而是因为它允许我们更容易地尝试以前可能的更广阔的思想空间。
如果您深入研究并开始将JAX用于自己的项目,你可能会对JAX在表面上做得如此之少而感到沮丧。
需要手工编写训练循环,管理参数需要自定义代码。
每当你想要一个新的随机值时,你甚至必须生成你自己的随机PRNG密钥。
但在某种程度上,这也是JAX最大的优势。
它不会把你看不到的细节藏在窗帘后面。
内部结构被广泛地记录下来,很明显,JAX关心的是让其他开发者做出贡献。
JAX对你打算如何使用它做了很少的假设,这样做给了你在其他框架中做不到的灵活性。
每当您将一个较低的API封装到一个较高的抽象层时,您就要对最终用户可能拥有的使用空间做出假设。
当您心中有一个非常有针对性的应用程序时,这就形成了非常简洁的应用程序接口,允许您用最少的配置获得想要的结果。
特别是最近在TF2.0中强调了Keras和更高级的APIs,编写Tensorflow感觉有点像使用3D打印机一样简单,只要你想要一个适合打印表面的塑料物体,它就会像被施了魔法一样工作。
和JAX一起工作就像被允许进入一个功能完善的机械车间。
是的,如果你不小心的话,你周围的一切东西,都有可能让你被砍掉一根手指或者造成严重的身体伤害。
但是,自由地实施和探索那些可能行得通的“无处不在”的想法,使得利用JAX变得值得。
所以请戴上你隐喻性的护目镜,开始使用JAX建造一些奇怪的东西。
尽管JAX的生态系统仍然相当分散,但是确实存在一些在JAX之上构建的框架,这些框架在核心应用编程接口之上提供了一些简单的抽象。
特别值得注意的是一下几个:
以上是关于新星JAX :双挑TensorFlow和PyTorch!有望担纲Google主要科学计算库和神经网络库的主要内容,如果未能解决你的问题,请参考以下文章
要替代TensorFlow?谷歌开源机器学习库JAX
是否有将 tensorflow NN 转换为 Jax 的模块?
TensorFlow败给PyTorch,谷歌:未来就靠你了,JAX
使用 JAX 构建强化学习 agent,并借助 TensorFlow Lite 将其部署到 Android 应用中
使用 JAX 构建强化学习 agent,并借助 TensorFlow Lite 将其部署到 Android 应用中
试试谷歌这个新工具:说不定比TensorFlow还好用!