试试谷歌这个新工具:说不定比TensorFlow还好用!
Posted 新智元
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了试试谷歌这个新工具:说不定比TensorFlow还好用!相关的知识,希望对你有一定的参考价值。
新智元原创
新智元原创
来源:Reddit、GitHub
编辑:三石
【新智元导读】谷歌团队(非官方发布)打造了一个名为JAX的系统,今日在Reddit引发了热议。网友纷纷为它叫好——“说不定能够取代TensorFlow”。本文便带领读者一览JAX的庐山真面目。
这个工具说不定比TensorFlow还好用!
它就是JAX,一款由谷歌团队打造(非官方发布),用于从纯Python和Numpy机器学习程序中生成高性能加速器(accelerator)代码,且特定于域的跟踪JIT编译器。
那么JAX到底有哪些威力呢?
JAX使用XLA编译器基础结构,来为子程序生成最有利于加速的优化代码,这些优化子程序可以由任意Python调用和编排;
由于JAX与Autograd完全兼容,它允许Python函数的正、反向模式(forward- and reverse-mode)自动区分为任意顺序;
由于JAX支持结构化控制流,所以它可以在保持高性能的同时为复杂的机器学习算法生成代码;
通过将JAX与Autograd和Numpy相结合,可得到一个易于编程且高性能的ML系统,该系统面向CPU,GPU和TPU,且能扩展到多核Cloud TPU。
此“神器”在Reddit上引发了热烈的讨论,网友纷纷为它叫好:
我的天,“可微分的numpy”实在是太棒了!我对pytorch有一点不是很满意,他们基本上重新做了numpy所做的一切,但存在一些愚蠢的差异,比如“dim”,而不是“axis”,等等。
谷歌团队通过观察发现,JAX的ML工作负载通常由PSC子程序控制。
JAX的设计便因此利用了函数通常可以直接在机器学习代码中识别的特性,使机器学习研究人员可以使用JAX的jit_ps修饰符进行注释。
虽然手工注释对非专业用户和“零工作量知识”优化提出了挑战,但它为专家提供了直接的好处,而且作为一个系统研究项目,它展示了PSC假设的威力。
JAX跟踪缓存为跟踪计算的参数创建了一个monomorphic signature,以便新遇到的数组元素类型、数组维度或元组成员触发重新编译。在跟踪缓存丢失时,JAX执行相应的Python函数,并将其执行跟踪到具有静态数据依赖关系的原始函数图中。
现有的原语不仅包括数组级别的数字内核,包括Numpy函数和其他函数,它们允许用户通过保留PSC属性将控制流分段到编译后的计算中。最后,JAX包含一些用于功能分布式编程的原语,如iterated_map_reduce。
为了生成代码,JAX将跟踪转换为XLA HLO,这是一种中间语言,可以对高度可加速的数组级数值程序进行建模。从广义上讲,JAX可以被看作是一个系统,它将XLA编程模型提升到Python中,并支持使用可加速的子程序,同时仍然允许动态编排。
def xla_add(xla_builder, xla_args, np_x, np_y):
return xla_builder.Add(xla_args[0], xla_args[1])
def xla_sinh(xla_builder, xla_args, np_x):
b, xla_x = xla_builder, xla_args[0]
return b.Div(b.Sub(b.Exp(xla_x), b.Exp(b.Neg(xla_x))), b.Const(2))
def xla_while(xla_builder, xla_args, cond_fun, body_fun, init_val):
xla_cond = trace_computation(cond_fun, args=(init_val,))
xla_body = trace_computation(body_fun, args=(init_val,))
return xla_builder.While(xla_cond, xla_body, xla_args[-1])
jax.register_translation_rule(numpy.add, xla_add)
jax.register_translation_rule(numpy.sinh, xla_sinh)
jax.register_translation_rule(while_loop, xla_while)
JAX从原语到XLA HLO的翻译规则
另外,JAX和Autograd完全兼容。
import autograd.numpy as np
from autograd import grad
from jax import jit_ps
def predict(params, inputs):
for W, b in params
outputs = np.dot(inputs, W) + b
inputs = np.tanh(outputs)
return outputs
def loss(params, inputs, targets):
preds = predict(params, inputs)
return np.sum((preds - targets)**2)
grad_fun = jit_ps(grad(loss)) # Compiled gradient-of-loss function
一个与JAX完全连接的基本神经网络
为了演示JAX和XLA提供的数组级代码优化和操作融合,谷歌团队编译了一个具有SeLU非线性的完全连接神经网络层,并在图1中显示JAX trace和XLA HLO图形。
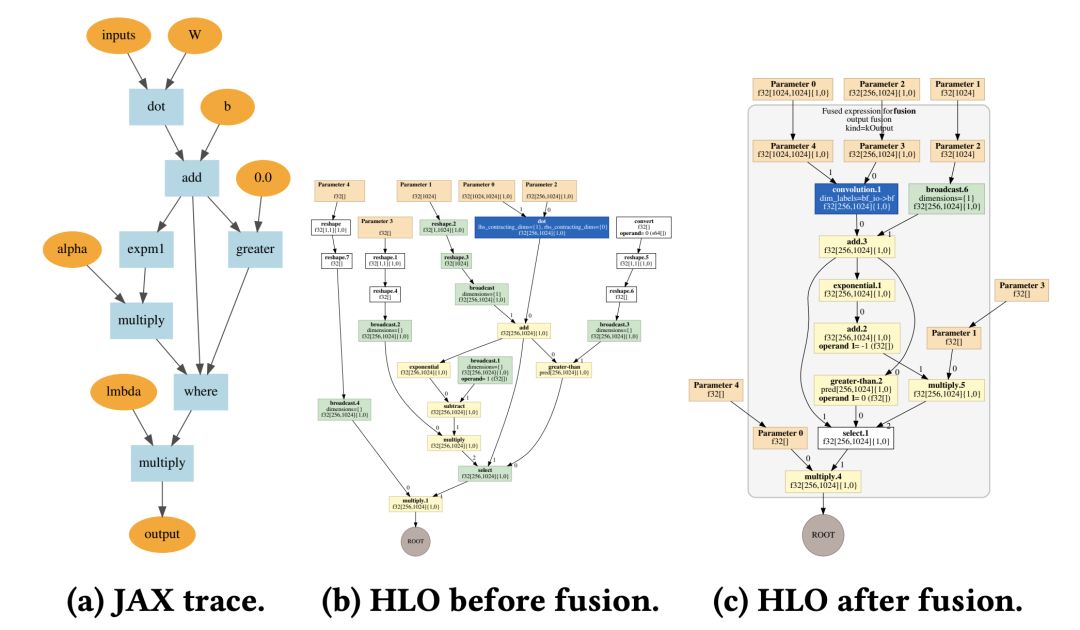
图1:XLA HLO对具有SeLU非线性的层进行融合。灰色框表示所有的操作都融合到GEMM中。
使用一个线程和几个小的示例优化问题(包括凸二次型、隐马尔科夫模型(HMM)边缘似然性和逻辑回归)将Python执行时间与CPU上的JAX编译运行时进行了比较。
对于某些CPU示例来说,XLA的编译时间比较慢,但将来可能会有显著的改进,对于经过warmed-up代码(表1),XLA的编译速度非常快。
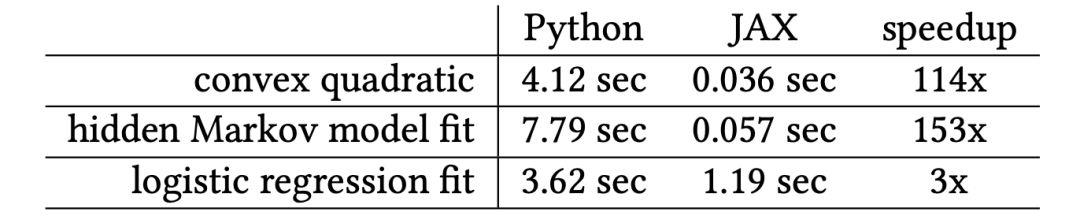
表1:在CPU上 Truncated Newton-CG的计时(秒)
在GPU上训练卷积网络。谷歌团队实现了一个all-conv CIFAR-10网络,只涉及卷积和ReLU激活。谷歌编写了一个单独的随机梯度下降(SGD)更新步骤,并从一个纯Python循环中调用它,结果如表2所示。
作为参考,谷歌在TensorFlow中实现了相同的算法,并在类似的Python循环中调用它。

表2:GPU上JAX convnet步骤的计时(msec)
云TPU可扩展性。云TPU核心上的全局批处理的JAX并行化呈现线性加速(图2,左)。 在固定的minibatch / replica中,texec受复制计数的影响最小(在2ms内,右边)
图2:为ConvNet训练步骤在云TPU上进行扩展。
参考文献、链接:
https://www.sysml.cc/doc/146.pdf
https://www.reddit.com/r/MachineLearning/comments/9z0gaj/d_what_seems_to_be_a_new_tflike_framework_from/
https://github.com/google/jax/blob/master/examples/mnist_vae.py
【加入社群】
以上是关于试试谷歌这个新工具:说不定比TensorFlow还好用!的主要内容,如果未能解决你的问题,请参考以下文章