机器学习基础 - 偏度正态化以及 Box-Cox 变换
Posted 五维实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习基础 - 偏度正态化以及 Box-Cox 变换相关的知识,希望对你有一定的参考价值。
1引言
对于数据挖掘、机器学习中的很多算法,往往会假设变量服从正态分布。例如,在许多统计技术中,假定误差是正态分布的。这个假设使得能够构建置信区间并进行假设检验。因此,在数据预处理阶段会查看目标变量以及各个特征是否服从或接近正态分布,如果偏离就通过一定变换将该数据的分布正态化。
一般来说,数据的直方图如果单峰并近似正态但看上去又有些扭曲,可以考虑正态化。比如整体看上去还是一个山峰,但可能峰顶很尖或者整座山往左/往右倾斜了。这些现象如何用数字量化呢?偏度(skewness)和峰度(Kurtosis)就是两个常见的统计量,本篇主要处理前者。如下图所示,红色表示正态分布,黑色表示不同偏度,绿色和蓝色表示正负峰度。
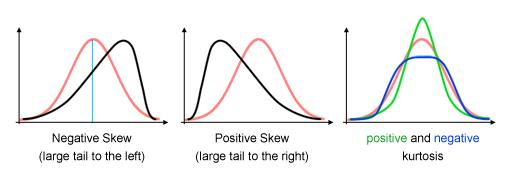
.偏度的意义
偏度是一个重要的统计概念,我们至少可以从三个方面来衡量,
-
实际数据很少遵循正态分布。而偏度衡量了数据分布的不对称性,对于了解数据分布的形状来说至关重要。
-
偏度告诉我们离群值的方向。正偏度表示存在较大的极值,负偏度表示存在较小的极值。
-
偏度可以揭示大多数值集中在哪里,以及反应了均值、中位数以及众数间的大小关系。
例如,下图描绘了人均 GDP 的密度图,该图偏向右侧,平均值比中位数高出两倍多,换句话说,大多数国家的人均 GDP 较低。
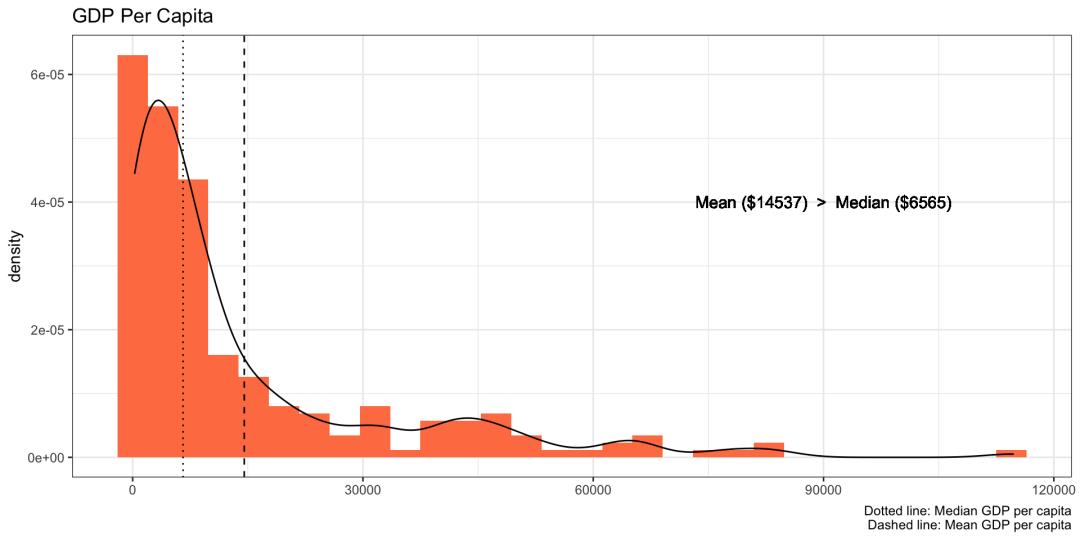
2偏度
偏度,也称为偏态、偏态系数,是统计数据分布偏斜方向和程度的度量,是统计数据分布非对称程度的数量特征。
.定义
随机变量
其中
.样本偏度
具有
其中
根据数值可以将偏度分为两种,
-
负偏度或左偏度:左侧的尾部更长,数据左侧有较多的极值,分布的主体集中在右侧。 -
正偏度或右偏度:右侧的尾部更长,数据右侧有较多的极值,分布的主体集中在左侧。
.偏度与 3M
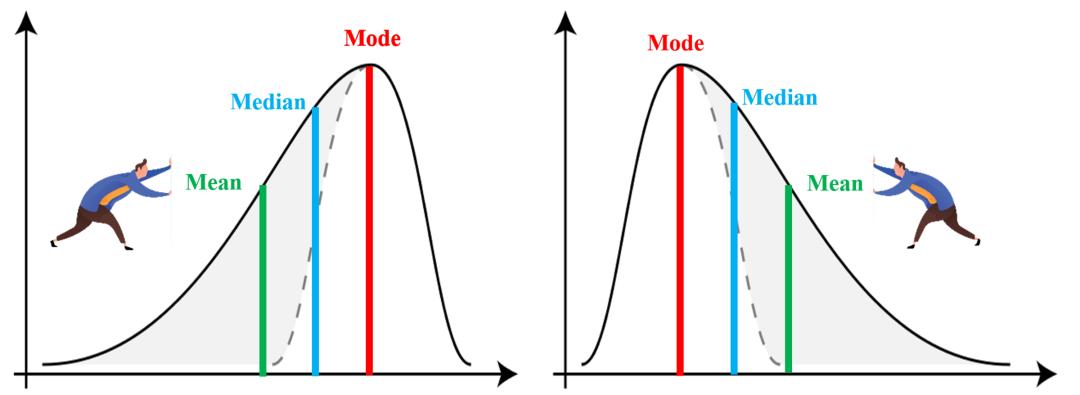
请注意,这里所谓的左偏和右偏的叫法,是根据尾部的方向来说的。对于左图,因为尾部在左侧,所以它是左偏(负偏);而右图的尾部是在右侧,所以它是右偏(正偏)。
上图分别为负偏度(左)和正偏度(右)的情况,注意平均值(mean)、中位数(median)和众数(mode)的位置。例如,对于右偏度,由于有较大的极值存在,所以拉高了平均值。
另外,如果分布对称,那么平均值 = 中位数,偏度为零。如果分布为单峰分布,那么平均值 = 中位数 = 众数。注意,偏度为零表示数值相对均匀地分布在平均值的两侧,但不一定意味着其为对称分布。
.皮尔逊偏度系数
为了简化计算,偏度还可以有其他定义方式,包括 Karl Pearson 建议的更简单的定义。
直观地看,偏度越大,众数与均值之间的距离就越大。从这个角度出发,我们可以定义如下皮尔逊(Pearson)第一偏度系数,
可以用中位数和均值来近似计算众数,即
这就是说所谓的皮尔逊第二偏度系数,
3偏度分级
分布的偏度计算出来以后,我们要想办法将数据正态化。不同的偏度意味着数据分布与正态分布的不同偏离程度,因此需要使用不同的变换。可以将偏度分成三级,然后针对每个级别采用不同方法。
| 偏度 | |
|---|---|
| 对称 | -0.5 到 0.5 |
| 中度正/负偏度 | -0.5 到 -1.0 以及 0.5 到 1.0 |
| 高度正/负偏度 | < -1.0 以及 > 1.0 |
将上面的图和表整合成如下一张图。

.样例
下面用三个图模拟一下对称、正偏和负偏三种情况,分别对应正态分布、指数分布和贝塔分布。
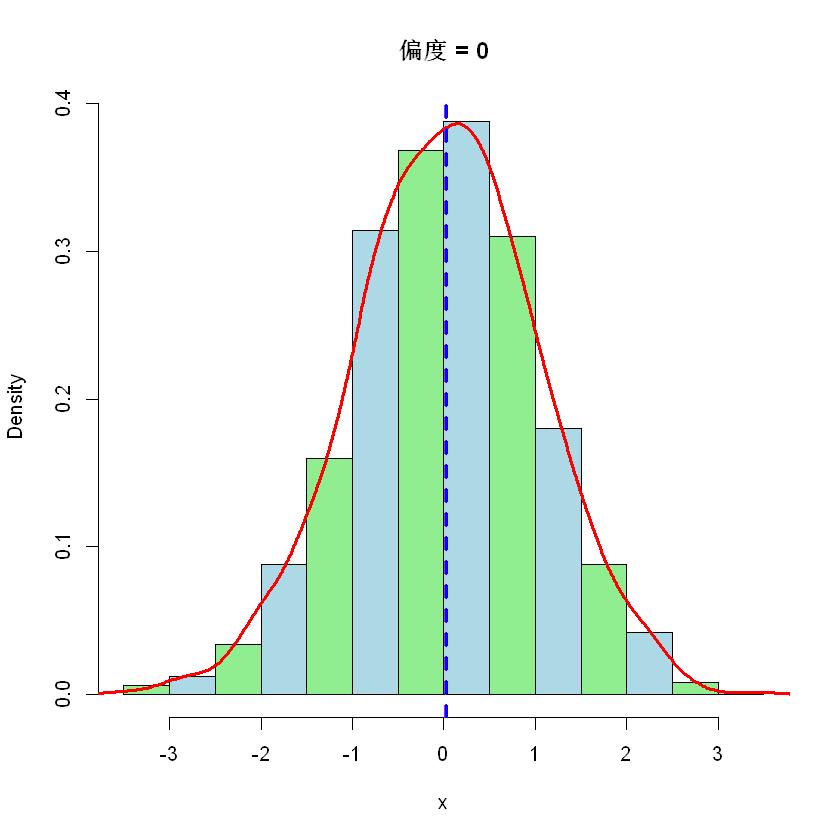
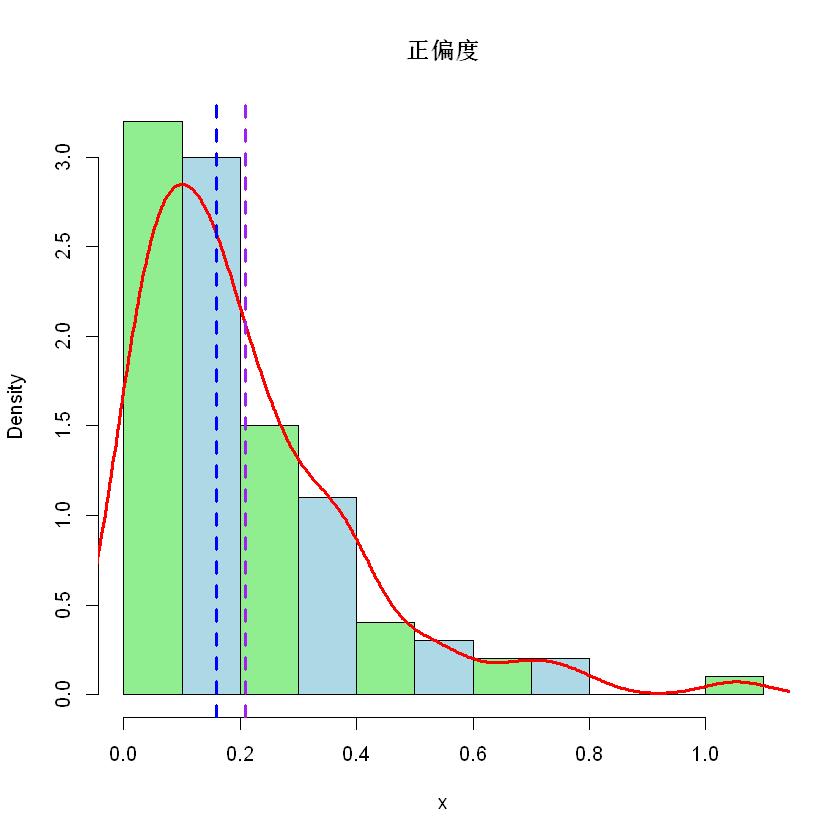
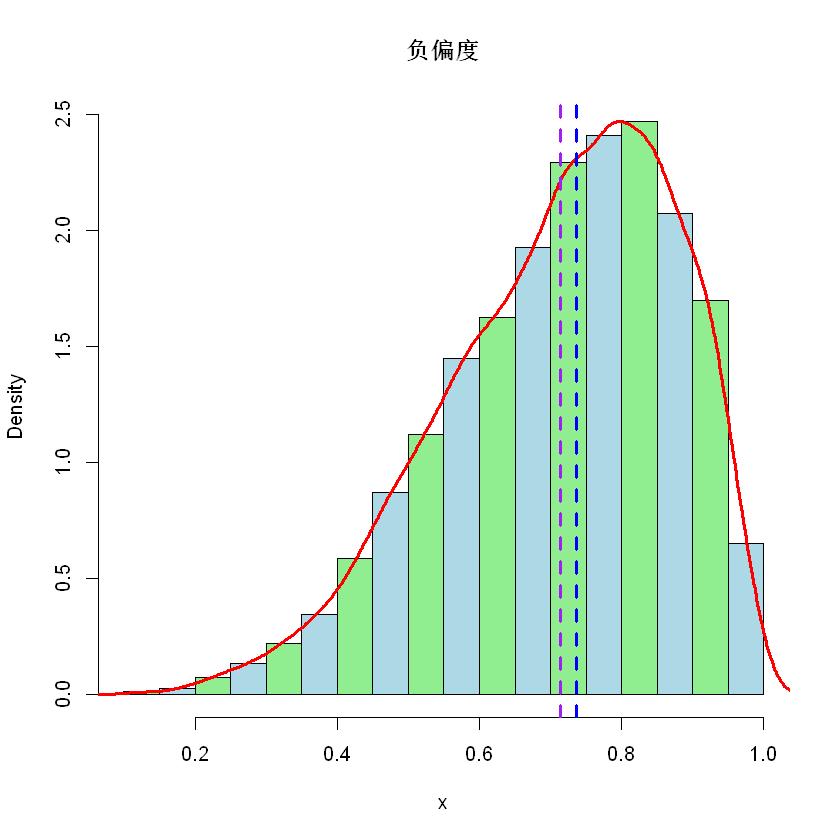
注意,紫色竖线表示平均值,蓝色竖线表示中位数。
4特征正态化
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
载入数据,发现有四个特征。
data = pd.read_csv('./data_to_transform.csv', encoding = "gbk")
data.shape
(10000, 4)
# 把几个 object 改成 float64
for col in data.columns:
data[col] = pd.to_numeric(data[col], errors='coerce').astype('float64')
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10000 entries, 0 to 9999
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 中度正偏度 10000 non-null float64
1 高度正偏度 10000 non-null float64
2 中度负偏度 10000 non-null float64
3 高度负偏度 10000 non-null float64
dtypes: float64(4)
memory usage: 312.6 KB
计算偏度(和峰度),发现中度偏度和高度偏度各两个。
data.agg(['skew', 'kurtosis']).transpose()
| skew | kurtosis | |
|---|---|---|
| 中度正偏度 | 0.656308 | 0.584120 |
| 高度正偏度 | 1.271249 | 2.405999 |
| 中度负偏度 | -0.690244 | 0.790534 |
| 高度负偏度 | -1.201891 | 2.086863 |
分别绘制四个特征的直方图。
data.hist(grid=False, figsize=(10, 6), bins=30);
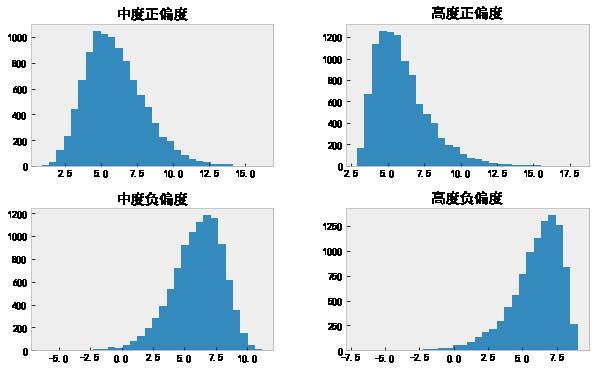
这里通过偏度和可视化的形式查看数据是否服从正态分布。当然也可以进行正态性的统计检验,例如 Shapiro-Wilks 等检验。
下面我们将开始转换上面四个非正态特征。首先,我们将先变换中等偏度的分布,然后再处理高偏度的数据。
.中度正偏 - 开方变换
对于中度正偏的特征,我们直接调用 np.sqrt 开根号伺候。
data.insert(len(data.columns), 'A_Sqrt', np.sqrt(data.iloc[:,0]))
# 查看变换前后的直方图
data[['中度正偏度', 'A_Sqrt']].hist(grid=False, figsize=(12, 5), bins=30);
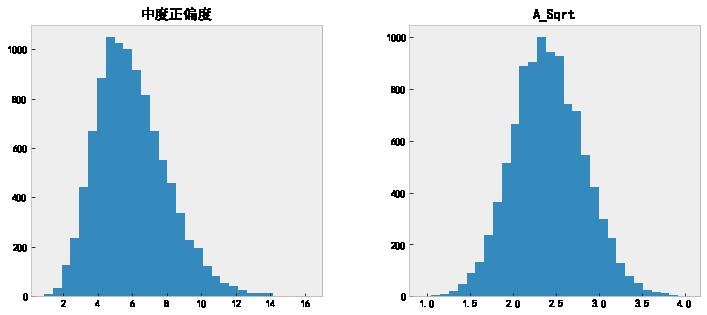
# 查看变换以后的偏度值
data['A_Sqrt'].skew()
0.15247903034789928
.中度负偏
那么如何处理负(左)偏度数据呢?如果直接应用 np.sqrt,那么现在,我们将收到 ValueError。
我们用最大值减去各个值,然后再开平方根,就可以变换负(左)偏度的特征。
data.insert(len(data.columns), 'B_Sqrt',
np.sqrt(max(data.iloc[:, 2]+1) - data.iloc[:, 2]))
data.columns
Index(['中度正偏度', '高度正偏度', '中度负偏度', '高度负偏度', 'A_Sqrt', 'B_Sqrt'], dtype='object')
# 查看变换前后的直方图
data[['中度负偏度', 'B_Sqrt']].hist(grid=False, figsize=(12, 5), bins=30);
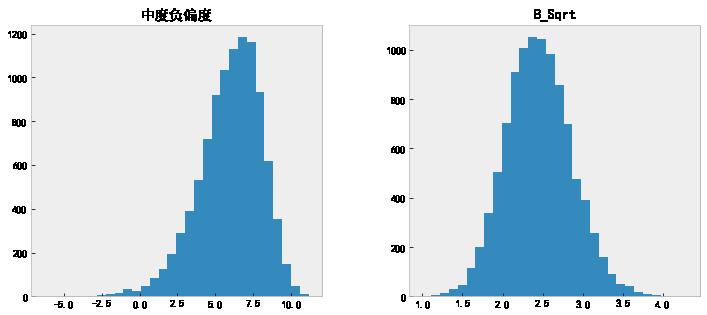
# 查看变换以后的偏度值。
data['B_Sqrt'].skew()
0.17976143295194769
.高度正偏
正偏度较大时,我们不再采用开方,而使用 log 对数变换。
data.insert(len(data.columns), 'C_log',
np.log(data['高度正偏度']))
# 查看变换前后的直方图
data[['高度正偏度', 'C_log']].hist(grid=False, figsize=(12, 5), bins=30);
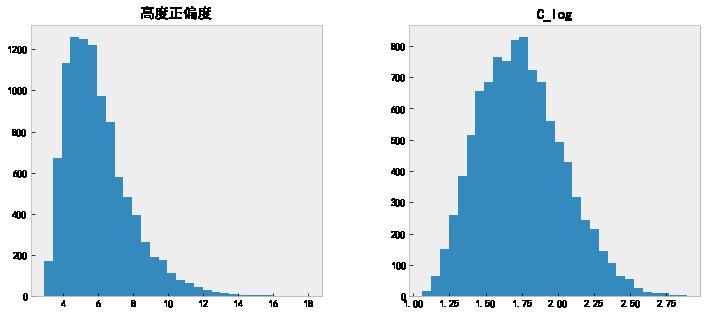
# 查看变换以后的偏度值。
data['C_log'].skew()
0.3987799089368201
看着这个偏度值,似乎还可以再做一次。
.高度负偏
log 对数变换负偏度。
data.insert(len(data.columns), 'D_log',
np.log(max(data.iloc[:, 2] + 1) - data.iloc[:, 2]))
# 查看变换前后的直方图
data[['高度负偏度', 'D_log']].hist(grid=False, figsize=(12, 5), bins=30);
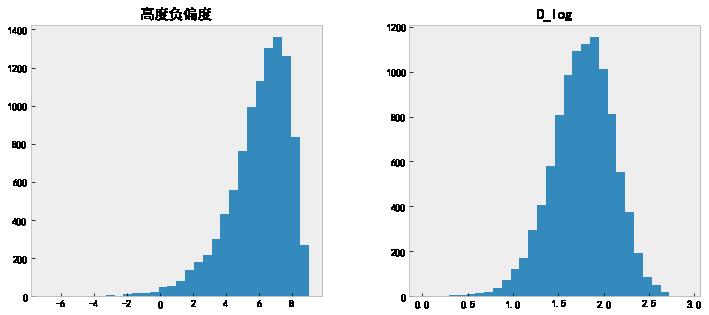
# 查看变换以后的偏度值。
data['D_log'].skew()
-0.3613244184552957
.Box-Cox 变换
除了 log 变换,还可以使用 Box-Cox 转换来对数据分布纠偏。从上面的开方变换和对数变换可以感觉到,不同偏度的数据应该使用不同的变换,那么我们能不能根据数据自动地选择变换函数呢?
我们用一个公式来统一上面两种函数,看公式,
这里当参数
对于给定的数据,Box-Cox 变换的主要问题就是要估计出合适的参数值
调用 scipy 的 boxcox
至于参数值是如何从数据中估计的我们先不管它,接下来直接使用 SciPy 提供的 Box-Cox 来估计参数以及变换数据。
from scipy.stats import boxcox
# Box-Cox 变换
data.insert(len(data.columns), 'A_Boxcox', boxcox(data.iloc[:, 0])[0])
我们来验证一下,先取得 boxcox 返回的参数
lmd = boxcox(data.iloc[:, 1])[1]
(data.iloc[:, 1]**lmd-1)/lmd
0 0.812909
1 0.825921
2 0.826679
3 0.833058
4 0.835247
...
9995 1.457701
9996 1.459189
9997 1.468681
9998 1.475357
9999 1.480525
Name: 高度正偏度, Length: 10000, dtype: float64
# boxcox 返回的结果
boxcox(data.iloc[:, 1])[0]
array([0.81290868,
0.8259212 ,
0.82667884,
...,
1.46868052,
1.47535734,
1.48052514])
可以看到,结果是一致的。
# 查看各列的偏度
data.agg(['skew']).transpose()
| skew | |
|---|---|
| 中度正偏度 | 0.656308 |
| 高度正偏度 | 1.271249 |
| 中度负偏度 | -0.690244 |
| 高度负偏度 | -1.201891 |
| A_Sqrt | 0.152479 |
| B_Sqrt | 0.179761 |
| C_log | 0.398780 |
| D_log | -0.361324 |
| A_Boxcox | 0.000155 |
我们从上表中可以看到,变换后的值的偏度值现在都在 0.5 以下。
# Box-Cox 变换
data.insert(len(data.columns), 'B_Boxcox', boxcox(data.iloc[:, 1])[0])
data[['中度正偏度', '高度正偏度', 'A_Sqrt', 'C_log', 'A_Boxcox', 'B_Boxcox']].hist(grid=False, figsize=(10, 15), bins=30);
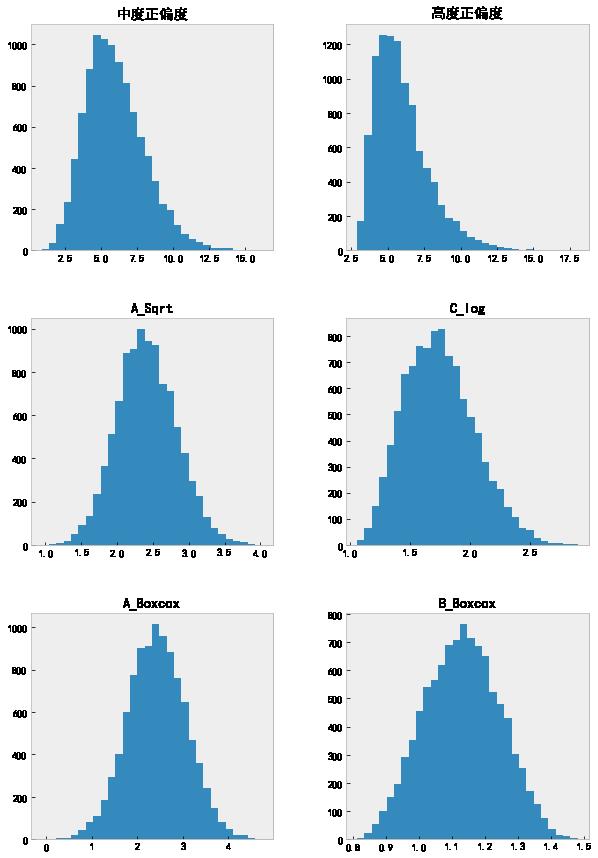
可以看出来,在这个例子中, Box-Cox 变换比开根号和对数变换的纠偏效果更好。
接着,我们通过 QQ-plot 来检验一下原始数据、对数变换以及 Box-Cox 变换的正态性。
from scipy import stats
最后一个 Box-Cox 变换后的 QQ-plot 绘制如下,其他的类似。
stats.probplot(data['B_Boxcox'],dist='norm',plot=plt);
下面的图按原始数据、对数变换以及 Box-Cox 变换的顺序。
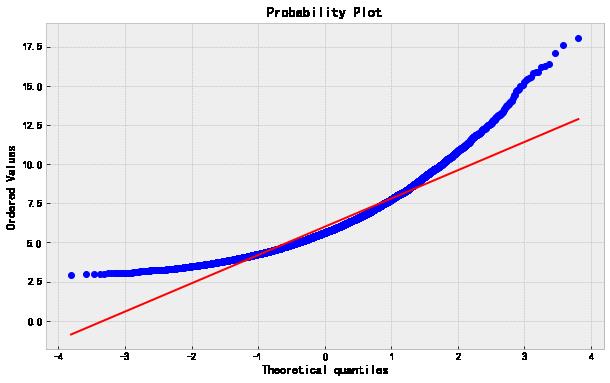
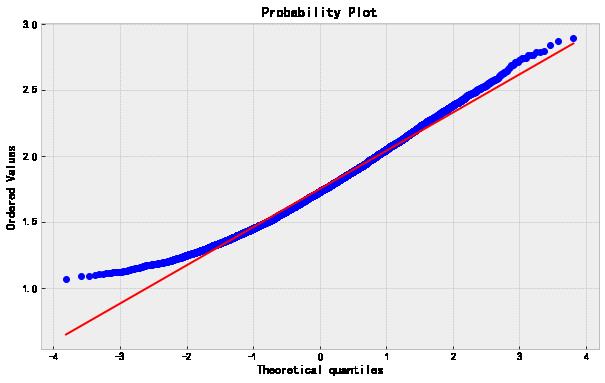
最后,如果你在训练一个机器学习的模型,那么 Box-Cox 的参数值应该从训练集里的数据估计而来,然后可以拿来对训练集之外的数据进行同样的变换。
# import modules
import numpy as np
from scipy import stats
from sklearn.model_selection import train_test_split
# plotting modules
import seaborn as sns
import matplotlib.pyplot as plt
# generate non-normal data
original_data = np.random.exponential(size = 1000)
# split into testing & training data
train,test = train_test_split(original_data, shuffle=False)
# transform training data & save lambda value
train_data,fitted_lambda = stats.boxcox(train)
# use lambda value to transform test data
test_data = stats.boxcox(test, fitted_lambda)
以上是关于机器学习基础 - 偏度正态化以及 Box-Cox 变换的主要内容,如果未能解决你的问题,请参考以下文章
R语言Box-Cox变换实战(Box-Cox Transformation):将非正态分布数据转换为正态分布数据计算最佳λ变换后构建模型
SPSS在分析一组数据时,偏度在啥范围内可以认为数据服从正态分布?
R语言使用moments包计算偏度(Skewness)和峰度(Kurtosis)实战:计算偏度(Skewness)和峰度(Kurtosis)确定样本数据是否具有与正态分布匹配的偏度和峰度(假设检验)