前端架构破局 - NodeJS 落地 WebSocket
Posted 前端巅峰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前端架构破局 - NodeJS 落地 WebSocket相关的知识,希望对你有一定的参考价值。
是全双工通信协议,当客户端与服务端建立连接之后,双方可以互相发送数据,这样的话就不需要客户端通过轮询这种低效的方式获取数据,服务端有新消息直接推送给客户端即可。
传统 HTTP 连接方式如下:
框架中。但是也许你不清楚,Socket.IO 并不是一个纯粹的 WebSocket 框架。它是将 Websocket 和轮询机制以及其它的实时通信方式封装成了通用的接口,以实现更高效的双向通信。
严格来说,Websocket 只是 Socket.IO 的一部分。
也许你会问:既然 Socket.IO 在 WebSocket 的基础上做了那么多的优化,并且非常成熟,那为什么还要搭一个原生 WebSocket 服务?
首先,Socket.IO 不能通过原生的 ws 协议连接。比如你在浏览器试图通过 ws://localhost:8080/test-socket 这种方式连接 Socket.IO 服务,是连接不上的。因为 Socket.IO 的服务端必须通过 Socket.IO 的客户端连接,不支持默认的 WebSocket 方式连接。
其次,Socket.IO 封装程度非常高,使用它可能不利于你了解 WebSocket 建立连接的原理。
因此,我们本篇就用 Node.js 中基础的 ws 模块,从头开始实现一个原生的 WebSocket 服务,并且在前端用 ws 协议直接连接,体验一把双向通信的感觉!
是 Node.js 下一个简单快速,并且定制程度极高的 WebSocket 实现方案,同时包含了服务端和客户端。用 ws 搭建起来的服务端,浏览器可以通过原生 WebSocket 构造函数直接连接,非常便捷。ws 客户端则是模拟浏览器的 WebSocket 构造函数,用于连接其他 WebSocket 服务器进行通信。
注意一点:ws 只能在 Node.js 环境中使用,浏览器中不可用,浏览器请直接使用原生 WebSocket 构造函数。
下面开始接入,第一步,安装 ws:
$ npm install ws
安装好后,我们先搭建一个 ws 服务端。
然后运行:$ node ws-server.js
这样一个监听 8080 端口的 WebSocket 服务器就已经跑起来了。
然后用浏览器打开,看到打印如下: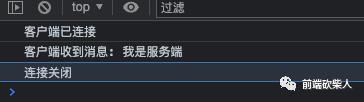
事件的回调函数,参数是一个 MessageEvent 的实例对象,服务端发来的实际数据需要通过 mevt.data 获取。
而在 ws 客户端,这个参数就是服务端的实际数据,直接获取即可。
连接:app.ws(的路由组并指向 websocket.js 文件,代码如下:就可以访问到这个子路由。路由组的作用是定义一个 websocket 连接组,不同需求连接这个组下的不同子路由。比如可以将 单聊 和 群聊 设置为两个子路由,分别处理各自的连接通信逻辑。
完整代码如下:
就是 WebSocket 实例,表示建立的连接。属性,赋值为一个函数来监听服务端消息:ws.onmessage = 方法用于发送信息,向服务端发送数据:ws.send(属性,以及 send 方法都是一致的。不过因为服务端是 Node.js 实现,因此会有更丰富的支持。比如下面两种监听事件的写法效果是一样的:
模块提供了快捷的获取方法:怎么获取:后,我们看看它到底是什么样子。经过打印,发现它的数据结构比想象到还要简单,就是由所有在线客户端的 WebSocket 实例组成的一个 Set 集合。那么,获取当前在线客户端的数量:
wss.clients.size
简单粗暴的实现广播:
wss.clients.forEach(存储在线客户端的状态和数据,这样检索分类更快,效率更高。局部广播实现,那一对一私聊就更容易了。找到两个客户端对应的 WebSocket 实例互发消息就行。
建立连接的第一步是客户端发起一个 HTTP 的连接请求,那么我们在这个 HTTP 请求上做验证,如果验证失败,则中断 WebSocket 的连接创建,不就可以了?顺着这个思路,我们来改造一下服务端代码。
因为要在 HTTP 层做校验,所以用 http 模块创建服务器,关掉 WebSocket 服务的端口。
连接服务端时,服务端会进行协议升级,也就是将 http 协议升级成 websocket 协议,此时会触发 upgrade 事件:server.on(认证简单说就是账号+密码认证,而且账号密码是带在 URL 里的。假设我有账号是 ruims,密码是 123456,那么客户端连接是这样:
就是 ruims:123456 的 base64 编码,服务端可以获取到这个编码来做认证。Quary 传参比较简单,就是普通的 URL 传参,可以带一个短一点的加密字符串过去,服务端获取到该字符串然后做认证:
协议连接,那 wss 是什么意思?其实非常简单,和 https 原理一摸一样。
https 表示安全的 http 协议,组成是 HTTP + SSL
wss 则表示安全的 ws 协议,组成是 WS + SSL
那为什么一定要用 wss 呢?除了安全性,还有一个关键原因是:如果你的 web 应用是 https 协议,你在当前应用中使用 WebSocket 就必须是 wss 协议,否则浏览器拒绝连接。
配置 wss 直接在 https 配置中加一个 location 即可,直接上 nginx 配置:
location /websocket
proxy_pass http://127.0.0.1:8080;
proxy_redirect off;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection upgrade;
然后客户端连接就变成了这样:
var ws = new WebSocket(\'wss://[host]/websocket\')
BFF 应用BFF 或许你听说过,全称是 Backend For Frontend,意思是为前端服务的后端,在实际应用架构中属于前端和后端的一个 中间层。
这个中间层一般是由 Node.js 实现,那么它有什么作用呢?
众所周知,现在后端的主流架构是微服务,微服务情况下 API 会划分的非常细,商品服务就是商品服务,通知服务就是通知服务。当你想在商品上架时给用户发一个通知,可能至少需要调两个接口。
这样的话对前端其实是不友好的,于是后来出现了 BFF 中间层,相当于一个后端请求的中间代理站,前端可以直接请求 BFF 的接口,然后 BFF 再向后端接口请求,将需要的数据组合起来,一次返回前端。
那我们在上面讲的一大堆 WebSocket 的知识,在 BFF 层如何应用呢?
我想到的应用场景至少有 4 个:
查看当前在线人数,在线用户信息 登录新设备,其他设备退出登录 检测网络连接/断开 站内消息,小圆点提示
这些功能以前是在后端实现的,并且会与其他业务功能耦合。现在有了 BFF,那么 WebSocket 完全可以在这一层实现,让后端可以专注核心数据逻辑。
由此可见,掌握了 WebSocket 在 Node.js 中的实践应用,作为前端的我们可以破除内卷,在另一个领域继续发挥价值,岂不美哉?
源码+答疑本文所有的代码都是经过我亲自实践,为了便于小伙伴们查阅和试验,我建了一个 GitHub 仓库专门存放本文的完整源码,以及之后文章的完整源码。
仓库地址在这里:https://github.com/ruidoc/blog-codes
欢迎大家查阅和试验。
首发公众号如果本文对你有启发,请左手一个赞,右手一个在看,祝你脱单不脱发,早日成为技术专家~
如对文中细节有疑问,欢迎加微信咨询~
阿里云天池Apache Spark落幕:AI医疗进入落地实践深水期,达摩院如何用生态破局?
机器之心原创
一次疫情,让阿里达摩院医疗 AI 团队一战成名。
他们利用整个假期,疫情爆发初期迅速将技术落地,率先在「郑州小汤山」落地的第一套 CT 影像识别系统代码和图片已经被分别收藏在中国国家博物馆和中国科技馆。
疫情之后,达摩院医疗 AI 产品迅速进入落地阶段,成长与痛点并存。
面对技术落地面临的普遍困境,达摩院以「数字人体」系列比赛为抓手,逐渐搭建起行业生态。



✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com
以上是关于前端架构破局 - NodeJS 落地 WebSocket的主要内容,如果未能解决你的问题,请参考以下文章