[Skr-Shop]购物车之架构设计
Posted 大愚Talk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Skr-Shop]购物车之架构设计相关的知识,希望对你有一定的参考价值。
skr shop是一群底层码农,由于被工作中的项目折磨的精神失常,加之由于程序员的自傲:别人设计的系统都是一坨shit,我的设计才是宇宙最牛逼,于是乎决定要做一个只设计不编码的电商设计手册。
项目地址:https://github.com/skr-shop/manuals
在上一篇文章 购物车设计之需求分析 描述了购物车的通用需求。本文重点则在如何实现上进行架构上的设计(业务+系统架构)。
(领域驱动设计)思想;还是那句话适合的就是最好的。来进行设计的。我们来看看如何将上面的业务架构映射到代码层面来。ShoppingData Item []*Item UpdateTime Version Item ItemId ParentItemId OrderId Sku Spu Channel Num Status TTL SalePrice SpecialPrice PostFree Activities []*ItemActivity AddTime UpdateTime ItemActivity ActID ActType ActTitle 这个结构,item_id 这个字段是标记购物车中某个商品的唯一标记,因为我们之前说过,同一个sku由于渠道不同,那么在购物车中会是两个不同的item;接下来的 parent_item_id 字段是用来标记父子关系的,这里将可能存在的树结构转成了顺序结构,我们不管是父商品还是子商品,都采用顺序存储,然后通过这个字段来进行关联;有些同学可能会奇怪,为什么会存order id这个字段呢?大家关注下自己的日常业务,比如:再来一单、定金预售等,这种一定是与某个订单相关联的,不管是为了资格验证还是数据统计。剩下的字段都是一些非常常规的字段,就不在一一介绍了;字段的类型,大家根据自己的需要进行修改。
接下来该说怎么选择Redis的存储结构了,Redis常用的 Hash Table、集合、有序集合、链表、字符串 五种,我们一个个来分析。
首先购车一定有一个key来标记这个购物车属于哪个用户的,为了简化,我们的key假设是:uid:cart_type。
我们先来看如果用 Hash Table;我们添加时,需要用到如下命令:HSET uid:cart_type sku ShoppingData;看起来没问题,我们可以根据sku快速定位某个商品然后进行相关的修改等,但是注意,ShoppingData是一个json串,如果用户购物车中有非常多的商品,我们用 HGETALL uid:cart_type 获取到的时间复杂度是O(n),然后代码中还需要一一反序列化,又是O(n)的复杂度。
如果用集合,也会遇到类似的问题,每个购物车看做一个集合,集合中的每个元素是 ShoppingData ,取到代码中依然需要逐一反序列化(反序列化是成本),关于有序集合与链表就不在分析,大家可以按照上面的思路去尝试下问题所在。
看起来我们没得选,只有使用String,那我们来看一下String的契合度是什么样子。首先SET uid:cart_type ShoppingDataArr;我们把购物车所有的数据序列化成一个字符串存储,每次取出来的时间复杂度是O(1),序列化、反序列化都只需要一次。看来是非常不错的选择。但是在使用中大家还是有几点需要注意。
单个Value不能太大,要不然就会出现大key问题,所以一般购物车有上限限制,比如item不能超过多少个; 对redis的操作性能提升上来了,但是代码的就是修改单个item时的不便,必须每次读取全部然后找到对应的item进行修改;这里我们可以把从redis中的数据读取出来后,在内存中构建一个HashTable,来减少每次遍历的复杂度;
网上也看到很多Redis数据结构组合使用来保存购物车数据的,但是无疑增加了网络开销,相比起来还是String最经济划算。
总结
至此对于购物车的实现设计算是完结了,其中关于订单表的设计会单独放到订单模块去讲。
对于整个购物车服务,虽然没有写的详细到某个具体的接口,但是分析到这一步,我相信大家心中都是有沟壑的,能够结合自己的业务去实现它。
文中有些很有意思的地方,建议大家动手去做做看,有任何问题,我们随时交流。
改编版的责任链模式 Redis的分布式事务锁实现 接下来终于要到订单部分的设计了,希望大家继续关注我们。
购物车之架构设计
skr shop是一群底层码农,由于被工作中的项目折磨的精神失常,加之由于程序员的自傲:别人设计的系统都是一坨shit,我的设计才是宇宙最牛逼,于是乎决定要做一个只设计不编码的电商设计手册。
在上一篇文章 购物车设计之需求分析 描述了购物车的通用需求。本文重点则在如何实现上进行架构上的设计(业务+系统架构)。
说明
架构设计可以分为三个层面:
-
业务架构
-
系统架构
-
技术架构
快速简单的说明下三个架构的意思;当我们拿到购物车需求时,我们说用Golang来实现,存储用Redis;这描述的是技术架构;我们对购物车代码项目进行代码分层,设计规范,以及依赖系统的规划这叫系统架构;
那业务架构是什么呢?业务架构本质上是对系统架构的文字语言描述;什么意思?我们拿到一个需求首先要跟需求方进行沟通,建立统一的认知。比如:规范名词(购物车中说的商品与商品系统中商品的含义是不同的);建立大家都能明白的模型,购物车、用户、商品、订单这些实体之间的互动,以及各自具备什么功能。
在业务架构分析上有很多方法论,比如:领域驱动设计,但是它并不是唯一的业务架构分析方法,也并不是说最好的。适合你的就是最好的。我们常用的实体关系图、UML图也属于业务架构领域;
这里需要强点一点的是,不管你用什么方式来建模设计,有设计总比没设计强,其次一定要将建模的内容体现到你的代码中去。
本文在业务架构上的分析借助了 DDD (领域驱动设计)思想;还是那句话适合的就是最好的。
业务架构
通过前面的需求分析,我们已经明确我们的购物车要干什么了。
先来看一下一个典型的用户操作购物车过程。

用户旅程
在这个过程中,用户使用购物车这个载体完成了商品的购买流程;不断流动的数据是商品,购物车这个载体是稳定的。这是我们系统中的稳定点与变化点。
商品的流动方式可能多种多样,比如从不同地方加入购物车,不同方式加入购物车,生命周期在购物车中也不一样;但是这个流程是稳定的,一定是先让购物车中存在商品,然后才能去结算产生订单。
商品在购物车中的生命周期如下:
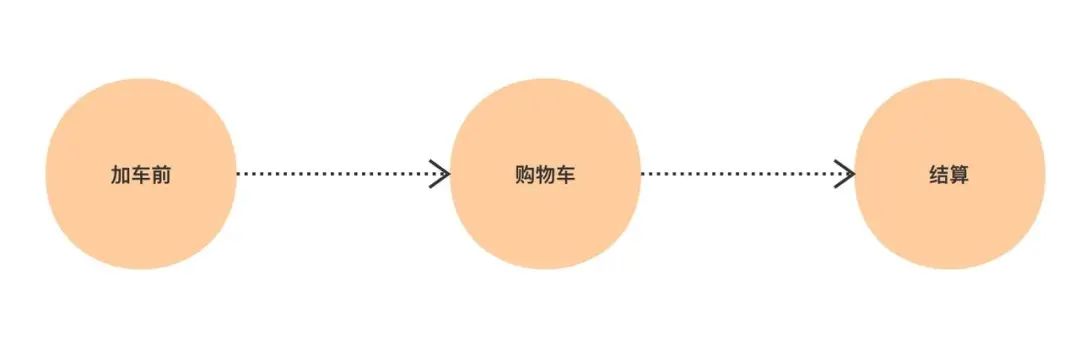
过程
按照这个过程,我们来看一下每个阶段对应的操作。
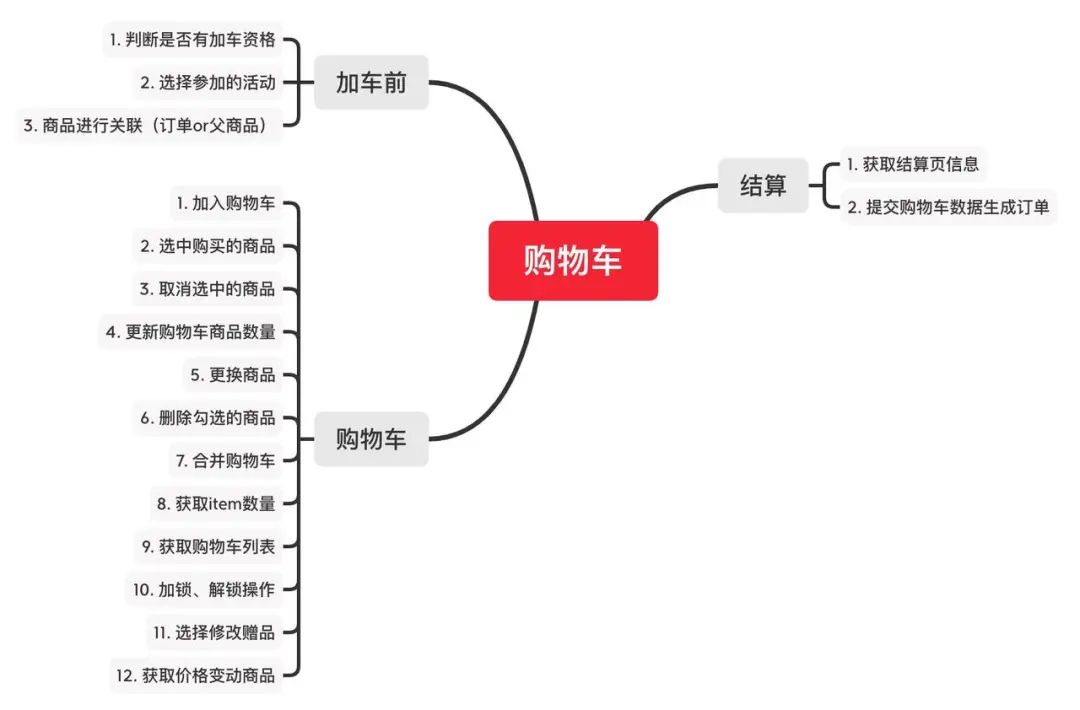
过程对应的操作
这里注意一点,加车前这个操作其实我们可以放到购物车的添加操作中,但是由于这部分是非常不稳定且多变的。我们将其独立出来,方便后续进行扩展而不影响相对比较稳定的购物车阶段。
上面这三个阶段,按照DDD中的概念,应该叫做实体,他们整体构成了购物车这个域;今天我们先不讲这些概念,就先略过,后面有机会单独发文讲解。
加车前
通过流程分析,我们总结出了系统需要具备的操作接口,以及这些接口对应的实体,现在我们先来看加车前主要要做些什么;
加车前其实主要就是对准备加入的购物车商品进行各个纬度的校验,检查是否满足要求。
在让用户加车前,我们首先解决的是用户从哪里卖,然后进行验证?因为同一个商品从不同渠道购买是存在不同情况的,比如:小米手机,我们是通过秒杀买,还是通过好友众筹买,或者商城直接购买,价格存在差异,但是实际上他是同一个商品;
第二个问题是是否具备购买资格,还是上面说的,秒杀、众筹这个加车操作,不是谁都可以添加的,得现有资格。那么资格的检查也是放到这里;
第三个问题是对这个购买的商品进行商品属性上的验证,如是否上下架,有库存,限购数量等等。
而且大家会发现,这里的验证条件可能是非常多变的。如何构建一个方便扩展的代码呢?
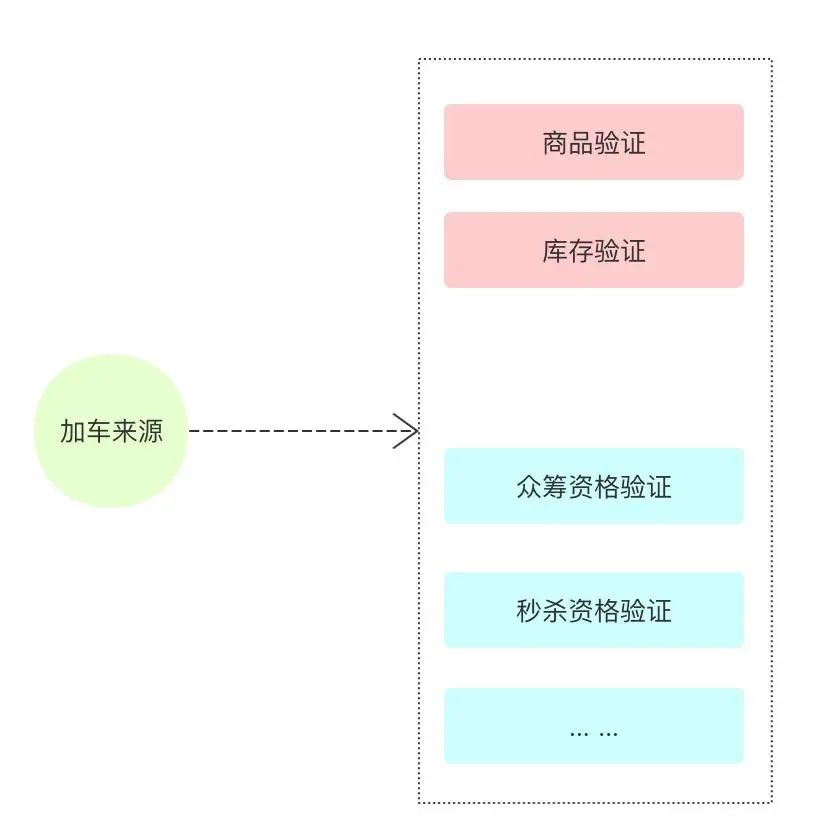
加车的验证
整个加车过程,重要的就是根据来源来区分不同的验证。我们有两种选择方式。
方式一:通过策略模式+门面模式的方式来搞定。策略就是根据不同的加车来源进行不同的验证,门面就是根据不同的来源封装一个个策略;
方式二:通过责任链模式,但是这里需要有一个变化,这个链在执行过程中,可以选择跳过某些节点,比如:秒杀不需要库存、也不需要众筹的验证;
通过综合的分析我选择了责任链的模式。贴一下核心代码
// 每个验证逻辑要实现的接口
type Handler interface {
Skipped(in interface{}) bool // 这里判断是否跳过
HandleRequest(in interface{}) error // 这里进行各种验证
}
// 责任链的节点
type RequestChain struct {
Handler
Next *RequestChain
}
// 设置handler
func (h *RequestChain) SetNextHandler(in *RequestChain) *RequestChain {
h.Next = in
return in
}
关于设计模式,大家可以看我小伙伴的github:
https://github.com/TIGERB/easy-tips/tree/master/go/src/patterns
购物车
说完了加车前,现在来看购物车这一部分。我们在之前曾讨论过,购物车可能会有多种形态的,比如:存储多个商品一起结算,某个商品立即结算等。因此购物车一定会根据渠道来进行购物车类型的选择。
这部分的操作相对是比较稳定的。我们挑几个比较重要的操作来讲一下思路即可。
加入购物车
通过把条件验证的前置,会发现在进行加车操作时,这部分逻辑已经变得非常的轻量了。要做的主要是下面几个部分的逻辑。
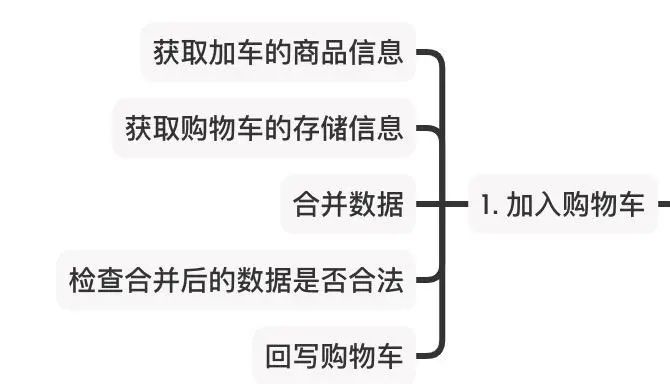
加入购物车
这里有几个取巧的地方,首先是获取商品的逻辑,由于在前面验证的时候也会用到,因此这里前面获取后会通过参数的方式继续往后传递,因此这里不需要在读库或者调用服务来获取;
其次这里需要把当前用户现有购物车数据获取到,然后将添加的这个商品添加进来。这是一个类似合并操作,原来这个商品是存在,相当于数量加一;需要注意这个商品跟现存的商品有没有父子关系,有没有可能加入后改变了某个活动规则,比如:原来买了2个送1个赠品,现在再添加了一个变成3个,送2个赠品;
注意:这里的添加并不是在购物车直接改数量,可能就是在列表、详情页直接添加添加。
通过将合并后的购物车数据,通过营销活动检查确认ok后,直接回写到存储中。
合并购物车
为什么会有合并购物车这个操作?因为一般电商都是准许游客身份进行操作的,因此当用户登录后需要将二者进行合并。
这里的合并很多部分的逻辑是可以与加入购物车复用的逻辑。比如:合并后的数据都需要检查是否合法,然后覆写回存储中。因此大家可以看到这里的关联性。设计的方法在某种程度上要通用。
购物车列表
购物车列表这是一个非常重要的接口,原则上购物车接口会提供两种类型,一种简版,一种完全版本;
简版的列表接口主要是用在类似PC首页右上角之类获取简单信息;完全版本就是在购物车列表中会用到。
在实际实现中,购物车绝不仅仅是一个读取接口那么简单。因为我们都知道不管是商品信息、活动信息都是在不断的发生变化。因此每次的读取接口必然需要检查当前购物车中数据的合法性,然后发现不一致后需要覆写原存储的数据。
购物车列表
也有一些做法会在每个接口都去检查数据的合法性,我建议为了性能考虑,部分接口可以适当放宽检查,在获取列表时再进行完整的检查。比如添加接口,我只会检测我添加的商品的合法性,绝不会对整个购物车进行检查。因为该操作之后一般都会调用列表操作,那么此时还会进行校验,二者重复操作,因此只取后者。
结算
这里另外一个需要注意的是:立即购买,我们也会通过结算页接口来实现,但是内部其实还是会调用添加接口,将商品添加到购物车中;有三个需要注意的地方,首先是这个添加操作是服务内部完成的,对于服务调用方是不需要感知这个加入操作的存在;其次是这个购物车在Redis中的Key是独立于普通购物车的,否则二者的商品耦合在一起非常难于操作处理;最后立即购买的购物车要考虑账号多终端登录的时候,彼此数据不能互相影响,这里可以用每个端的uuid来作为购物车的标记避免这种情况。
购物车的最后一步是生成订单,这一步最要紧的是需要给购物车加锁,避免提交过程中数据被篡改,多说一句,很多人写的Redis分布式锁代码都存在缺陷,大家一定要注意原子性的问题,这类文章网络上很多不再赘述。
加锁成功之后,我们这里有多种做法,一种是按照DB涉及组织数据开始写表,这适用于业务量要求不大,比如订单每秒下单量不超过2000K的;那如果你的系统并发要求非常高怎么办?
其实也很简单,高性能的三大法宝之一:异步;我们提交的时候直接将数据快照写入MQ中,然后通过异步的方式进行消费处理,可以通过通过控制消费者的数量来提升处理能力。这种方法虽然性能提升,但是复杂度也会上升,大家需要根据自己的实际情况来选择。
关于业务架构的设计,到此告一段落,接下来我们来看系统架构。
系统架构
系统结构主要包含,如何将业务架构映射过来,以及输出对应输入参数、输出参数的说明。
由于输入、输出针对各自业务来确定的,而且没有什么难度,我们这里就只说如何将业务架构映射到系统架构,以及系统架构中最核心的Redis数据结构选择以及存储的数据结构设计。
代码结构
下面的代码目录是按照 Golang 来进行设计的。我们来看看如何将上面的业务架构映射到代码层面来。
├── addproducts.go
├── cartlist.go
├── mergecart.go
├── entity
│ ├── cart
│ │ ├── add.go
│ │ ├── cart.go
│ │ └── list.go
│ ├── order
│ │ ├── checkout.go
│ │ ├── order.go
│ │ └── submit.go
│ └── precart
├── event
│ └── sendorder.go
├── facade
│ ├── activity.go
│ └── product.go
└── repo
外层有 entity、event、facade、repo这四个目录,职责如下:
entity: 存放的是我们前面分析的购物领域的三个实体;所有主要的操作都在这三个实体上;
event: 这是用来处理产生的事件,比如刚刚说的如果我们提交订单采用异步的方式,那么该目录就该完成的是如何把数据发送到MQ中去;
facade: 这儿目录是干嘛的呢?这主要是因为我们的服务还需要依赖像商品、营销活动这些服务,那么我们不应该在实体中直接调用它,因为第三方可能存在变动,或者有增加、减少,我们在这里进行以下简单的封装(设计模式中的门面模式);
repo: 这个目录从某种程度上可以理解为 Model层,在整个领域服务中,如果与持久化打交道,都通过它来完成。
最后外层的几个文件,就是我们所提供的领域服务,供应用层来进行调用的。
为了保证内容的紧凑,我这里放弃了对整个微服务的目录介绍,只单独介绍了领域服务,后续会单独成文介绍下微服务的整个系统架构。
通过上面的划分,我们完成了两件事情:
-
业务架构分析的结构在系统代码中都有映射,他们彼此体现。这样最大的好处是,保证设计与代码的一致性,看了文档你就知道对应的代码在哪里;
-
每个目录各自的关注点都进行了分离,更内聚,更容易开发与维护。
Redis存储
现在来看,我们选择Redis作为购物商品数据的存储,我们要解决两个问题,一是我们需要存哪些数据?二是我们用什么结构来存?
网络上很多写购物车的都是只保存一个商品id,真实场景是很难满足需求的。你想想,一个商品id如何记住用户选择的赠品?用户上次选择的活动?以及购买的商品渠道?
综合比较通用的场景,我给出一个参考结构:
// 购物车数据
type ShoppingData struct {
Item []*Item `json:"item"`
UpdateTime int64 `json:"update_time"`
Version int32 `json:"version"`
}
// 单个商品item元素
type Item struct {
ItemId string `json:"item_id"`
ParentItemId string `json:"parent_item_id,omitempty"` // 绑定的父item id
OrderId string `json:"order_id,omitempty"` // 绑定的订单号
Sku int64 `json:"sku"`
Spu int64 `json:"spu"`
Channel string `json:"channel"`
Num int32 `json:"num"`
Status int32 `json:"status"`
TTL int32 `json:"ttl"` // 有效时间
SalePrice float64 `json:"sale_price"` // 记录加车时候的销售价格
SpecialPrice float64 `json:"special_price,omitempty"` // 指定价格加购物车
PostFree bool `json:"post_free,omitempty"` // 是否免邮
Activities []*ItemActivity `json:"activities,omitempty"` // 参加的活动记录
AddTime int64 `json:"add_time"`
UpdateTime int64 `json:"update_time"`
}
// 活动
type ItemActivity struct {
ActID string `json:"act_id"`
ActType string `json:"act_type"`
ActTitle string `json:"act_title"`
}
重点说一下 Item 这个结构,item_id 这个字段是标记购物车中某个商品的唯一标记,因为我们之前说过,同一个sku由于渠道不同,那么在购物车中会是两个不同的item;接下来的 parent_item_id 字段是用来标记父子关系的,这里将可能存在的树结构转成了顺序结构,我们不管是父商品还是子商品,都采用顺序存储,然后通过这个字段来进行关联;有些同学可能会奇怪,为什么会存order id这个字段呢?大家关注下自己的日常业务,比如:再来一单、定金预售等,这种一定是与某个订单相关联的,不管是为了资格验证还是数据统计。剩下的字段都是一些非常常规的字段,就不在一一介绍了;
字段的类型,大家根据自己的需要进行修改。
接下来该说怎么选择Redis的存储结构了,Redis常用的 Hash Table、集合、有序集合、链表、字符串 五种,我们一个个来分析。
首先购车一定有一个key来标记这个购物车属于哪个用户的,为了简化,我们的key假设是:uid:cart_type。
我们先来看如果用 Hash Table;我们添加时,需要用到如下命令:HSET uid:cart_type sku ShoppingData;看起来没问题,我们可以根据sku快速定位某个商品然后进行相关的修改等,但是注意,ShoppingData是一个json串,如果用户购物车中有非常多的商品,我们用 HGETALL uid:cart_type 获取到的时间复杂度是O(n),然后代码中还需要一一反序列化,又是O(n)的复杂度。
如果用集合,也会遇到类似的问题,每个购物车看做一个集合,集合中的每个元素是 ShoppingData ,取到代码中依然需要逐一反序列化(反序列化是成本),关于有序集合与链表就不在分析,大家可以按照上面的思路去尝试下问题所在。
看起来我们没得选,只有使用String,那我们来看一下String的契合度是什么样子。首先SET uid:cart_type ShoppingDataArr;我们把购物车所有的数据序列化成一个字符串存储,每次取出来的时间复杂度是O(1),序列化、反序列化都只需要一次。看来是非常不错的选择。但是在使用中大家还是有几点需要注意。
-
单个Value不能太大,要不然就会出现大key问题,所以一般购物车有上限限制,比如item不能超过多少个;
-
对redis的操作性能提升上来了,但是代码的就是修改单个item时的不便,必须每次读取全部然后找到对应的item进行修改;这里我们可以把从redis中的数据读取出来后,在内存中构建一个HashTable,来减少每次遍历的复杂度;
网上也看到很多Redis数据结构组合使用来保存购物车数据的,但是无疑增加了网络开销,相比起来还是String最经济划算。
总结
至此对于购物车的实现设计算是完结了,其中关于订单表的设计会单独放到订单模块去讲。
对于整个购物车服务,虽然没有写的详细到某个具体的接口,但是分析到这一步,我相信大家心中都是有沟壑的,能够结合自己的业务去实现它。
文中有些很有意思的地方,建议大家动手去做做看,有任何问题,我们随时交流。
-
改编版的责任链模式
-
Redis的分布式事务锁实现
https://juejin.im/post/5e8ac7f06fb9a03c4a496b0d
以上是关于[Skr-Shop]购物车之架构设计的主要内容,如果未能解决你的问题,请参考以下文章
ShoppingDataItem []*Item UpdateTime Version ItemItemId ParentItemId OrderId Sku Spu Channel Num Status TTL SalePrice SpecialPrice PostFree Activities []*ItemActivity AddTime UpdateTime ItemActivityActID ActType ActTitle 这个结构,item_id这个字段是标记购物车中某个商品的唯一标记,因为我们之前说过,同一个sku由于渠道不同,那么在购物车中会是两个不同的item;接下来的parent_item_id字段是用来标记父子关系的,这里将可能存在的树结构转成了顺序结构,我们不管是父商品还是子商品,都采用顺序存储,然后通过这个字段来进行关联;有些同学可能会奇怪,为什么会存order id这个字段呢?大家关注下自己的日常业务,比如:再来一单、定金预售等,这种一定是与某个订单相关联的,不管是为了资格验证还是数据统计。剩下的字段都是一些非常常规的字段,就不在一一介绍了;字段的类型,大家根据自己的需要进行修改。
接下来该说怎么选择Redis的存储结构了,Redis常用的
Hash Table、集合、有序集合、链表、字符串五种,我们一个个来分析。首先购车一定有一个key来标记这个购物车属于哪个用户的,为了简化,我们的key假设是:
uid:cart_type。我们先来看如果用
Hash Table;我们添加时,需要用到如下命令:HSET uid:cart_type sku ShoppingData;看起来没问题,我们可以根据sku快速定位某个商品然后进行相关的修改等,但是注意,ShoppingData是一个json串,如果用户购物车中有非常多的商品,我们用HGETALL uid:cart_type获取到的时间复杂度是O(n),然后代码中还需要一一反序列化,又是O(n)的复杂度。如果用
集合,也会遇到类似的问题,每个购物车看做一个集合,集合中的每个元素是 ShoppingData ,取到代码中依然需要逐一反序列化(反序列化是成本),关于有序集合与链表就不在分析,大家可以按照上面的思路去尝试下问题所在。看起来我们没得选,只有使用
String,那我们来看一下String的契合度是什么样子。首先SET uid:cart_type ShoppingDataArr;我们把购物车所有的数据序列化成一个字符串存储,每次取出来的时间复杂度是O(1),序列化、反序列化都只需要一次。看来是非常不错的选择。但是在使用中大家还是有几点需要注意。
单个Value不能太大,要不然就会出现大key问题,所以一般购物车有上限限制,比如item不能超过多少个; 对redis的操作性能提升上来了,但是代码的就是修改单个item时的不便,必须每次读取全部然后找到对应的item进行修改;这里我们可以把从redis中的数据读取出来后,在内存中构建一个HashTable,来减少每次遍历的复杂度; 网上也看到很多Redis数据结构组合使用来保存购物车数据的,但是无疑增加了网络开销,相比起来还是String最经济划算。
总结
至此对于购物车的实现设计算是完结了,其中关于订单表的设计会单独放到订单模块去讲。
对于整个购物车服务,虽然没有写的详细到某个具体的接口,但是分析到这一步,我相信大家心中都是有沟壑的,能够结合自己的业务去实现它。
文中有些很有意思的地方,建议大家动手去做做看,有任何问题,我们随时交流。
改编版的责任链模式 Redis的分布式事务锁实现 接下来终于要到订单部分的设计了,希望大家继续关注我们。
购物车之架构设计
skr shop是一群底层码农,由于被工作中的项目折磨的精神失常,加之由于程序员的自傲:别人设计的系统都是一坨shit,我的设计才是宇宙最牛逼,于是乎决定要做一个只设计不编码的电商设计手册。
在上一篇文章 购物车设计之需求分析 描述了购物车的通用需求。本文重点则在如何实现上进行架构上的设计(业务+系统架构)。
说明
-
业务架构 -
系统架构 -
技术架构
快速简单的说明下三个架构的意思;当我们拿到购物车需求时,我们说用Golang来实现,存储用Redis;这描述的是技术架构;我们对购物车代码项目进行代码分层,设计规范,以及依赖系统的规划这叫系统架构;
那业务架构是什么呢?业务架构本质上是对系统架构的文字语言描述;什么意思?我们拿到一个需求首先要跟需求方进行沟通,建立统一的认知。比如:规范名词(购物车中说的商品与商品系统中商品的含义是不同的);建立大家都能明白的模型,购物车、用户、商品、订单这些实体之间的互动,以及各自具备什么功能。
在业务架构分析上有很多方法论,比如:领域驱动设计,但是它并不是唯一的业务架构分析方法,也并不是说最好的。适合你的就是最好的。我们常用的实体关系图、UML图也属于业务架构领域;
这里需要强点一点的是,不管你用什么方式来建模设计,有设计总比没设计强,其次一定要将建模的内容体现到你的代码中去。
本文在业务架构上的分析借助了 DDD (领域驱动设计)思想;还是那句话适合的就是最好的。
业务架构
在这个过程中,用户使用购物车这个载体完成了商品的购买流程;不断流动的数据是商品,购物车这个载体是稳定的。这是我们系统中的稳定点与变化点。
商品的流动方式可能多种多样,比如从不同地方加入购物车,不同方式加入购物车,生命周期在购物车中也不一样;但是这个流程是稳定的,一定是先让购物车中存在商品,然后才能去结算产生订单。
商品在购物车中的生命周期如下:
按照这个过程,我们来看一下每个阶段对应的操作。
这里注意一点,加车前这个操作其实我们可以放到购物车的添加操作中,但是由于这部分是非常不稳定且多变的。我们将其独立出来,方便后续进行扩展而不影响相对比较稳定的购物车阶段。
上面这三个阶段,按照DDD中的概念,应该叫做实体,他们整体构成了购物车这个域;今天我们先不讲这些概念,就先略过,后面有机会单独发文讲解。
加车前
通过流程分析,我们总结出了系统需要具备的操作接口,以及这些接口对应的实体,现在我们先来看加车前主要要做些什么;
加车前其实主要就是对准备加入的购物车商品进行各个纬度的校验,检查是否满足要求。
在让用户加车前,我们首先解决的是用户从哪里卖,然后进行验证?因为同一个商品从不同渠道购买是存在不同情况的,比如:小米手机,我们是通过秒杀买,还是通过好友众筹买,或者商城直接购买,价格存在差异,但是实际上他是同一个商品;
第二个问题是是否具备购买资格,还是上面说的,秒杀、众筹这个加车操作,不是谁都可以添加的,得现有资格。那么资格的检查也是放到这里;
第三个问题是对这个购买的商品进行商品属性上的验证,如是否上下架,有库存,限购数量等等。
而且大家会发现,这里的验证条件可能是非常多变的。如何构建一个方便扩展的代码呢?
整个加车过程,重要的就是根据来源来区分不同的验证。我们有两种选择方式。
方式一:通过策略模式+门面模式的方式来搞定。策略就是根据不同的加车来源进行不同的验证,门面就是根据不同的来源封装一个个策略;
方式二:通过责任链模式,但是这里需要有一个变化,这个链在执行过程中,可以选择跳过某些节点,比如:秒杀不需要库存、也不需要众筹的验证;
通过综合的分析我选择了责任链的模式。贴一下核心代码
// 每个验证逻辑要实现的接口
type Handler interface {
Skipped(in interface{}) bool // 这里判断是否跳过
HandleRequest(in interface{}) error // 这里进行各种验证
}
// 责任链的节点
type RequestChain struct {
Handler
Next *RequestChain
}
// 设置handler
func (h *RequestChain) SetNextHandler(in *RequestChain) *RequestChain {
h.Next = in
return in
}
关于设计模式,大家可以看我小伙伴的github:
https://github.com/TIGERB/easy-tips/tree/master/go/src/patterns
购物车
说完了加车前,现在来看购物车这一部分。我们在之前曾讨论过,购物车可能会有多种形态的,比如:存储多个商品一起结算,某个商品立即结算等。因此购物车一定会根据渠道来进行购物车类型的选择。
这部分的操作相对是比较稳定的。我们挑几个比较重要的操作来讲一下思路即可。
加入购物车
通过把条件验证的前置,会发现在进行加车操作时,这部分逻辑已经变得非常的轻量了。要做的主要是下面几个部分的逻辑。
这里有几个取巧的地方,首先是获取商品的逻辑,由于在前面验证的时候也会用到,因此这里前面获取后会通过参数的方式继续往后传递,因此这里不需要在读库或者调用服务来获取;
其次这里需要把当前用户现有购物车数据获取到,然后将添加的这个商品添加进来。这是一个类似合并操作,原来这个商品是存在,相当于数量加一;需要注意这个商品跟现存的商品有没有父子关系,有没有可能加入后改变了某个活动规则,比如:原来买了2个送1个赠品,现在再添加了一个变成3个,送2个赠品;
注意:这里的添加并不是在购物车直接改数量,可能就是在列表、详情页直接添加添加。
通过将合并后的购物车数据,通过营销活动检查确认ok后,直接回写到存储中。
合并购物车
为什么会有合并购物车这个操作?因为一般电商都是准许游客身份进行操作的,因此当用户登录后需要将二者进行合并。
这里的合并很多部分的逻辑是可以与加入购物车复用的逻辑。比如:合并后的数据都需要检查是否合法,然后覆写回存储中。因此大家可以看到这里的关联性。设计的方法在某种程度上要通用。
购物车列表
购物车列表这是一个非常重要的接口,原则上购物车接口会提供两种类型,一种简版,一种完全版本;
简版的列表接口主要是用在类似PC首页右上角之类获取简单信息;完全版本就是在购物车列表中会用到。
在实际实现中,购物车绝不仅仅是一个读取接口那么简单。因为我们都知道不管是商品信息、活动信息都是在不断的发生变化。因此每次的读取接口必然需要检查当前购物车中数据的合法性,然后发现不一致后需要覆写原存储的数据。
也有一些做法会在每个接口都去检查数据的合法性,我建议为了性能考虑,部分接口可以适当放宽检查,在获取列表时再进行完整的检查。比如添加接口,我只会检测我添加的商品的合法性,绝不会对整个购物车进行检查。因为该操作之后一般都会调用列表操作,那么此时还会进行校验,二者重复操作,因此只取后者。
结算
这里另外一个需要注意的是:立即购买,我们也会通过结算页接口来实现,但是内部其实还是会调用添加接口,将商品添加到购物车中;有三个需要注意的地方,首先是这个添加操作是服务内部完成的,对于服务调用方是不需要感知这个加入操作的存在;其次是这个购物车在Redis中的Key是独立于普通购物车的,否则二者的商品耦合在一起非常难于操作处理;最后立即购买的购物车要考虑账号多终端登录的时候,彼此数据不能互相影响,这里可以用每个端的uuid来作为购物车的标记避免这种情况。
购物车的最后一步是生成订单,这一步最要紧的是需要给购物车加锁,避免提交过程中数据被篡改,多说一句,很多人写的Redis分布式锁代码都存在缺陷,大家一定要注意原子性的问题,这类文章网络上很多不再赘述。
加锁成功之后,我们这里有多种做法,一种是按照DB涉及组织数据开始写表,这适用于业务量要求不大,比如订单每秒下单量不超过2000K的;那如果你的系统并发要求非常高怎么办?
其实也很简单,高性能的三大法宝之一:异步;我们提交的时候直接将数据快照写入MQ中,然后通过异步的方式进行消费处理,可以通过通过控制消费者的数量来提升处理能力。这种方法虽然性能提升,但是复杂度也会上升,大家需要根据自己的实际情况来选择。
关于业务架构的设计,到此告一段落,接下来我们来看系统架构。
系统架构
代码结构
下面的代码目录是按照 Golang 来进行设计的。我们来看看如何将上面的业务架构映射到代码层面来。
├── addproducts.go
├── cartlist.go
├── mergecart.go
├── entity
│ ├── cart
│ │ ├── add.go
│ │ ├── cart.go
│ │ └── list.go
│ ├── order
│ │ ├── checkout.go
│ │ ├── order.go
│ │ └── submit.go
│ └── precart
├── event
│ └── sendorder.go
├── facade
│ ├── activity.go
│ └── product.go
└── repo
外层有 entity、event、facade、repo这四个目录,职责如下:
entity: 存放的是我们前面分析的购物领域的三个实体;所有主要的操作都在这三个实体上;
event: 这是用来处理产生的事件,比如刚刚说的如果我们提交订单采用异步的方式,那么该目录就该完成的是如何把数据发送到MQ中去;
facade: 这儿目录是干嘛的呢?这主要是因为我们的服务还需要依赖像商品、营销活动这些服务,那么我们不应该在实体中直接调用它,因为第三方可能存在变动,或者有增加、减少,我们在这里进行以下简单的封装(设计模式中的门面模式);
repo: 这个目录从某种程度上可以理解为 Model层,在整个领域服务中,如果与持久化打交道,都通过它来完成。
最后外层的几个文件,就是我们所提供的领域服务,供应用层来进行调用的。
为了保证内容的紧凑,我这里放弃了对整个微服务的目录介绍,只单独介绍了领域服务,后续会单独成文介绍下微服务的整个系统架构。
通过上面的划分,我们完成了两件事情:
-
业务架构分析的结构在系统代码中都有映射,他们彼此体现。这样最大的好处是,保证设计与代码的一致性,看了文档你就知道对应的代码在哪里;
-
每个目录各自的关注点都进行了分离,更内聚,更容易开发与维护。
Redis存储
现在来看,我们选择Redis作为购物商品数据的存储,我们要解决两个问题,一是我们需要存哪些数据?二是我们用什么结构来存?
网络上很多写购物车的都是只保存一个商品id,真实场景是很难满足需求的。你想想,一个商品id如何记住用户选择的赠品?用户上次选择的活动?以及购买的商品渠道?
综合比较通用的场景,我给出一个参考结构:
// 购物车数据
type ShoppingData struct {
Item []*Item `json:"item"`
UpdateTime int64 `json:"update_time"`
Version int32 `json:"version"`
}
// 单个商品item元素
type Item struct {
ItemId string `json:"item_id"`
ParentItemId string `json:"parent_item_id,omitempty"` // 绑定的父item id
OrderId string `json:"order_id,omitempty"` // 绑定的订单号
Sku int64 `json:"sku"`
Spu int64 `json:"spu"`
Channel string `json:"channel"`
Num int32 `json:"num"`
Status int32 `json:"status"`
TTL int32 `json:"ttl"` // 有效时间
SalePrice float64 `json:"sale_price"` // 记录加车时候的销售价格
SpecialPrice float64 `json:"special_price,omitempty"` // 指定价格加购物车
PostFree bool `json:"post_free,omitempty"` // 是否免邮
Activities []*ItemActivity `json:"activities,omitempty"` // 参加的活动记录
AddTime int64 `json:"add_time"`
UpdateTime int64 `json:"update_time"`
}
// 活动
type ItemActivity struct {
ActID string `json:"act_id"`
ActType string `json:"act_type"`
ActTitle string `json:"act_title"`
}
重点说一下 Item 这个结构,item_id 这个字段是标记购物车中某个商品的唯一标记,因为我们之前说过,同一个sku由于渠道不同,那么在购物车中会是两个不同的item;接下来的 parent_item_id 字段是用来标记父子关系的,这里将可能存在的树结构转成了顺序结构,我们不管是父商品还是子商品,都采用顺序存储,然后通过这个字段来进行关联;有些同学可能会奇怪,为什么会存order id这个字段呢?大家关注下自己的日常业务,比如:再来一单、定金预售等,这种一定是与某个订单相关联的,不管是为了资格验证还是数据统计。剩下的字段都是一些非常常规的字段,就不在一一介绍了;
字段的类型,大家根据自己的需要进行修改。
接下来该说怎么选择Redis的存储结构了,Redis常用的 Hash Table、集合、有序集合、链表、字符串 五种,我们一个个来分析。
首先购车一定有一个key来标记这个购物车属于哪个用户的,为了简化,我们的key假设是:uid:cart_type。
我们先来看如果用 Hash Table;我们添加时,需要用到如下命令:HSET uid:cart_type sku ShoppingData;看起来没问题,我们可以根据sku快速定位某个商品然后进行相关的修改等,但是注意,ShoppingData是一个json串,如果用户购物车中有非常多的商品,我们用 HGETALL uid:cart_type 获取到的时间复杂度是O(n),然后代码中还需要一一反序列化,又是O(n)的复杂度。
如果用集合,也会遇到类似的问题,每个购物车看做一个集合,集合中的每个元素是 ShoppingData ,取到代码中依然需要逐一反序列化(反序列化是成本),关于有序集合与链表就不在分析,大家可以按照上面的思路去尝试下问题所在。
看起来我们没得选,只有使用String,那我们来看一下String的契合度是什么样子。首先SET uid:cart_type ShoppingDataArr;我们把购物车所有的数据序列化成一个字符串存储,每次取出来的时间复杂度是O(1),序列化、反序列化都只需要一次。看来是非常不错的选择。但是在使用中大家还是有几点需要注意。
-
单个Value不能太大,要不然就会出现大key问题,所以一般购物车有上限限制,比如item不能超过多少个; -
对redis的操作性能提升上来了,但是代码的就是修改单个item时的不便,必须每次读取全部然后找到对应的item进行修改;这里我们可以把从redis中的数据读取出来后,在内存中构建一个HashTable,来减少每次遍历的复杂度;
网上也看到很多Redis数据结构组合使用来保存购物车数据的,但是无疑增加了网络开销,相比起来还是String最经济划算。
总结
对于整个购物车服务,虽然没有写的详细到某个具体的接口,但是分析到这一步,我相信大家心中都是有沟壑的,能够结合自己的业务去实现它。
文中有些很有意思的地方,建议大家动手去做做看,有任何问题,我们随时交流。
-
改编版的责任链模式 -
Redis的分布式事务锁实现
https://juejin.im/post/5e8ac7f06fb9a03c4a496b0d
以上是关于[Skr-Shop]购物车之架构设计的主要内容,如果未能解决你的问题,请参考以下文章