CentOS7.6搭建Hadoop2.7.2运行环境-三节点集群模式
Posted 莲藕淹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CentOS7.6搭建Hadoop2.7.2运行环境-三节点集群模式相关的知识,希望对你有一定的参考价值。
Hadoop集群搭建记录 | 云计算[CentOS7] | 伪分布式集群 Master运行WordCount
本文目录
写在前面
本系列文章索引以及一些默认好的条件在 传送门
step1 eclipse访问hadoop
首先需要明确eclipse安装目录,然后将hadoop-eclipse-plugin_版本号.jar插件放在安装目录的dropins下

关于插件,可以通过博主上传到csdn的免费资源获取,链接
具体版本可以自己选择:

step2 重启并配置eclipse
在eclipse界面中依次选择:Window→show view→other→MapReduce Tools/Map/Reduce Locations

然后在界面上会显示一个大象符号,如下图:
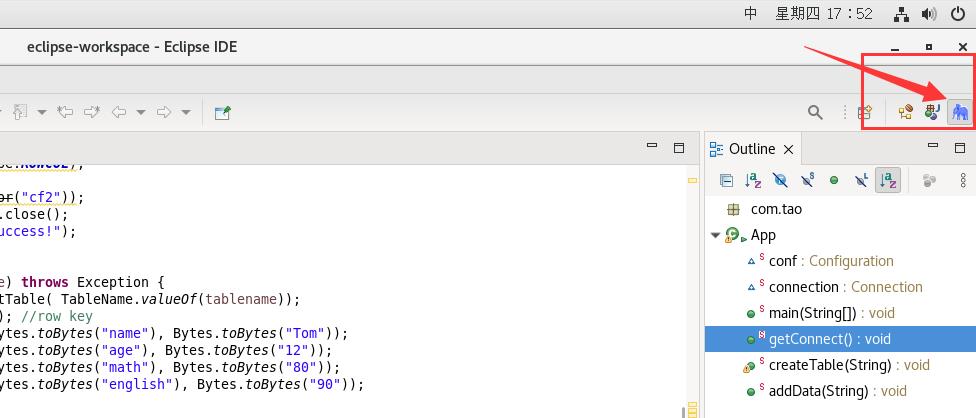
点击大象符号,然后就会配置一个DFS Location
配置参数为:
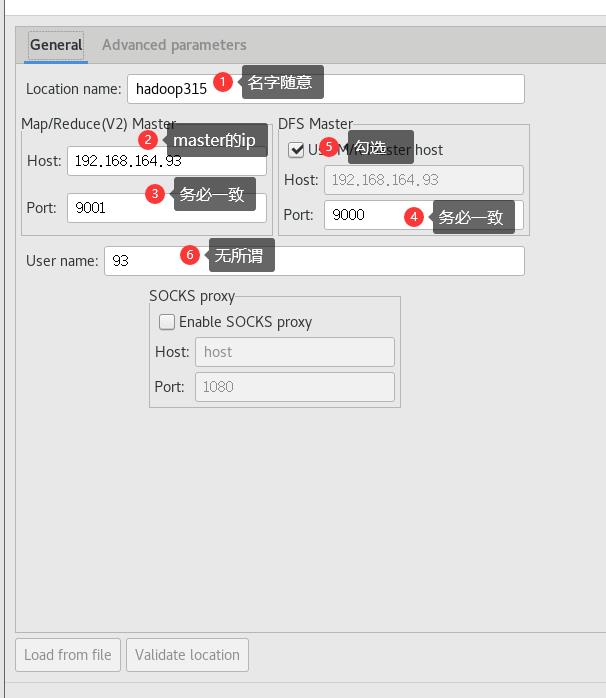
配置好后点击finish
然后会出现:

step3 新建Map/Reduce项目
在Eclipse中依次选择File→New→Other…→Map/Reduce Project→Next,
输入项目名TestWordCount,浏览并选择Hadoop路径/usr/local/hadoop,单击“Finish”按钮,则新建项目TestWordCount成功
新建包并在包下创建相应的类,具体项目结构如下:

step4 复制粘贴代码
package wordCount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount
public static class WordCountMapper extends Mapper<Object, Text, Text, IntWritable>
/**
* 定义final 静态变量one,用来标示键值对<String,One>
* 然后定义Text类型的变量来存储字符串
*/
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) //
word.set(itr.nextToken());
/**
* 写入键值对
*/
context.write(word, one);
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException
int sum = 0;
for (IntWritable val : values)
sum += val.get();
result.set(sum);
context.write(key, result);
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
if (args.length != 2)
System.err.println("Usage: <in> <out>");
System.exit(2);
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setCombinerClass(WordCountReducer.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
step5 配置运行参数
启动hadoop集群后在终端写入:
hadoop fs -mkdir /tmp
hadoop fs -chmod -R 777 /tmp
Run→Run Configurations选项,以配置输入输出参数
大致为:

点击run直接跑
然后在左侧的目录下会显示文件夹:

点进去看下part-r-00000文件就会发现,该文件存储结果:

其中输入为:

结果与预期一致,项目成功~
整个hadoop就到此结束啦
以上是关于CentOS7.6搭建Hadoop2.7.2运行环境-三节点集群模式的主要内容,如果未能解决你的问题,请参考以下文章