机器学习基础常用激活函数(激励函数)理解与总结
Posted 机器学习初学者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习基础常用激活函数(激励函数)理解与总结相关的知识,希望对你有一定的参考价值。
引言
学习神经网络的时候我们总是听到激活函数这个词,而且很多资料都会提到常用的激活函数,比如Sigmoid函数、tanh函数、Relu函数。那么我们就来详细了解下激活函数方方面面的知识。
1. 什么是激活函数?
2. 激活函数的用途(为什么需要激活函数)?
3. 有哪些激活函数,都有什么性质和特点?
4. 应用中如何选择合适的激活函数?
如果你对以上几个问题不是很清楚,下面的内容对你是有价值的。
01
什么是激活函数?
首先要了解神经网络的基本模型。(不熟悉的同学没关系,很快我会更新一篇介绍:人工神经网络基本原理)
单一神经元模型如下图所示:
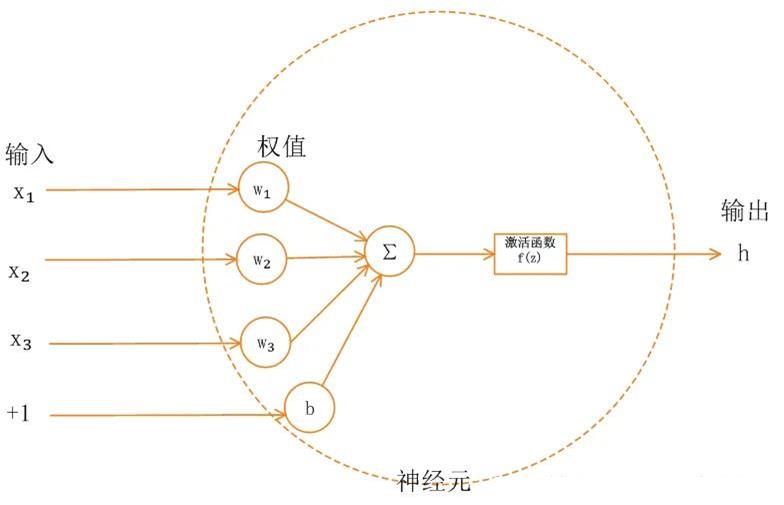
神经网络中的每个神经元节点接受上一层神经元的输出值作为本神经元的输入值,并将输入值传递给下一层,输入层神经元节点会将输入属性值直接传递给下一层(隐层或输出层)。在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数(又称激励函数)。
02
为什么需要激活函数?
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层节点的输入都是上层输出的线性函数。很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了,那么网络的逼近能力就相当有限。正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络表达能力就更加强大(不再是输入的线性组合,而是几乎可以逼近任意函数)。
03
有哪些激活函数
早期研究神经网络主要采用sigmoid函数或者tanh函数,输出有界,很容易充当下一层的输入。近些年Relu函数及其改进型(如Leaky-ReLU、P-ReLU、R-ReLU等)在多层神经网络中应用比较多。
下面我们来总结下这些激活函数:
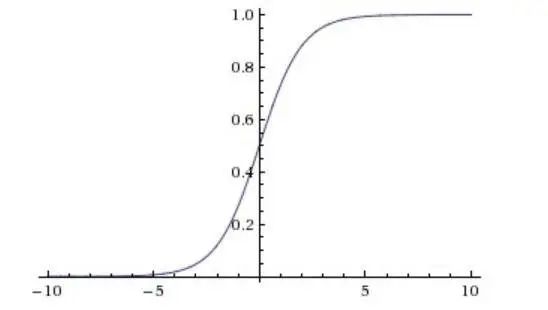
Sigmoid函数
Sigmoid的几何图像如下:
特点:
它能够把输入的连续实值变换为0和1之间的输出,特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1.
缺点:
sigmoid函数曾经被使用的很多,不过近年来,用它的人越来越少了。主要是因为它固有的一些 缺点。
缺点1:在深度神经网络中梯度反向传递时导致梯度爆炸和梯度消失,其中梯度爆炸发生的概率非常小,而梯度消失发生的概率比较大。
首先来看Sigmoid函数的导数,如下图所示:
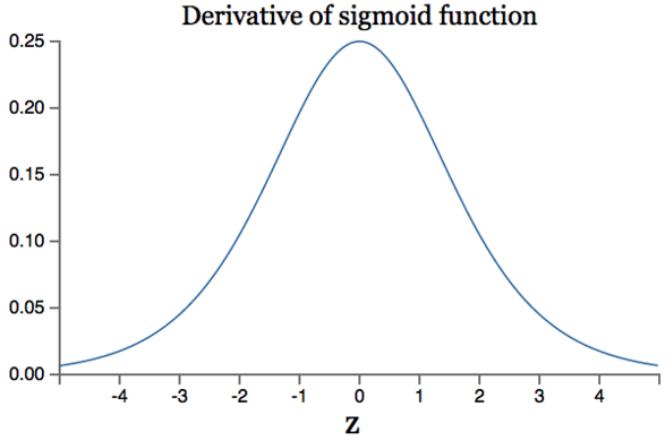
如果我们初始化神经网络的权值为[0,1] 之间的随机值,由反向传播算法的数学推导可知,梯度从后向前传播时,每传递一层梯度值都会减小为原来的0.25倍,如果神经网络隐层特别多,那么梯度在穿过多层后将变得非常小接近于0,即出现梯度消失现象;当网络权值初始化为 (1,+∞)区间内的值,则会出现梯度爆炸情况。
详细数学分析见文章:http://neuralnetworksanddeeplearning.com/chap5.html 中文译文:深度神经网络为何很难训练。关于反向传播BP算法我也会在之后的文章中,给大家详细介绍。
缺点2:Sigmoid 的 output 不是0均值(即zero-centered)。这是不可取的,因为这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。 产生的一个结果就是:如x>0,
缺点3:其解析式中含有幂运算,计算机求解时相对来讲比较耗时。对于规模比较大的深度网络,这会较大地增加训练时间。
tanh函数
tanh函数及其导数的几何图像如下图:
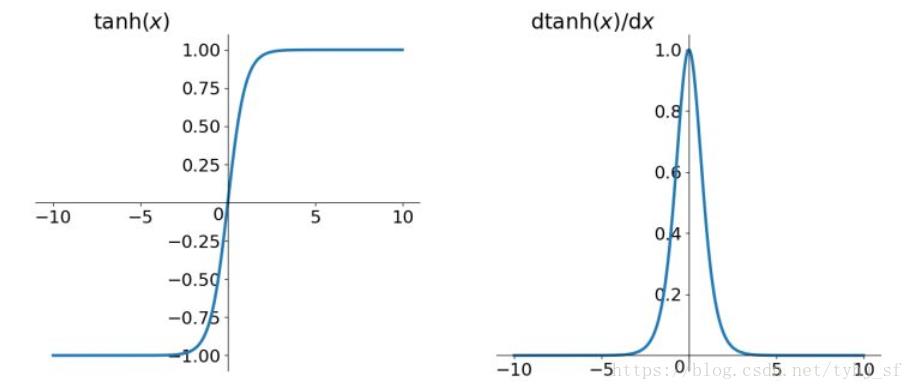
tanh读作Hyperbolic Tangent,它解决了Sigmoid函数的不是zero-centered输出问题,然而,梯度消失(gradient vanishing)的问题和幂运算的问题仍然存在。
Relu函数
Relu函数的解析式:
Relu函数及其导数的图像如下图所示:
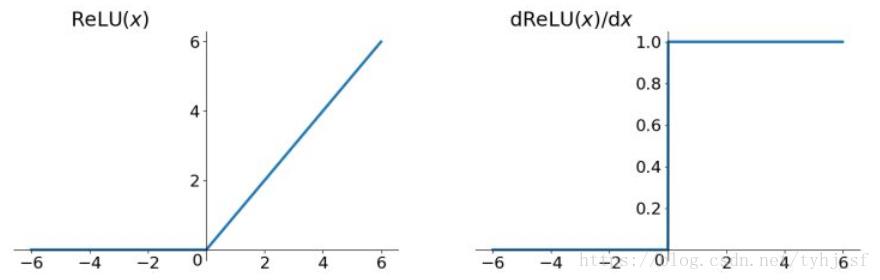
ReLU函数其实就是一个取最大值函数,注意这并不是全区间可导的,但是我们可以取sub-gradient,如上图所示。
ReLU虽然简单,但却是近几年的重要成果,有以下几大优点:
1)相比起Sigmoid和tanh,ReLU在SGD中能够快速收敛。
2)Sigmoid和tanh涉及了很多很expensive的操作(比如指数),ReLU可以更加简单的实现。
3)有效缓解了梯度消失的问题。
4)在没有无监督预训练的时候也能有较好的表现。
5)提供了神经网络的稀疏表达能力。
ReLU也有几个需要特别注意的问题:
1)ReLU的输出不是zero-centered
2)Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生: ①非常不幸的参数初始化,这种情况比较少见;②learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
尽管存在这两个问题,ReLU目前仍是最常用的activation function,在搭建人工神经网络的时候推荐优先尝试!
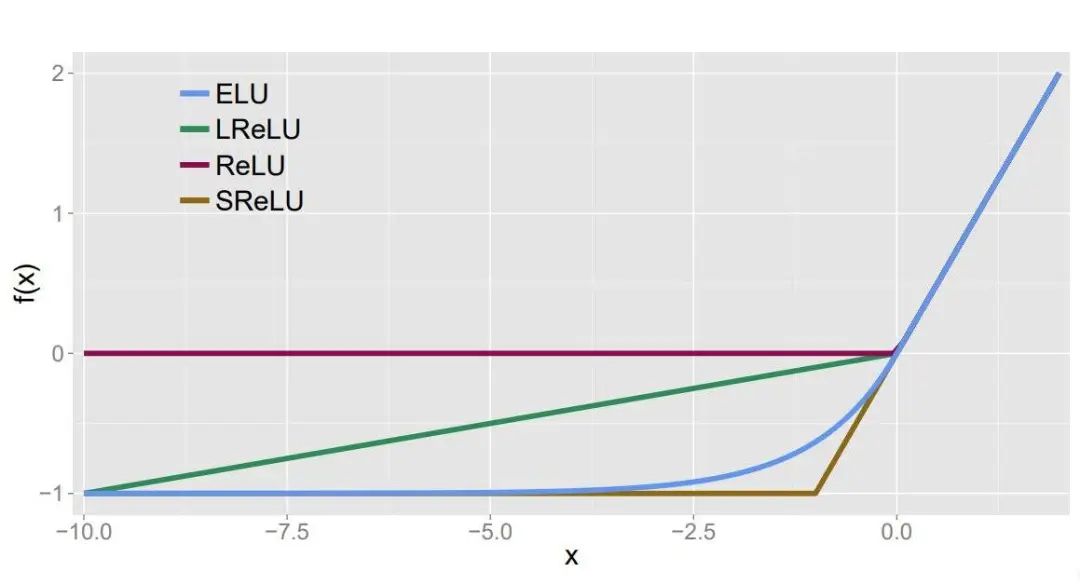
Leaky ReLU函数(PReLU)
函数表达式:
Leaky Relu函数及其导数的图像如下图所示:
(有社友私信反映下图有误,其实没有错误,左半边直线斜率非常接近0(
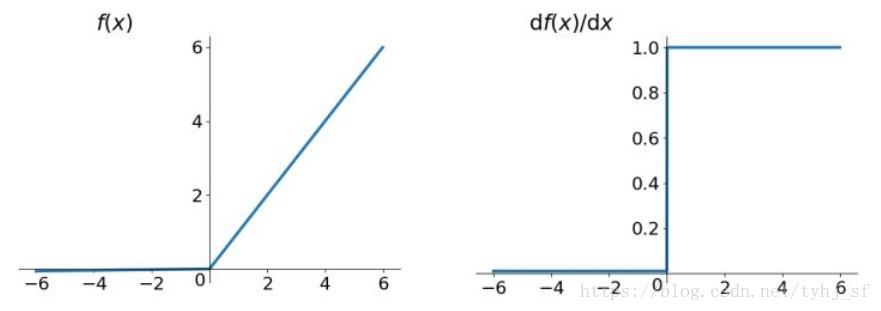
人们为了解决Dead ReLU Problem,提出了将ReLU的前半段设为
ELU (Exponential Linear Units) 函数
函数及其导数的图像如下图所示:
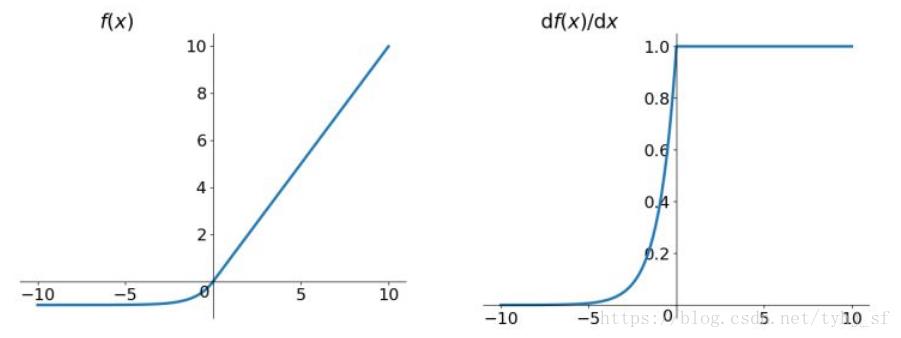
ELU也是为解决ReLU存在的问题而提出,显然,ELU有ReLU的基本所有优点,以及:
不会有Dead ReLU问题
输出的均值接近0,zero-centered
它的一个小问题在于计算量稍大。类似于Leaky ReLU,理论上虽然好于ReLU,但在实际使用中目前并没有好的证据ELU总是优于ReLU。
LReLU、PReLU与RReLU对比
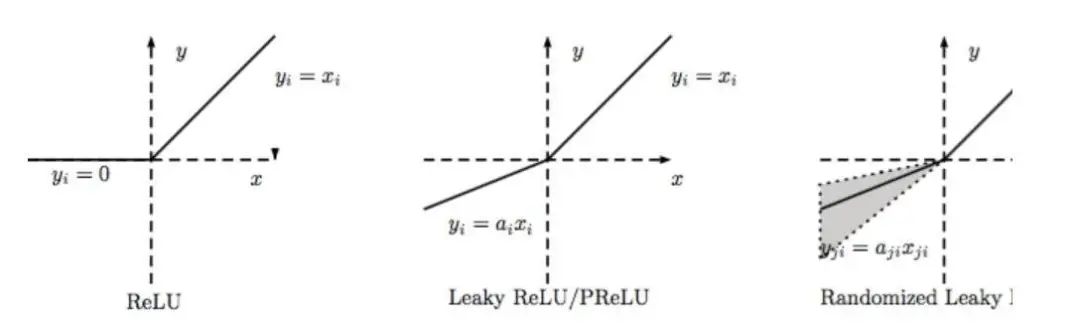
通常在LReLU和PReLU中,我们定义一个激活函数为:
LReLU 当ai比较小而且固定的时候,我们称之为LReLU。LReLU最初的目的是为了避免梯度消失。但在一些实验中,我们发现LReLU对准确率并没有太大的影响。很多时候,当我们想要应用LReLU时,我们必须要非常小心谨慎地重复训练,选取出合适的a,LReLU的表现出的结果才比ReLU好。因此有人提出了一种自适应地从数据中学习参数的PReLU。
PReLU PReLU是LReLU的改进,可以自适应地从数据中学习参数。PReLU具有收敛速度快、错误率低的特点。PReLU可以用于反向传播的训练,可以与其他层同时优化。
如图所示,其中α是一个可调整的参数,它控制着ELU负值部分在何时饱和。
MaxOut函数
这个函数可以参考论文《maxout networks》https://arxiv.org/pdf/1302.4389v4.pdf,Maxout是深度学习网络中的一层网络,就像池化层、卷积层一样等,我们可以把maxout 看成是网络的激活函数层,我们假设网络某一层的输入特征向量为:X=(x1,x2,……xd),也就是我们输入是d个神经元。Maxout隐藏层每个神经元的计算公式如下:
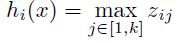
上面的公式就是maxout隐藏层神经元i的计算公式。其中,k就是maxout层所需要的参数了,由我们人为设定大小。就像dropout一样,也有自己的参数p(每个神经元dropout概率),maxout的参数是k。公式中Z的计算公式为:
权重w是一个大小为(d,m,k)三维矩阵,b是一个大小为(m,k)的二维矩阵,这两个就是我们需要学习的参数。如果我们设定参数k=1,那么这个时候,网络就类似于以前我们所学普通的MLP网络。
我们可以这么理解,本来传统的MLP算法在第i层到第i+1层,参数只有一组,然而现在我们不这么干了,我们在这一层同时训练n组的w、b参数,然后选择激活值Z最大的作为下一层神经元的激活值,这个
表1 常用激活函数汇总表
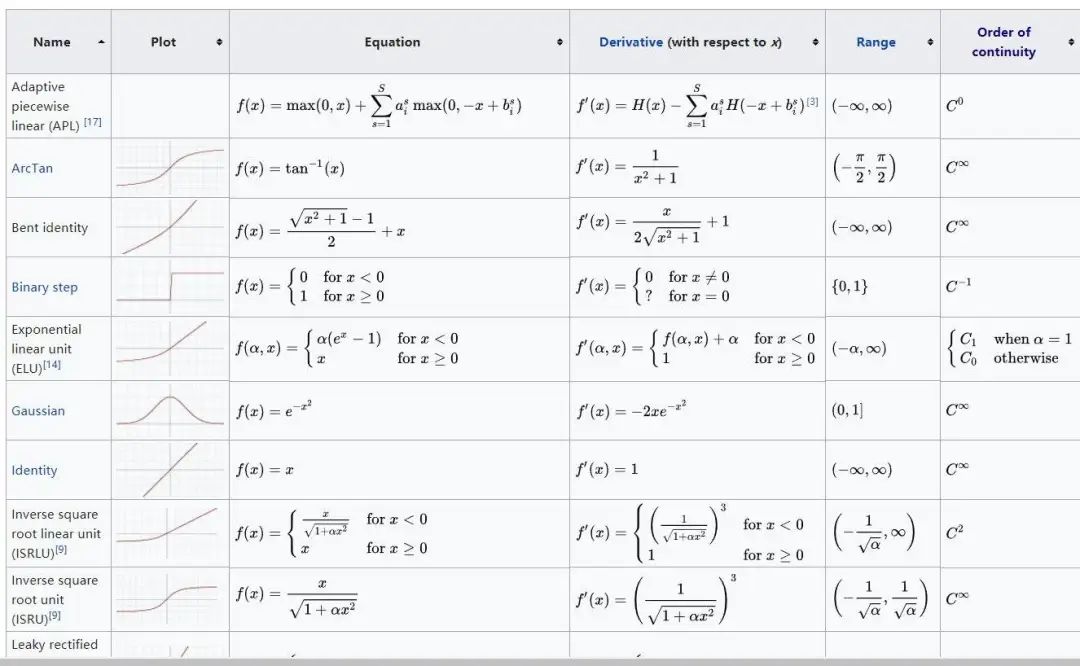


来源:维基百科
接下来是我们在实际操作中最关心的问题,如何选择合适的激活函数?
04
如何选择合适的激活函数?
这个问题目前没有确定的方法,凭一些经验吧。以下来自个人和网友的经验总结:
1)深度学习往往需要大量时间来处理大量数据,模型的收敛速度是尤为重要的。所以,总体上来讲,训练深度学习网络尽量使用zero-centered数据 (可以经过数据预处理实现) 和zero-centered输出。所以要尽量选择输出具有zero-centered特点的激活函数以加快模型的收敛速度。
2)如果使用 ReLU,那么一定要小心设置 learning rate,而且要注意不要让网络出现很多 “dead” 神经元,如果这个问题不好解决,那么可以试试 Leaky ReLU、PReLU 或者 Maxout.
3)最好不要用 sigmoid,你可以试试 tanh,不过可以预期它的效果会比不上 ReLU 和 Maxout.
另外,关于这方面的经验,之前发布Gray大佬的Kaggle经验总结中也有很值得推荐的方法,非常实用有效。
参考资料
1.聊一聊深度学习的activation function—夏飞https://zhuanlan.zhihu.com/p/25110450
2.【机器学习】神经网络-激活函数-面面观(Activation Function)
3. maxout简单理解-tornadomeet
4.《maxout networks》



愉快的每一天
往期精彩回顾
本站qq群704220115,加入微信群请扫码:
以上是关于机器学习基础常用激活函数(激励函数)理解与总结的主要内容,如果未能解决你的问题,请参考以下文章