xpath解析案例
Posted 秋泊ソース
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了xpath解析案例相关的知识,希望对你有一定的参考价值。
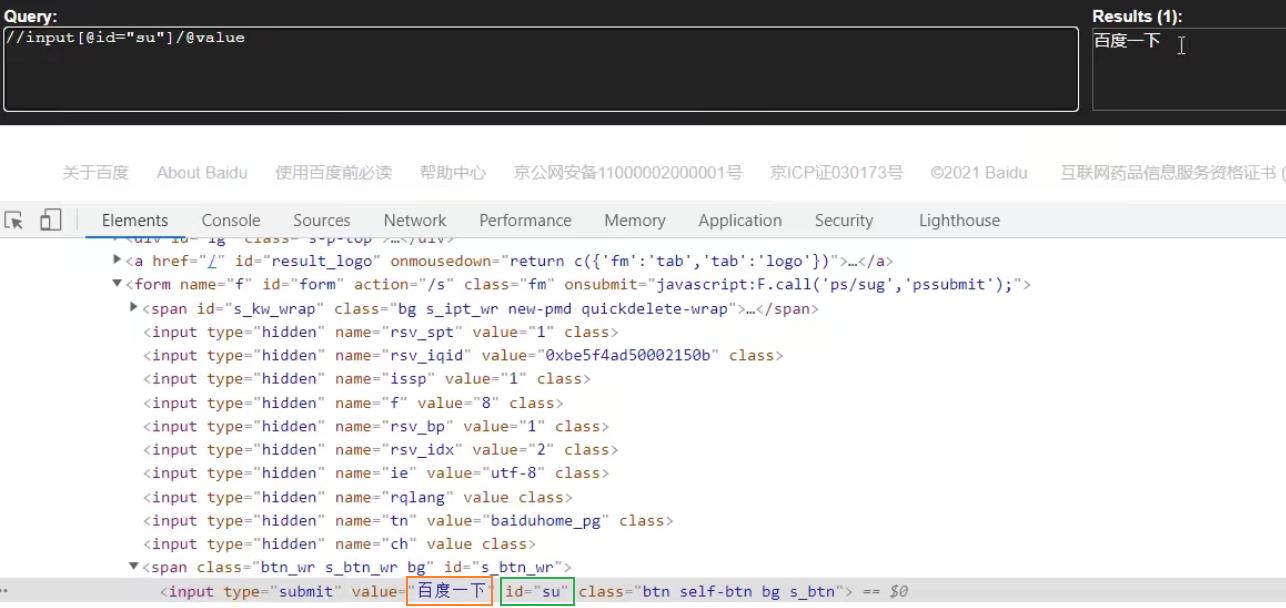
xpath解析百度页面的百度一下
# 1)获取网页的源码 # 2)解析的服务器响应的文件 etree.html # 3)打印 import urllib.request # 请求地址 url = \'https://www.baidu.com/\' # 请求头 headers = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36\' } # 请求对象的定制 request = urllib.request.Request(url = url, headers = headers) # 模拟浏览器访问服务器 response = urllib.request.urlopen(request) # 获取网页源码 content = response.read().decode(\'utf-8\') # 解析网页源码 来获取我们想要的数据 from lxml import etree # 解析服务器响应的文件 tree = etree.HTML(content) # 获取想要的数据 xpath的返回值是一个列表类型的数据 result = tree.xpath(\'//input[@id="su"]/@value\')[0] print(result)

xpath案例 爬取58出租房源信息&解析下载图片数据&乱码问题
58二手房解析房源名称
from lxml import etree import requests url = ‘https://haikou.58.com/chuzu/j2/‘ headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Mobile Safari/537.36‘ } parser = etree.HTMLParser(encoding=‘utf-8‘) page_text = requests.get(url=url).text tree = etree.HTML(page_text,parser=parser) lis = tree.xpath(‘//ul[@class="house-list"]/li‘) for li_item in lis: res=li_item.xpath(‘.//h2/a/text()‘) #注意 ./ print(res[0].strip())
爬取彼岸图网图片
from lxml import etree import requests url = ‘http://pic.netbian.com/4kfengjing‘ headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Mobile Safari/537.36‘ } parser = etree.HTMLParser(encoding=‘utf-8‘) page_text = requests.get(url=url,headers=headers).text tree = etree.HTML(page_text,parser=parser) res = tree.xpath(‘//div[@class="slist"]//li/a/img/@src‘) count=0 for url_item in res: full_url = "%s%s"%(‘http://pic.netbian.com/‘,url_item) res = requests.get(url=full_url).content with open(‘图片%s.jpg‘%count,‘wb‘)as f: f.write(res) count+=1
乱码问题:
1.整体
- response = requests.get(url=xxx,headers=xxx)
-response.encoding = ‘utf-8‘
2. 单独
- xxx.encode(‘iso-8859-1‘).decode(‘gbk‘) (通用处理中文乱码方案)
以上是关于xpath解析案例的主要内容,如果未能解决你的问题,请参考以下文章
xpath案例 爬取58出租房源信息&解析下载图片数据&乱码问题
Python爬虫编程思想(149):使用Scrapy抓取数据,并通过XPath指定解析规则