不会SQL也能做数据分析?浅谈语义解析领域的机会与挑战
Posted SivilTaram
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不会SQL也能做数据分析?浅谈语义解析领域的机会与挑战相关的知识,希望对你有一定的参考价值。
笔者按: 在第5次AI TIME PhD Debate上,笔者邀请了部分国内外语义解析领域的杰出华人学者共话语义解析的过去,现状和未来。本博客为笔者根据视频讨论总结的干货整理。对原视频感兴趣的同学可以直接观看原视频: 传送门。语义解析是个新兴热门的领域,也欢迎读者在本博客下留言分享自己的感悟或问题,笔者会尽可能解答大家的问题。
一直以来是,语义解析(Semantic Parsing) 都是自然语言处理领域一个非常基础且重要的研究问题。通俗来讲,语义解析旨在让计算机学会理解自然语言,并将其翻译成机器可执行的、形式化的编程语言(比如 SQL语句) 。这样一来,用户无需学习编程,通过描述就可以驱动系统生成代码。鉴于语义解析潜在的商业应用价值,近些年来以Text-to-SQL为代表的语义解析领域引起了很多国内外研究者的研究兴趣。

7月31日,PhD Debate第五期“语义解析漫谈:机会与挑战”,AI TIME特别邀请了来自卡内基梅隆大学的殷鹏程学长、俄亥俄州立大学的姚子瑜学姐、爱丁堡大学的王柏林学长,并由北京航空航天大学的刘乾(就是笔者我啦) 和清华大学的张亚娴主持,共话语义解析方向的机会与挑战。话不多说,下面就让我们来看看嘉宾们具体讨论了哪些话题吧!
语义解析领域近年来受关注的具体方向和任务
计算机自然语言接口 Natural Language Interface
SQL Generation (Text-to-SQL)
王柏林: 语义解析最常见的一个应用场景就是数据库的自然语言接口(Natural Language Interface for Database, 又名 NLIDB)。一个主要的原因是数据库我们平时应用比较多,许多应用都是通过数据库来存储数据的,而用户和开发者也都需要与数据库的频繁交互来查询数据。在这个方向上,最近受大家关注度比较多的就是 Spider这个数据集 [1]。它的创建过程是这样的:首先收集一些数据库,每个数据库里可能包含很多表格,比如下图中的 instructor 和 department。
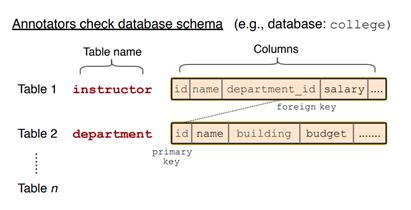
标注者被要求想出一个复杂的问句,同时要标注出跟这个问句对应的SQL语句,如下图所示:
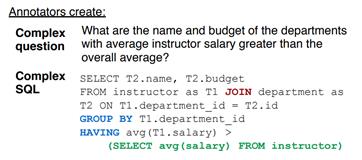
当这个数据集创建完成后,我们就可以构建一个系统从这个数据集中学会将人类的自然语言翻译成SQL语句,进而实现用户通过自然语言查询数据库的需求。
刘乾:Spider是一个英文的数据集,中文领域与Spider相对应的是百度NLP团队发表在EMNLP2020上的数据集 DuSQL [2],它的一个例子如下图所示。

DuSQL与Spider一样,生成的SQL都需要在多张表格上进行连表查询,问句也比较复杂。除了中文和英文的区别外,DuSQL相比Spider还额外考虑了用户场景的区别,继而在标注数据时考虑到不同场景的用户的问句涉及到SQL语句的分布情况。例如说,信息检索场景的用户一般不涉及SQL里的计算(Calculation)操作,因为他们提问主要是想得到一个通过检索可得到的事实性答案,但它对于数据分析场景的用户来说却是很常见的。从这个角度来说,DuSQL带给我们的启示是: 在收集语义解析的数据前我们就要考虑好面向用户的场景。场景的不同也会决定数据集的侧重有所不同。
Code Generation
殷鹏程: 刚刚两位讲到了如何将自然语言转换成SQL语句这种领域相关的代码(Domain-Specific Language, DSL),其实语义解析还可以用在更广泛的范畴,比如说通用的代码生成(Code)。在代码生成领域,第一项工作是由DeepMind于2016年发布的HeartStone数据集 [3]。在这个数据集的设定下,系统所接受的自然语言的输入并不是一个用户提交的问题,而是一组关于炉石传说卡牌的描述,系统的目标就是生成一串能够实现这个卡牌的代码。一个包含输入、输出的示例如下图:

相比于前面所讲到的SQL Generation,Code Generation的难点在于输出是更加复杂和多样的。比如这里系统要生成Python一个类的名字和成员函数。
其实呢,除了炉石传说这种特定领域下的代码生成,我们还可以考虑开放领域下的代码生成。下图是CoNaLa数据集,是由我们团队在2018年构建的 [4],它的目标是能够自动化地把一个程序员的自然语言问题变成相应的Python代码实现。这个数据集是源自一些知名的编程问答平台(如StackoverFlow)上网友提问的问题,和其他网友贡献的一些Python实现。但是,想从这样的平台上自动抽取干净的平行语料还是比较困难的,我们团队当时构建了一个模型来自动地抽取这样的数据对。有了这些数据对后,我们邀请一些程序员对这些数据对进行进一步的过滤和修正,最终就可以得到CoNaLa这个数据集。

除了这种简短的代码外,近些年也有如Github Copilot 这样的能够生成较为复杂程序的技术。Copilot背后的技术就是OpenAI最近提出的CodeX [5],一个基于代码的预训练模型。CodeX系统的输入是一段提示(Prompt),比方说下图中的提示输入到CodeX中,它可以生成一个判断输入数字是否为质数的Python程序。

Code Search
姚子瑜: 前一位嘉宾介绍了代码生成,那我接下来要介绍的技术与代码生成联系是非常紧密的,它就是代码检索(Code Search/Code Retrieval)。当用户用自然语言提问时,假设我们有一个非常大的代码库,我们希望从这个大的代码库中检索到对用户而言最有用的,最能帮助用户回答问题的代码。下图展示了StaQC数据集 [6] 中的一个示例。

相比于代码生成,代码检索的特点在于用户的问句可能更短,而期望的解决方案要更加复杂。目前,代码检索的主要难点有三个: 1. 如何同时建模自然语言问题和代码的语义,以及它们之间的关联,使得用户可以检索到有用的代码解决方案;2. 如何高效地检索到最有用的代码解决方案;3. 如何找到有效的负样本(negative sample)来训练一个更有效的代码检索模型。从另外一个角度来说,代码检索其实也可以作为代码生成的一个前置流程。当系统需要产生一些复杂代码时,它可以先检索一些代码作为基础,然后对它们进行编辑(edit)得到一个新的代码返回给用户。
语义解析与对话系统 Semantic Parsing and Dialogue Systems
刘乾: 除了单轮的语义解析外,近些年语义解析与对话系统的结合也吸引了很多关注。伴随着任务型对话与对话式语义解析之间的界限越来越模糊,语义解析和对话系统之间的渊源也越来越深,包括了用于传统对话系统的语义解析方法,对话式语义解析以及交互式语义解析。
Semantic Parsing for Dialogue Systems
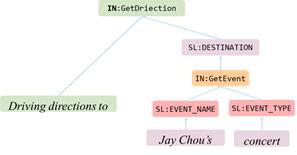
殷鹏程: 随着任务型对话需求的复杂程序逐渐提升,使用语义解析方法来解决传统的任务型对话是一种趋势。在这个方向上,首先我想介绍一下Facebook所提出数据集TOP [7],它的任务要求模型能够层次(Hierarchical)化地理解自然语言,这种层次化理解的难度我认为介于槽位填充(Slot Filling)方法与语义解析方法之间。下图是一个TOP中的示例,它通过定义一种层次化的表示来支持嵌套查询等复杂操作。
姚子瑜:如上位嘉宾所说的,当任务型对话复杂到一定程度后,解决方案最终其实会收敛到语义解析的方法。例如,去年微软Semantic Machines 团队就发布了一个数据集 SMCalFlow [8],将语义解析方法直接用在了任务型对话中。下图展示了该数据集中的一个示例,大家可以看到相比TOP而言,这个数据集中的代码要更加复杂。而这种代码设计的主要动机在于更好地处理用户自然语言中组合式(Compositional)的语义。
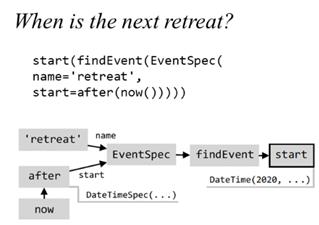
同时,为了更好地建模对话中的上下文,SMCalFlow 提出了两种元算子(Meta Computation),分别是指代(Reference)和更新 (Revision)。指代对应的是refer,主要处理对话中存在指代的现象,比如用代词指代上文中的某个物体。更新对应的是 revise,主要处理用户希望更新历史状态时,比如用户说 “把会议改到5点”。
刘乾: 刚刚两位嘉宾介绍了如何在开放域(Open Domain)的场景下利用语义解析的方法来解决对话系统,但这些方法理论上都无法泛化到新的领域中。例如,当训练数据是关于天气预报的对话,测试时系统也只能完成天气预报的功能,而无法跨域泛化(Cross-domain Generalization),完成如订会议室等功能。下面我们将介绍的面向数据库的、带上下文的语义解析(Contextual Semantic Parsing) 在训练模型时就带上了领域知识,例如领域相关的数据库。在测试时,我们可以通过切换模型依赖的领域知识来实现它的跨域泛化,使得系统更加实用。
Contextual Semantic Parsing
王柏林: 面向数据库的对话式语义解析相比传统的对话而言泛化性要更强一些,也更关注于数据库的交互。与传统任务型对话动机一样,当用户与数据库交互时,很多情况下都需要多轮交互才能达到最终的目的。下图的例子展示了数据集 SParC [9] 中一个关于学生宿舍数据库上的一个比较复杂的问句 C1。大家可以看到,这个问句非常复杂,用户一般其实也不会这么去提问。更自然的一种交互方式其实是用户通过一组对话比如 Q1, Q2 等一起来完成一个复杂询问的操作。

刘乾: SParC数据集的主要动机是想让用户通过一组简单对话表达一个复杂意图,因此它在数据标注时也遵循一样的原则,即让标注人员通过对话在最后一轮时产生一个复杂的SQL语句。但实际上这样的标注方法会带来一些问题,其中最主要的就是会造成SQL复杂度分布不均匀。例如,在SParC数据集中,第1轮问句对应的SQL往往非常简单,而最后1轮问句对应的SQL往往非常复杂。为了缓解数据集与真实情况下的分布差异问题,西安交大与微软的研究员改进了数据标注流程,并在今年ACL发布了一个新的中文对话级NL-to-SQL的数据集CHASE [10]。CHASE中各轮SQL的复杂度比较均衡,它也鼓励标注员在一轮对话中间开启一个全新的话题,也因此更具挑战性。下图是CHASE数据集中的一个示例,可以看到中文的对话与英文的对话差距还是较大的,中文相比而言更加简洁一些。

Interactive Semantic Parsing
姚子瑜: 交互式语义解析也是近几年学术界关注的一个方向。虽然同为对话系统下的场景,但和上述嘉宾所关注的上下文依赖的场景不同的是,交互式语义解析(Interactive Semantic Parsing)关注在人机交互上。它允许一个系统通过与用户的交互来澄清用户的意图(Clarify User Intent) ,获得用户确认 (Ask for Confirmation) ,以及通过用户反馈纠正自身 (Ask for Correction) 等。通过交互,一个语义解析系统可以有更好的鲁棒性以及提升它自己的置信度。目前,这个研究领域有一个相对比较初步的数据集 SPLASH [11] (如下图),它可以用来训练系统学会利用用户的反馈更正自己的错误。
语义解析领域近年来受关注的新技术
模型架构与任务建模 Model Architecture
刘乾: 目前语义解析模型按照建模方式主要是两种范式,一类是以WikiSQL这类SQL相对比较简单的数据集为目标的,通过将语义解析的生成任务分解成若干个简单的分类子任务来完成语义解析,如XSQL [12],另一类则是以Spider这类SQL相对比较复杂的数据集为目标的,通过自回归的生成式模型来完成语义解析,如 IRNet [13]。前者的好处在于通过简化任务降低了模型的学习压力,对工业界而已更容易商业化;而后者则更加通用,接下里嘉宾主要会侧重于后者的相关讨论。
Grammar-based Decoding
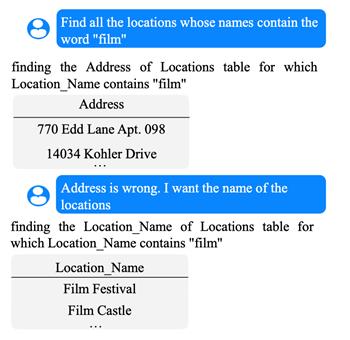
殷鹏程: 语义解析领域下其实囊括了许多不同的任务,如NL-to-SQL, NL-to-Python等。不同任务其实需要不同的领域知识(Domain-specific Knowledge),其中很重要的一种知识就是生成代码本身要遵从的对应语法(Grammar)。下图右侧是一段Python代码和它所对应的抽象语法树(Abstract Syntax Tree),左侧则是Python的语法。不难看出,Python的语法中其实蕴涵了许多对模型输出空间的约束,例如,一个Expr (即表达式)只能展开成一个 Name (即变量名) 或者一个 Call (即函数调用)。
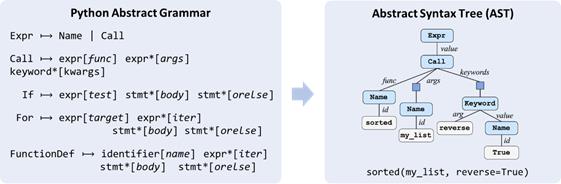
当我们在需要完成NL-to-Python任务的模型中引入Python语法作为先验知识时,它应该可以保证所生成的代码在语法上一定是正确的,这就是基于语法的解码方法(Grammar-based Decoding), 而 [14] 就是其中经典的工作之一。在实际建模中,与传统的直接利用序列到序列模型(Sequence to Sequence Model)来生成代码 [15] 不同,基于语法的解码方法利用的是序列到树模型(Sequence to Tree Model),生成的实际上是上图中抽象语法树深度优先遍历得到的序列(即动作序列, Action Sequence),最终再通过确定性的算法将动作序列转换成目标代码。
Relation-Aware Encoding
王柏林: 前位嘉宾讲到了通过语法来增强解码器,接下来我要介绍的就是如何利用关系感知的编码(Relation-Aware Encoding)来增强Text-to-SQL任务中编码器的能力。当我们在构建面向数据库的Text-to-SQL系统时,系统其实需要完成两件事: 模式编码(Schema Encoding)与模式链接(Schema Linking),这里的模式指的是数据库模式,包括表名,列名和值。
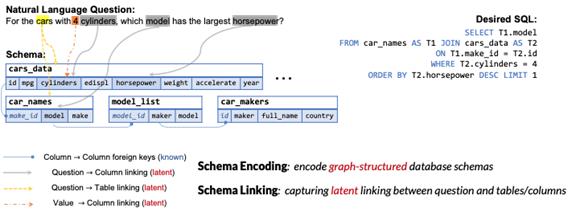
模式编码是指如何编码数据库信息,因为数据库由多个主外键相连的表格构建而成,它本身是一个图的结构,如何编码这种图结构对算法提出了比较大的挑战。模式链接是指用户的问题中有一些词或显式或隐式地提到数据库模式,比如这里的cars就关系到表名cars_data和列cars_name。如何把问题和数据库模式的这种关系让模型感知到就是模型设计的另一个关键。
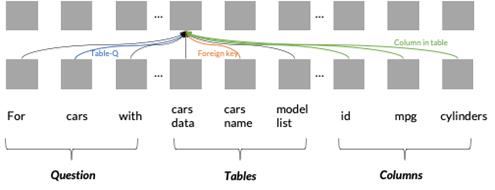
为了更好地解决这两个挑战,我们在Transformer的基础上提出了关系感知的编码方法RAT-SQL [16]。模型的输入包含三部分,包括了用户的问题,数据库表名和数据库列名。比如下面这个例子,模型在编码 cars_data的时候会考虑到若干种关系,如cars_data 与用户问题中cars一词的链接关系,再如cars_data与其表内列名在同一个表的关系等。在具体实现时,这些关系会被加入到自注意力层种,从而让Transformer能够更好地感知和表示关系。
Meaning Representation
刘乾: 除了上述两位嘉宾所提到的编码器和解码器的设计都会影响模型的性能外,其实还有一点很容易被大家忽视,就是数据集所使用的编程语言本身也会影响模型的性能。去年EMNLP上我们组做了一个工作 [17],通过实验我们发现: 即使用同样语义的语料来训练模型,模型在不同编程语言上的性能还是有显著的差异。举个例子,下表中展示了四种不同的编程语言所对应的的一段语义相同的程序,它们分别是Prolog,Lambda Calculuas, FunQL 和 SQL。我们发现在多数情况下模型在FunQL上的表现要比在SQL上的表现更好,而这有可能是因为FunQL本身的歧义要更少。这也启发了我们,在收集语义解析的新数据集前要先想想编程语言是否有明显的改进空间,再请专家标注数据。当然,关于这方面的研究学术界目前还不够深入,也没有确定性的结论来指导我们设计“更好”的编程语言。

预训练模型 Pre-trained Language Models
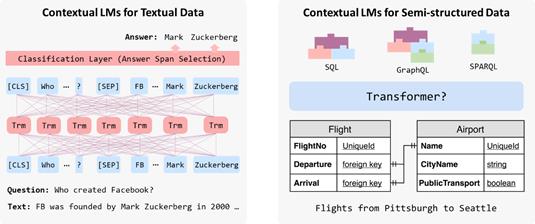
殷鹏程: 正如我们之前所提到的,语义解析任务需要很多的领域知识,例如程序相关的语法结构。而在领域知识中,另一块比较重要的其实就是表格 (例如text-to-SQL里需要把表格作为输入的一部分)。目前主流的语义解析中的预训练模型都是与表格相关的。下图对比展示了传统的针对文本数据的预训练(左侧)和针对表格数据的预训练(右侧)。传统的文本预训练模型在阅读理解任务中应用时需要利用Transformer来理解问题 Who created Facebook,并在相应的领域知识——非结构化文档上进行推理得到最终的答案;针对表格的预训练模型在语义解析任务中应用时同样需要学会理解问题如 Flights from Pittsburgh to Seattle,但它的领域知识变成了结构化的数据表,最终输出的是编程语言如SQL, GraphQL 等。同样地,针对表格的预训练同样需要用Transformer来编码,编码过程主要有两大难点: (1) 如何用 Transformer编码结构化的表格;(2) 如何设计一个通用的预训练模型,使得其可以兼容不同的编程语言。
TaBERT
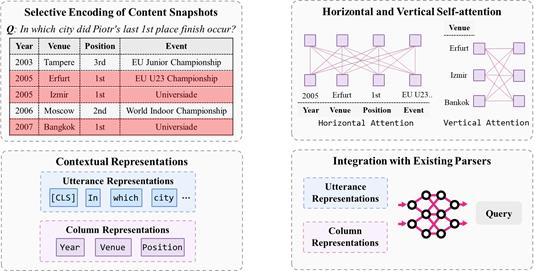
殷鹏程: 针对以上问题,我们提出了一个可以增强表格理解的预训练语言模型TaBERT [18]。该模型设计的主要一个出发点在于,现实生活中表格会非常长,比如商用系统中的数据表可能有成千上万行。所以,第一步要先做一个数据精简,即下图中的选择编码(Selection Encoding)。以下图中的问题为例,当用户提问 In which city did Piot’s last 1st place finish occur? TaBERT首先会选几个与问题相关的行(下图红色所示),然后只需要编码它们即可。有了精简的表格后,接下来的一个关键问题在于,如何修改Transformer从而让它能够理解结构化的表格知识。TaBERT通过扩展传统的自注意力(Self Attention),让模型既能注意到水平方向的其他格,也可以注意到垂直方向的其他格的内容。TaBERT最终的输出不仅包括了用户问题的表示,还包括了表格中的每个表头的表示。这些表示可以被下游的语义解析模型用到,从而解码得到对应的编程语言。
GraPPa
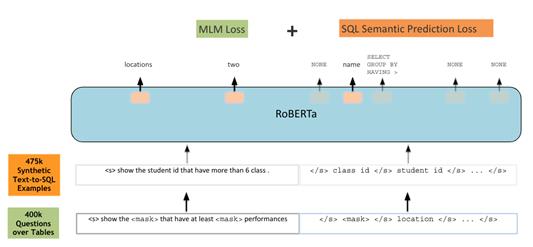
王柏林: GraPPa [19] 跟TaBERT的动机是一样的,就是如何利用大规模的预训练数据来通用地向语义解析模型注入领域知识。但是不同于TaBERT在网上爬取大规模的数据,GraPPa的核心思想是利用现有数据集里的模板系统性地构造大规模的数据。其构造数据的核心思想借鉴于论文[20],即通过同步上下文无关文法(SCFG)来合成新的自然语言和编程语言的成对数据。GraPPa首先通过现有的数据集人工归纳出SCFG文法,接着将这些SCFG应用在新的编程语言上,从而得到可能有噪音的(自然语言,编程语言)的成对数据。最终,搭配合适的预训练目标,GraPPa可以普遍地增强text-to-SQL模型的性能。预训练用到的训练模板除了传统的掩码自然语言目标(Masked Language Model, MLM) 外,还引入了SQL语义预测目标(SQL Semantic Prediction)。前者就是利用自然语言上下文去预测当前被[MASK]掉的词对应的原文中的词,而后者是去预测这个自然语言对应的SQL的操作符有哪些。
TAPEX
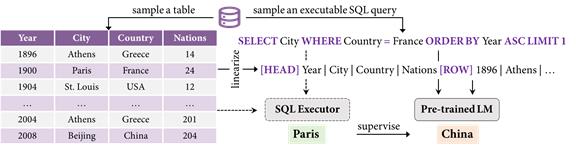
刘乾: 不同于上两个预训练模型最终的应用场景是输出SQL,TAPEX [21] 的目标是增强模型在弱监督场景下的性能。它的下游模型在接受自然语言问题和表格作为输入后,直接输出其对应的答案。因此呢,TAPEX 提出的目的就在于提升下游模型在理解表格结构以及在表格上进行推理的能力。那如何增强下游模型对表格的推理能力呢,TAPEX给出的答案是:让模型去模仿学习一个SQL执行器的行为。如果一个神经网络都能学会执行如此复杂的SQL,并给出它正确的执行结果,那我们可以预期它对表格的结构也好,在表格上的推理能力都应是相当强的。TAPEX的实验也验证了,就只需要在这种SQL和其执行结果的纯合成的数据上做预训练,TAPEX也能在四个不同的数据集上都获得最好的性能。
交互式语义解析 Interactive Semantic Parsing
姚子瑜: 交互式语义解析的主要目标是丰富人与语义解析系统之间的交互,系统可以通过与人的交互来提升系统的置信度。一个交互式的对话如下图所示。

Learning from User Feedback
姚子瑜: 当用户问的问题里有歧义时,或者系统不理解用户的问题时,我们希望系统能够主动地提出一些澄清式问题以从用户的反馈中学习。如下图所示,当系统不理解用户提出的问题时,可以通过用户的反馈(比如做下图的多选题)来告诉系统在这种提问下应该如何决策。在我们的工作中 [22],我们实现了刚才所描述的系统,期望系统在部署后可以通过与用户源源不断的交互来持续提高在编程语言生成的能力。同时这种系统还可以在线上收集更多平行语料。

Learning to Edit Programs
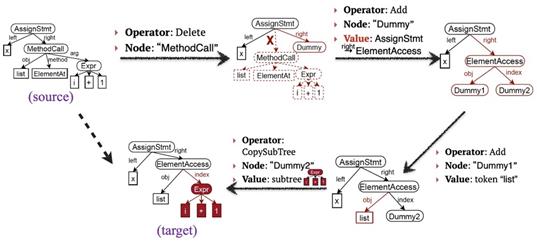
姚子瑜: 除了可以通过交互让系统更了解用户意图,系统其实还可以更通用地支持用户对已经生成的程序进行简单的编辑,从而在之前的程序的基础上更快地表达用户意图。下图给出了一个例子,其中源程序(source program)是待编辑的程序,目标程序(target program)是编辑后的程序。在 [23] 这个工作中,我们探索了能否设计一个通用的模型来完成程序的编辑操作。我们所提出的模型直接在程序对应的树结构上做编辑操作,在每个动作时要确定若干信息:(1) 编辑类型 (Delete/Add);(2) 编辑结点 (Node);以及可能的额外内容如新增的值 (Value)。
Learning to Detect Ambiguity
刘乾: 上面的两个工作主要关注在系统对自己生成的程序不确信时,目前交互式语义解析中其实也有目标定位在歧义发现(Detect Ambiguity)的工作如 [24]。它主要关注的场景就是,当用户的话语中包含歧义时,系统能够发现并给予反馈,同时可以允许用户简单地通过选项消除自然语言中的歧义短语。但是,其实这种带歧义负样本的数据集目前并不常见。为了解决这个问题,[24] 就把歧义发现建模成了一个细粒度的自然语言和编程语言之间细粒度的匹配问题。匹配上的部分意味着这部分自然语言在编程语言中有所对应,否则的话就意味着这部分自然语言的语义并没有在编程语言中体现,也就是我们所说的歧义短语。具体的检测流程如下图所示。
语义解析领域当前存在的挑战与未来的方向
在思辨的最后,四位嘉宾针对语义解析领域当前存在的挑战与未来的方向进行了讨论,在这里我们简单介绍一下嘉宾们所讨论的话题,更多思辨的细节请读者观看原视频 (https://www.bilibili.com/video/BV1Uh411z7ZQ, 1:29:13)。
1. 数据集采集与标注成本高 Dataset Annotation
语义解析任务的目标是生成程序,这就要求数据集在采集时需要请领域专家如程序员进行标注,标注成本较高。如何降低数据集的标注成本是第一大挑战·。
2. 语义解析领域的预训练 Pre-training for Semantic Parsing
预训练现在非常火热,该如何设计针对于语义解析任务的预训练模型,或者如何在语义解析里用好开放式的大规模预训练模型是第二大挑战。
3. 模型的组合泛化问题 Compositional Generalization
程序是组合性的,组合的特点就意味着程序的搜索空间非常大,如何让语义解析模型能够泛化地生成程序的新组合是第三大挑战。
4. 未来数据集与任务范式 Future Avenues: Datasets and Tasks
对于语义解析的未来,嘉宾们认为主要有两大方向: (1) 如何将语义解析与阅读理解等没有显式程序标注的场景结合,(2) 对这些新的领域和应用场景,该如何构建更有效的系统评价体系,从而帮助设计更实用,更有价值的语义解析系统。
参考文献
[1]. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task [2]. DuSQL: A Large-Scale and Pragmatic Chinese Text-to-SQL Dataset [3]. Latent Predictor Networks for Code Generation [4]. Learning to Mine Aligned Code and Natural Language Pairs from Stack Overflow [5]. Evaluating Large Language Models Trained on Code [6]. StaQC: A Systematically Mined Question-Code Dataset from Stack Overflow [7]. Semantic Parsing for Task Oriented Dialog using Hierarchical Representations [8]. Task-Oriented Dialogue as Dataflow Synthesis [9]. SParC: Cross-Domain Semantic Parsing in Context [10]. Chase: A Large-Scale and Pragmatic Chinese Dataset for Cross-Database Context-Dependent Text-to-SQL [11]. Speak to your Parser: Interactive Text-to-SQL with Natural Language Feedback [12]. X-SQL: reinforce schema representation with context [13]. Towards complex text-to-sql in cross-domain database with intermediate representation [14]. A Syntactic Neural Model for General-Purpose Code Generation [15]. Semantic Parsing as Machine Translation [16]. RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parser [17]. Benchmarking Meaning Representations in Neural Semantic Parsing [18]. TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data [19]. GraPPa: Grammar-Augmented Pre-Training for Table Semantic Parsing [20]. Data Recombination for Neural Semantic Parsing [21]. TAPEX: Table Pre-training via Learning a Neural SQL Executor [22]. An Imitation Game for Learning Semantic Parsers from User Interaction [23]. Learning Structural Edits via Incremental Tree Transformations [24]. "What Do You Mean by That?" A Parser-Independent Interactive Approach for Enhancing Text-to-SQL学会这款自动化测试神器,不会写代码也能做
前 言
做自动化测试肯定要了解就是 DDT 数据驱动测试,这样做的好处就是可以通过一组或多组数据进行灵活的测试,而不需要硬编码。
那今天我们就来讲解一下 Katalon 怎么进行测试数据读取的。
Katalon 支持的数据格式
Excel
CSV
database data
internal data
前提准备
-
创建好 Excel 文件并输入测试数据
-
通过 katalon 录制好执行的测试用例,并且把 input 里录制好的测试数据去掉
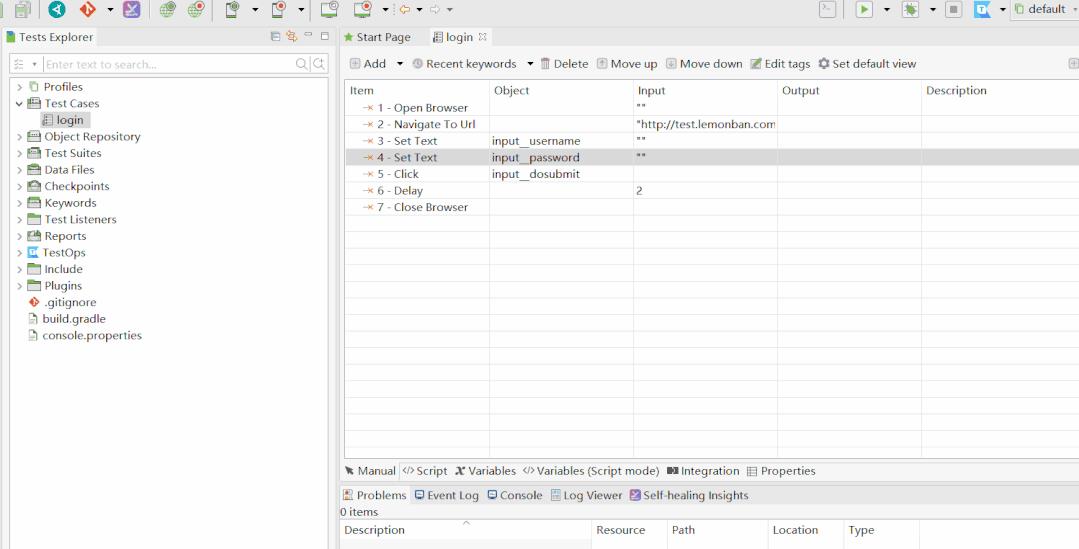
1、在 Data Files 里新建一个 Excel 格式的 testdata

重点知识:
在添加 Excel 文件后有三个设置项:
Use first row as header:勾选上会自动帮你去除掉 Excel 的 title(默认勾选)
Use relative path:如果把 Excel 放到 katalon 工程对应的文件夹下,就可以使用相对路径了,也就是勾选上之后只需要输入文件名即可,不需要绝对路径(默认不勾选)
Bind to test case as string:以字符串形式绑定到测试用例(默认勾选)
最后:一定要记得添加 Excel 之后要保存这个 datafiles 文件
2、在测试用例里面创建变量用来接收 Excel 里面的数据,默认值可以不用填写
重点知识:
一定要记得保存测试用例
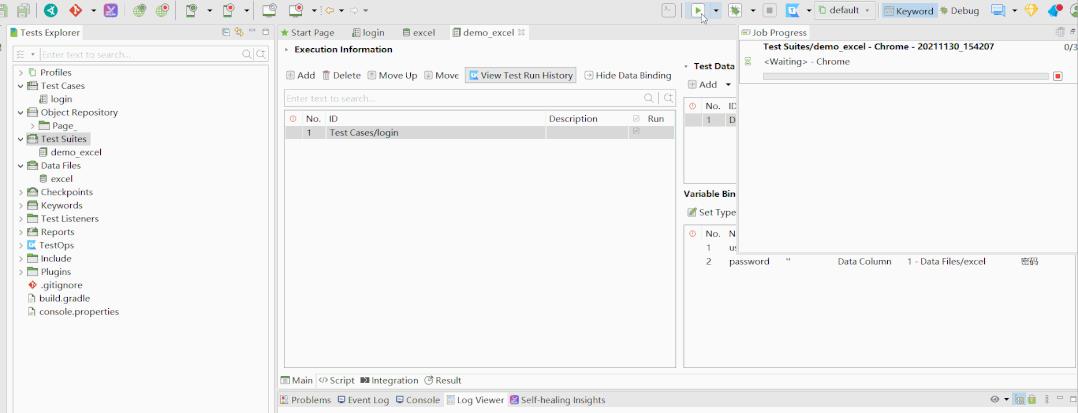
3、创建一个 TestSuite 并配置一个测试用例

4、将测试用例里面的变量绑定 Excel 数据

重点知识:
一定要记得保存 Testsuite
5、运行测试用例即可看到会依据 Excel 的数据数量执行多次测试用例
到此,katalon 进行 DDT 数据驱动测试就已经实现了哦~~~
今天教的小技巧 大家学会了吗?
下面是我当时学习时用过的部分资料,有需要的朋友可以点击下面链接即可免费领取哟


以上是关于不会SQL也能做数据分析?浅谈语义解析领域的机会与挑战的主要内容,如果未能解决你的问题,请参考以下文章
#yyds干货盘点# 出现吧,Python Web 菜谱系统的首页,不会前端技术,也能做
不会写代码?那你一定不能错过这款自动化测试神器,不会写代码也能做!