使用Numpy进行深度学习中5大反向传播优化算法的性能比较
Posted OSC开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Numpy进行深度学习中5大反向传播优化算法的性能比较相关的知识,希望对你有一定的参考价值。
在本文中,我们将通过计算二次凸函数的最优点来比较主要的深度学习优化算法的性能。
简介
深度学习被称为人工智能的未来。现在,神经网络被称为通用函数逼近器,也就是说,它们有能力表示这个宇宙中任何复杂的函数。计算这个具有数百万个参数的通用函数的想法来自优化的基本数学。优化可以通过多种方式完成,但在本文中,我们将重点讨论基于梯度下降的优化技术。
非凸函数的优化是研究的主要领域。多年来,不同的科学家提出了不同的优化算法来优化神经网络的成本函数。这些算法大部分都是基于梯度的方法,稍作修改。在这篇文章中,我们将讨论5个专业的下降基于算法-Gradient Descent,Momentum,Adagrad, RMSprop, Adam。
方法
为了了解每个算法在实际中是如何工作的,我们将使用一个凸二次函数。我们将对每个算法进行固定次数的迭代(20次),以比较它们在达到最优点时的收敛速度和轨迹。下面给出了为此任务选择的函数的方程,以及使用Matplotlib绘制的函数的三维图和级别集。
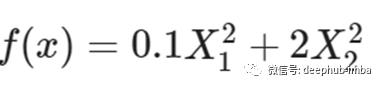
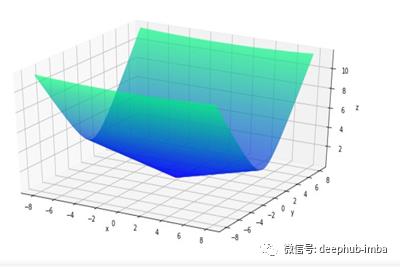
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(13,6))
ax = plt.axes(projection="3d")
start, stop, n_values = -8, 8, 800
x_vals = np.linspace(start, stop, n_values)
y_vals = np.linspace(start, stop, n_values)
X, Y = np.meshgrid(x_vals, y_vals)
Z = np.sqrt(0.1*X**2 + 2*Y**2)
plt.contourf(X,Y,Z,)
ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='winter', edgecolor='none')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')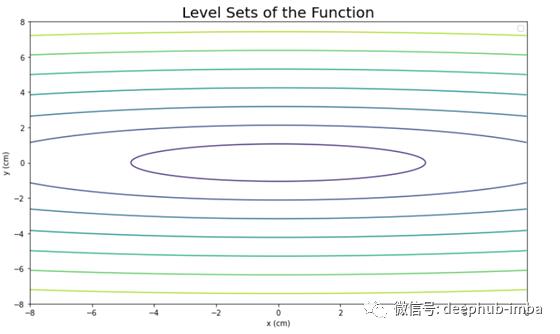
首先,我们将从最基本的梯度下降算法开始,然后我们将跟随它们发展的趋势来支持每个算法发展背后的想法。所以趋势是这样的
1-Gradient Descent
2-Momentum
3-Adagrad
4-RMSprop
5-Adam
因为所有这些算法在更新规则的每次迭代时都需要梯度。因此,下面给出了函数的梯度,用于在每次迭代时更新两个变量。我们将对所有算法使用固定的学习率值=0.4。
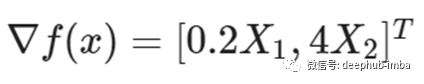
1、Gradient Descent
梯度下降法是求解最优解的最传统的方法。在这个算法中,使用当前梯度(gt)乘以一些称为学习率的因子来更新当前权值。更新规则的公式如下所示。
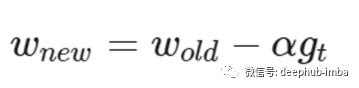
lr=0.4
x1=-4
x2=-6
l1_gd=[]
l2_gd=[]
for i in range(20):
l1_gd.append(x1)
l2_gd.append(x2)
x1=x1-lr*0.2*x1
x2=x2-lr*4*x2
使用梯度下降的轨迹
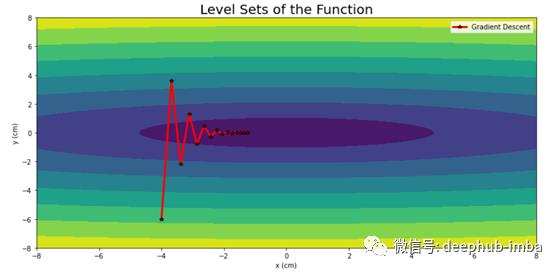
fig = plt.figure(figsize=(13,6))
left, bottom, width, height = 100, 0.1, 0.8, 0.8
ax = fig.add_axes([left, bottom, width, height])
start, stop, n_values = -8, 8, 100
x_vals = np.linspace(start, stop, n_values)
y_vals = np.linspace(start, stop, n_values)
X, Y = np.meshgrid(x_vals, y_vals)
Z = np.sqrt(0.1*X**2 + 2*Y**2)
plt.contourf(X,Y,Z,)
plt.plot(l1_gd[:15],l2_gd[:15],color="red",marker="*",markeredgecolor="black",linewidth=3,label="Gradient Descent")
plt.figure(figsize=(15,10))
plt.figure(figsize=(15,10))
ax.set_title('Level Sets of the Function',size=20)
ax.set_xlabel('x (cm)')
ax.set_ylabel('y (cm)')
ax.legend()
plt.show()
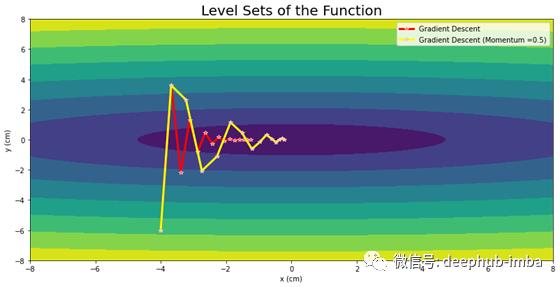
正如我们在上面的图中看到的,梯度下降经历了很多振荡,收敛速度非常慢。所以在后面的部分,我们将学习梯度下降的改进,它将帮助我们实现稳定和更快的收敛。
2、Momentum
动量梯度下降是一种常用的优化器,它消除了标准梯度下降引起的振荡,加速了收敛最优点。当它在水平方向上加速时,它在垂直方向上减速。在这种杰出行为的帮助下,它使我们在学习率的方向上迈出了一大步。此外,动量比标准梯度下降要稳定得多。
下面给出的方程式解释了更新规则-
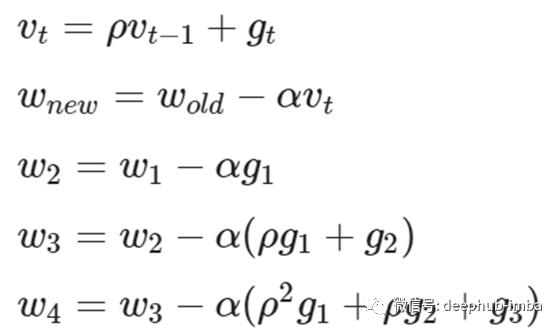
v1,v2=0,0
gamma,lr=0.5,0.4
x1,x2=-4,-6
l1_gd_m,l2_gd_m=[],[]
for i in range(20):
l1_gd_m.append(x1)
l2_gd_m.append(x2)
v1=gamma*v1+(0.2*x1)
v2=gamma*v2+(4*x2)
x1=x1-lr*v1
x2=x2-lr*v2
Gradient Descent vs Momentum
import matplotlib.pyplot as plt
import numpy as np
fig = plt.figure(figsize=(13,6))
left, bottom, width, height = 100, 0.1, 0.8, 0.8
ax = fig.add_axes([left, bottom, width, height])
start, stop, n_values = -8, 8, 100
x_vals = np.linspace(start, stop, n_values)
y_vals = np.linspace(start, stop, n_values)
X, Y = np.meshgrid(x_vals, y_vals)
Z = np.sqrt(0.1*X**2 + 2*Y**2)
plt.contourf(X,Y,Z,)
plt.plot(l1_gd[:15],l2_gd[:15],color="red",marker="*",markeredgecolor="black",linewidth=3,label="Gradient Descent")
plt.plot(l1_gd_m[:15],l2_gd_m[:15],color="yellow",marker="*",markeredgecolor="orange",linewidth=3,label="Gradient Descent (Momentum =0.5)")
plt.figure(figsize=(15,10))
plt.figure(figsize=(15,10))
ax.set_title('Level Sets of the Function',size=20)
ax.set_xlabel('x (cm)')
ax.set_ylabel('y (cm)')
ax.legend()
plt.show()
3、Adagrad
自适应梯度下降算法(adaptive gradient descent)是一种学者梯度下降算法。其主要区别在于Adagrad根据网络中参数的重要性对每个权值利用不同的学习速率。换句话说,用较高的学习率训练不必要的参数,用较小的学习率训练重要参数,使其更稳定地收敛。在不允许失真的情况下,实现了算法的加速。更新公式类似于动量,这里每一步的动量是用之前的动量和梯度的平方来计算的。下面的公式显示了Adagrad中的更新规则。
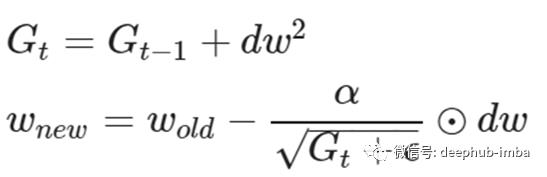
Gt是一个对角矩阵组成的平方和过去的渐变和ϵ平滑项。此外,表示矩阵-向量积运算。
v1,v2=0,0
gamma,lr=0.9,0.4
x1,x2=-4,-6
l1_adagrad,l2_adagrad=[],[]
for i in range(20):
l1_adagrad.append(x1)
l2_adagrad.append(x2)
v1=v1+(0.2*x1)**2
v2=v2+(4*x2)**2
x1=x1-(lr/math.sqrt(v1+c))*0.2*x1
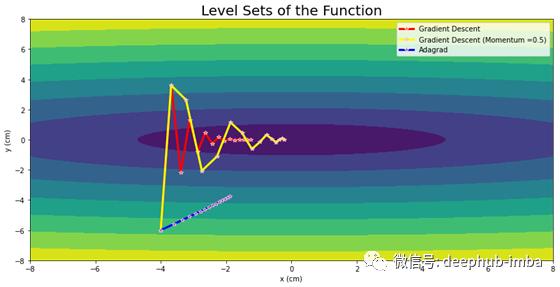
x2=x2-(lr/math.sqrt(v2+c))*4*x2Momentum vs Adagrad
import matplotlib.pyplot as plt
import numpy as np
fig = plt.figure(figsize=(13,6))
left, bottom, width, height = 100, 0.1, 0.8, 0.8
ax = fig.add_axes([left, bottom, width, height])
start, stop, n_values = -8, 8, 100
x_vals = np.linspace(start, stop, n_values)
y_vals = np.linspace(start, stop, n_values)
X, Y = np.meshgrid(x_vals, y_vals)
Z = np.sqrt(0.1*X**2 + 2*Y**2)
plt.contourf(X,Y,Z,)
plt.plot(l1_gd[:15],l2_gd[:15],color="red",marker="*",markeredgecolor="black",linewidth=3,label="Gradient Descent")
plt.plot(l1_gd_m[:15],l2_gd_m[:15],color="yellow",marker="*",markeredgecolor="orange",linewidth=3,label="Gradient Descent (Momentum =0.5)")
plt.plot(l1_adagrad[:15],l2_adagrad[:15],color="blue",marker="*",markeredgecolor="black",linewidth=3,label="Adagrad")
plt.figure(figsize=(15,10))
plt.figure(figsize=(15,10))
ax.set_title('Level Sets of the Function',size=20)
ax.set_xlabel('x (cm)')
ax.set_ylabel('y (cm)')
ax.legend()
plt.show()
从上图中可以看出,Adagrad虽然运动平稳无振荡,但收敛能力不足。为了解决这个问题,Geoffrey Hinton引入了一个更有效的优化器RMSprop。
4、RMSprop
Rmsprop是由著名计算机科学家Geoffrey Hinton (Hinton et al., 2012)提出的另一种高效优化算法。该算法的工作原理与Adagrad相似,只是稍加修改。不像AdaGrad那样取梯度平方的累积和,我们取这些梯度的指数移动平均值。使用指数平均的原因是为了给最近更新的梯度权重大于最近更新的梯度。下面的方程式显示了Rmsprop的更新规则。
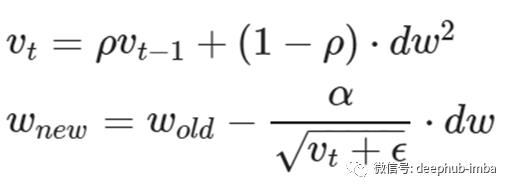
v1,v2=0,0
gamma,lr=0.9,0.4
x1,x2=-4,-6
l1,l2=[],[]
for i in range(20):
l1.append(x1)
l2.append(x2)
v1=gamma*v1+(1-gamma)*(0.2*x1)**2
v2=gamma*v2+(1-gamma)*(4*x2)**2
x1=x1-(lr/math.sqrt(v1+c))*0.2*x1
x2=x2-(lr/math.sqrt(v2+c))*4*x2
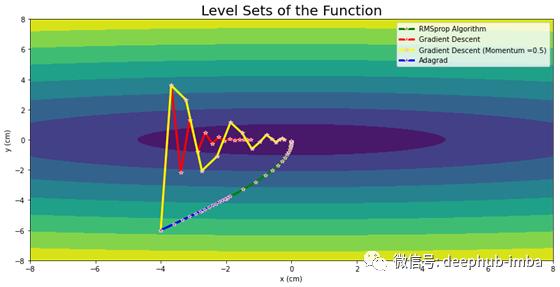
Momentum vs Adagrad vs RMSprop
import matplotlib.pyplot as plt
import numpy as np
fig = plt.figure(figsize=(13,6))
left, bottom, width, height = 100, 0.1, 0.8, 0.8
ax = fig.add_axes([left, bottom, width, height])
start, stop, n_values = -8, 8, 100
x_vals = np.linspace(start, stop, n_values)
y_vals = np.linspace(start, stop, n_values)
X, Y = np.meshgrid(x_vals, y_vals)
Z = np.sqrt(0.1*X**2 + 2*Y**2)
plt.contourf(X,Y,Z,)
plt.plot(l1_gd[:15],l2_gd[:15],color="red",marker="*",markeredgecolor="black",linewidth=3,label="Gradient Descent")
plt.plot(l1_gd_m[:15],l2_gd_m[:15],color="yellow",marker="*",markeredgecolor="orange",linewidth=3,label="Gradient Descent (Momentum =0.5)")
plt.plot(l1_adagrad[:15],l2_adagrad[:15],color="blue",marker="*",markeredgecolor="black",linewidth=3,label="Adagrad")
plt.plot(l1[:15],l2[:15],color="g",marker="*",markeredgecolor="b",linewidth=3,label="RMSprop Algorithm")
plt.figure(figsize=(15,10))
plt.figure(figsize=(15,10))
ax.set_title('Level Sets of the Function',size=20)
ax.set_xlabel('x (cm)')
ax.set_ylabel('y (cm)')
ax.legend()
plt.show()
显而易见,当收敛到最优点时,梯度下降算法在垂直方向上产生巨大的振荡,RMSprop限制了垂直运动,加速了水平方向。此外,虽然动量减小了振荡,RMSprop提供了更可靠和更快的收敛。
5、Adam
自适应矩估计是另一种计算每个参数的自适应学习率的优化器。与其他优化器相比,它更加健壮和可靠,因为它基本上结合了动量和RMSprop(即。移动类似梯度的动量的平均值,并使用梯度的平方来调整学习速率,如RMSprop)。更精确地说,Adam算法执行如下-

v1,v2,s1,s2=0,0,0,0
gamma,beta,lr=0.9,0.999,0.4
x1,x2=-6,-6
l1_adam,l2_adam=[],[]
for i in range(20):
l1_adam.append(x1)
l2_adam.append(x2)
v1=gamma*v1+(1-gamma)*(0.2*x1)
v2=gamma*v2+(1-gamma)*(4*x2)
s1=beta*s1+(1-beta)*(0.2*x1)**2
s2=beta*s2+(1-beta)*(4*x2)**2
m_hat_v1= v1 / (1 - np.power(gamma, i+1))
m_hat_v2 = v2 / (1 - np.power(gamma, i+1))
s_hat_s1= s1 / (1 - np.power(beta, i+1))
s_hat_s2 = s2 / (1 - np.power(beta, i+1))
x1=x1-(lr)*(m_hat_v1/math.sqrt((s_hat_s1)+c))
x2=x2-(lr)*(m_hat_v2/math.sqrt((s_hat_s2)+c))
print(x1,x2)
if abs(x1)<=0.1 and abs(x2)<0.1:
break
在收敛期间的轨迹汇总
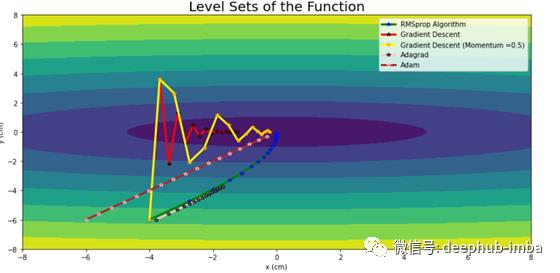
import matplotlib.pyplot as plt
import numpy as np
fig = plt.figure(figsize=(13,6))
left, bottom, width, height = 100, 0.1, 0.8, 0.8
ax = fig.add_axes([left, bottom, width, height])
start, stop, n_values = -8, 8, 100
x_vals = np.linspace(start, stop, n_values)
y_vals = np.linspace(start, stop, n_values)
X, Y = np.meshgrid(x_vals, y_vals)
Z = np.sqrt(0.1*X**2 + 2*Y**2)
plt.contourf(X,Y,Z,)
plt.plot(l1_gd[:15],l2_gd[:15],color="red",marker="*",markeredgecolor="black",linewidth=3,label="Gradient Descent")
plt.plot(l1_gd_m[:15],l2_gd_m[:15],color="yellow",marker="*",markeredgecolor="orange",linewidth=3,label="Gradient Descent (Momentum =0.5)")
plt.plot(l1_adagrad[:15],l2_adagrad[:15],color="blue",marker="*",markeredgecolor="black",linewidth=3,label="Adagrad")
plt.plot(l1[:15],l2[:15],color="g",marker="*",markeredgecolor="b",linewidth=3,label="RMSprop Algorithm")
plt.plot(l1_adam[:20],l2_adam[:20],color="Brown",marker="*",markeredgecolor="pink",linewidth=3,label="Adam")
plt.figure(figsize=(15,10))
plt.figure(figsize=(15,10))
ax.set_title('Level Sets of the Function',size=20)
ax.set_xlabel('x (cm)')
ax.set_ylabel('y (cm)')
ax.legend()
plt.show()
正如在最后的图中所看到的,Adam优化器在直线路径上导致最快的收敛。在Adam的例子中,它通过累积之前梯度的总和来减弱振荡,并且由于梯度的平方项,它遵循一条直线,类似于RMSprop。这导致了一个明显的结论,即Adam是Momentum和RMSprop的结合版本。从上图中我们可以很容易地看出为什么Adam是deep learning中最流行的优化器。即使从离最优值(-6,-6)很远的地方开始,Adam也能以最小的迭代收敛得最快。
作者:Saket Thavanani

觉得不错,请点个在看呀
以上是关于使用Numpy进行深度学习中5大反向传播优化算法的性能比较的主要内容,如果未能解决你的问题,请参考以下文章