大数据云原生时代,为什么说湖仓一体代表了未来?
Posted 全球云观察
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据云原生时代,为什么说湖仓一体代表了未来?相关的知识,希望对你有一定的参考价值。
20年发展至今,大数据因其4V的显著特点与复杂性,带给了业内诸多技术争论,尤为持久又备受关注的便是数据湖与数据仓库。
本来这两个系统各自为阵发展了多年,最终却在阿里云工程师们的努力下,实现了湖仓一体化的统一。
当然,湖仓一体化的出现,并非巧合,而是来自一个著名客户的真实需求。
那么,故事要从2015年说起……
新生之道
2015年,是一个不平凡之年。从娱乐圈到社会各界,各种社会热点层出不穷, 各种文化事件也是此起彼伏,引起公众在微博上的广泛关注和热议。
热点事件的微博热议,自然带来了微博后台数据处理能力的挑战。
也在这一年,阿里云与微博的合作也开始了。
从2017年开始,阿里云与微博共同携手。双方在大规模机器学习技术、内容理解技术方面展开了深入研究,在确保算法训练的效率和及时性上,取得了显著效果。
2019年春节,微博平台的扩容规模达到了1300台服务器。通过微博自研的DCP管控平台,实现热点事件的自动扩缩容,带来了针对热点事件流量处理的常态化自动化。
然而,随着时间的推移,微博基于大数据需求发展了数据仓库平台,基于AI需求发展了数据湖平台,这两套平台系统在集群层面处于完全割裂状态,数据和计算无法在两个平台里自由流动。
为此,微博希望打造统一的大数据平台,既保持面向AI的各类数据和计算的灵活性,又解决超大规模下计算和算法的性能以及成本问题。
微博自身的发展需求带来的技术挑战,最终在阿里云MaxCompute产品团队和微博机器学习平台团队联合共建“湖仓一体”新技术下得到解决。就此,奇迹般地打通了MaxCompute云数据仓库和开源Hadoop数据湖,为微博构建了一个跨湖和仓的AI计算中台。
2020年1月9日,微博首次成功演示了数据湖和数据仓库的数据和元数据打通。
2020年4月,湖仓一体在微博生产系统正式应用。微博的深度学习和机器学习训练任务以及各种数据处理任务通过湖仓一体技术,实现数据仓库MaxCompute和数据湖EMR之间的无缝调度。从那之后,在两套体系之上,真正实现了统一的元数据管理和数据开发体验。
微博实现“湖仓一体”技术方案的落地,引发了业内广泛的讨论与关注。
对此,阿里巴巴集团副总裁、阿里云计算平台负责人贾扬清解释说,阿里云的数据仓库MaxCompute通过全面升级网络基础设施,提供了数据仓库到用户VPC私网的高速安全网络通道,同时可以将Hive存储的元数据信息一键映射到数据仓库中。并且再配合数据仓库完善的SQL、PAI引擎能力,最终无缝对接MaxCompute和Hadoop数据库技术体系,实现湖仓一体化的统一智能化管理和调度。
从此,微博摆脱了繁重的数据搬迁,平台化服务能力获得极大提升。借助阿里巴巴成熟的超大规模计算能力和算法赋能业务提效,并且实现数据仓库加数据湖的闭环,极大提升了AI类作业的效率,将数据湖的灵活性和数据仓库的性能成本,云原生优势充分结合,形成互补,从而达到成本节约。

2020年9月18日,在2020云栖大会上,阿里云正式推出“湖仓一体”的下一代大数据平台。不仅打通数据仓库和数据湖两套体系,而且让数据和计算在湖与仓之间自由流动,从而构建一个完整的有机的大数据技术生态体系。
前世今生
事实上,湖仓一体的技术架构,并非空想,而是源自全球知名中文社区的微博最佳实践。从实践中来,到实践中去,成为了湖仓一体化架构诞生的基本路径。
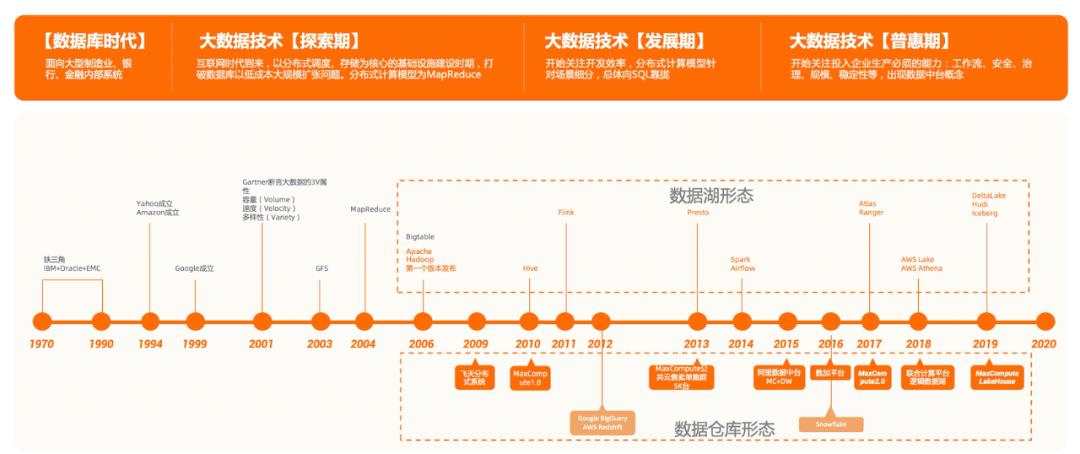
然而,在回顾数据仓库和数据湖的前世今生中,我们不免发现,数据的发展史历经了50多年的时间,而大数据发展也历经了20多年,其间可以简单概括为四个标志性的发展阶段。

第一阶段,从1970年到2000年左右,属于数据库时代。
以“IOE”为代表的架构下,数据库发展走过了30年的风雨历程。但在20 世纪 90 年代,数据仓库的概念诞生。但受制于传统数据库的处理能力与高昂价格,此时的数据仓库仅处于启蒙时期,距离普通企业和用户还很遥远。业界当时甚至还在争论数据仓库和数据集市哪个更具可行性。
第二阶段,从2001年到2009年左右,属于大数据技术的探索期。
随着互联网的爆发,动辄几十亿、上百亿的页面以及海量的用户点击行为,开启了全球的数据量急剧增加的新时代。
2003、2004、2006年Google先后发布有关GFS、MapReduce、BigTable的3篇经典论文,奠基了这个大数据时代的基本技术框架,即分布式存储、分布式调度以及分布式计算模型。
在随后的同一时期里,诞生了包括Google、微软Cosmos、阿里巴巴飞天系统以及开源Hadoop为代表的分布式技术体系。这个时期业界强调的核心是大数据的海量,当然以分布式调度、存储与计算为核心的基础设施建设,在一定程度上也打破了传统数据库的高成本壁垒,可以低成本实现数据的大规模采集、存储和分析。
第三阶段,从2010年到2015年左右,属于大数据技术的发展期。
随着越来越多的资源投入到大数据计算领域,大数据技术进入一个蓬勃发展的阶段,整体开始从能用转向好用。业界开始关注开发效率,分布式计算模型针对场景细分,各种以SQL语言为表达的计算引擎如雨后春笋般出现,也极大降低了大数据技术的使用成本。
由此业界浮现了数据仓库和数据湖两条发展路径。云厂商主推的如AWS Redshift、Google BigQuery、Snowflake,以及阿里云MaxCompute等集成系统被称为数据仓库。
而以开源Hadoop技术体系为代表HDFS存储、开放文件格式、开放元数据服务以及Hive、Presto、Spark、Flink等多引擎协同工作的模式,逐渐形成了数据湖的形态。
第四阶段,从2016年到现在,属于云原生时代。
随着云原生被更广泛接受,降低了大数据使用门槛,也标志着大数据的普惠期已经到来。
当前,业界对大数据产品的要求,包括了规模、性能、简单易用、成本、安全、稳定性等更全面满足企业级生产要求的维度。
在数据湖路线上,开源Hadoop得到广泛关注,大家对开源大数据技术的认知达到空前的水平。虽然赢得了不错市场份额,但是开放架构的松散则使开源方案在企业级能力构建上遇到瓶颈,尤其是数据安全、身份权限强管控、数据治理等方面,协同效率较差,甚至出现裂痕。
后来还是云厂商AWS真正将数据湖概念推广开了。AWS构筑了一套以S3为中心化存储、Glue为元数据服务,E-MapReduce、Athena为引擎的开放协作式的产品解决方案,在2019年推出Lake Formation解决产品间的安全授信问题。
AWS之后,各个云厂商在数据湖领域纷纷跟进,并在自己的云服务上提供类似产品解决方案。
在数据仓库路线上,云厂商也持续给力。如阿里云的MaxCompute,在核心能力方面持续增强,其性能、成本方面也获得极大改善。后来MaxCompute完成了核心引擎的全面升级和性能跳跃式发展,连续3年刷新TPC-BB世界记录。
当前,MaxCompute数据管理能力空前增强,拥有了数据中台建模理论、智能数仓。企业级安全能力也大为繁荣,同时支持基于ACL和基于规则等多种授权模型,实现列级别细粒度授权,可信计算,存储加密,数据脱敏等安全技术。在联邦计算方面也普遍做了增强,一定程度上开始将非数仓自身存储的数据纳入管理,与数据湖的边界日益模糊。
因此,数据仓库虽然是诞生在数据库时代的方法论,但是直到大数据技术诞生才得以落地,成为一种大数据系统的架构。数据仓库提供了基于数据抽象的统一存储,强调数据的清洗、建模和管理,以极高的数据存储、计算能力,完善而精细的数据管理能力,成为了建设企业级数据中台的上佳选择。
争夺大战
随着数据湖与数据仓库两条大数据路线的进一步发展,自然也就出现了众多厂商试图都往“湖仓一体化”方向尝试,在抢跑过程中,虽然百花齐放,但一直未见硕果。
▏一方面,从数据仓库向数据湖融合做的尝试。
2017年AWS Redshift推出Redshift Spectrum,支持Redsift数仓用户访问S3数据湖的数据。开始在AWS产品体系内,尝试打通数据仓库到数据湖统一存储的边界。
2018年阿里云MaxCompute推出外表能力,支持访问包括OSS/OTS/RDS数据库在内的多种外部存储。实现阿里云产品体系内数仓产品到数据湖统一存储的打通。
此时,这类数据仓库到数据湖的打通,仍然停留在各自的技术体系内,而且是从存储层进行打通,上层元数据仍然要在数据仓库中人工重建,易用性较差,只适用于低频查询。
▏另一方面,从数据湖向数据仓库融合做的尝试。
2011年,Hadoop开源体系公司Hortonworks开始了Apache Atlas和Ranger两个开源项目的开发,分别对应数据追踪和数据权限安全两个数仓核心能力。
但是这两个开源项目的活跃度一直不高,经过了6年时间,直到2017年才完成孵化。且发布周期较慢,相较同时期的Spark、Flink等开源项目完全不可同日而语。
此外,如将Ranger作为权限管控组件、Atlas作为数据追中治理组件,与今天的主流引擎仍旧无法做到全覆盖。社区对此认识不足,开源产品背后的各商业公司又难以达成一致,这极大限制了开源数据湖产品在这两个维度上的能力。
由此可见,数据湖这样一个统一存储、各引擎和组件松散协同的组织方式,在建设需要强管控特性的企业级能力方面存在着天然效率不足的问题。
2018年,Nexflix开源了内部增强版本的元数据服务系统Iceberg,提供包括多版本和多版本并发MVCC在内的增强数仓能力。
2018-2019年,Uber和Databricks相继推出了Apache Hudi和DeltaLake,均推出Delta文件格式用以支持Update/Insert、事务等数据仓库功能。新功能带来文件格式以及组织形式的改变,打破了数据湖原有多套引擎之间关于共用存储的简单约定。
这三个开源项目虽然出发点不尽相同,但是目标都指向了本该是统一的中心元数据服务,在开源数据湖体系中造成了事实上的混乱。
然而,在这场从数据仓库到数据湖,或从数据湖到数据仓库的湖仓一体化争夺大战中,阿里云从微博的大数据实际应用出发,强强联合构建并成功落地了真正的“湖仓一体化”架构和方案,通过技术手段把数据湖和数据仓库两套不同的架构体系融合在一起,向上对微博提供统一无缝的数据开发和管理体验。
破解难题
通过历史脉络和技术发展路径的回顾,大家不难发现数据湖与数据仓库有着本质区别。如何让一套架构里面具备数据湖灵活性,兼有数据仓库的成长性,其中充满技术挑战。想要应对这个挑战,破解这个难题,那么需要在对比两者的区别与优劣基础上,做进一步分析。
//对于数据湖来说,属于事后建模的方式,其存储类型包括了结构化、半结构化与非结构化的所有类型数据,向计算引擎全面开放但各个引擎优化受限。数据湖虽然易于启动,但难在运维管理,在数据治理上也显得质量低下。
//对于数据仓库来说,属于事先建模的方式,其存储类型包括了结构化与半结构化的两类数据,向特定的计算引擎开放但易于实现引擎的高度优化。数据仓库虽然难于启动,但易于运维管理甚至免运维管理,在数据治理上也显得质量高。

就此分析,数据湖和数据仓库的两套系统是非常矛盾,也是非常互补。
对于任何用户来说,想要同时拥有云数据仓库高性能、低成本和管理能力,以及享受到数据湖的灵活性。两套系统在一起,需要明确两个方面的重要问题。
问题一,哪些数据放数据仓库,哪些数据放数据湖?
对于数据放数据仓库,对于数据放数据湖。数据与业务分成已知与未知两大类,对于已知数据与已知业务,更容易建模和优化那么可以放在数据仓库,对于未知和探索性的数据、业务那就适合放数据湖。
问题二,两套系统合二为一,如何打通?
一是,需要建立统一的数据与源数据的存储体系;二是,通过智能数据仓库技术,根据不同数据和业务特点做自动分类和处理。
三是,通过DataWorks开发平台,向上层形成形成统一开发、数据管理与数据治理的体验。
从而将两套系统形成统一,打破数据湖与数据仓库割裂的体系,架构上融合数据湖的灵活性与生态丰富性,同时兼有数据仓库的企业级能力与成长性。对于用户基于存储计算一体化数据湖还是基于云上分离式数据湖,只要与数据仓库形成一体化之后,就形成了数仓一体化的架构。
对此,阿里巴巴集团副总裁、阿里云计算平台负责人贾扬清分析指出,在阿里云的湖仓一体化架构设计上,实现了技术栈各个层面的创新融合。
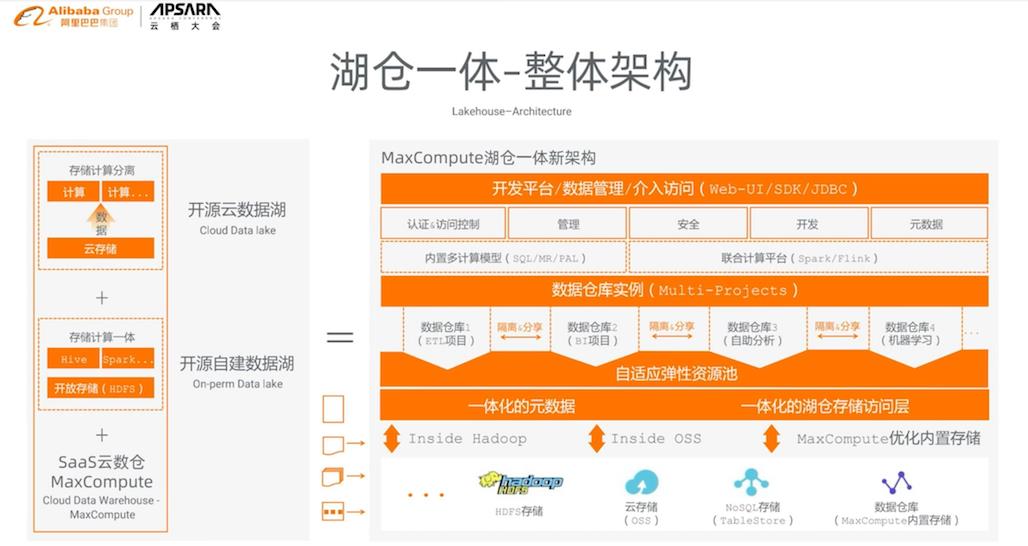
最下层为多套存储系统并存,但是其存储系统是打通的。实现了数据仓库和数据库之间的数据智能缓存加速和互访,针对元数据要实现了统一的数据管理和透视。
向上一层,有一个统一的云数据管理与治理,用来保证数据访问的安全性、统一性和可解释性。这样可以利于保证用户数据访问的一体化体验。
向上对于计算引擎而言,实现了实现异构计算集群之间的网络打通。多套引擎可以通过不同元数据访问不同存储组件中数据。因而对于上层引擎而言,下层是一体化的。
从用户视觉来看,如果有用户想整合数据湖与数据仓库的两张表,可以非常容易实现,甚至在元数据层面看到的就是一套系统。
再向上第三层,有一个统一认证、管理和数据治理的开发体验,也就是DataWorks平台。由此再向上形成数据统一管理与治理的能力,这就是阿里云的数据中台。支持湖仓一体,以及多种形态的数据分析和计算,以此更有效地支持各种应用业务。通过这样的方式,形成阿里云的数据湖与数据仓库的湖仓一体化架构。
非常显然,要实现数据湖和数据仓库之间的无缝流转,就需要打通不同层面。对用户来说,湖仓一体化的意义非凡,不需要看见湖和仓,元数据已经实现打通互访,数据可以自由流动,自由对接上层多样化的计算生态。
与此同时,基于阿里云构建的湖仓一体解决方案,为用户带来了全新价值,包括可以享受到一致的数据体系,一致的开发体系,以及智能缓存,冷热分层,性能加速和跨平台的计算等创新技术。
整体而言,阿里云提供的湖仓一体化架构的技术特点非常突出,覆盖异构集群、存储层、计算层与中台层。
▏一是,保持了数据湖灵活性,保持数据快速接入。
无论是IDC用户还是云上自建Hadoop用户,通过简单开通步骤就可以和购买的MaxCompute资源互相连通。
▏二是,具备数据开发与治理管理的体验。
从用户视觉来看,具备了统一的数据与元数据管理的特点。Hadoop集群中的Hive Database可以直接映射为MaxCompute Project,享受数据仓库配套的工具链。
▏三是,实现了统一开发体验。
基于DataWorks平台强大的数据开发、管理与治理能力,提供统一的湖仓一体开发体验,从而降低两套系统的管理成本。
▏四是,数据湖与数据仓库之间的数据实现智能化搬迁。
由相对智能化的创新模块“自动数仓Auto Data Warehouse”来完成,通过后台自动学习用户访问和引擎对数据访问,自动搬迁数据湖与数据仓库的数据,有自动Cashe能力加速读数据,也有资源自动平衡能力,进一步将数据湖与数据仓库资源打通,极大降低了数据迁移和作业迁移的难度。在统一管理框架下,用户可以根据自身资产使用情况来构建混合计算架构,通过合理的数据分层,同时享受数据湖带来的灵活性以及MaxCompute带来的企业级数据仓库能力。
可见,技术架构的融合与创新,让湖仓一体化的技术优势得到了充分体现。这也是破解难题的技术“杀手锏”。
小结:湖仓一体代表了未来
20年的大数据发展史,让我们看到了随着数据湖与云数据仓库的不断创新与发展,也让我们看到了以湖仓一体化为核心的技术架构,对微博大数据的价值发挥带来了更为重要的现实意义。
特别是处于云原生+大数据的时代,湖仓一体更能综合发挥出数据湖的灵活性与生态丰富性,以及云数据仓库的成长性与企业级能力。
湖仓一体的能力,也明显大于单一的数据湖,大于单一的数据仓库。潮平两岸阔,风正一帆悬。毋庸置疑,湖仓一体代表了未来。
(by Aming)

以上是关于大数据云原生时代,为什么说湖仓一体代表了未来?的主要内容,如果未能解决你的问题,请参考以下文章
数仓架构的持续演进与发展 — 云原生湖仓一体离线实时一体SaaS模式