离线实时一体化数仓与湖仓一体—云原生大数据平台的持续演进
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了离线实时一体化数仓与湖仓一体—云原生大数据平台的持续演进相关的知识,希望对你有一定的参考价值。
简介: 阿里云智能研究员 林伟 :阿里巴巴从湖到仓的演进给我们带来了湖仓一体的思考,使得湖的灵活性、数据种类丰富与仓的可成长性和企业级管理得到有机融合,这是阿里巴巴最佳实践的宝贵资产,是大数据的新一代架构。

林伟,阿里云智能研究员、阿里云智能通用计算平台MaxCompute、机器学习PAI平台技术负责人
本篇内容将从三个部分为读者讲述离线实时一体化数仓与湖仓一体—云原生大数据平台的持续演进。通过从数据湖到数仓的历史,反思为什么要做湖仓一体,以及湖仓一体在今天这个阶段为什么开始做离线和实时湖仓一体化的数仓。
- 湖仓一体
- 离线在线数仓一体化
- 智能数仓
希望这次的分享让大家进一步理解我们为什么做湖仓一体。
一、湖仓一体
(1) 阿里巴巴从数据湖到数仓历程
2007年的宁波战略会议确定建立一个开发、协同、繁荣的电子商务生态系统,其中生态系统的核心是数据。但这个时候各个业务部门都在垂直式发展数据能力,用数据支撑商业的决策服务。这些数据中台支撑了业务部门的发展。但我们发展到一个阶段的时候,希望进一步挖掘出各个业务部门数据之间的关联性,从而利用这些高阶数据分析挖掘更高商业价值,我们遇到了很多的困难,因为数据来自不同的部门,不同的人会提供你不同的数据集,没有清晰数据质量监控,你也不知道这些数据是不是完整的,你就需要花费很多时间不停的去校准数据。这个过程耗时太长且多数情况会做了非常多的无用功,这样其实整体下降了公司的效率。
所以到了2012年,我们决定将所有的业务部门的数据都关联起来,决心做『One Data,One Service』。其实这个过程就是典型一个数据湖升级到数仓的过程,但是因为我们缺乏很好湖仓一体的系统沉淀,这个过程非常艰难,我们称之这个过程为“登月”。大家可以从这个名字可见中间的艰难。在这个时间段,各个团队甚至需要停下日常的自身业务发展来配合整理数据,把所以原来已有的数据分析过程,搬到统一一套数仓系统上面。最终我们历经18个月,在花了非常大的代价,于2015年的12月完成建立了统一大数据仓库平台建立,这就是阿里巴巴的MaxCompute。通过这个统一数仓平台,无论是业务团队、服务商家还是物流或其它环节都可以方便,迅捷,更好的挖掘商机。所以大家可以看到在阿里巴巴统一的大数据平台完成后,业务成长也进入了快车道。这正是因为有更好的数据支撑,才使得商家、客户都能快速的进行一些商业决策。
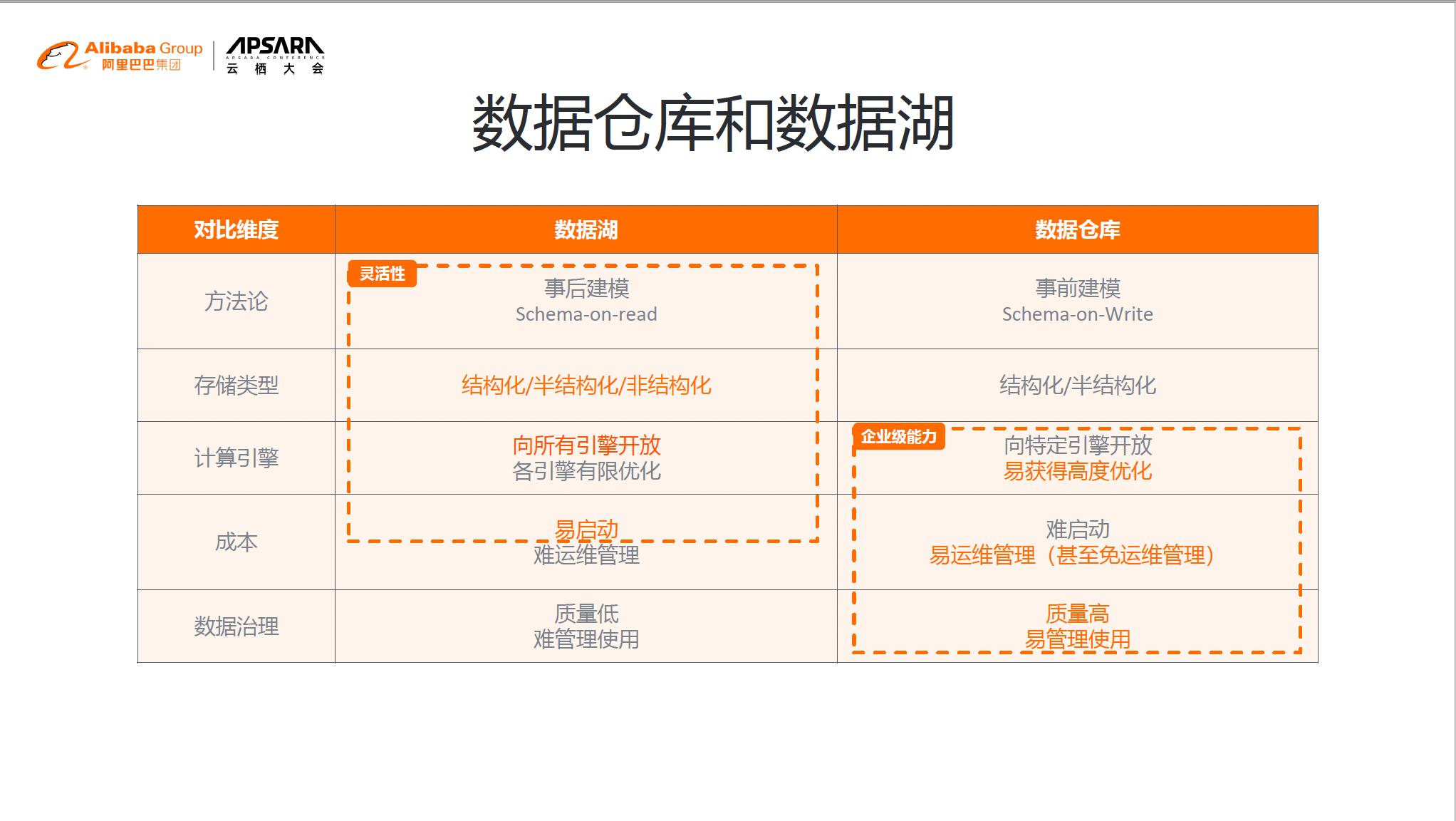
(2) 数据仓库和数据湖的关系
从开发人员的角度看,数据湖更为灵活,更喜欢这种随心所欲的模式,任意的引擎都可以去读、写,没有约束,启动也非常容易。
从数据管理者角度看,数据湖能作为起步,但达到特定规模时,把数据当作资产或者需要做更大的商业决策的时候,都希望有一个很好的数仓。
(3) 数据仓库和数据湖系统的增长曲线

上图的增长曲线,基本上也是阿里发展的曲线,最开始也是数据湖状态,各个业务部门独立发展,起步快、灵活性强。但当达到特定规模时,数据无人管理、每个业务部门的数据的逻辑语言不一致,很难对齐。所以当时花了50%、80%的无效时间在校验数据,随着规模的不断扩大,这样的损耗越来越大,迫使我们推动公司统一数据仓库的建立。
(4) 湖仓一体
正是因为我们经历过堪比“登月”的痛苦,所以我们不希望MaxCompute未来的企业客户也经历这么痛苦过程,所以我们构建湖仓一体的开发平台。当公司规模较小的时候,可以运用数据湖能力更快定制自己的分析。公司成长到一定的阶段,需要更好的数据管理和治理方式的时候,湖仓一体平台可以无缝把数据以及数据分析进行有效的升级管理,使得公司对于数据管理更加规范。这就是湖仓一体整体设计背后的核心思想。
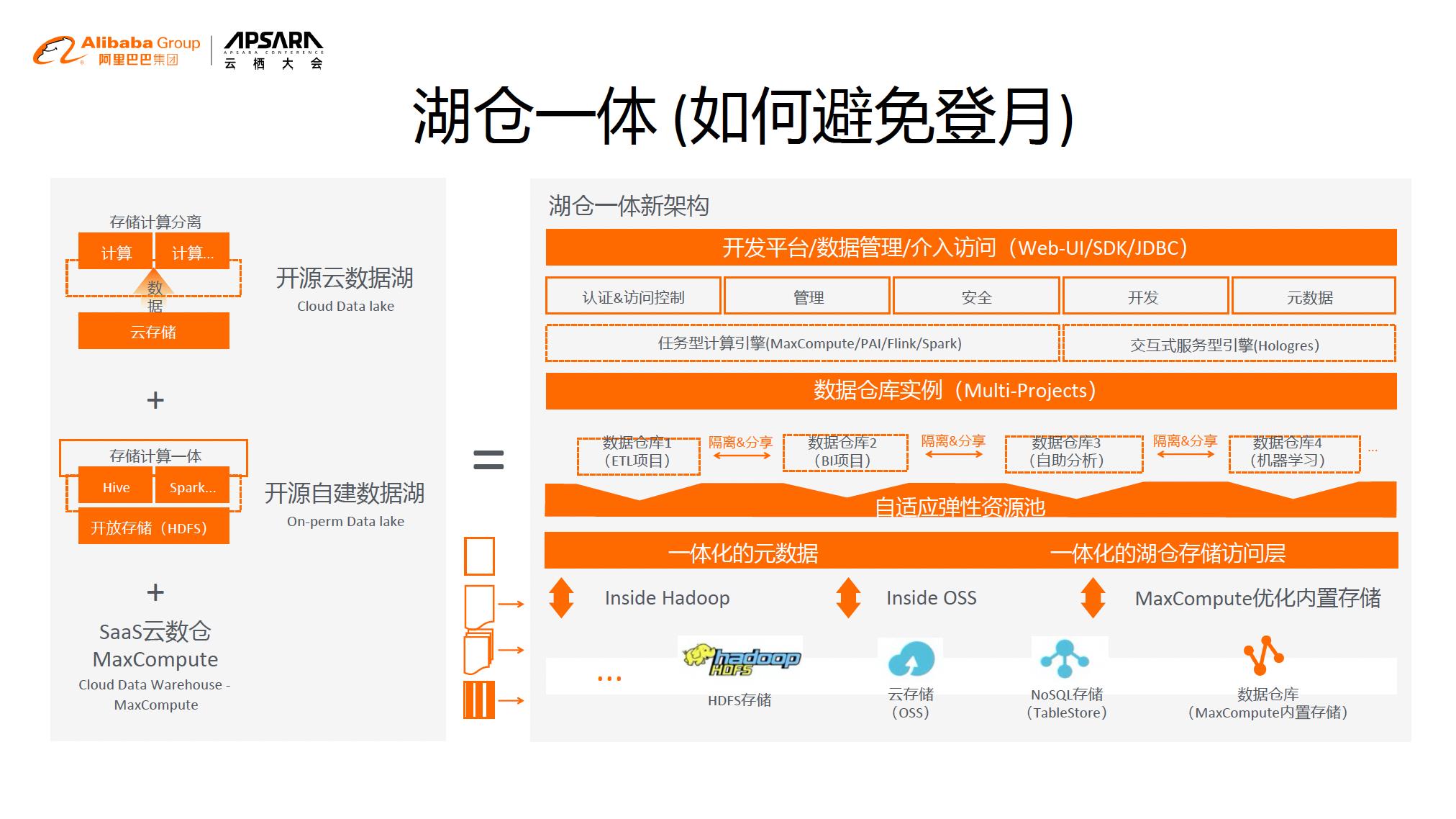
我们把湖的系统和仓的系统有机结合在一起,一开始是没有元数据,你想要建立数仓的时候,我们有可以在湖上面来抽取这个元数据,这个元数据是和仓的元数据放在一个一体化的元数据的分析平台上面。在这个元数据之上可以建立很多数据仓库的数据管理平台。
同时,在数据仓库湖仓一体的平台上面,我们有效支持很多分析引擎,有任务型的计算引擎,包括像MaxCompute是批处理、Flink是流式处理、机器学习等,还有开源的组件可以分析我们的数据;也有服务性质数据引擎可以支持交互式查询服务,能够去更加实时性很好的展示我们的数据,从而使得用户可以在这个服务性引擎上去构建自己数据服务应用。
在引擎之上我们构建丰富数据管理工具从而能够让业务部门能够进行高效整体的数据治理。而这都得益于我们把湖和仓的数据打通,这也是整体湖仓一体设计的核心。
二、离线在线数仓一体化
现今社会越来越便捷,客户需要更快的做出商业决策。在双十一GMV实时大屏、春晚直播实时大屏等数据分析,以及机器学习从离线模型走向在线模型的趋势中我们都可以看到。这些需求推动了实时数仓的发展。
其实实时数仓和离线数仓有着相似的发展过程。当时实时系统发展的早期,我们首先考虑的是引擎,因为只有先有引擎了你才可以进行实时数据分析,所以阿里巴巴把研发精力放在Flink这样的流计算引擎上。但是只有流计算引擎,类似数据湖的阶段,我们缺乏将分析出来的结果数据进行管理,所以到了第二阶段,我们利用我们离线数仓产品来管理这些分析结果,从而把分析结果纳管到我们整体数据仓库和数据管理中。但是把实时分析之后的结果放在离线数仓里面,显然这样是对于实时商业决策是不够的及时。所以我们现在发展第三个阶段:实时数仓。
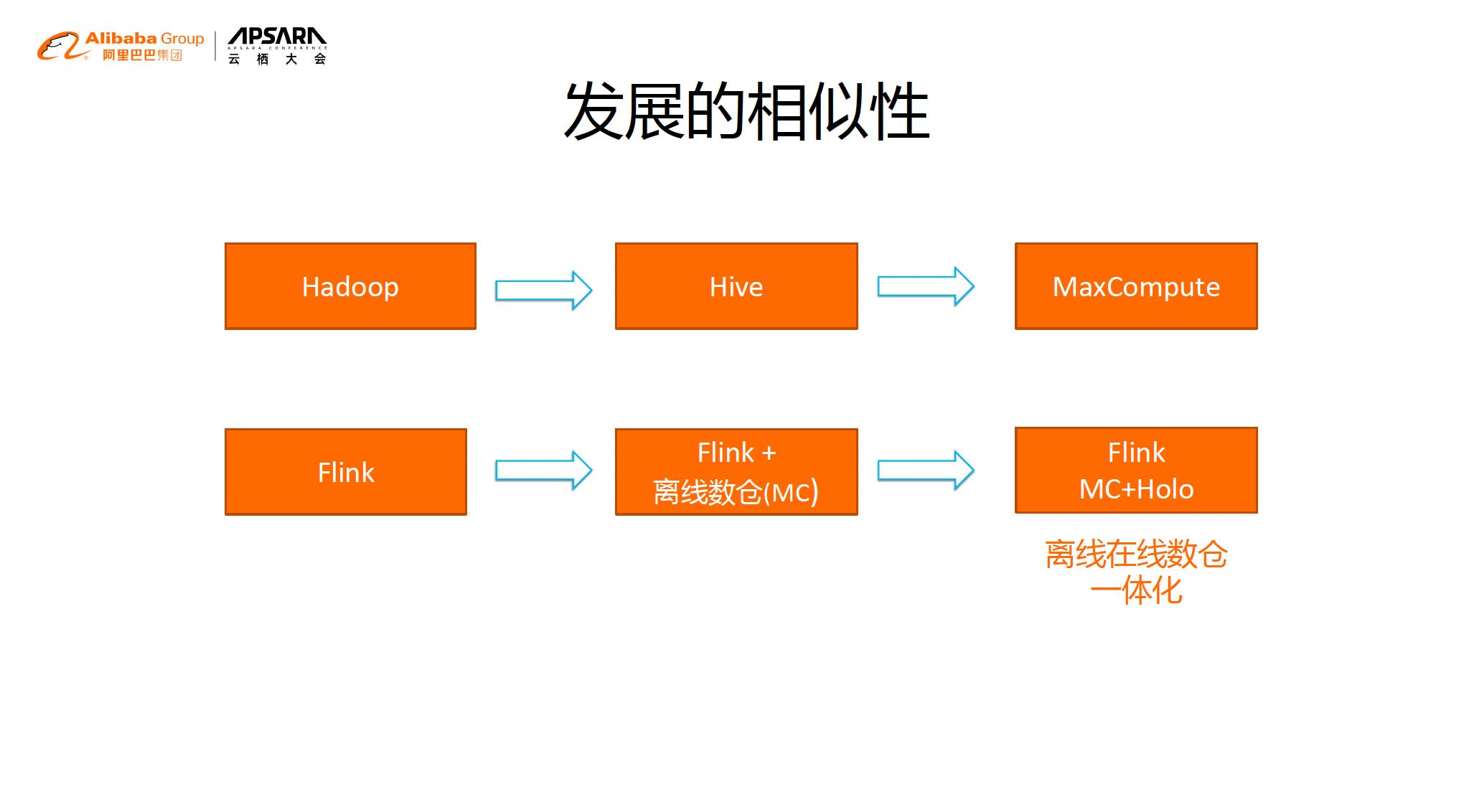
我们会把流式引擎的分析结果结果实时的写到实时数仓Hologres里面,从而能够让分析的结果更实时的进行BI的分析,从而有效的支持客户实时商业决策。
这就是离线和在线数仓一体化的设计。

总结一下,原有的分析在离线和在线的数仓一体化之前是一个很纷繁的过程,有离线、有在线的、有很多不同的引擎,现在把它总结到或者简化成上图的架构。我们会用实时的引擎做预处理,做完预处理后,我们把这些数据写入到MaxCompute离线的数仓,也可以同时写入到Hologres实时数仓中里面,从而可以做更加实时的服务化的BI分析。而MaxCompute离线的数仓存储的成本更低,吞吐的性能更好,可以做大量的离线数据分析,这就是离在线数仓一体化的设计。
有了一体化的设计,就可以给客户带来一个非常平衡的系统。根据数据的场景或者是业务的场景,你可以用批处理。并且通过数据的压缩、冷存,数据根据热和冷的方式做不同梯度的存储,就可以得到更低成本的离线分析。
当对于数据的实时性的价值更加重视,可以用流计算的引擎去做。同时又希望有很快的交互式,希望快速通过各种方式的、各种维度、角度去观察已生成好的报表。这时候可以利用交互式引擎,在高度提纯过数据后的进行各个维度的洞察。
希望用湖仓一体化平台就能够达到一个好的平衡,根据实际的业务体量、要求、规模成本达到更好点。

总的来说,希望湖仓一体系统上,不管是离线还是在线。通过不同的分析引擎,支持各类分析,同时通过在线服务型引擎能够实时进行BI,能够达到低成本、自定义能力,以及实时和在线服务的各种平衡。让客户能够根据实际业务场景选择。
三、智能数仓
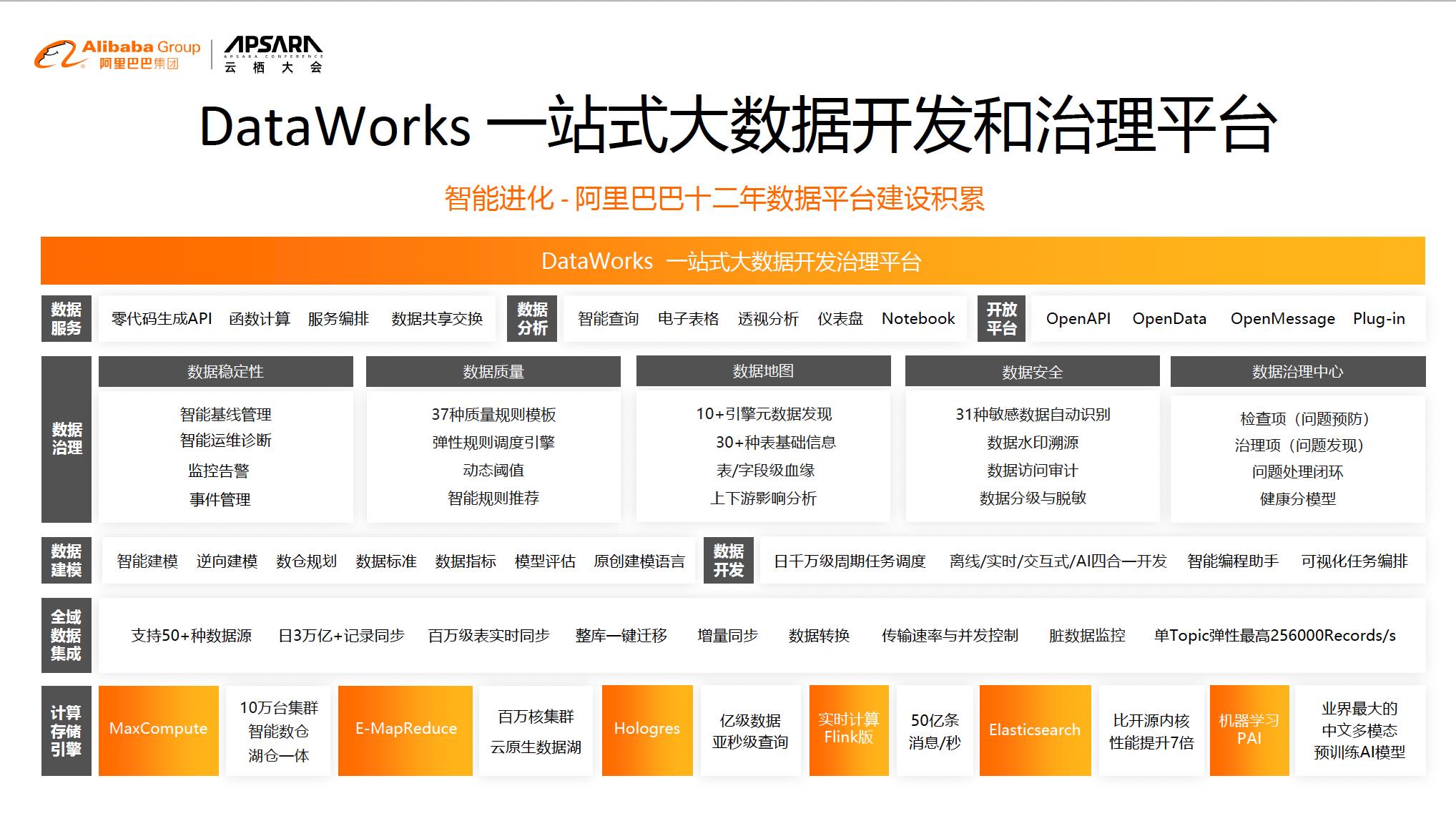
有了统一的数仓平台,我们就可以在此之上建立强大的数据治理或者是分析平台,这个就是我们的DataWorks。在这个平台上面有很多数据建模工具,提供数据的质量和标准、提供血缘的分析、提供编程助理等等。正是因为湖仓一体在线和离线的一体化的底座能力,才赋予了我们有这样的可能性去做到大数据开发和治理平台更加智能化的方式。从而将更多经过验证过有效数据治理经验分享到我们企业客户上。
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于离线实时一体化数仓与湖仓一体—云原生大数据平台的持续演进的主要内容,如果未能解决你的问题,请参考以下文章
数仓架构的持续演进与发展 — 云原生湖仓一体离线实时一体SaaS模式