Hadoop完全分布模式的搭建
Posted hei-yan-quan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop完全分布模式的搭建相关的知识,希望对你有一定的参考价值。
Hadoop完全分布模式的搭建
1.安装前准备
在VMware安装3台Ubuntu16.04的虚拟机并且都安装jdk。采用ifconfig命令查看IP地址,
我的IP地址依次是:
192.168.17.135
192.168.17.136
192.168.17.137
IP地址建议设置成固定IP地址
2.修改主机名
(1)修改第一台主机名称为node1。
sudo vi /etc/hostname
将原有内容删除,添加如下内容。
node1
重启使之生效。
sudo reboot
(2)修改第二台主机名称为node2。
sudo vi /etc/hostname
将原有内容删除,添加如下内容。
node2
重启使之生效。
sudo reboot
(3)修改第三台主机名称为node3。
sudo vi /etc/hostname
将原有内容删除,添加如下内容。
node3
重启使之生效。
sudo reboot
3.映射IP地址及主机名
对3台虚拟机,依次修改/etc/hosts文件。
sudo vi /etc/hosts
在文件末尾添加如下内容。注意:IP地址要根据实际情况填写。
192.168.17.135 node1
192.168.17.136 node2
192.168.17.137 node3
4.免密登录设置
在完全分布式模式下,集群内任意一台主机可免密登录集群内所有主机,即实现了两 两免密登录。免密登录的设置方法和伪分布模式的免密登录设置方法一样,分别在 nodel.node2.node3主机上生成公钥/私钥密钥对,然后将公钥发送给集群内的所有主机。 下面以node1免密登录集群内其他所有主机为例进行讲解。在完成nodel主机免密登录 集群内其他主机后,其他两台主机可仿照node1的步骤完成免密码登录设置。
(1)在nodel主机生成密钥对。
ssh-keygen -t rsa
其中,rsa表示加密算法,键人上面一条命令后连续敲击三次回车键,系统会自动在~/. ssh目录下生成公钥(id_rsa.pub)和私钥(id_rsa),可通过命令$ls~/ssh查看。
ls ~/.ssh
id_rsa id_rsa.pub
(2)将node1公钥id_rsa.pub复制到node1、node2和node3主机上。
$ ssh-copy-id-i ~/.ssh/idrsa.pub nodel
$ ssh-copy-id -i ~/.ssh/id rsa.pub node2
$ ssh-copy-id-i ~/.ssh/id rsa.pub node3
(3)验证免密登录:在nodel主机输人一下命令验证,注意主机名称的变化。
$ ssh node1
$ ssh node2
$ ssh node3
5.安装NTP服务
完全分布式模式由名台主机组成,各个主机的时间可能存在较大差异。如果时间 异较大,执行MapReduce程序的时候会存在问题。NTP服务通过获取网络时间使集群内不同主机的时间保持一致。默认安装Ubuntu操作系统时,不会安装NTP服务。
在3台主机分别安装NTP服务,命令如下(在安装NTP服务时需连接互联网):
$ sudo apt-get install ntp
查看时间服务是否运行,如果输出有“ntp"字样,说明NTP正在运行。
$ sudo dpkg -1 | grepntp
6.安装Hadoop
下载hadoop2.7.3的安装包
下载地址:http://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/

解压安装包
将下载的hadoop-2.7.3.tar.gz文件通过Xftp等工具上依次传到3台Ubuntu的~/soft目录下中。
注意:
Xftp需要先安装,安装方法自行百度,上传成功后ls命令查看有hadoop-2.7.3.tar.gz
cd ~/soft #注意:soft目录如果不存在,需要先用mkdir ~/soft命令创建
ls
hadoop-2.7.3.tar.gz
解压安装包
$ tar -zxvf hadoop-2.7.3.tar.gz
解压后ls查看发现多了一个目录hadoop2.7.3
$ ls
hadoop-2.7.3.tar.gz hadoop-2.7.3
创建软链接,方便使用
ln -s hadoop-2.7.3 hadoop
配置Linux环境变量
$ nano ~/.bashrc
在文件末尾添加
export HADOOP_HOME=~/soft/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
让环境变量立即生效
$ source ~/.bashrc
另外两台Ubuntu主机node1、node2也按如上安装。
7.设置Hadoop配置文件
在node1主机进行操作。进人node1主机的Hadoop配置文件目录${HADOOP HOME}/ etc/hadoop。
$ cd~/hadoop/etc/hadoop
(1)设置hadoop-env.sh
vi hadoop-env.sh
找到含有export JAVA_HOME=${JAVA_HOME}一行,将等号后面的内容删除,换成JAVA_HOME的绝对路径,
export JAVA_HOME=自己jdk的绝对路径
(2)设置core-site.xml.
$ vi core-site.xml
在<configuration与</configuration之间添加配置内容
添加的配置如下:
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
<!-- 以上主机名node1要按实际情况修改 -->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/jsy/soft/hadoop/tmp</value>
<!-- 以上jsy为用户名要修改成自己的 -->
</property>
(3)设置hdfs-site.xml。
$ vi hdfs-site.xml
同样在<configuration与</configuration之间添加配置内容,配置内容如下:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
(4)配置mapred-site.xml
原来没有mapred-site.xml文件,由mapred-site.xml.template复制出mapred-site.xml
$ cp mapred-site.xml.template mapred-site.xml
配置 mapred-site.xml
vi mapred-site.xml
同样在<configuration与</configuration之间添加配置内容,配置内容如下:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(5) 配置yarn-site.xml
vi yarn-site.xml
同样在<configuration与</configuration之间添加配置内容,配置内容如下:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
注意:node1为主机名,注意按实际修改。
(6) 配置slaves
vi slaves
将原有内容删除,添加以下内容。
node2
node3
(7)分发配置。
将node1的配置文件分发至node2和node3主机。
$ cd~/hadoop/etc/
$ scp-r hadoop jsy@ node2:~ /hadoop/etc/
$ scp-r hadoop jsy@ node3:~ /hadoop/etc/
8.格式化HDFS
在nodel主机操作,命令如下:
$ hdfs namenode -format
9.启动Hadoop
启动命令只需在node1主机操作。
采用下面命令分别启动HDFS和YARN。
$ start-dfs.sh
$ start-yarn.sh
或者用以下命令启动HDFS和YARN。
$ start-all.sh
10.验证Hadoop进程
用jps命令分别在所有主机验证。
$ jps
nodel主机包含以下3个进程表示启动Hadoop成功。
$ jps
SecondaryNameNode
NameNode
ResourceManager
在node2和node3主机分别执行jps命令,均包含以下两个进程表示启动Hadoop成功。
$ jps
NodeManager
DataNode
如果某个主机少了某个进程,应该到对应主机去找相关的log查看原因,log存放 在$ {HADOOP_HOME}/logs目录下。例如,node3主机少了DataNode进程,则应该进 人node3主机的${HADOOP_HOME}/logs目录下,查看DataNode相关的log,找到含有 “WARN” Error”"Exception”等的关键字句,通过上网搜索关键字句找到解决问题的 办法。
$ ssh node3
$ cd~ /hadoop-2.7.3/logs
$ cathadoop-hadoop-datanode-node3.log
也可以通过vi命令查看。
$ vi hadoop-hadoop-datanode-nodel.log
最新出现的错误,其信息都在文件末尾。
11.通过Web访问Hadoop
(I) HDFS Web界面。
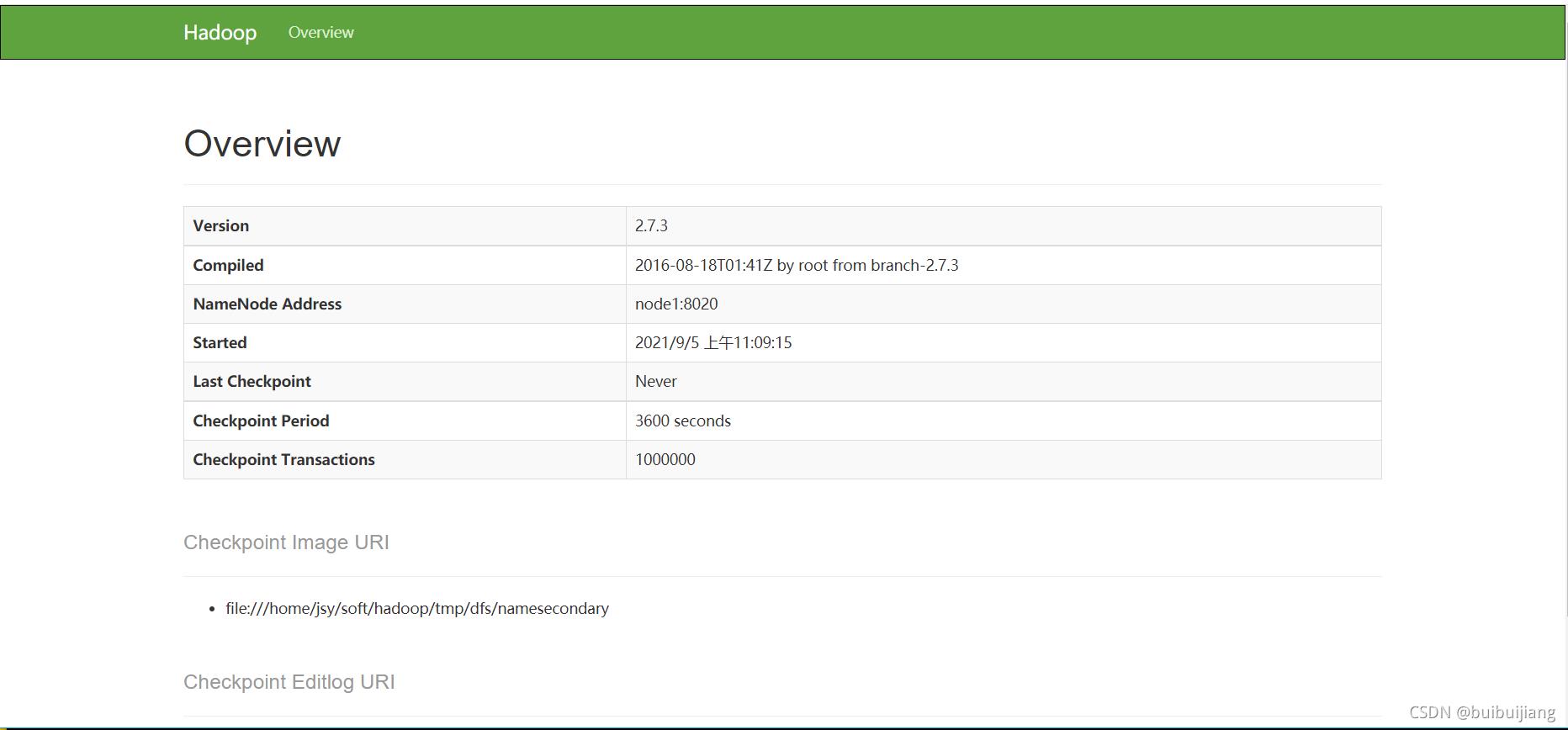
在Windows的测览器中,输人网址:http://192.168.17.136:50070,可以查看NameNode和 DetaNode信息,如图所示。其中,192.168.30.136表示Master的IP地址,请根据实际 情况修改。

单击Web页面的Datanodes查看DataNode信息,如图2-32所示,有两个DataNode 正 在运行。

在 Windows测览器中,输人网址tp://192.168.30.136:5090,可以查看Secondar NameNode信息。
(2) YARN Web界面。
在Windows的浏览器中,输人网址tp://9161.30.136:8088可以查看集群所有应用 程序的信息,如图2-34所示,可以看到Active Nodes为2,说明集群有两个NodeManage 节点正在运行。

至此,Hadoop完全分布模式(集群模式)搭建完成。
以上是关于Hadoop完全分布模式的搭建的主要内容,如果未能解决你的问题,请参考以下文章