云原生数据湖构建管理与分析@BIGDATA+AI·2020北京站
Posted 知了小巷
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生数据湖构建管理与分析@BIGDATA+AI·2020北京站相关的知识,希望对你有一定的参考价值。
点击关注上方“知了小巷”,
设为“置顶或星标”,第一时间送达干货。
大数据+AI 2020 北京站 活动全程回看链接:
https://developer.aliyun.com/live/245788
活动内容(不分顺序):
1. 云原生数据湖构建、管理与分析
2. 汇量科技在 Spark 上构建推荐算法 Pipeline 的实践
3. 人工智能算法与医学影像分析
4. 深度解析 Delta Lake Trasaction Log
5. 异构集群,统一计算在微博机器学习平台的应用
6. Fluid—云原生环境下数据密集型应用的高效支撑平台
7. Hive SQL到Spark SQL在滴滴的实践
8. Milvus 在图片检索场景的最佳实践
9. NLP 在医学领域的应用
《云原生数据湖构建、管理与分析》
简介:
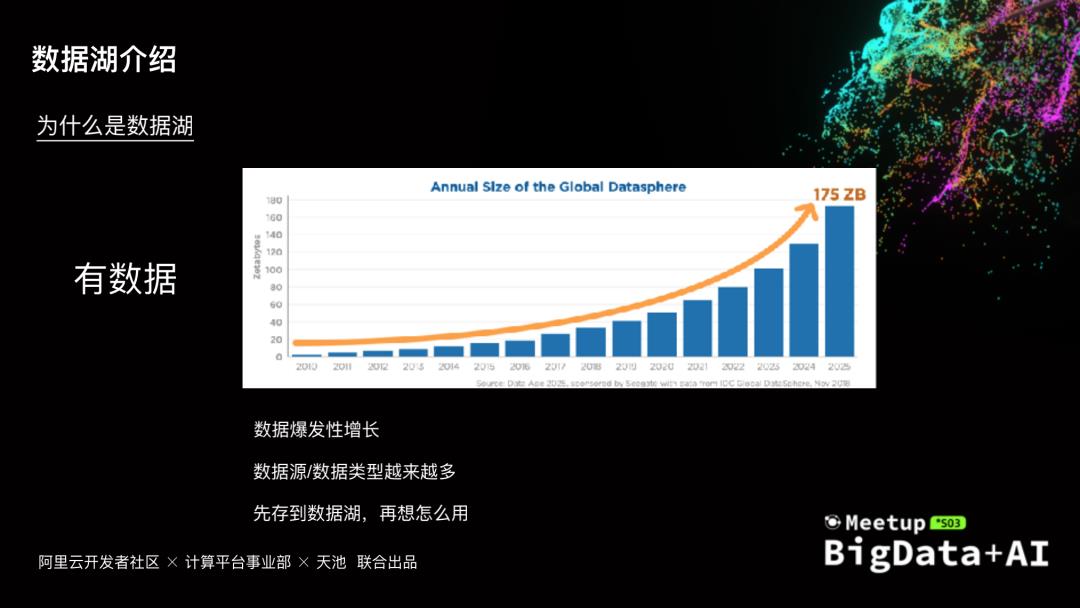
数字化是各行各业的发展趋势,数据成为其中最重要的生产资料。数据源越来越多,数据也呈爆发式增长,如何有效的管理数据,充分挖掘数据价值,同时考虑成本性能等因素,数据湖架构越来越多的被提起,本次分享会介绍数据湖架构遇到的一些问题和挑战,以及阿里云云原生数据湖构建、管理与分析的一些实践

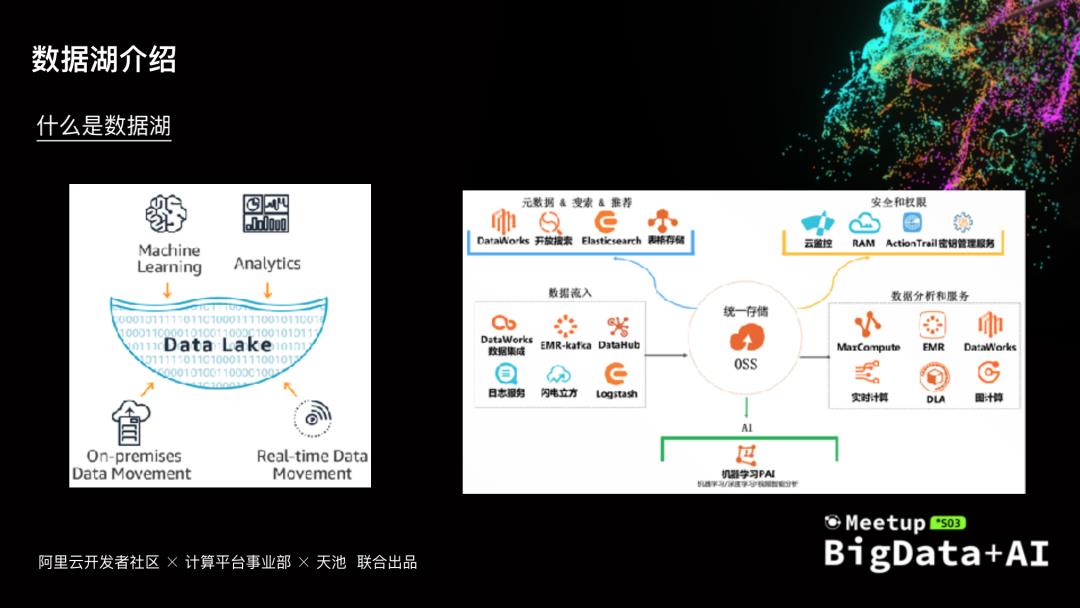
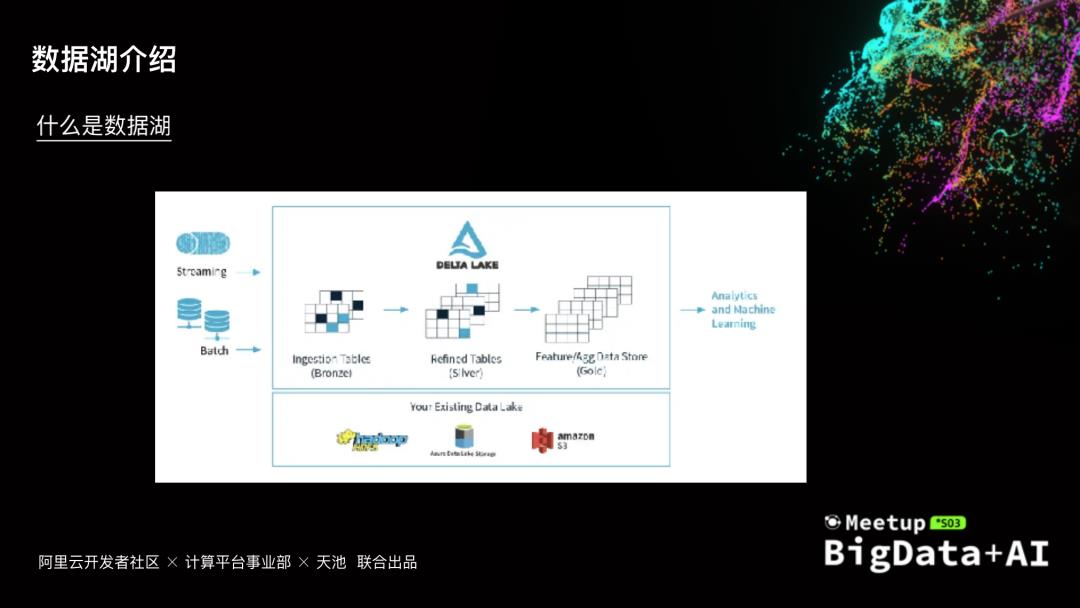
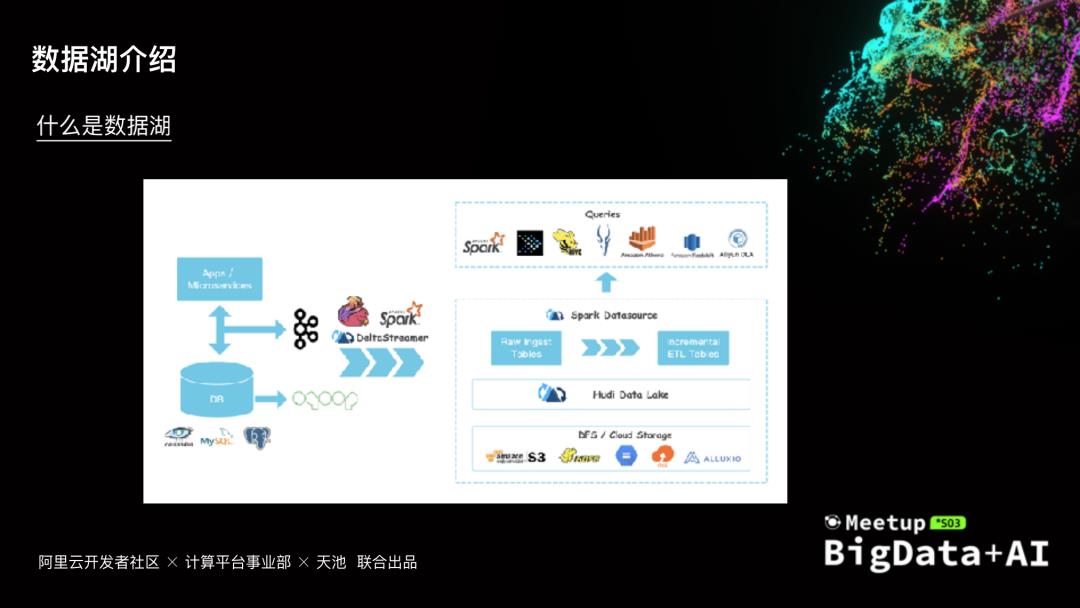

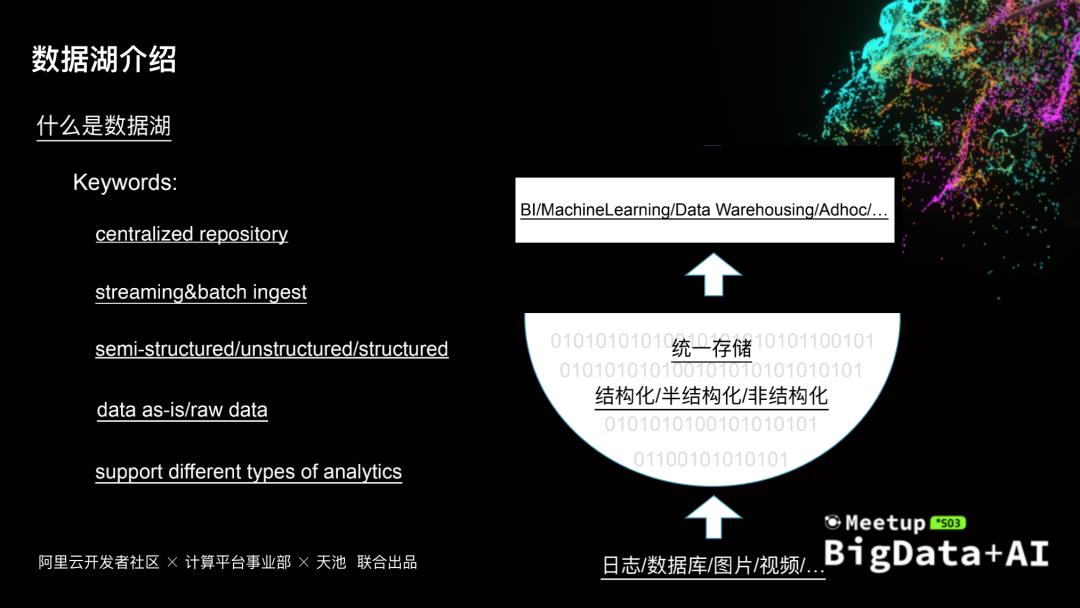




...
更多信息请加入大数据+ai钉钉交流群

猜你喜欢
点一下,代码无 Bug
以上是关于云原生数据湖构建管理与分析@BIGDATA+AI·2020北京站的主要内容,如果未能解决你的问题,请参考以下文章