常用缓存淘汰策略算法解析
Posted 书香人家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常用缓存淘汰策略算法解析相关的知识,希望对你有一定的参考价值。
前言
对于很多缓存中间件来说,内存是其操作的主战场,以redis来说,redis是很多互联网公司必备的选择,redis具有高效、简洁且易用的诸多特性被大家广泛使用,但我们知道,redis操作大多数属于内存性级操作,如果用于存放大批量数据,随着时间的增长,性能一定会下降,因此为了解决此类问题,redis自身提供了诸多的用于淘汰缓存的策略配置;
缓存淘汰的策略,可以有效的缓解redis服务在运行过程中由于内存吃紧带来的空间不知,性能下降的问题,不仅如此,在很多类似的中间件,比如spark,clickhouse等以内存为主要操作的中间件,都有类似的缓存淘汰机制;
不管它们的淘汰策略多么的复杂,但是基本的原理都是类似的,说到底,缓存淘汰策略的配置背后都是基于一套算法的,下面,小编列举几种比较常用的缓存淘汰策略算法以供参考和了解;
1、FIFO
中文解释:先来先淘汰;映射一种数据结构的话,即先进先出,这就很容易让我们想到Java中的某些数据结构有相似的特性;
FIFO的工作示意图可以参考上面的图示,简单总结其特点如下:
一个固定长度的有序队列
进出队列的元素按顺序排列,可以通过下标(索引)定位
当队列长度达到上限时,移除队列中最早入队的一个或多个
于是我们很容易想到,Java中的linkedList可以拿来使用,相信下面这段代码稍有Java基础的同学可以很快的撸出来
/**
* 先进先出 FIFO
*/
public class FiFo {
//作为存放元素的队列
static LinkedList<Integer> fifo = new LinkedList<Integer>();
//定义队列的最大长度
static int QUEUE_SIZE = 3;
public static void main(String[] args) {
FiFo fifo = new FiFo();
System.out.println("begin add 1‐3:");
fifo.add(1); fifo.add(2); fifo.add(3);
System.out.println("begin add 4:");
fifo.add(4);
System.out.println("begin read 2:"); fifo.read(2);
System.out.println("begin read 100:"); fifo.read(100);
System.out.println("add 5:"); fifo.add(5);
}
public void add(int i) {
fifo.addFirst(i);
if (fifo.size() > QUEUE_SIZE) {
fifo.removeLast();
}
showData();
}
//打印队列数据
public void showData() {
System.out.println(this.fifo);
}
/**
* 读取队列数据
* @param data
*/
public void read(int data) {
Iterator<Integer> iterator = fifo.iterator();
while (iterator.hasNext()) {
int j = iterator.next();
if (data == j) {
System.out.println("find the data");
showData();
return;
}
}
System.out.println("not found");
showData();
}
}
程序中主要提供了3个方法,入队,移除队列最早加入的元素,以及读取队列期望元素的几个方法,运行下这段代码,通过打印输出的内容加深一下体会

总结:
FIFO 的实现比较简单
FIFO 实现的淘汰策略比较粗暴,只单纯从时间维度上考虑,而不管元素的使用情况如何,即哪怕可能是经常用到的数据,最早加入的那些数据也可能被干掉
实际生产中使用的较少,不够人性化
2、LRU
中文解释 : 最久未用淘汰
LRU全称是Least Recently Used,即淘汰最后一次使用时间最久远的数值。FIFO非常的粗暴,不管有没有用到, 直接踢掉时间久的元素。而LRU认为,最近频繁使用过的数据,将来也很可能会被频繁用到,因此淘汰那些懒惰的数据
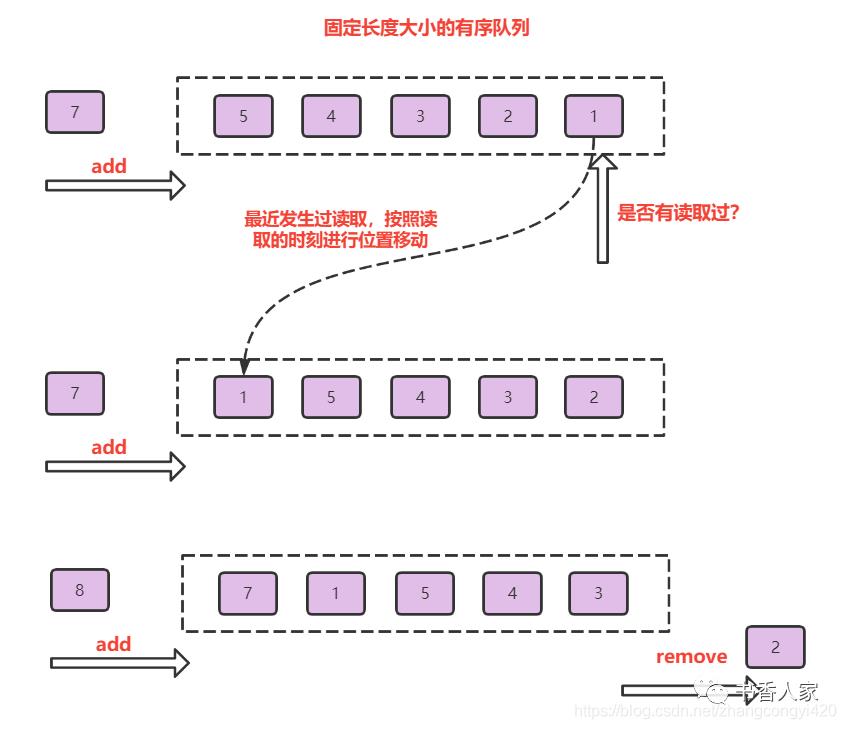
LRU算法的工作原理可以依照上图理解,其过程总结如下:
固定长度的队列,在未达到最大容量之前,过来的数据有序存放在队列中
如果没有任何数据发生过读取,再进来的数据,依照FIFO的策略淘汰(这时大家是平等的)
如果中间任何数据发生过读取,被读取的数据将会发生位置的移动,移动至队尾(其他的元素也如此)
再进入队列的元素,移除(淘汰)队首的元素
LRU算法考虑到了数据的读取(使用)操作,这个和上面的解释也是符合的,即被读取过的元素认为有较高的优先级,使用Java中的LinkedHashMap,数组,链表均可实现LRU,下面直接上代码,可以结合注释参阅,
/**
* 最久未用淘汰【先进先出】
*/
public class LRU {
//作为存放元素的队列
static LinkedList<Integer> lru = new LinkedList<Integer>();
//定义队列的最大长度
static int QUEUE_SIZ = 3;
//添加元素
public void add(int i) {
lru.addFirst(i);
if (lru.size() > QUEUE_SIZ) {
lru.removeLast();
}
showData();
}
//读取数据
public void read(int data) {
Iterator<Integer> iterator = lru.iterator();
int index = 0;
while (iterator.hasNext()) {
int temData = iterator.next();
if (data == temData) {
System.out.println("find the data");
//找到了这个元素之后,移除这个位置的这个元素,并将它移动到队尾
lru.remove(index);
lru.addFirst(temData);
showData();
return;
}
index++;
}
System.out.println("not found!");
showData();
}
//打印数据
public void showData() {
System.out.println(this.lru);
}
public static void main(String[] args) {
LRU lru = new LRU();
System.out.println("begin add 1‐3:");
lru.add(1);
lru.add(2);
lru.add(3);
System.out.println("add 4:");
lru.add(4);
System.out.println("read 2:");
lru.read(2);
System.out.println("read 5:");
lru.read(5);
System.out.println("add 5:");
lru.add(5);
}
}
其中最关键的部分在数据读取的这个方法里面,可参考注释重点理解,下面来运行下这段代码,通过控制台输出加深下理解,

总结:
相比FIFO,增加了按照使用的维度进行判断,更贴合理性的选择
判断的维度不够充分,仅仅是从使用的时间上考虑,未考虑到使用的频次等更多因素
3、LFU
中文解释 : 最近最少使用
Least Frequently Used,最近最少使用。它要淘汰的是最近一段时间内,使用次数最少的元素。可认为比LRU 多一重判断。
LFU需要时间和次数两个维度进行参考。要注意的是,两个维度就可能涉及到同一时间段内, 访问次数相同的情况,那么就必须内置一个计数器和一个队列,计数器统计访问元素的次数,而队列用于放置相同计数时的访问时间。
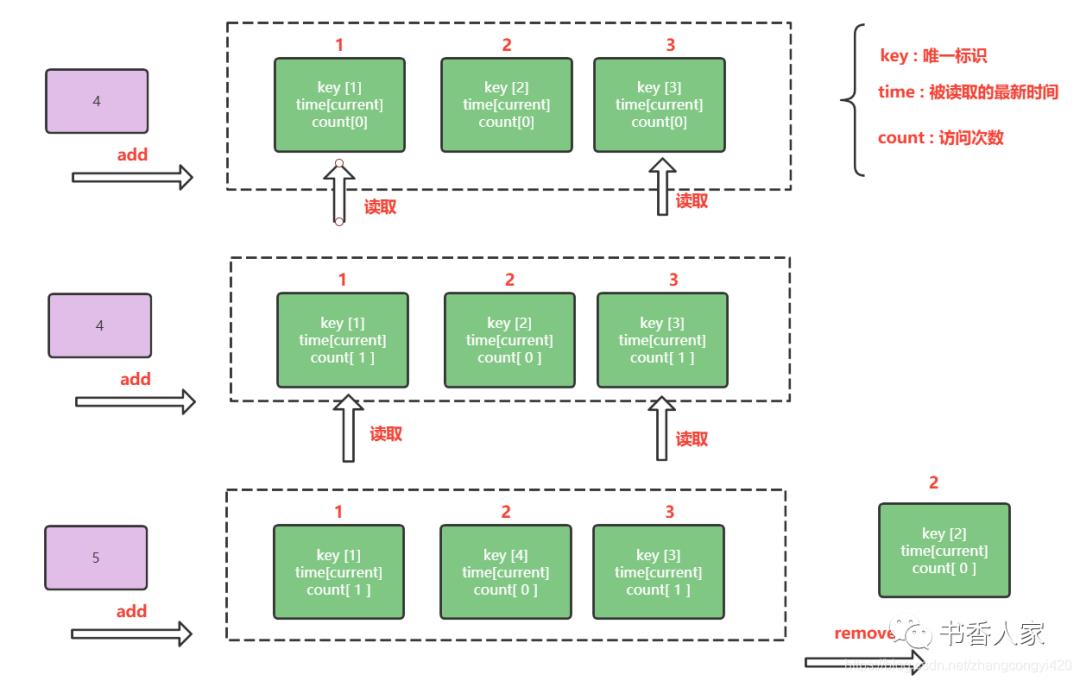
LFU的工作原理可以参考上图进行理解,总体实现思路如下:
定义一个对象,其属性包括,key(对象唯一标识),addTime(对象构造时间),count(标识对象被读取的次数);
对象中需要重载一个比较大小的方法,即实现Comparable接口,比较的方法中,先根据对象的读取次数进行比较,如果读取的次数相同,再根据最近的读取时间比较
定义一个计数器,即每次添加或读取的时候用于标识对象的读取次数,方便快速查找
根据上面的思路,我们直接来看下面的代码
1、定义一个实体对象,并实现Comparable接口
/**
* 对象
*/
public class DataDto implements Comparable<DataDto> {
private String key;
private int count;
private long lastTime;
public DataDto(String key, int count, long lastTime) {
this.key = key;
this.count = count;
this.lastTime = lastTime;
}
@Override
public int compareTo(DataDto o) {
int compare = Integer.compare(this.count, o.count);
return compare == 0 ? Long.compare(this.lastTime, o.lastTime) : compare;
}
@Override
public String toString() {
return String.format("[key=%s,count=%s,lastTime=%s]", key, count, lastTime);
}
public String getKey() {
return key;
}
public void setKey(String key) {
this.key = key;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public long getLastTime() {
return lastTime;
}
public void setLastTime(long lastTime) {
this.lastTime = lastTime;
}
}
2、主要操作LFU的方法
/**
* 最近最少使用
* 时间维度+ 访问次数共同控制
*/
public class SelfLFU {
private final int size = 3;
//存放的数据容量,即代表容器里面能存放的元素最大的个数
private Map<String, Integer> counter = new HashMap<>();
//通过key能够快速定位到对象
private Map<String, DataDto> cache = new HashMap<>();
public void putData(String key, Integer value) {
Integer v = counter.get(key);
if (v == null) {
//如果这个元素不存在
if (counter.size() == size) {
//如果队列元素已经到达最大限度,需要做元素的移除操作
removeElement();
}
//如果未达到队列最大上限,重新构建一个新的对象
cache.put(key, new DataDto(key, 1, System.currentTimeMillis()));
} else {
//如果计数器缓存中已经存在了,只需要给这个元素的访问次数累加即可
addCount(key);
}
counter.put(key, value);
}
//根据key获取计数器中当前元素的次数
public Integer get(String key) {
Integer value = counter.get(key);
if (value != null) {
addCount(key);
return value;
}
return null;
}
//移除元素
private void removeElement() {
DataDto dto = Collections.min(cache.values());
counter.remove(dto.getKey());
cache.remove(dto.getKey());
}
//计数器增加key的次数
private void addCount(String key) {
DataDto Dto = cache.get(key);
Dto.setCount(Dto.getCount() + 1);
Dto.setLastTime(System.currentTimeMillis());
}
//打印输出结果
private void print() {
System.out.println("counter=" + counter);
System.out.println("count=" + cache);
}
public static void main(String[] args) {
SelfLFU lfu = new SelfLFU();
//前3个容量没满,1,2,3均加入
System.out.println("begin add 1‐3:");
lfu.putData("1", 1);
lfu.putData("2", 2);
lfu.putData("3", 3);
lfu.print();
//1,2有访问,3没有,加入4,淘汰3
System.out.println("begin read 1,2");
lfu.get("1");
lfu.get("2");
lfu.print();
System.out.println("begin add 4:");
lfu.putData("4", 4);
lfu.print();
//2=3次,1,4=2次,但是4加入较晚,再加入5时淘汰1
System.out.println("begin read 2,4");
lfu.get("2");
lfu.get("4");
lfu.print();
System.out.println("begin add 5:");
lfu.putData("5", 5);
lfu.print();
}
}
请重点关注putData方法,下面我们通过断点调试其中的关键代码来看看数据如何
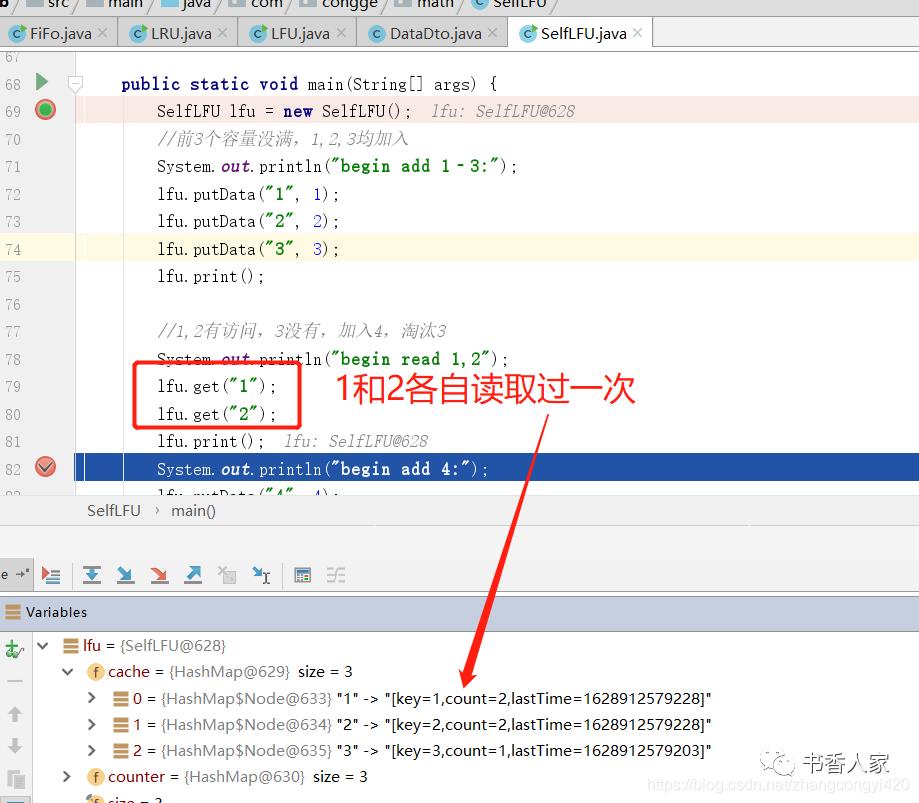
图中展示了3个对象在添加到对象列表之后,通过一次读取之后在内存中的情况,可以发现,1和2读取过一次了,因此count的值变为2,而3这个key代表的对象未发生过读取,count还为1
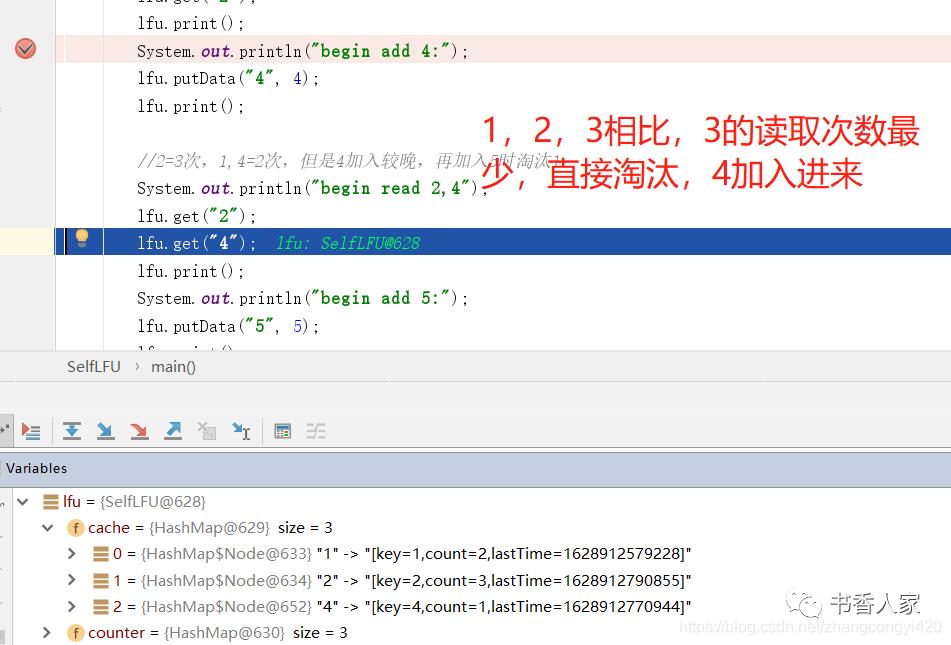
通过上面的代码断点走读,可以发现LFU的淘汰策略是按照预期的估计执行的,在实际运用中,大家可以结合redis官方的相关淘汰策略一起对比进行学习理解
以上是关于常用缓存淘汰策略算法解析的主要内容,如果未能解决你的问题,请参考以下文章