06 | 链表(上):如何实现LRU缓存淘汰算法?
Posted lakeslove
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了06 | 链表(上):如何实现LRU缓存淘汰算法?相关的知识,希望对你有一定的参考价值。
我们先来讨论一个经典的链表应用场景,那就是 LRU 缓存淘汰算法。
缓存的大小有限,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?这就需要缓存淘汰策略来决定。
常见的策略有三种:
先进先出策略 FIFO(First In,First Out)、最少使用策略 LFU(Least Frequently Used)、最近最少使用策略 LRU(Least Recently Used)。
三种最常见的链表结构,它们分别是:单链表、双向链表和循环链表。
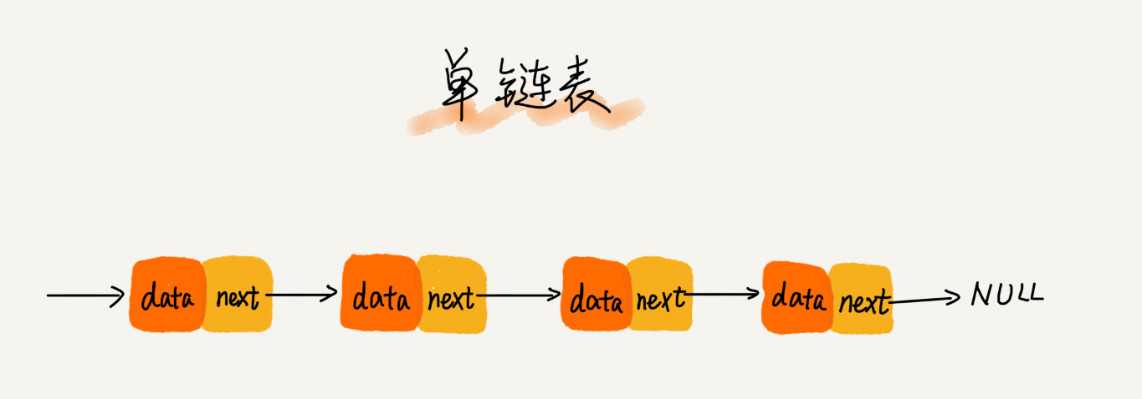
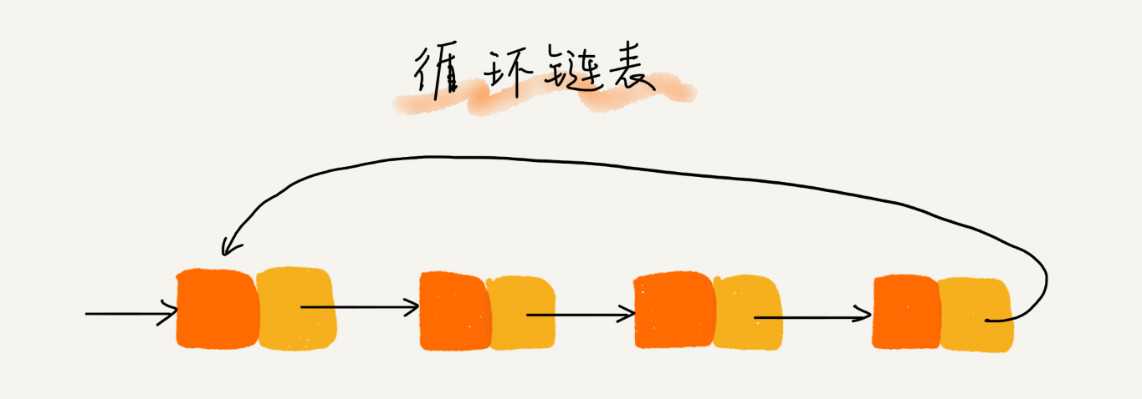
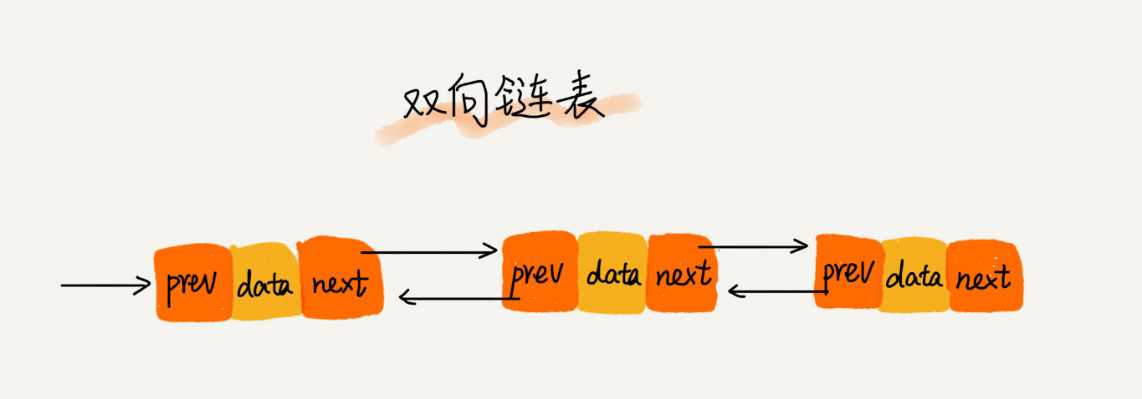
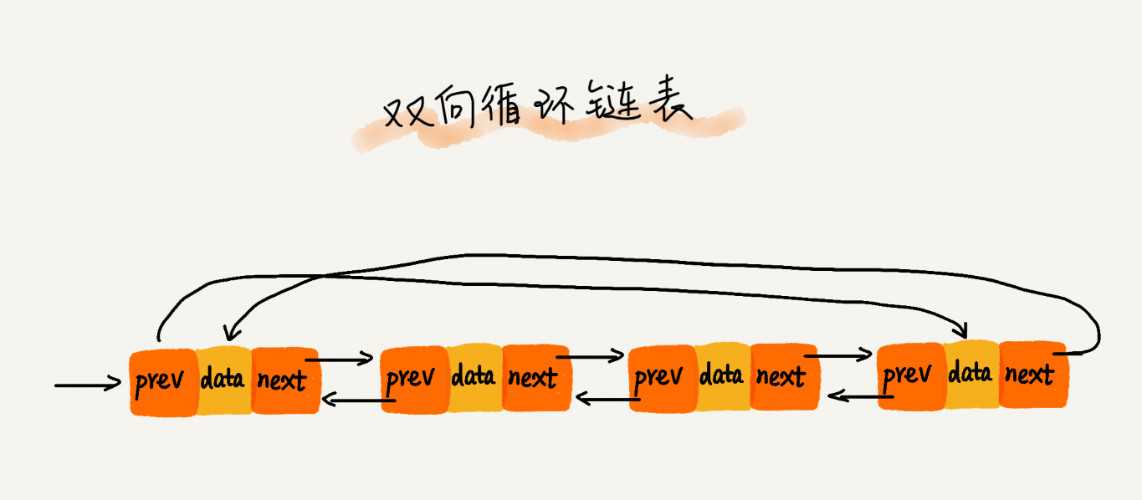
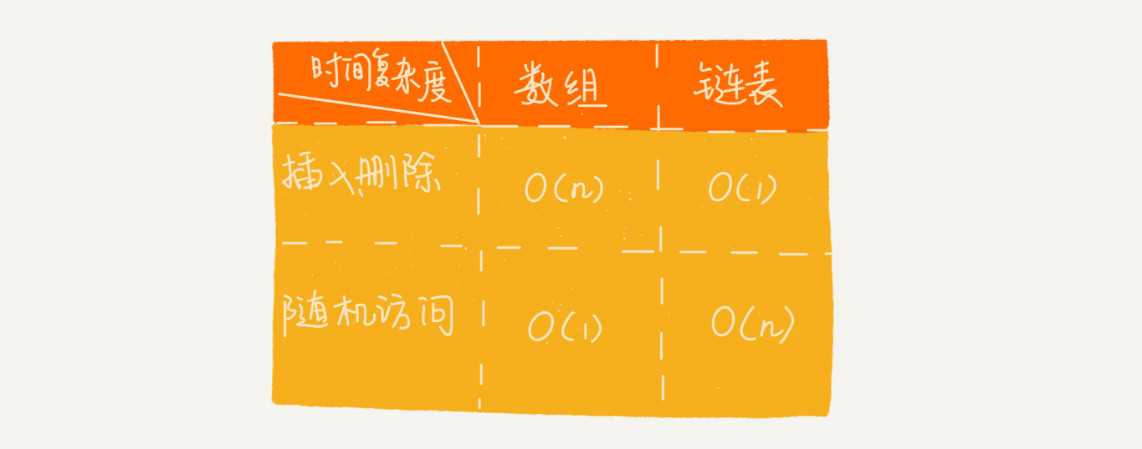
数组简单易用,在实现上使用的是连续的内存空间,可以借助 CPU 的缓存机制,预读数组中的数据,所以访问效率更高。而链表在内存中并不是连续存储,所以对 CPU 缓存不友好,没办法有效预读.
数组的缺点是大小固定,一经声明就要占用整块连续内存空间。如果声明的数组过大,系统可能没有足够的连续内存空间分配给它,导致“内存不足(out of memory)”。如果声明的数组过小,则可能出现不够用的情况。这时只能再申请一个更大的内存空间,把原数组拷贝进去,非常费时。链表本身没有大小的限制,天然地支持动态扩容,我觉得这也是它与数组最大的区别。
以上是关于06 | 链表(上):如何实现LRU缓存淘汰算法?的主要内容,如果未能解决你的问题,请参考以下文章