哈工大SCIR出品《自然语言处理》新书,无套路送5本!
Posted 夕小瑶的卖萌屋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了哈工大SCIR出品《自然语言处理》新书,无套路送5本!相关的知识,希望对你有一定的参考价值。
自然语言处理面临着8个难点,即语言的抽象性、组合性、歧义性、进化性、非规范性、主观性、知识性及难移植性。
正是由于这些难点的存在,导致自然语言处理任务纷繁复杂。
不过,虽然自然语言处理任务多种多样,却可以被归为三大类常见的自然语言处理任务,即:语言模型、基础任务以及应用任务。
本文就分别来介绍一下!
 语言模型
语言模型
语言模型(Language Model,LM)(也称统计语言模型)是描述自然语言概率分布的模型,是一个非常基础和重要的自然语言处理任务。
利用语言模型,可以计算一个词序列或一句话的概率,也可以在给定上文的条件下对接下来可能出现的词进行概率分布的估计。同时,语言模型是一项天然的预训练任务,在基于预训练模型的自然语言处理方法中起到非常重要的作用,因此这种预训练模型有时也 被称为预训练语言模型。
这里将主要介绍经典的N元语言模型(N-gram Language Model),现代的神经网络语言模型(Neural Network Language Model)在《自然语言处理:基于预训练模型的方法》的第 5 章进行详细的介绍。
01 N 元语言模型
语言模型的基本任务是在给定词序列 的条件下,对下一时刻 可能出现的词 的条件概率 进行估计。
一般地,把 称为w_t的历史。
例如,对于历史“我 喜欢”,希望得到下一个词为“读书” 的概率,即: 。
在给定一个语料库时,该条件概率可以理解为当语料中出现“我喜欢”时,有多少次下一个词为“读书”,然后通过最大似然估计进行计算:
(1)
式中, 表示相应词序列在语料库中出现的次数(也称为频次)。
通过以上的条件概率,可以进一步计算一个句子出现的概率,即相应单词序列的联合概率 ,式中 为序列的长度。
可以利用链式法则对该式进行分解,从而将其转化为条件概率的计算问题,即: 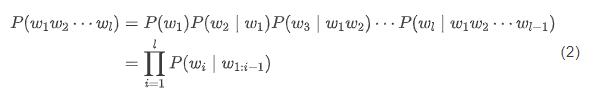
式中, 表示由位置 到 的子串 。
然而,随着句子长度的增加, 出现的次数会越来越少,甚至从未出现过,那么 则很可能为0,此时对于概率估计就没有意义了。
为了解决该问题,可以假设“下一个词出现的概率只依赖于它前面
个词”,即: 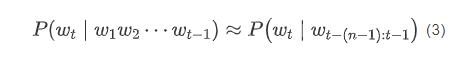
该假设被称为马尔可夫假设(Markov Assumption)。满足这种假设的模型,被称为N 元语法或N元文法(N-gram)模型。
特别地,当 时,下一个词的出现独立于其历史,相应的一元语法通常记作 unigram。当 时,下一个词只依赖于前 1 个词,对应的二元语法记作 bigram。
二元语法模型也被称为一阶马尔可夫链(Markov Chain)。
类似的,三元语法假设 也被称为二阶马尔可夫假设,相应的三元语法记作trigram。 的取值越大,考虑的历史越完整。
在 unigram 模型中,由于词与词之间相互独立,因此它是与语序无关的。
以 bigram 模型为例,式 (2) 可转换为:
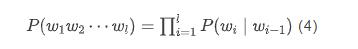
为了使 对于 有意义,可在句子的开头增加一个句首标记 <BOS>(Begin Of Sentence),并设 <BOS>。同时,也可以在句子的结尾增加一个句尾标记 <EOS>(End Of Sentence),设 <EOS>。
注:也有论文中使用 <s> 等标记表示句首,使用 </s>、<e> 等标记表示句尾。
02 平滑
虽然马尔可夫假设(下一个词出现的概率只依赖于它前面 个词)降低 了句子概率为 0 的可能性,但是当 比较大或者测试句子中含有未登录词(Out-Of-Vocabulary, OOV)时,仍然会出现“零概率”问题。
由于数据的稀疏性,训练数据很难覆盖测试数据中所有可能出现的 N-gram,但这并不意味着这些 N-gram 出现的概率为 0。
为了避免该问题,需要使用平滑(Smoothing)技术调整概率估计的结果。这里将介绍一种最基本,也最简单的平滑算法——折扣法。
折扣法(Discounting)平滑的基本思想是“损有余而补不足”,即从频繁出现 的 N-gram 中匀出一部分概率并分配给低频次(含零频次)的 N-gram,从而使得整体概率分布趋于均匀。
加 1 平滑(Add-one Discounting)是一种典型的折扣法,也被称为拉普拉斯平滑(Laplace Smoothing),它假设所有 N-gram 的频次比实际出现的频次多一次。
例如,对于 unigram 模型来说,平滑之后的概率可由以下公式计算: 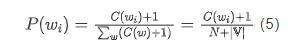
式中, 是词表大小。所有未登录词可以映射为一个区别于其他已知词汇的独立标记,如 <UNK>。
相应的,对于 bigram 模型,则有: 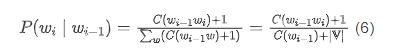
在实际应用中,尤其当训练数据较小时,加 1 平滑将对低频次或零频次事件给出过高的概率估计。一种自然的扩展是加 平滑。在加 平滑中,假设所有事件的频次比实际出现的频次多 次,其中 。
以 bigram 语言模型为例,使用加 平滑之后的条件概率为:
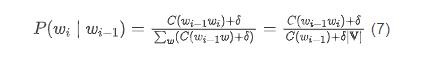
关于超参数 的取值,需要用到开发集数据。根据开发集上的困惑度对不同 取值下的语言模型进行评价,最终将最优的 用于测试集。由于引入了马尔可夫假设,导致 N 元语言模型无法对长度超过 的长距离词语依赖关系进行建模,如果将 扩大,又会带来更严重的数据稀疏问题,同时还会急剧增加模型的参数量(N-gram 数目),为存储和计算都带来极大的挑战。神经网络语言模型可以较好地解决 N 元语言模型的这些缺陷。
语言模型性能评价
如何衡量一个语言模型的好坏呢?
一种方法是将其应用于具体的外部任务 (如机器翻译),并根据该任务上指标的高低对语言模型进行评价。
这种方法也 被称为“外部任务评价”,是最接近实际应用需求的一种评价方法。
但是,这种方式的计算代价较高,实现的难度也较大。因此,目前最为常用的是基于困惑度 (Perplexity,PPL)的“内部评价”方式。
为了进行内部评价,首先将数据划分为不相交的两个集合,分别称为训练集 和测试集 ,其中 用于估计语言模型的参数。由该模型计算出的测试集的概率 则反映了模型在测试集上的泛化能力。
注:当模型较为复杂(例如使用了平滑技术)时,在测试集上反复评价并调整超参数的方式会使得模型在一定程度 上拟合了测试集。因此在标准实验设置中,需要划分一个额外的集合,以用于训练过程中的必要调试。该集合 通常称为开发集(Development set),也称验证集(Validation set)。
假设测试集 (每个句子的开始和结束分布增加 <BOS> 与 <EOS> 标记),那么测试集的概率为:
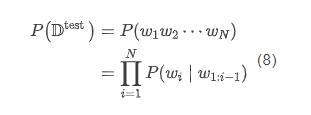
困惑度则为模型分配给测试集中每一个词的概率的几何平均值的倒数:
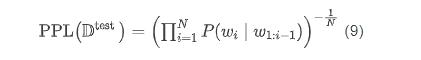
例如,对于 bigram 模型而言:
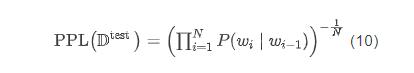
在实际计算过程中,考虑到多个概率的连乘可能带来浮点数下溢的问题,通常需要将式 (10) 转化为对数和的形式:
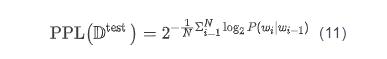
困惑度越小,意味着单词序列的概率越大,也意味着模型能够更好地解释测试集中的数据。
需要注意的是,困惑度越低的语言模型并不总是能在外部任务上取得更好的性能指标,但是两者之间通常呈现出一定的正相关性。
因此,困惑度可以作为一种快速评价语言模型性能的指标,而在将其应用于下游任务时,仍然需要根据其在具体任务上的表现进行评价。
基础任务
自然语言处理的一大特点是任务种类纷繁复杂,有多种划分的方式。
从处理顺序的角度,可以分为底层的基础任务以及上层的应用任务。
其中,基础任务往往是语言学家根据内省的方式定义的,输出的结果往往作为整个系统的一个环节或者下游任务的额外语言学特征,而并非面向普罗大众。
本文就来介绍几种常见的基础任务,包括词法分析(分词、词性标注)、句法分析和语义分析等。
01 中文分词
词(Word) 是最小的能独立使用的音义结合体,是能够独立运用并能够表达语义或语用内容的最基本单元。
在以英语为代表的印欧语系(Indo-European languages)中,词之间通常用分隔符(空格等)区分。但是在以汉语为代表的汉藏语系(Sino-Tibetan languages),以及以阿拉伯语为代表的闪-含语系(Semito-Hamitic languages)中,却不包含明显的词之间的分隔符。
因此,为了进行后续的自然语言处理,通常需要首先对不含分隔符的语言进行分词(Word Segmentation)操作。本节以中文分词为例,介绍词的切分问题和最简单的分词算法。
中文分词 就是将一串连续的字符构成的句子分割成词语序列,如“我喜欢读 书”,分词后的结果为“我 喜欢 读书”。最简单的分词算法叫作正向最大匹配 (Forward Maximum Matching,FMM)分词算法,即从前向后扫描句子中的字符串,尽量找到词典中较长的单词作为分词的结果。具体代码如下:
def fmm_word_seg(sentence, lexicon, max_len):
"""
sentence:待分词的句子
lexicon:词典(所有单词集合)
max_len:词典中最长单词长度
"""
begin = 0
end = min(begin + max_len, len(sentence))
words = []
while begin < end:
word = sentence[begin:end]
if word in lexicon or end - begin == 1:
words.append(word)
begin = end
end = min(begin + max_len, len(sentence))
else:
end -= 1
return words
通过下面的代码加载词典并调用正向最大匹配分词算法:
def load_dict():
f = open("lexicon.txt") # 词典文件,每行存储一个单词
lexicon = set()
max_len = 0
for line in f:
word = line.strip()
lexicon.add(word)
if len(word) > max_len:
max_len = len(word)
f.close()
return lexicon, max_len
lexicon, max_len = load_dict()
words = fmm_word_seg(input("请输入句子:"), lexicon, max_len)
for word in words:
print(word,)
正向最大匹配分词算法存在的明显缺点是倾向于切分出较长的词,这容易导致错误的切分结果,如“研究生命的起源”,由于“研究生”是词典中的词,所以使用正向最大匹配分词算法的分词结果为“研究生 命 的 起源”,显然分词结果不正确。
这种情况一般被称为切分歧义问题,即同一个句子可能存在多种分词结果, 一旦分词错误,则会影响对句子的语义理解。正向最大匹配分词算法除了存在切 分歧义,对中文词的定义也不明确,如“哈尔滨市”可以是一个词,也可以认为 “哈尔滨”是一个词,“市”是一个词。因此,目前存在多种中文分词的规范,根据不同规范又标注了不同的数据集。
另外,就是未登录词问题,也就是说有一些词并没有收录在词典中,如新词、 命名实体、领域相关词和拼写错误词等。由于语言的动态性,新词语的出现可谓 是层出不穷,所以无法将全部的词都及时地收录到词典中,因此,一个好的分词系统必须能够较好地处理未登录词问题。
相比于切分歧义问题,在真实应用环境 中,由未登录词问题引起的分词错误比例更高。
因此,分词任务本身也是一项富有挑战的自然语言处理基础任务,可以使用多种机器学习方法加以解决,《自然语言处理:基于预训练模型的方法(全彩)》一书中有详细的介绍。
02 子词切分
一般认为,以英语为代表的印欧语系的语言,词语之间通常已有分隔符(空 格等)进行切分,无须再进行额外的分词处理。
然而,由于这些语言往往具有复杂的词形变化,如果仅以天然的分隔符进行切分,不但会造成一定的数据稀疏问题, 还会导致由于词表过大而降低处理速度。如“computer”“computers”“computing” 等,虽然它们语义相近,但是被认为是截然不同的单词。
传统的处理方法是根据语言学规则,引入词形还原(Lemmatization)或者词干提取(Stemming)等任务, 提取出单词的词根,从而在一定程度上克服数据稀疏问题。
其中,词形还原指的是将变形的词语转换为原形,如将“computing”还原为“compute”;而词干提取则 是将前缀、后缀等去掉,保留词干(Stem),如“computing”的词干为“comput”, 可见,词干提取的结果可能不是一个完整的单词。
词形还原或词干提取虽然在一定程度上解决了数据稀疏问题,但是需要人工 撰写大量的规则,这种基于规则的方法既不容易扩展到新的领域,也不容易扩展 到新的语言上。
因此,基于统计的无监督子词(Subword)切分任务应运而生,并 在现代的预训练模型中使用。
所谓子词切分,就是将一个单词切分为若干连续的片段。目前有多种常用的子词切分算法,它们的方法大同小异,基本的原理都是使用尽量长且频次高的子词对单词进行切分。
此处重点介绍常用的字节对编码(Byte Pair Encoding,BPE) 算法。首先,BPE 通过算法 2.1 构造子词词表。

下面,通过一个例子说明如何构造子词词表。
首先,假设语料库中存在下列 Python 词典中的 3 个单词以及每个单词对应的频次。其中,每个单词结尾增加了 一个 '</w>' 字符,并将每个单词切分成独立的字符构成子词。
{'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}
初始化的子词词表为 3 个单词包含的全部字符:
{'l', 'o', 'w', 'e', 'r', '</w>', 'n', 's', 't', 'i', 'd'}
然后,统计单词内相邻的两个子词的频次,并选取频次最高的子词对 'e' 和 's',合并成新的子词 'es'(共出现 9 次),然后加入子词词表中,并将语料库中 不再存在的子词 's' 从子词词表中删除。此时,语料库以及子词词表变为:
{'l o w e r </w>': 2, 'n e w es t </w>': 6, 'w i d es t </w>': 3}
{'l', 'o', 'w', 'e', 'r', '</w>', 'n', 't', 'i', 'd', 'es'}
然后,合并下一个子词对 'es' 和 't',新的语料库和子词词表为:
{'l o w e r </w>': 2, 'n e w est </w>': 6, 'w i d est </w>': 3}
{'l', 'o', 'w', 'e', 'r', '</w>', 'n', 'i', 'd', 'est'}
重复以上过程,直到子词词表大小达到一个期望的词表大小为止。
构造好子词词表后,如何将一个单词切分成子词序列呢?可以采用贪心的方 法,即首先将子词词表按照子词的长度由大到小进行排序。然后,从前向后遍历子 词词表,依次判断一个子词是否为单词的子串,如果是的话,则将该单词切分,然 后继续向后遍历子词词表。如果子词词表全部遍历结束,单词中仍然有子串没有被切分,那么这些子串一定为低频串,则使用统一的标记,如 '<UNK>' 进行替换。
例如,对一个含有三个单词的句子['the</w>', 'highest</w>', 'mountain </w>'] 进行切分,假设排好序的词表为 ['errrr</w>', 'tain</w>', 'moun', 'est</w>', 'high', 'the</w>', 'a</w>'],则子词切分的结果为 ['the</w >', 'high', 'est</w>', 'moun', 'tain</w>']。此过程也叫作对句子(单词 序列)进行编码。
那么,如何对一个编码后的句子进行解码,也就是还原成原始的句子呢?此 时,单词结尾字符 '</w>' 便发挥作用了。只要将全部子词进行拼接,然后将结尾 字符替换为空格,就恰好为原始的句子了。
通过以上过程可以发现,BPE 算法中的编码步骤需要遍历整个词表,是一个非常耗时的过程。可以通过缓存技术加快编码的速度,即将常见单词对应的编码 结果事先存储下来,然后编码时通过查表的方式快速获得编码的结果。对于查不到的单词再实际执行编码算法。由于高频词能够覆盖语言中的大部分单词,因此 该方法实际执行编码算法的次数并不多,因此可以极大地提高编码过程的速度。除了 BPE,还有很多其他类似的子词切分方法,如 WordPiece、Unigram Language Model(ULM)算法等。其中,WordPiece 与 BPE 算法类似,也是每次从子 词词表中选出两个子词进行合并。与 BPE 的最大区别在于,选择两个子词进行合 并的策略不同:BPE 选择频次最高的相邻子词合并,而 WordPiece 选择能够提升 语言模型概率最大的相邻子词进行合并。经过公式推导,提升语言模型概率最大 的相邻子词具有最大的互信息值,也就是两子词在语言模型上具有较强的关联性, 它们经常在语料中以相邻方式同时出现。
与 WordPiece 一样,ULM 同样使用语言模型挑选子词。不同之处在于,BPE 和 WordPiece 算法的词表大小都是从小到大变化,属于增量法。而 ULM 则是减量 法,即先初始化一个大词表,根据评估准则不断丢弃词表中的子词,直到满足限定条件。ULM 算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词 分段。
为了更方便地使用上述子词切分算法,Google 推出了 SentencePiece 开源工具 包,其中集成了 BPE、ULM 等子词切分算法,并支持 Python、C++ 编程语言的调 用,具有快速、轻量的优点。此外,通过将句子看作 Unicode 编码序列,从而使 其能够处理多种语言。
03词性标注
词性 是词语在句子中扮演的语法角色,也被称为词类(Part-Of-Speech,POS)。 例如,表示抽象或具体事物名字(如“计算机”)的词被归为名词,而表示动作 (如“打”)、状态 (如“存在”) 的词被归为动词。词性可为句法分析、语义理解等 提供帮助。
词性标注(POS Tagging)任务是指给定一个句子,输出句子中每个词相应的词性。例如,当输入句子为:
他 喜欢 下 象棋 。
则词性标注的输出为:
他/PN 喜欢/VV 下/VV 象棋/NN 。/PU
其中,斜杠后面的 PN、VV、NN 和 PU 分别代表代词、动词、名词和标点符号①。
① 不同标注规范定义的词性及表示方式不同,本书主要以中文宾州树库(Chinese Penn Treebank)词性标注规范为例。
词性标注的主要难点在于歧义性,即一个词在不同的上下文中可能有不同的 词性。例如,上例中的“下”,既可以表示动词,也可以表示方位词。因此,需要 结合上下文确定词在句子中的具体词性。
04 句法分析
句法分析(Syntactic Parsing)的主要目标是给定一个句子,分析句子的句法 成分信息,例如主谓宾定状补等成分。最终的目标是将词序列表示的句子转换成 树状结构,从而有助于更准确地理解句子的含义,并辅助下游自然语言处理任务。例如,对于以下两个句子:
您转的这篇文章很无知。 您转这篇文章很无知。
虽然它们只相差一个“的”字,但是表达的语义是截然不同的,这主要是因 为两句话的主语不同。其中,第一句话的主语是“文章”,而第二句话的主语是 “转”的动作。通过对两句话进行句法分析,就可以准确地获知各自的主语,从而推导出不同的语义。
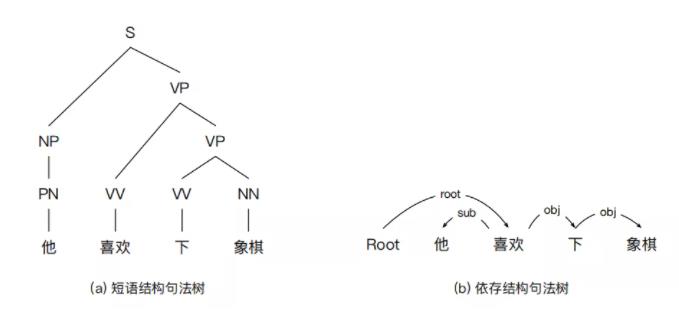
典型的句法结构表示方法包含两种——短语结构句法表示和依存结构句法表 示。它们的不同点在于依托的文法规则不一样。其中,短语结构句法表示依托上 下文无关文法,属于一种层次性的表示方法。而依存结构句法表示依托依存文法。
图 2-2 对比了两种句法结构表示方法。在短语结构句法表示中,S 代表起始符号, NP 和 VP 分别代表名词短语和动词短语。在依存结构句法表示中,sub 和 obj 分 别表示主语和宾语,root 表示虚拟根节点,其指向整个句子的核心谓词。
05 语义分析
自然语言处理的核心任务即是让计算机“理解”自然语言所蕴含的意义,即 语义(Semantic)。本章前面介绍的文本向量表示,可以被认为隐性地蕴含了很多语义信息。而一般意义上的语义分析指的是通过离散的符号及结构显性地表示语义。根据待表示语言单元粒度以及语义表示方法的不同,语义分析又可以被分为多种形式。
从词语的粒度考虑,一个词语可能具有多种语义(词义),例如“打”,含义即可能是“攻击”(如“打人”),还可能是“玩”(如“打篮球”),甚至“编织”(如 “打毛衣”)等。
根据词语出现的不同上下文,确定其具体含义的自然语言处理任 务被称为词义消歧(Word Sense Disambiguation,WSD)。对于每个词可能具有的词义,往往是通过语义词典确定的,如 WordNet 等。除了以上一词多义情况,还有多词一义的情况,如“马铃薯”和“土豆”具有相同的词义。
由于语言的语义组合性和进化性,无法像词语一样使用词典定义句子、段落或篇章的语义,因此很难用统一的形式对句子等语言单元的语义进行表示。众多的语言学流派提出了各自不同的语义表示形式,如语义角色标注(Semantic Role Labeling,SRL)、语义依存分析(Semantic Dependency Parsing,SDP)等。
其中,语义角色标注也称谓词论元结构(Predicate-Argument Structure),即首先识别句子中可能的谓词(一般为动词),然后为每个谓词确定所携带的语义角 色(也称作论元),如表示动作发出者的施事(Agent),表示动作承受者的受事 (Patient)等。除了核心语义角色,还有一类辅助描述动作的语言成分,被称为附加语义角色,如动作发生的时间、地点和方式等。表 2-2 展示了一个语义角色标注的示例,其中有两个谓词——“喜欢”和“下”,并针对每个谓词产生相应的论元输出结果。

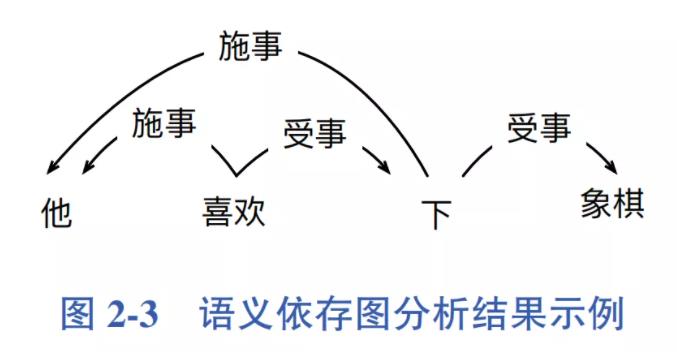
语义依存分析则利用通用图表示更丰富的语义信息。根据图中节点类型的不 同,又可分为两种表示——语义依存图(Semantic Dependency Graph)表示和概念语义图(Conceptual Graph)表示。其中,语义依存图中的节点是句子中实际存在的词语,在词与词之间创建语义关系边。而概念语义图首先将句子转化为虚拟 的概念节点,然后在概念节点之间创建语义关系边。图 2-3 展示了一个语义依存图分析结果示例。
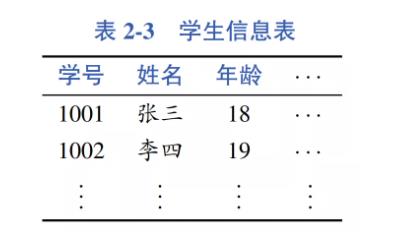
以上的语义表示方式属于通用语义表示方式,也就是针对各种语言现象,设计统一的语义表示。除此之外,还有另一类语义分析用于专门处理具体的任务,如将自然语言表示的数据库查询转换成结构化查询语言(SQL)。例如,对于如表2-3 所示的学生信息表,系统需要将用户的自然语言查询:年龄大于18岁的学生姓名, 转化为 SQL 语句:select name where age > 18;。
应用任务
本文介绍信息抽取、情感分析、问答系统、机器翻译和对话系统等自然语言处理应用任务。这些任务可以直接或间接地以产品的形式为终端用户提供服务,是自然语言处理研究应用落地的主要技术。
01 信息抽取
信息抽取(Information Extraction,IE)是从非结构化的文本中自动提取结构化信息的过程,这种结构化的信息方便计算机进行后续的处理。另外,抽取的结果还可以作为新的知识加入知识库中。信息抽取一般包含以下几个子任务。
命名实体识别(Named Entity Recognition,NER)是在文本中抽取每个提及的 命名实体并标注其类型,一般包括人名、地名和机构名等,也包括专有名称等,如 书名、电影名和药物名等。在文本中找到提及的命名实体后,往往还需要将这些命名实体链接到知识库或知识图谱中的具体实体,这一过程被称作实体链接(Entity Linking)。
如“华盛顿”既可以指美国首任总统,也可以指美国首都,需要根据上下文进行判断,这一过程类似于词义消歧任务。
关系抽取(Relation Extraction)用于识别和分类文本中提及的实体之间的语 义关系,如夫妻、子女、工作单位和地理空间上的位置关系等二元关系。
事件抽取(Event Extraction)的任务是从文本中识别人们感兴趣的事件以及 事件所涉及的时间、地点和人物等关键元素。其中,事件往往使用文本中提及的具体触发词(Trigger)定义。可见,事件抽取与语义角色标注任务较为类似,其 中触发词对应语义角色标注中的谓词,而事件元素则可认为是语义角色标注中的论元。
事件的发生时间往往比较关键,因此时间表达式(Temporal Expression)识别 也被认为是重要的信息抽取子任务,一般包括两种类型的时间:绝对时间(日期、 星期、月份和节假日等)和相对时间(如明天、两年前等)。使用时间表达归一化(Temporal Expression Normalization)将这些时间表达式映射到特定的日期或一天 中的时间。
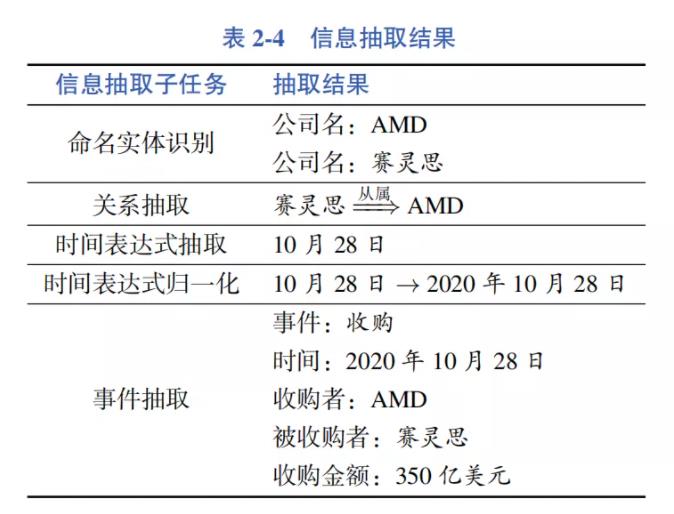
下面通过一个例子,综合展示以上的各项信息抽取子任务。如通过下面的新闻报道:
10月28日,AMD宣布斥资350亿美元收购FPGA芯片巨头赛灵思。这两家传了多年绯闻的芯片 公司终于走到了一起。
信息抽取结果如表 2-4 所示。
02 情感分析
情感(Sentiment)是人类重要的心理认知能力,使用计算机自动感知和处理 人类情感已经成为人工智能领域重要的研究内容之一。自然语言处理中的情感分 析主要研究人类通过文字表达的情感,因此也称为文本情感分析。
但是,情感又是一个相对比较笼统的概念,既包括个体对外界事物的态度、观点或倾向性,如正面、负面等;又可以指人自身的情绪(Emotion),如喜、怒、哀和惧等。随着互联 网的迅速发展,产生了各种各样的用户生成内容(User Generated Content,UGC), 其中很多内容包含着人们的喜怒哀惧等情感,对这些情感的准确分析有助于了解 人们对某款产品的喜好,随时掌握舆情的发展。因此,情感分析成为目前自然语 言处理技术的主要应用之一。
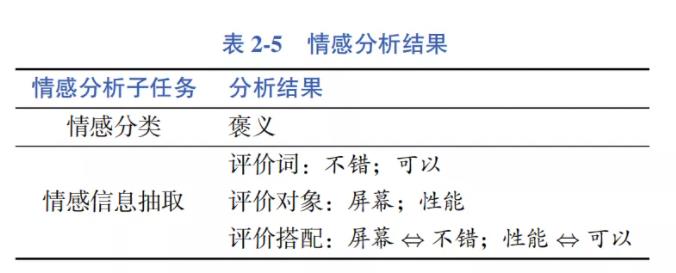
情感分析可以从任务角度分为两个主要的子任务,即情感分类(识别文本中 蕴含的情感类型或者情感强度,其中,文本既可以是句子,也可以是篇章)和情感信息抽取(抽取文本中的情感元素,如评价词语、评价对象和评价搭配等)。针对下面的用户评论:
这款手机的屏幕很不错,性能也还可以。
情感分析结果如表 2-5 所示。
由于情感分析具有众多的应用场景,如商品评论的分析、舆情分析等,因此, 情感分析受到工业界的广泛关注,已成为自然语言处理研究应用落地的重要体现。另外,情感分析还在社会学、经济学和管理学等领域显示出重要的研究意义和广 泛的应用前景,这些需求对情感分析不断提出更高的要求,推动了情感分析研究 的内涵和外延不断扩展和深入。
03 问答系统
问答系统(Question Answering,QA)是指系统接受用户以自然语言形式描 述的问题,并从异构数据中通过检索、匹配和推理等技术获得答案的自然语言处 理系统。根据数据来源的不同,问答系统可以分为 4 种主要的类型:
1)检索式问答系统,答案来源于固定的文本语料库或互联网,系统通过查找相关文档并抽取答案完成问答;
2)知识库问答系统,回答问题所需的知识以数据库等结构化形式 存储,问答系统首先将问题解析为结构化的查询语句,通过查询相关知识点,并 结合知识推理获取答案;
3)常问问题集问答系统,通过对历史积累的常问问题集 进行检索,回答用户提出的类似问题;
4)阅读理解式问答系统,通过抽取给定文 档中的文本片段或生成一段答案来回答用户提出的问题。在实际应用中,可以综 合利用以上多种类型的问答系统来更好地回答用户提出的问题。
04 机器翻译
机器翻译(Machine Translation,MT)是指利用计算机实现从一种自然语言 (源语言)到另外一种自然语言(目标语言)的自动翻译。
据统计,目前世界上存在约 7,000 种语言,其中,超过 300 种语言拥有 100 万个以上的使用者。
而随着全球化趋势的发展和互联网的广泛普及,不同语言使用者之间的信息交流变得越来越重要。如何突破不同国家和不同民族之间的语言障碍,已成为全人类面临的 共同难题。
机器翻译为克服这一难题提供了有效的技术手段,其目标是建立自动 翻译方法、模型和系统,打破语言壁垒,最终实现任意时间、任意地点和任意语言之间的自动翻译,完成人们无障碍自由交流的梦想。
自从自然语言处理领域诞生以来,机器翻译一直是其主要的研究任务和应用场景。
近年来,谷歌、百度等公司纷纷推出在线的机器翻译服务,科大讯飞等公司也推出了翻译机产品,能够直接将一种语言的语音翻译为另一种语言的语音,为具有不同语言的人们之间的互相交流提供了便利。
下面给出一个中英互译的例子,其中源语言(中文)和目标语言(英文)都经过了分词处理:
S: 北京 是 中国 的 首都 。
T: Beijing is the capital of China .
机器翻译方法一般以句子为基本输入单位,研究从源语言句子到目标语言句子的映射函数。
机器翻译自诞生以来,主要围绕理性主义和经验主义两种方法进行研究。
所谓“理性主义”,是指基于规则的方法;而“经验主义”是指数据驱动 的统计方法,在机器翻译领域表现为基于语料库(翻译实例库)的研究方法。
近年来兴起的基于深度学习的机器翻译方法利用深度神经网络学习源语言句子到目标语言句子的隐式翻译规则,即所有的翻译规则都被编码在神经网络的模型参数 中。该方法又被称为神经机器翻译(Neural Machine Translation, NMT)。
05 对话系统
对话系统(Dialogue System)是指以自然语言为载体,用户与计算机通过多轮交互的方式实现特定目标的智能系统。
其中,特定目标包括:完成特定任务、获取信息或推荐、获得情感抚慰和社交陪伴等。20 世纪 50 年代,图灵提出用于评测计算机系统智能化水平的“图灵测试”,就是以自然语言对话的形式进行的。
对话系统可以直接应用于语音助手、智能音箱和车载语音系统等众多场景。
对话系统主要分为任务型对话系统(Task-Oriented Dialogue)和开放域对话系统(Open-Domain Dialogue)。
前者是任务导向型的对话系统,主要用于垂直领域的自动业务助理等,具有明确的任务目标,如完成机票预订、天气查询等特定 的任务。
后者是以社交为目标的对话系统,通常以闲聊、情感陪护等为目标,因此也被称为聊天系统或聊天机器人(Chatbot),在领域和话题上具有很强的开放性。
下面是一段开放域对话系统人机对话的示例,其中 U 代表用户的话语(Utterance),S 代表对话系统的回复。该类对话系统的主要目标是提升对话的轮次以及用户的满意度。相比对话的准确性,开放域对话系统更关注对话的多样性以及对用户的吸引程度。
U: 今天天气真不错!
S: 是啊,非常适合室外运动。
U: 你喜欢什么运动?
S: 我喜欢踢足球,你呢?
任务型对话系统一般由顺序执行的三个模块构成,即自然语言理解、对话管理和自然语言生成。
其中,自然语言理解(Natural Language Understanding,NLU) 模块的主要功能是分析用户话语的语义,通常的表示形式为该话语的领域、意图以及相应的槽值等。如对于用户话语:
U: 帮我订一张明天去北京的机票
自然语言理解的结果如表 2-6 所示。

对话管理(Dialogue Management,DM)模块包括对话状态跟踪(Dialogue State Tracking,DST)和对话策略优化(Dialogue Policy Optimization,DPO)两个子模块。
对话状态一般表示为语义槽和值的列表。例如,通过对以上用户话语 自然语言理解的结果进行对话状态跟踪,得到当前的对话状态(通常为语义槽及 其对应的值构成的列表):[到达地 = 北京;出发时间 = 明天;出发地 =NULL;数量 =1]。
获得当前对话状态后,进行策略优化,即选择下一步采用什么样的策略, 也叫作动作。动作有很多种,如此时可以询问出发地,也可以询问舱位类型等。
在任务型对话系统里,自然语言生成(Natural Language Generation,NLG)模 块工作相对比较简单,通常通过写模板即可实现。比如要询问出发地,就直接问 “请问您从哪里出发?”,然后经过语音合成(Text-to-Speech,TTS)反馈给用户。
以上三个模块可以一直循环执行下去,随着每次用户的话语不同,对话状态也随之变化。然后,采用不同的回复策略,直到满足用户的订票需求为止。
▼
本文摘自《自然语言处理:基于预训练模型的方法(全彩)》一书,想要了解更多预训练模型的内容,推荐阅读此书!


▊《自然语言处理:基于预训练模型的方法(全彩)》
车万翔,郭江,崔一鸣 著
哈工大SCIR多位学者倾力奉献
揭秘自然语言处理中预训练语言模型的“魔力”之源
详解预训练语言模型的基础知识、模型设计、代码实现和前沿进展
本书在介绍自然语言处理、深度学习等基本概念的基础上,重点介绍新的基于预训练模型的自然语言处理技术。除了理论知识,本书还有针对性地结合具体案例提供相应的PyTorch 代码实现,不仅能让读者对理论有更深刻的理解,还能快速地实现自然语言处理模型,达到理论和实践的统一。

(京东满100减50,快快扫码抢购吧!)
▼点击阅读原文,查看本书详情~
福利时间
好书值得分享,这次我们有5本相送哦~ 各位小可爱可通过以下两种方式参与:
方式一:本文『评论点赞』前3名;
方式二:『最走心评论』幸运儿2名;
注意活动截止时间为【8月16日(周一) 18点整】哦~
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
以上是关于哈工大SCIR出品《自然语言处理》新书,无套路送5本!的主要内容,如果未能解决你的问题,请参考以下文章