自然语言处理中模型的“偷懒”
Posted python遇见NLP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理中模型的“偷懒”相关的知识,希望对你有一定的参考价值。
来源:哈工大SCIR
作者:哈工大SCIR 杜晏睿
介绍
本文主要介绍在自然语言处理中,模型常常会有“偷懒”的现象,即模型常常爱走“捷径”(Shortcut)[1]。用现实生活来举个例子,人们往往会依靠一些“捷径”做出最后的决策,想必大家在谈论选择题的答题技巧的时候或多或少听过一个口诀,“选择题的答案三长一短选最短,三短一长选最长”,我们往往会依赖这个口诀,实际就是在依赖一种“捷径”来选择答案。我们为什么相信这个口诀是正确的?其实,在实际的考题中,三长一短最短的答案或者三短一长最长的答案往往也就是正确的答案,所以我们通过不断地积累经验,学习到了这样一个经验性的知识,在面对一道选择题时,通过表面的特征就能够选择正确的答案。
其实,深度学习中的模型亦是如此,当训练数据中存在某种简单特征与样本真实标签有较强的相关性时,模型会学习到依靠简单的特征做出决策的能力,而并不是像我们预期的一样,模型通过理解句子的语义或复杂的逻辑做出决策。比如自然语言推理任务,给出前提和假设两个句子,判断两个句子是蕴含、中立还是矛盾关系,有研究人员发现在SNLI数据集[2]的训练集中某些类型的词与标签具有强烈的相关性[3]。如animal、instrument、outdoors等通用词与蕴涵关系具有强烈的相关性;如tall、sad、first等修饰语以及最高级词语与中立关系具有强烈的相关性;如nobody、never、nothing等否定词与矛盾关系具有强烈的相关性。因此,在模型学习的过程中,模型往往会倾向于依靠这些简单特征做出最后的决策。
1.“捷径”从哪里来
在深度学习中,模型的能力都是从训练数据中学习到的。那么,模型能够走“捷径”,一定程度上也是训练数据带来的问题,比如前面提到的自然语言推理任务SNLI数据集,训练数据中某些类型的词就与标签具有强烈的相关性,模型只关注这些特定类型的词就能获得非常小的损失,这样就会造成模型学习到某些“捷径”。在阅读理解任务上,研究人员也有类似的发现,阅读理解任务的形式是给定需要阅读的文本段落P和问题Q,模型需要在候选的答案中找出正确的那个。在阅读理解任务SQuAD数据集[4]中,存在两类可能会学习到的“捷径”[5]:问题词匹配(question word matching)和简单词匹配(simple matching)。在问题词匹配“捷径”中,训练数据中特殊疑问词与正确答案具有很强的相关性,比如,训练数据中当问句Q的特殊疑问词是'when'时,正确答案往往是段落P中的时间实体;训练数据中当问句Q的特殊疑问词是'where'时,正确答案往往是段落P的地点实体。这便造成模型学习到通过识别问题Q的特殊疑问词(wh-question)所限制的期望的实体类型,来从段落P中简单的获得一个答案短语的能力。在简单词匹配“捷径”中,如果训练数据中的问题Q和段落P有共享词存在,正确答案往往会出现在共享词附近的文本中,模型便会通过识别问题Q和段落P之间的共享词来寻找答案。
总的来说,当训练数据中存在某种简单特征与真实标签具有高度的相关性时,模型便倾向于学习到依靠这种简单特征做出决策的简单规则,而不会去深入学习句子的语义或者更复杂的逻辑关系。
2.“捷径”带来什么影响
“捷径”带来最直接的影响便是模型学习到“捷径”后,不会再去学习更复杂的规则或者逻辑做出预测,造成的现象是模型在域内(in-domain)数据上往往会表现出较好的性能,而在域外(out-of-domain)数据上,相比于在域内数据上其性能往往会下降很多(域内和域外数据的解释:比如有两个数据集,报纸数据集A和维基百科数据集B,用A的训练集训练一个模型,那么A的测试集便是域内数据,B的测试集便是域外数据)。在域内数据上,模型学习到的“捷径”往往会带来正收益,即模型学习到的“捷径”在域内数据上往往是可靠的,并且当模型依赖于学习到的“捷径”做预测而不关注句子的语义或者复杂逻辑时,往往也是能够预测对的。然而面对域外数据时,模型学习到的“捷径”不一定是可靠的,当模型仍然依赖于学习到的捷径做预测而不去关注句子的语义或者复杂逻辑时,因为在特定数据集上学习到的“捷径”往往是一个小规模样本上有偏的分布导致的。当模型在域外数据上做预测时,如果仍然依赖于学习到的“捷径”做预测而不去关注句子的语义或者复杂逻辑,往往会做出很多错误的判断。这便造成了模型在域内数据和域外数据上的性能表现出较大的差距。这就好比前文提到的做选择题时的口诀,也许这个口诀在国内的考试中是一个比较有效的“捷径”,但如果放在国外的考试中,这个口诀可能就不再适用了。
因此,我们期望模型是能够通过理解句子的语义或者复杂的逻辑关系给出最后的决策,而不是依靠“捷径”来给出预测,即便模型依靠“捷径”做对了,也不是我们期望的结果。
3.规避模型学习到“捷径”的方法
3.1 方法分类
规避模型学习到“捷径”的方法整体上分为两类:
1)从训练数据上做调整,尽可能地避免训练数据中存在某种简单与真实标签具有强烈相关性的有偏特征,进而从数据上规避模型学习到“捷径”的风险。比如就有研究人员设计了筛选数据的方法AFLITE[6]来避免模型依赖“捷径”做判断。
2)从模型学习的过程中做调整,让模型在学习过程中尽可能少地关注“捷径”。比如可以考虑元学习[7]方法以及下面介绍的LTGR框架[8]等等。
这里主要介绍一种从模型微调过程中做调整的方法,框架名叫:LTGR(Long-Tailed distribution Guided Regularizer),是2021年Mengnan Du等人[8]提出的一种消除模型学习到“捷径”的方法。整体的框架如下图所示:
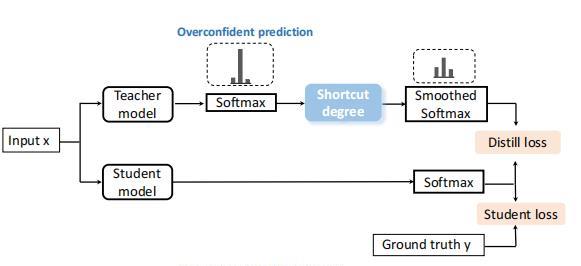
该方法的核心思想,通俗点讲可以主要分为两步:1)微调一个模型teacher model,用来为训练数据中每一条样本进行打分(shortcut degree)。这里如果shortcut degree越大,代表这条样本越可能让模型学习到shortcut。2)初始化一个student model,与teacher model相同的参数以及大小,进行蒸馏操作。在蒸馏过程中,依据每条样本的shortcut degree对loss进行操作,目的是让模型尽可能小的关注shortcut degree高的样本。
作者将LTGR方法与其他三种消除“捷径”的方法(Reweighting、Product-of-expert、Order-changes)进行比较,结果如下图,贴出了作者在自然语言推理任务上对Bert-base、DistillBert模型的实验分析结果。该实验用MNLI的训练数据来训练模型,图中的MNLI代表域内测试数据,Hard和HANS代表域外测试数据。通过实验结果来看,其他三种消除“捷径”的方法一定程度上提升了模型在域外数据上的准确率,但牺牲了模型在域内数据上的准确率。相比而言,LTGR方法既提升了模型在域内数据上的准确率,又能够提升模型在域外数据上的效果。

3.2 LTGR框架介绍
关于LTGR框架,我们也有一些细节方面的介绍。
3.2.1 Shortcut degree的计算
介绍之前,我们需要具备一些先验知识:
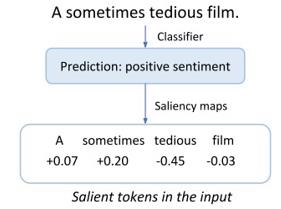
积分梯度[9]是一种用来帮助解释模型决策过程的可解释性方法,能够计算句子中每个token对于预测结果的贡献程度,如下图情感分析任务的样例所示。
-
Shortcut会在模型微调过程的早期被学习到(目前已有研究证明模型早期更倾向于学习Shortcut,使loss快速下降)。
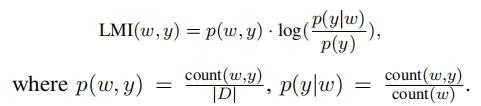
统计分布如下图的“长尾分布”现象,发现在头部的词往往是功能词,比如停用词、否定词、数字等等,在尾部往往是信息量高的词。

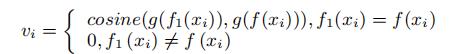
3.2.2 蒸馏过程的loss计算
蒸馏过程的loss定义如下:

主要分为两部分:
student model预测softmax概率与ground truth求交叉熵,得到loss定义中的第一部分。
student model预测softmax概率与Si求交叉熵,得到loss定义中的第二部分。
个人理解蒸馏操作loss的第一部分是希望student model能够学习到样本正确的标签,loss的第二部分是当模型面对shortcut degree高的样本时,希望模型尽可能的做出平滑的预测,减小模型对于shortcut的关注度。
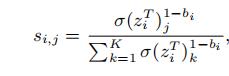
4.总结
模型对于“捷径”的学习根源其实是训练数据造成的,因此,我们期望在未来能够产出更高质量的数据,尽可能的减少训练数据有偏所带给模型的“捷径”,当然数据量特别庞大时,对于数据的操作有很大的挑战。除了对训练数据的处理,我们可以将目光放在模型的学习过程,如何让模型具备自主的学习能力,在学习过程中尽可能少的关注“捷径”,更多的关注对于句子语义或者复杂逻辑的学习而不是“偷懒”,这是我们可以努力研究的方向。
参考资料
Roberta Grirhos,Jacobsen,et al."Shortcut Learning in Deep Neural Networks."arXIV preprint arXIV:2004.07780.
[2]Samuel R.Bowman,Gabor Angeli,et al."A large annotated corpus for learning natural language inference."arXIV preprint arXIV:1508.05326.
[3]Suchin Gururangan,Swabha Swayamdipta,et al."Annotation Artifacts in Natural Language Inference Data".arXIV preprint arXIV:1803.02324.
[4]Pranav Rajpurkar,Jian Zhang, et al."SQuAD:100,000+ Questions for Machine Comprehension of Text".arXIV preprint arXIV:1606.05250.
[5]Yuxuan Lai,Chen Zhang,et al."Why Machine Reading Comprehension Models Learn Shortcut".arXIV preprint arXIV:2106.01024.
[6]Ronan Le Bras,Swabha Swayamdipta,et al."Adversarial Filters of Dataset BIases".2020 International Conference on Machine Learning.ICML 2020.
[7]Pride Kavumba,Benjamin Heinzerling,et al."Learning to Learn to be Right for the Right Reasons".arXIV preprint arXIV:2104.11514.
[8]Mengnan Du,Varun Manjunatha,et al."Towards Interpreting and Mitigating Shortcut Learning Behaviour of NLU Models".arXIV preprint arXIV:2103.06922.
[9]Mukund Sundararajan,Ankur Tuly,et al."Axiomatic Attribution for Deep Networks".Proceedings of the 34th International Conference on Machine Learning, PMLR 70:3319-3328, 2017.
[10]Stefan Evert. 2005. The statistics of word co-occurrences: word pairs and collocations.
本期责任编辑:丁 效
END
欢迎加入NLP未来大佬学习交流群
每日干货,共同成长
往期推荐
以上是关于自然语言处理中模型的“偷懒”的主要内容,如果未能解决你的问题,请参考以下文章