实时OLAP分析利器Druid介绍
Posted 民宿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时OLAP分析利器Druid介绍相关的知识,希望对你有一定的参考价值。
前言
项目早期、数据(报表分析)的生产、存储和获取业务,mysql基本上可以满足需要,但是随着业务的快速增长,数据量翻至亿为单位时,MySQL无法满足例如:快速实时返回“分组+聚合计算+排序聚合指标”查询需求。记得还是2017年之后,对当时的几款OLAP进行了调研,用线上数据训练。当时Druid在性能和功能上基本上能够满足需要,下面介绍一下Apache Druid。
Druid介绍
Apache Druid 是一个高性能实时分析数据库,在复杂的海量数据下进行交互式实时数据展现的OLAP工具。能够处理TB级别数据,毫秒级响应。目前国内在使用的公司有:阿里、滴滴、知乎、360、eBay,Hulu等。官方网址:http://druid.io
主要特性
- 开源、列式存储,预聚合
- 实时流式和批量数据摄入
- 灵活的数据模式、支持SQL查询
- 扩展方便,容易运维
- TB,PB级别的数据处理
基础概念
数据格式
数据源:datasource,datasource的结构有:时间列(timestamp)、维度列(Dimension)和指标列(Metric)
时间列:将时间相近的一些数据聚合在一起,查询的时候指定时间范围
维度列:标识一些统计的维度,比如:名称、类别等
指标列:用于聚合和计算的列,比如:访问总数、合计金额等
|
timestamp |
demensions |
metric |
||||
|
date |
userid |
username |
age |
sex |
visits |
costs |
|
2020-01-01T00:00:00Z |
100001 |
张三 |
20 |
男 |
201 |
20.10 |
|
2020-01-01T00:00:00Z |
100002 |
李四 |
21 |
男 |
160 |
16.00 |
|
2020-01-01T00:00:00Z |
100003 |
王五 |
20 |
女 |
100 |
10.00 |
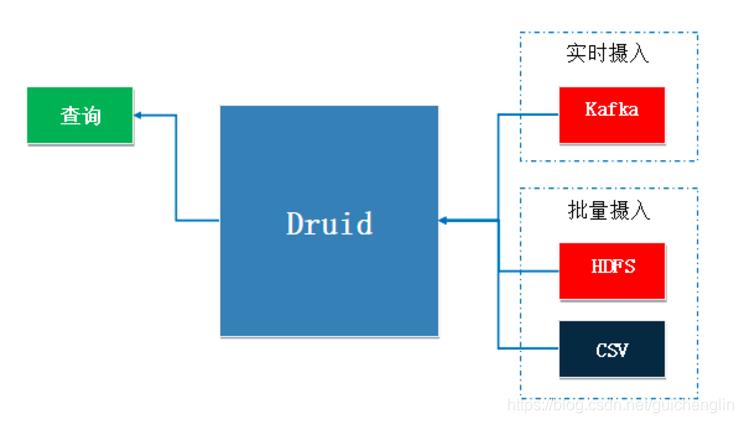
数据摄入
同时支持流式和批量数据摄入。通常通过像 Kafka 这样的消息总线(加载流式数据)或通过像 HDFS 这样的分布式文件系统(加载批量数据)来连接原始数据源。
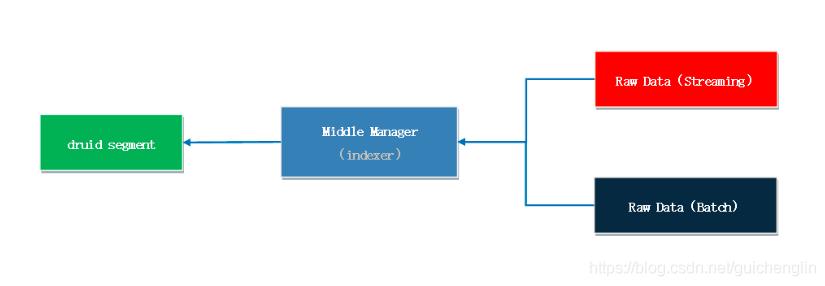
Druid 通过 Indexing 处理将原始数据以 segment 的方式存储在数据节点,segment 是一种查询优化的数据结构。
数据存储
Druid 采用列式存储。根据不同列的数据类型(string,number 等),Druid 对其使用不同的压缩和编码方式。Druid 也会针对不同的列类型构建不同类型的索引。
类似于检索系统,Druid 为 string 列创建反向索引,以达到更快速的搜索和过滤。类似于时间序列数据库,Druid 基于时间对数据进行智能分区,以达到更快的基于时间的查询。
不像大多数传统系统,Druid 可以在数据摄入前对数据进行预聚合。这种预聚合操作被称之为 rollup,这样就可以显著的节省存储成本。
数据查询
支持两种查询:JSON-HTTP,SQL两种方式
查询类型
Timeseries:基于时间范围查询的类型
TopN:基于单维度的排名查询
GroupBy:基于多维度的分组查询
架构
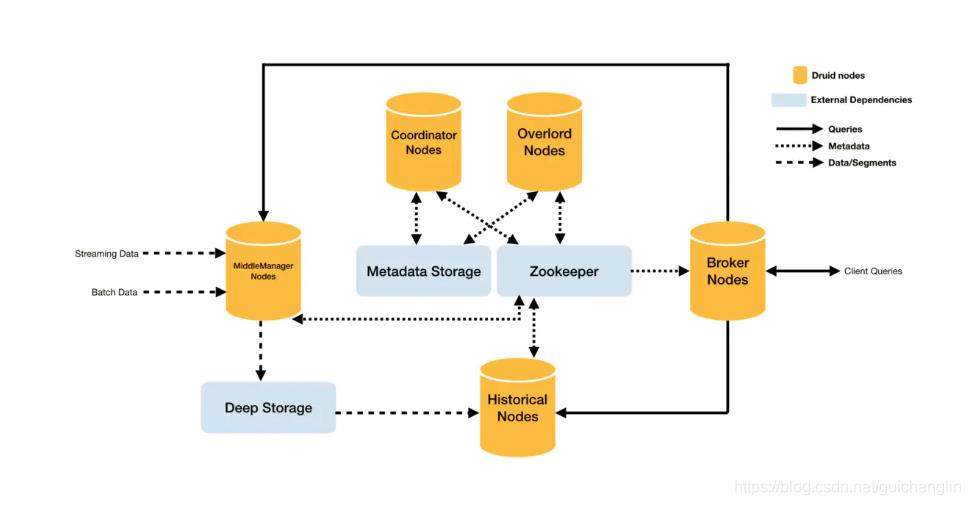
运维
Druid是非常健壮的系统,Druid 拥有数据副本、独立服务、自动数据备份和滚动更新,以确保长期运行,并保证数据不丢失。
OLAP方案对比
|
|
Druid |
Kylin |
Elasticsearch |
Spark SQL |
|
数据规模 |
超大 |
超大 |
中等 |
超大 |
|
查询效率 |
高 |
高 |
中等 |
低 |
|
并发度 |
高 |
高 |
高 |
低 |
|
SQL支持 |
中 |
高 |
中 |
高 |
|
灵活度 |
中 |
低 |
高 |
高 |
Druid:是一个实时处理时序数据的OLAP数据库,因为它的索引首先按照时间分片,查询的时候也是按照时间线去路由索引。
Kylin:核心是Cube,Cube是一种预计算技术,基本思路是预先对数据作多维索引,查询时只扫描索引而不访问原始数据从而提速。
ES:最大的特点是使用了倒排索引解决索引问题。根据研究,ES在数据获取和聚集用的资源比在Druid高。
Spark SQL:基于Spark平台上的一个OLAP框架,基本思路是增加机器来并行计算,从而提高查询速度。
使用场景
- 广告数据分析
- 风控分析
- 服务器指标存储
- 应用性能指标
- 实时在线分析系统 OLAP
- 实时报表分析
- 离线+实时数据源
- 行为数据分析
使用建议
- 时序化数据:所有行记录中必须有日期指标
- OLAP并发有限,不适合OLTP查询,建议首次回源加Cache
- 目前不支持JOIN操作,不支持数据更新
- 离线数据替换前一天实时数据
- 分页支持的不够完善
另外、Druid在项目中已经投产多年,用OLAP方案解决业务上的问题,整理技术点为了方便相似业务同学参考和使用。
参考
https://druid.apache.org/docs/latest/design/
转载:https://www.cnblogs.com/guichenglin/p/12716475.html
以上是关于实时OLAP分析利器Druid介绍的主要内容,如果未能解决你的问题,请参考以下文章
Druid入门—— 快速入门实时分析利器-Druid_0.17