实时数据流计算引擎Flink和Spark剖析
Posted 浅梦的学习笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时数据流计算引擎Flink和Spark剖析相关的知识,希望对你有一定的参考价值。
“ 在过去几年,业界的主流流计算引擎大多采用Spark Streaming,随着近两年Flink的快速发展,Flink的使用也越来越广泛。与此同时,Spark针对Spark Streaming的不足,也继而推出了新的流计算组件。本文旨在深入分析不同的流计算引擎的内在机制和功能特点,为流处理场景的选型提供参考!”
文章来源:https://zhuanlan.zhihu.com/p/210826594
一. Spark Streaming
Spark Streaming是Spark最早推出的流处理组件,它基于流式批处理引擎,基本原理是把输入数据以某一时间间隔批量的处理(微批次),当批处理时间间隔缩短到秒级时,便可以用于实时数据流。
1. 编程模型
在Spark Streaming内部,将接收到数据流按照一定的时间间隔进行切分,然后交给Spark引擎处理,最终得到一个个微批的处理结果。
2. 数据抽象
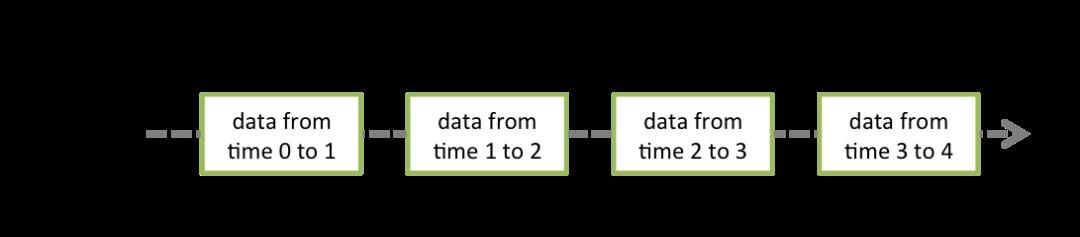
离散数据流或者数据流是Spark Streaming提供的基本抽象。它可以是从数据源不断流入的,也可以是从一个数据流转换而来的。本质上就是一系列的RDD。每个流中的RDD包含了一个特定时间间隔内的数据集合,如下图所示。
3. 窗口操作
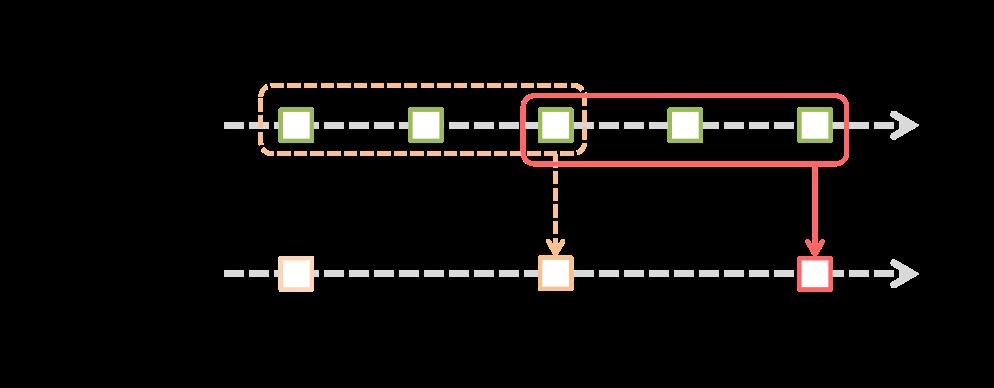
Spark Streaming提供了滑动窗口接口,滑动窗口的两个重要的参数是窗口大小,滑动步长。它允许在数据的滑动窗口上应用转换。如下图所示,每当窗口在源Dstream上滑动时,位于窗口内的源RDDs就会被何冰冰操作,来生成窗口化的Dstream的RDDs。
 二. Flink
二. Flink
由于Spark Streaming是基于批处理引擎的,因此它的处理延时较大,基本上为秒级延迟。因此,具有毫秒级的流处理引擎Flink诞生了。
Flink从2014年12月成为Apache的顶级项目,近两年才逐渐走入大众视野。Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。Flink的特点是低延迟、高吞吐和一致性(结果的准确和良好的容错性)。
1. 编程模型
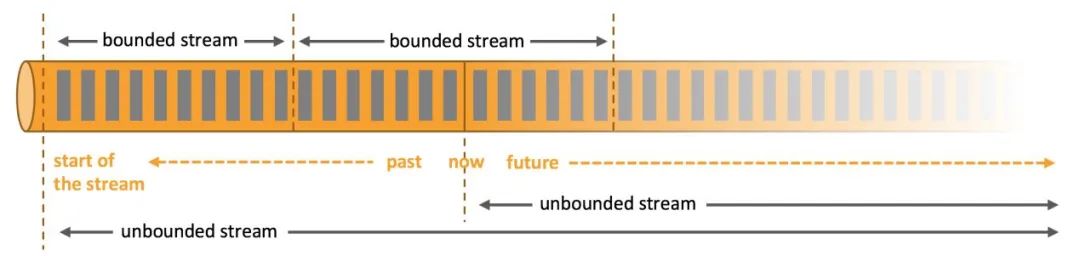
在Flink中,流也被分成两类:无界流和有界限,分别对应着Flink中的流处理场景和批处理场景。
无界流:有开始无结束的流;
有界流:批处理被抽象成有界流,有开始也有结束的数据流;
2.窗口类型
Flink中提供了三种窗口计算类型:滚动窗口、滑动窗口和会话窗口。
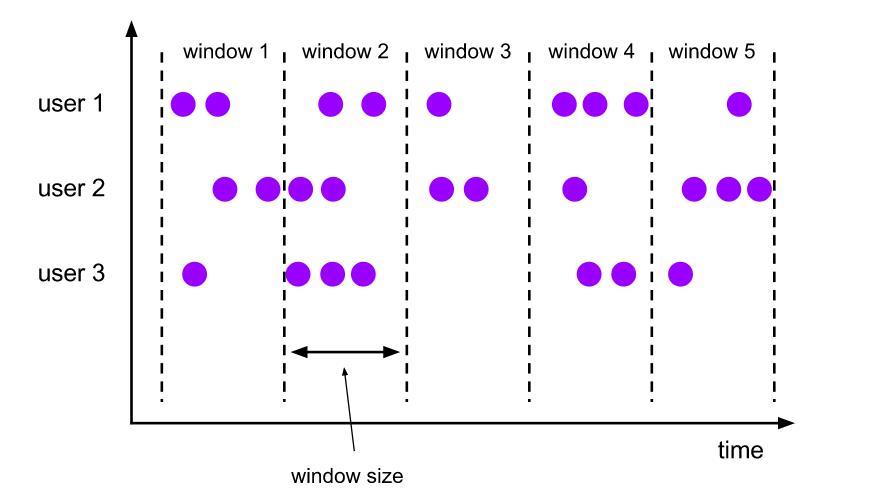
滚动窗口是将每个元素分配给具有指定窗口大小的窗口。滚动窗口有固定大小,而且不会互相重叠。一个窗口的结束意味着另一个窗口的开始。
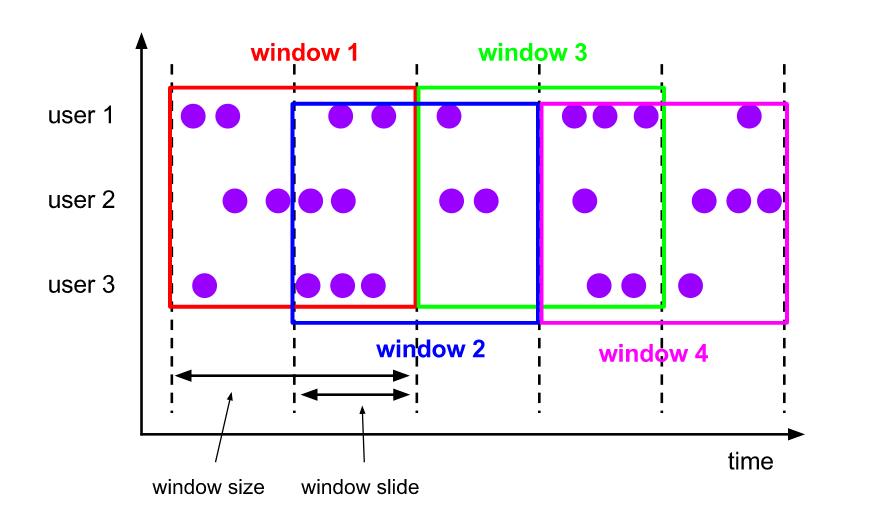
滑动窗口将元素分配到固定长度的窗口,类似于滚动窗口的分配。窗口大小由窗口大小参数配置。滑动步长控制滑动窗口启动的频率,如果滑动步长小于窗口大小,则滑动窗口会有重叠。
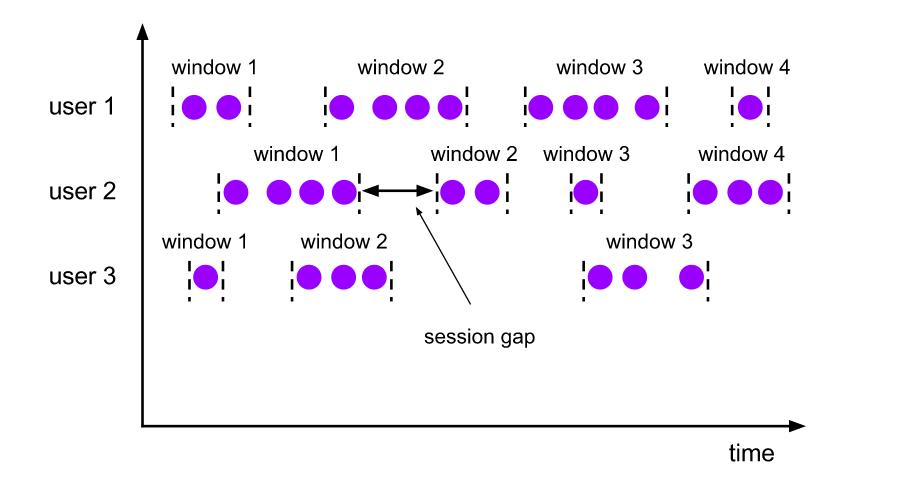
会话窗口:会话窗口根据会话间隔进行窗口的划分,与滑动和滚动窗口相比,会话窗口没有重叠,也没有固定的开始和结束时间。
3.时间语义
Flink提供了三种时间语义,分别是事件时间、注入时间和处理时间。
事件时间即为事件发生的时间;
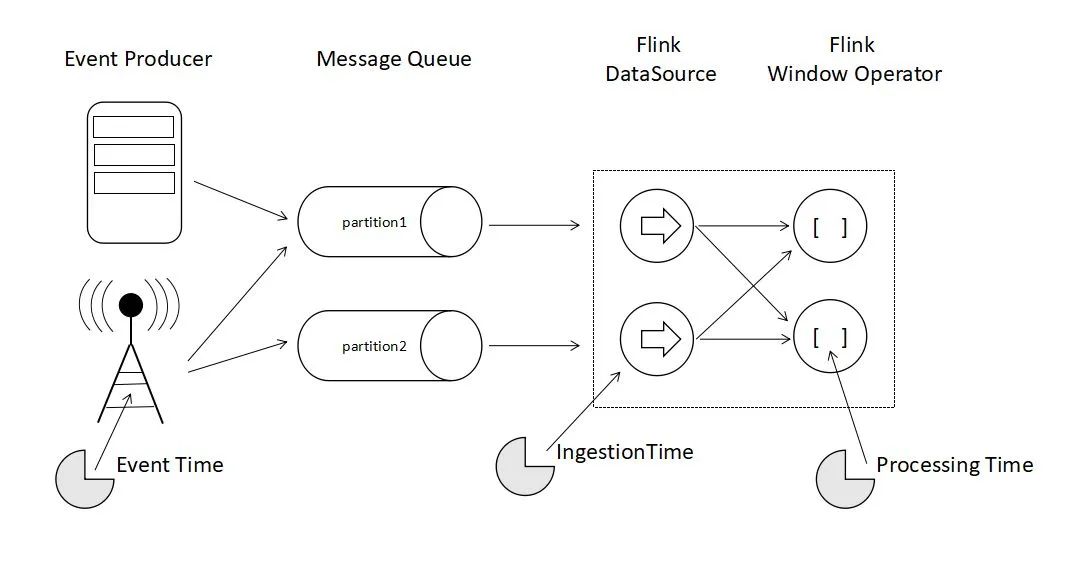
注入时间是指数据从数据源进入数据处理引擎的时间;处理时间是真正进行数据处理的任务运行的机器时间。
-
「watermark机制」
Flink在事件时间应用程序中使用水印来判断时间。水印也是一种灵活的机制,以权衡结果的延迟和完整性。
三、Structured Streaming
随着Flink的兴起,以及Spark Streaming的短板显现,从Spark 2.0开始引入了Structured Streaming, 将微批次处理从高级 API 中解耦出去,简化了 API 的使用,API 不再负责进行微批次处理;开发者可以将流看成是一个没有边界的表,并基于这些“表”运行查询。Structured Streaming的默认引擎基于微批处理引擎,并且可以达到最低100ms的延迟和数据处理的exactly-once保证。
从Spark 2.3开始,Structured Streaming继续向更快、更易用、更智能的目标迈进,引入了低延迟的持续流处理模式,这时候已经不再采用批处理引擎,而是一种类似Flink机制的持续处理引擎,可以达到端到端最低1ms的延迟和数据处理的at- least-once的保证。采用何种处理模式只需要进行简单的模式配置即可。
「1.编程模型」
Structured Streaming将数据流看作是一张无界表,每个流的数据源从逻辑上来说看做一个不断增长的动态表,从数据源不断流入的每个数据项可以看作为新的一行数据追加到动态表中。用户可以通过静态结构化数据的批处理查询方式(SQL查询),对数据进行实时查询。
 「2.触发类型」
「2.触发类型」
Structured Streaming通过不同的触发模式来实现不同的延迟级别和一致性语义。主要提供了以下四种触发模式:
单次触发:顾名思义就是只触发一次执行,类似于Flink的批处理;
周期性触发:查询以微批处理模式执行,微批执行将以用户指定的时间间隔来进行;
默认触发:一个批次执行结束立即执行下个批次;
连续处理:是Structured Streaming从2.3开始提出的新的模式,对标的就是Flink的流处理模式,该模式支持传入一个参数,传入参数为checkpoint间隔,也就是连续处理引擎每隔多久记录查询的进度;
「3.写入模式」
为了满足不同操作的结果需求,还提供了三种写入模式:
Complete:当trigger触发时,输出整个更新后的结果表到外部存储,存储连接器决定如何处理整个表的写入
Append:只有最后一次触发的追加到结果表中的数据行会被写入到外部存储,这只适用于已存在的数据项没有被更新的情况
Update:之后结果表中被更新的数据行会被写出到外部存储
「4.窗口类型」
在窗口类型方面,Structured Streaming继续支持滑动窗口,跟spark Streaming类似,但是Spark Streaming是基于处理时间语义的,Structured Streaming还可以基于事件时间语义进行处理。
「5.时间语义」
时间语义上,Structured Streaming也是根据当前的需要,支持了事件时间和处理时间,一步步向Flink靠近。
「6.Watermark机制」
在进行流处理的时候,不能无限保留中间状态结果,因此它也通过watermark来丢弃迟到数据。因为Flink和Structured Streaming都是支持事件时间语义,因此都支持watermark机制。
四. 总结
上面的这张表展示了三种流处理在一些特性和机制方面的比较。技术总在互相比较和互相借鉴中发展。Spark紧跟流处理的步伐,弥补短板;Flink也不仅在流处理方面发力,在生态建设方面也加快了步伐。究竟谁能最终统一江湖,我们可以拭目以待。
推荐阅读
码字很辛苦,有收获的话就请分享、点赞、在看三连吧 以上是关于实时数据流计算引擎Flink和Spark剖析的主要内容,如果未能解决你的问题,请参考以下文章 基于Kafka的实时计算引擎:Flink能否替代Spark?