实时和离线,大数据计算引擎谁主沉浮
Posted 学而知之@
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时和离线,大数据计算引擎谁主沉浮相关的知识,希望对你有一定的参考价值。
摘要:今天分享的主要内容是实时、离线大数据计算引擎的简介和对比,希望通过此文各位同学能收获一二。本文主要内容包括:
1、Flink简介
2、Spark简介
3、Flink和Spark的引擎技术对比
4、两大技术的发展方向

一、Flink简介
1.1、官方定义:
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
1.2、有界流和无界流:
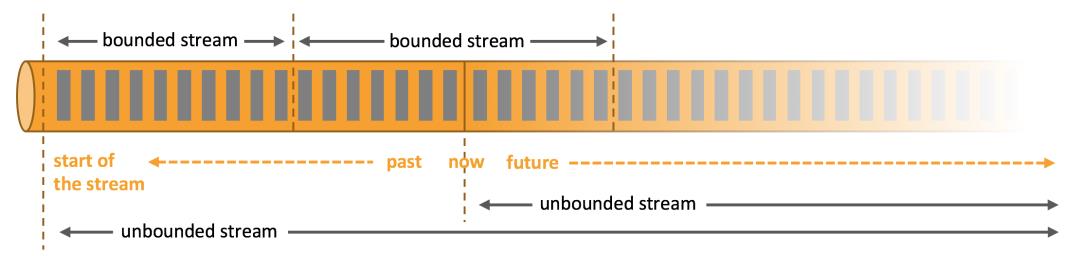
有界流:
可以在摄取所有数据后再进行计算。
有界流所有数据可以被排序。
无界流:
不能等到所有数据到达再处理,因为输入是无限的。
数据通常要求以特定顺序摄取。
1.3、流和状态:
Apache Flink 是一个针对无界和有界数据流进行有状态计算的框架。

流:
有界和无界的数据流
实时和历史记录的数据流
状态(中间结果):
状态是Flink中的一等公民
持久化和checkpoint
精准一次语义
时间:
事件时间(event-time)和处理时间(processing-time)
Watermark,平衡处理延时和完整性的机制
1.4、API:
Flink 根据抽象程度不同,提供了三种不同的 API。每一种 API 在简洁性和表达力上有 着不同的侧重,并且针对不同的应用场景。
ProcessingFunction:提供了基于事件的对于时间和状态的细粒度控制
DataStream:提供了流处理原语,预定义了map()、reduce()、aggregate()等函数
SQL/Table API:借助了Apache Calcite,将无界流和有界流数据进行统一
1.5、Flink架构图:
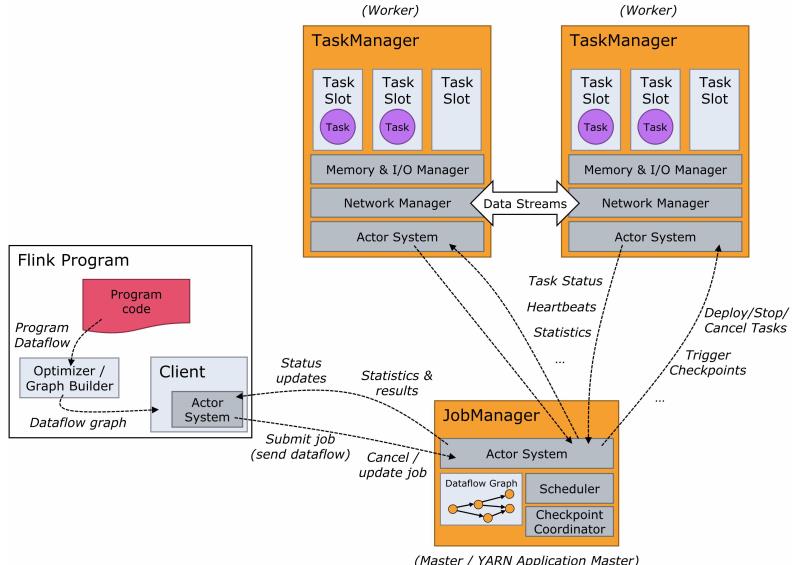
Flink运行时有两种类型的进程组成:一个JobManager和一个或者多个TaskManager。Flink 架构也遵循 Master-Slave 架构设计原则,JobManager 为 Master 节点,TaskManager 为 Worker (Slave)节点。
JobManager :
负责整个 Flink 集群任务的调度以及资源的管理,从客户端中获取提交的应用,然后根据集群中 TaskManager 上 TaskSlot 的使用情况,为提交的应用分配相应的 TaskSlot 资源并命令 TaskManager 启动从客户端中获取的应用
JobManager 相当于整个集群的 Master 节点,且整个集群有且只有一个活跃的 JobManager ,负责整个集群的任务管理和资源管理
TaskManager:
TaskManager 相当于整个集群的 Slave 节点,负责具体的任务执行和对应任务在每个节点上的资源申请和管理
客户端通过将编写好的 Flink 应用编译打包,提交到 JobManager,然后 JobManager 会根据已注册在 JobManager 中 TaskManager 的资源情况,将任务分配给有资源的 TaskManager节点,然后启动并运行任务
1.6、Flink生态圈:

Deployment层:该层主要涉及了Flink的部署模式,Flink支持多种部署模式:本地、集群(Standalone/YARN),(GCE/EC2)。
Runtime层:Runtime层提供了支持Flink计算的全部核心实现,比如:支持分布式Stream处理、JobGraph到ExecutionGraph的映射、调度等等,为上层API层提供基础服务。
API层:主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中面向流处理对应DataStream API,面向批处理对应DataSet API。
Libraries层:该层也可以称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。面向流处理支持:CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);面向批处理支持:FlinkML(机器学习库)、Gelly(图处理)

二、Spark简介
2.1、官方定义:
Apache Flink是用于大规模数据处理的统一分析引擎。
2.2、Spark架构图:
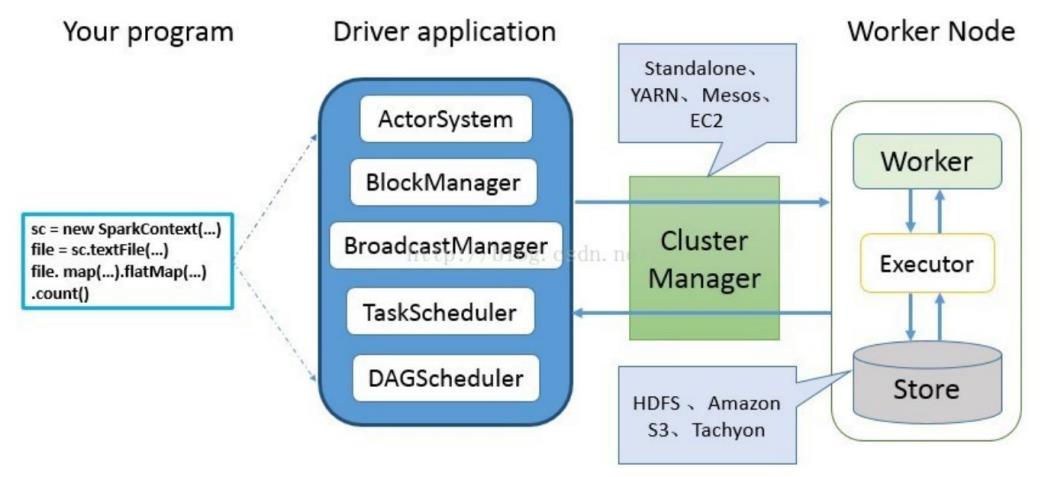
Spark 运行时由两种类型的进程组成:一个 Driver 和一个或者多个 Executor。
2.3、Spark执行流程图:
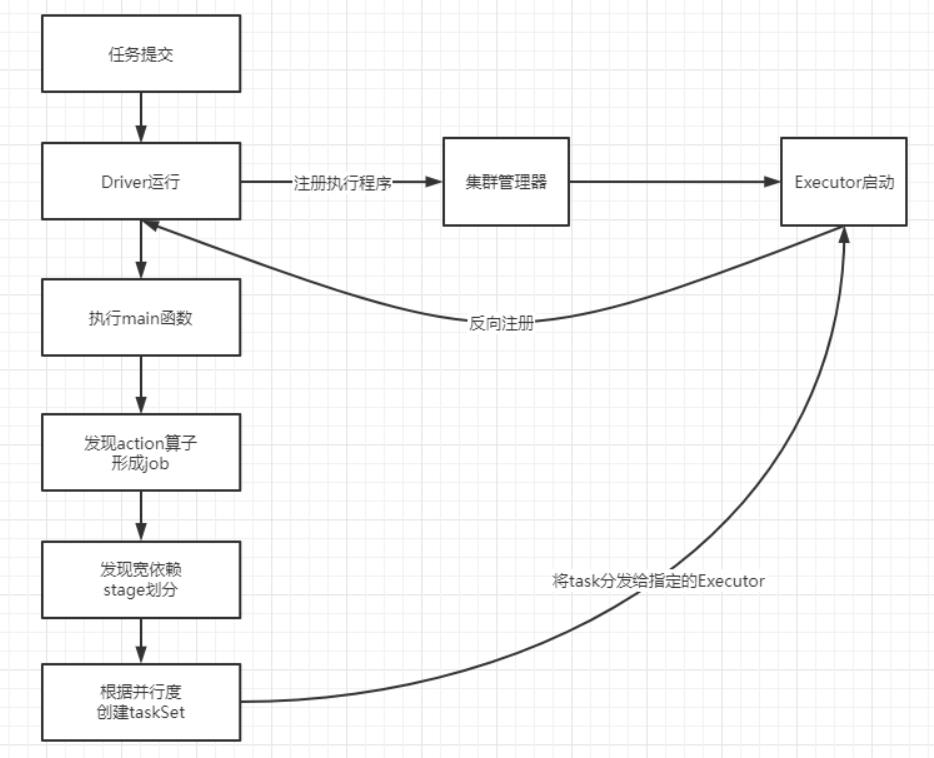
2.4、核心概念介绍:
Master:
Spark特有的资源调度系统Leader,掌控整个集群资源信息,类似于Yarn框架中的ResourceManager
Master对Worker、Application等的管理(接收Worker的注册并管理所有的Worker,接收Client提交的Application,调度等待Application并向Worker提交)
Worker:
Spark特有的资源调度Slave,有多个,每个Slave掌管着所有节点的资源信息,类似Yarn框架中的NodeManager
通过RegisterWorker注册到Master
定时发送心跳给Master
根据Master发送的Application配置进程环境,并启动ExecutorBackend(执行Task所需的计算任务进程进程)
Driver:
Spark的驱动器,是执行开发程序中的main方法的线程
将用户程序转化为作业(Job)
在Executor之间调度任务(Task)
跟踪Executor的执行情况
通过UI展示查询运行情况
Excutor:
Spark Executor是一个工作节点,负责在Spark作业中运行任务,任务间相互独立
负责运行组成Spark应用的任务,并将结果返回给驱动器(Driver)
通过自身块管理器(BlockManager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算
RDDs:
Resilient Distributed DataSet:弹性分布式数据集
一旦拥有SparkContext对象,就可以用它来创建RDD
2.5、RDD的设计:

出自 2012 Berkley’s AMPLab 论文
一种容错的内存计算数据抽象
不可变,可重复计算
分布式对象集合
通过多个分区将数据分散在不同节点
并行计算
分区可以在内存中也可以在硬盘上
通过血缘可以知道所有计算的顺序和历史
什么是RDD:
分布在磁盘上的一组对象的集合
分布在内存里的一组对象的集合
分布在 Cassandra 集群里的一组对象的集
2.6、APIs:
Spark 根据抽象程度不同,也提供了三种不同的 API。每一种 API 在简洁性和表达力上 有着不同的侧重,并且针对不同的应用场景。
RDD:提供了基本的非结构化数据处理能力。
Dstream:利用 Micro-Batch 将流式数据特化为批处理的接口。
DataFrame/DateSet:提供了结构化数据的处理,将无边界流和有边界数据进行统 一。
SQL:抽象级最高。适合数据分析等应用
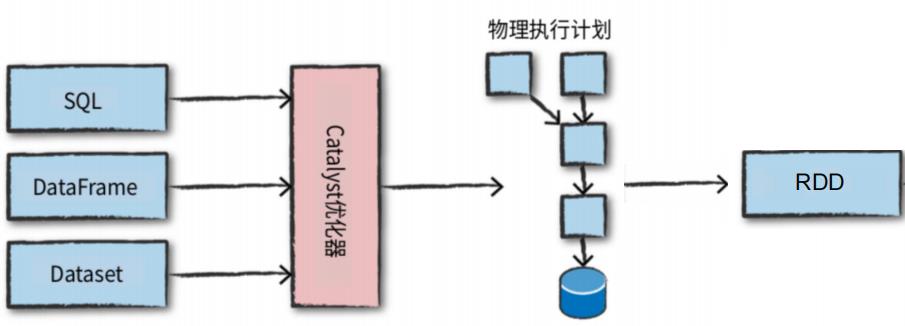

三、Flink和Spark的对比
3.1、Streaming设计理念不同:
Spark Streaming是Micro-Batch模型,该模型认为“流是批的特化”,流式计算即是连续计算足够小的批。当批处理引擎足够快时,可以做到几乎每一条记录为一个“批”。

PS:使用Spark Streaming处理流式计算存在着低延时的瓶颈,但业务真的需要毫秒级的延时吗??
Flink Streaming是真正的流的数据模型,该模型认为“批是流的特化”,批处理就是缓存一段时间的流。
3.2、流式计算方面:
Flink在流式计算,低延时应用上几乎是碾压SparkStreaming的。
近年来,Spark 也在流计算方面做了不少努力,从 2.0 开始引入了 Structured Streaming,到 2.3 上实现了持续处理 Continuous Processing。

3.3、批处理计算方面:
Spark 在离线计算,批处理上仍然具有压倒性的优势。特别是在SQL层面,SQL优化器上,离线数据仓库技术等方向,非常的成熟和强大。
近年来,Flink也在SQL支持,批处理上做了不少努力。
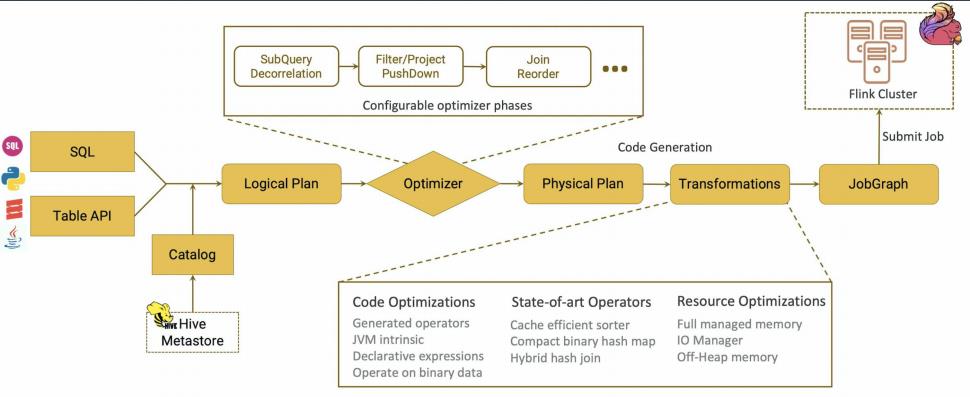
3.4、数据模型方面:
Spark最早采用RDD模型,达到比MR快100倍的显著优势。RDD弹性分布式数据集是分隔为固定大小的批数据,RDD提供了丰富的API对数据集做操作。
Flink的基本数据模型是数据流,及事件(Event)的序列。数据流作为数据的基本模型可能没有表或者数据块直观熟悉,但是可以证明是完全等效的。流可以是无边界的无限流,也就是真正的流处理。也可以是有边界的有限流,这样就是批处理。
3.5、运行时架构:
Spark运行时架构:批计算是把DAG划分为不同的stage,DAG节点之间有血缘关系,在运行期间一个stage的task任务列表执行完毕,销毁再去执行下一个stage;Spark Streaming则是对持续流入的数据划分一个批次,定时去执行批次的数据运算。
Flink运行时架构:Flink有统一的runtime,在此之前是Batch API、Stream API、ML、CEP等DAG中的节点上执行上述模块的功能函数,DAG会一步步转化为ExecutionGraph,即物理可执行的图,最终交给调度系统。
在DAG的执行上,Spark和Flink有一个比较显著的区别。在Flink的流执行模型中,一个事件在一个节点处理完后的输出就可以发到下一个节点立即处理。这样执行引擎并不会引入额外的延迟。与之相应的,所有节点是需要同时运行的。而Spark的Micro-Batch和一般的batch执行一样,处理完上游的stage得到的输出之后才开始下游的stage
3.6、应用场景:
Spark 适合的场景:
批量处理(Batch Processing),偏重点在于处理海量数据的能力,至于处理延时 可忍受,通常的时间可能是在数十分钟到数小时
基于历史数据的交互式查询(Interactive Query),通常的时间在数十秒到数十分 钟之间
复杂的 SQL 查询和离线/近实时数据分析( Data Analytics Applications )应用
一般的机器学习(Machine Learning)任务
Flink适合的场景:
基于实时数据流的数据处理(Streaming Processing),通常在数十毫秒到数百毫秒之间
典型的事件驱动类应用,包括欺诈检测(Fraud detection)、异常检测(Anomaly detection)、基于规则的告警(Rule-basedalerting)、业务流程监控(Business process monitoring)、Web应用程序(社交网络)等
实时的数据分析应用(Real-time Data Analytics Applications)
管道式 ETL(Data Pipeline Applications), 比如启动一个 Flink 实时应用,数据源(比如数据库、Kafka)中的数据不断的通过 Flink Data Pipeline流入或者追加到数据仓库(数据库或者文件系统),或者 Kafka 消息队列

四、两大技术的发展方向
Spark和Flink无疑是这个时代最好的计算引擎,它们在各自的场景和生态中都发挥着不可替代的作用,至于未来会如何发展,还要看社区如何推动了。
大数据+AI:
目前无论是实时计算还是离线计算,在人工智能领域都有着非常大的发展前景
Spark 已经做了大量的工作,例如 PySpark,MLlib,Mlflow,Koalas,GPU 调 度器等等
Flink 下一步也将加大对 AI 场景的支持,支持更多机器学习算法,与 TensorFlow/PyTorch 等深度学习框架更好的集成,支持Python API等

实时数仓+数据湖:
实时数仓也是企业大数据发展的一个重要方向
虽然实时数仓强调的是实时,但是由于低延迟并非是实时数仓中最重要的因素, 所以无论是 Spark Streaming 还是 Flink 都可以构建实时数仓
支持更好的数仓工具,提供快速的数据分析和查询性能等仍然是数仓引擎的关键
谁能在数据湖/湖仓一体技术上抢占先机变得尤为重要。目前 Spark+Hudi, Spark+Delta,Flink+Hudi,Flink+Iceberg 还没有明显差距

IOT边缘技术:
物联网 IoT 应用的增加,增加了实时计算的需求,Flink 在流式计算中具有的天然 优势
IoT 边缘计算也有自己的计算引擎,主要是时序数据库。离线分析也将是非常常 见的需求

云原生:
还有一个重要的方向是云原生,Spark 和 Flink 都在与 Kubernetes 深度融合
Flink 1.12 已经可以原生地运行在 Kubernetes 之上,对接 K8S 的 HA 方案,并 不再依赖 ZooKeeper,达到生产可用级别
Spark3.0.0 也有大量 K8S 支持的增加,但目前因为调度器和 shuffle 服务的问题, 仍然需要额外的开发


写在最后
大数据技术发展到现在已经是百花齐放,各个公司也在紧跟新技术浪潮,希望通过更好的解决方案为业务赋能。但殊途同归,不管用什么技术最终也逃不开这几个问题:
框架没有谁比谁强,只有适不适合
框架再好也有被淘汰的一天
大数据技术庞杂,紧跟业务需求
今天分享的内容先到这里了,欢迎感兴趣的小伙伴关注、交流。让我们站在巨人的肩膀上,不断砥砺前行。
往期推荐
点分享

点收藏

点点赞

点在看
以上是关于实时和离线,大数据计算引擎谁主沉浮的主要内容,如果未能解决你的问题,请参考以下文章