HBase
Posted 大数据架构成长日记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase相关的知识,希望对你有一定的参考价值。
1. 如何设计一个分布式KV数据库头脑风暴
需求:确保在海量数据中,实现低延时的随机读写操作?
· 如果是少量数据:设计一个类似Map类型的数据结构
· 如果是海量数据,那么大致的一些方案总计:
1. 排序 —> 二分查询 —> 范围分区 + 索引 —> Topo结构
2. 分区数据:内存 + 磁盘
3. 内存数据良好的数据结构
4. 磁盘数据良好的组织和索引
5. 内存设置写缓存和读缓存
6. WAL机制保证数据安全
· 功能实现
· 效率
· 安全
核心思路:
1. 解决海量数据的低延时的随机读写需求。必然需要给这些数据进行排序,假设这些数据就都是存储在一张表中。
2. 既然数据有序,就可以根据二分查询的思路,去构建一个多层索引的跳表结构,最大的好处,就是可以在固定的时间里面,快速把待搜寻的数据范围降低到原来的 1/n,n就是这张表的数据分段个数。这张表排序了,分成了多段,范围分区
3. 分段中的数据,有三种组织形式:写缓存,读缓存,磁盘文件
4. 先到读缓存中,查询,如果命中,则直接返回
5. 如果没有命中,再去写内存中查找,写内存被设计了一种特殊的数据结构能够帮助提高插入和查询的效率,所以如果能命中,这个效率也很高
6. 如果写内存也没有命中,最后就只能到磁盘文件去搜寻
7. 去设计一个布隆索引:快速判断一个元素是否在这个文件中。
8. 如果磁盘文件有多个,我使用布隆索引,挨个儿询问,如果要搜寻的数据在某一个文件中(布隆返回 true),这个文件一般来说,都不会被设计很大的。这个文 件,就是跟HDFS的默认的数据块的大小是一样的。128M
9. 这个128M的文件也会被精心设计,来提高查询效率,这个文件名称叫做HFile,自带索引结构。
2. HBase存储引擎分析
HBase核心介绍:HBase(PowerSet) 是 Google 的 BigTable 的开源实现,底层存储引擎是基于 LSM-Tree 数据结构设计的。写入数据时会先写 WAL 日志,再将数据写到写缓存 MemStore 中,MemStore 的内部实现是一个跳表数据结构,等写缓存达到一定规模后或满足其他触发条件才会 flush 刷写到磁盘,为了提高从文件中查找数据的效率,将内存的数据先按照一定的规则排序,然后刷写到磁盘上。这样就将磁盘随机写变成了顺序写,提高了写性能。每一次刷写磁盘都会生成新的 HFile 文件。
HBase解决的核心问题:海量数据的低延迟的随机读写 = 分布式 Key-Value 数据库
HBase的应用场景:
mysql 关系型数据库 小量的关系型数据
redis 内存数据结构服务器 热点数据
mongodb 文档数据库 文档数据库(图片,pdf)
elasticsearch 索引数据库 全文检索(也可分析和检索,但不是很好)
hbase 分布式NoSQL数据库 海量数据集中根据key找value
clickhouse 分布式OLAP类型的数据库 专门做分析的
TiDB 时序数据库
JunusGraph 图数据库
Hudi IceBerg 数据湖
单点查询多 ?NoSQL数据库(HBase)。扫描分析多?分析型数据库(clickhouse)
select * from table where id = x; - 单点查询
select dpt,count(*) as total from table group by dpt; - 扫描分析
mysql 对于单机系统类似于 hbase 对于分布式系统! - Kudu(分析和随机读写较为均衡)
二级索引解决方案:
假如两百个字段,50个作为查询条件,可以这样做:
· HBase + ES(实现什么,用ES存索引,来确实数据是哪条,也就是id,HBase做存储)
· 查询条件多: 把查询条件条件当做 key, id 当做value,另外一种形式是直接构建数据的全文检索索引 (全文检索索引)根据条件找到 ID
· 数据量量多:海量数据根据 key(ID) 找 value(明细数据) HBase Phoenix
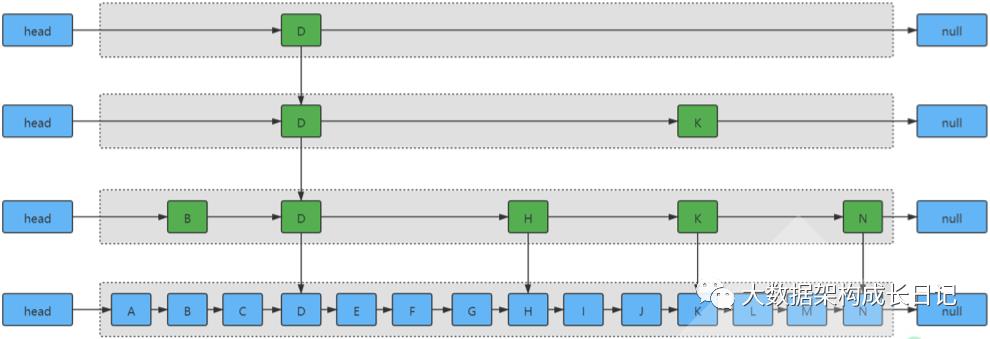
2.1 数据结构跳表分析:
对于 HBase 来说,整体的架构设计就是一个跳表结构,其次,存储在内存中的数据,也是以跳表的数据结构进行存储的!
2.2 存储引擎 LSM Tree 解析
将一次随机 IO 写入转换成一个顺序 IO 写入(HLog 顺序写入)加上一次内存写入(MemStore 写入),使得写入性能得到极大提升。
LSM 树的设计思想非常朴素:将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘,不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。极端的说, 基于 LSM 树实现的HBase 的写性能比 MySQL 高了一个数量级,读性能低了一个数量级。
LSM 树原理把一棵大树拆分成 N 棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会 flush 到磁盘中,磁盘中的树定期可以做 merge 操作,合并成一棵大树,以优化读性能。
关于 LSM-Tree 的论文:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.44.2782&rep=rep1&type=pdf
2.3 布隆过滤器详解
核心要点:它是由一个很长的二进制向量和一系列随机映射函数组成的一种用来判断元素是否存在的数据结构!
优点:迅速判断一个元素是不是在一个庞大的集合内
缺点:有误判
原本不存在于该集合的元素,布隆过滤器有可能会判断说它存在
如果布隆过滤器判断说某一个元素不存在该集合,那么该元素就一定不在该集合内
我之前CSDN上这个写个蛮详细:https://blog.csdn.net/eraining/article/details/108567882
3. HBase 逻辑表模型
HBase 是一个稀疏的、分布式的、多维排序的 Map,在 Google 2006 发表的关于 BigTable 的论文中就提到称 HBase是:sparse,distributed,persistent、multidimensional sorted map
先来看 Map 结构,根据 Key 查询 Value,我们把它称之为 一维表(value = map.get(key))。那么 HBase 就是一张稀疏的四维表。
维度的概念:
f(x) = y redis根据key找value 一维数组:本质:map
f(x1, x2) = y mysql根据ID和列找value 二维平面:mysql excel 二维表结构
f(x1, x2, x3) = y 根据长、宽、高定位立体空间中的某点 三维空间
..... 依次类推
HBase 是一个四维表的说法来源:value = table.get(rowkey, cf, qualifier, timestamp) .....
Kylin 内部将数据组织成一个多维立方体!
到底如何理解 HBase 就是一个超级复杂的 Map 呢?举例说明。
table.get(timestamp) = value
table.get(qualifier) = map(timestamp, value)
table.get(cf) = map(qualifier, map(timestamp, value))
table.get(rowkey) = map(cf, map(qualifier, map(timestamp, value)))
所以一个 HBase 其实就可以理解成:
table = map(rowkey, map(cf, map(qualifier, map(timestamp, value))))
table = map((rowkey, cf, qualifier, timestamp), value)
HBase 逻辑上可以看做是列式存储,物理上其实是行式存储,更严谨的说法是 - 列簇式存储
· 列簇式存储的第一个极端: 每个列簇只有一个列,列式存储,HBase 把每个列簇的数据单独存储
· 列簇式存储的第二个极端:整张表只有一个列簇,包含了所有的列,行式存储
来,我们看为何 HBase 是稀疏的四维表:
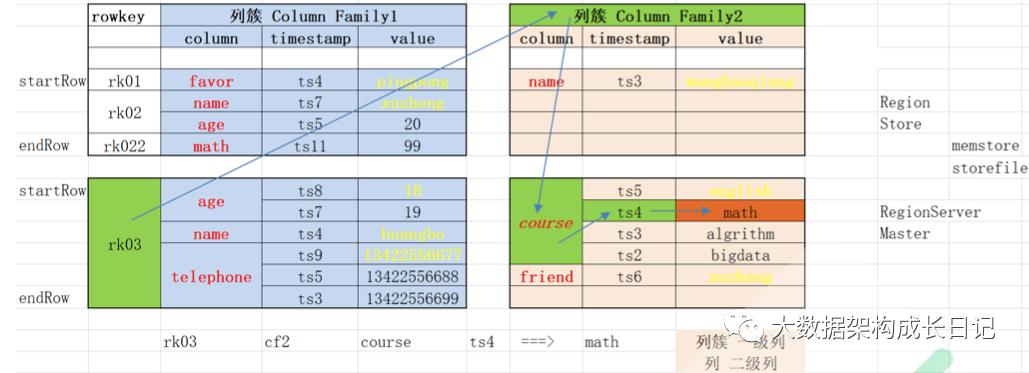
查询语句伪代码:table.get(rk03, cf2, course, ts4 ) = math
table = map(rowkey, map(cf, map(qualifier, map(timestamp, value))))
table = map((rowkey, cf, qualifier, timestamp), value)
Cell = rowkey, cf, qualifier, timestamp, value
· 逻辑上:稀疏 列式
· 物理上:紧密 行式
4. HBase 物理表模型
物理表模型,就是指真实的数据,是怎么被组织起来的进行存储的!
HFile 文件结构
5. HBase的架构设计
HBase 的宏观设计:
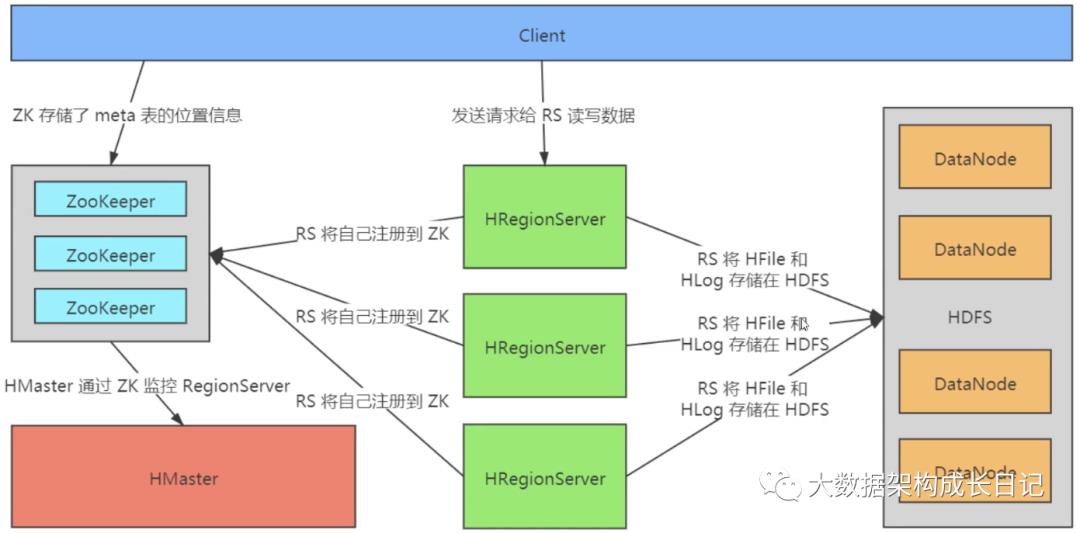
来看看各个组件的职责:
Client:
负责向 ZooKeeper 发起请求,获取元数据
维护了一个 MetaCache 用来缓存元数据信息
HMaster:
· 为 HRegionServer 分配 Region
· 负责 HRegionServer 的负载均衡
· 发现失效的 HRegionServer 并重新分配其上的 HRegion
· HDFS 上的垃圾文件(HBase)回收
· 处理 Schema 更新请求(表的创建,删除,修改,列簇的增加等等 DDL 操作,DML请求由 RegionServer 处理)
如果 HBase 的 HMaster 宕机一段时间?HBase 还能正常工作么?(可以,部分功能受影响)
· HDFS: 主从架构,namenode死亡,HDFS 集群不可用
· HBase:主从架构,HMaster死亡,HBase依然可用(DML功能可用,DDL功能不可用)
HRegionServer:
· HRegionServer 维护 HMaster 分配给它的 Region,处理对这些 Region 的 IO 请求
· HRegionServer 负责和底层的文件系统 HDFS 的交互,存储数据到 HDFS
· HRegionServer 负责 Store 中的 HFile 的合并 Compact 工作
· HRegionServer 负责 Split 在运行过程中变得过大的 Region
ZooKeeper:
· ZooKeeper 为 HBase 提供 Failover 机制,选举 HMaster,避免单点 HMaster 单点故障问题
· 存储所有 Region 的寻址入口:meta 表在哪台服务器上。
· 实时监控 HRegionServer 的状态,将 HRegionServer 的上线和下线信息实时通知给 HMaster
· 存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family
HDFS:
· 负责存储 HBase 的各个 HRegionServer 上生成的 HFile 数据文件
· 负责存储 HBase 的各个 HRegionServer 上生成的 Hlog 日志文件
详细的 HBase 架构图:
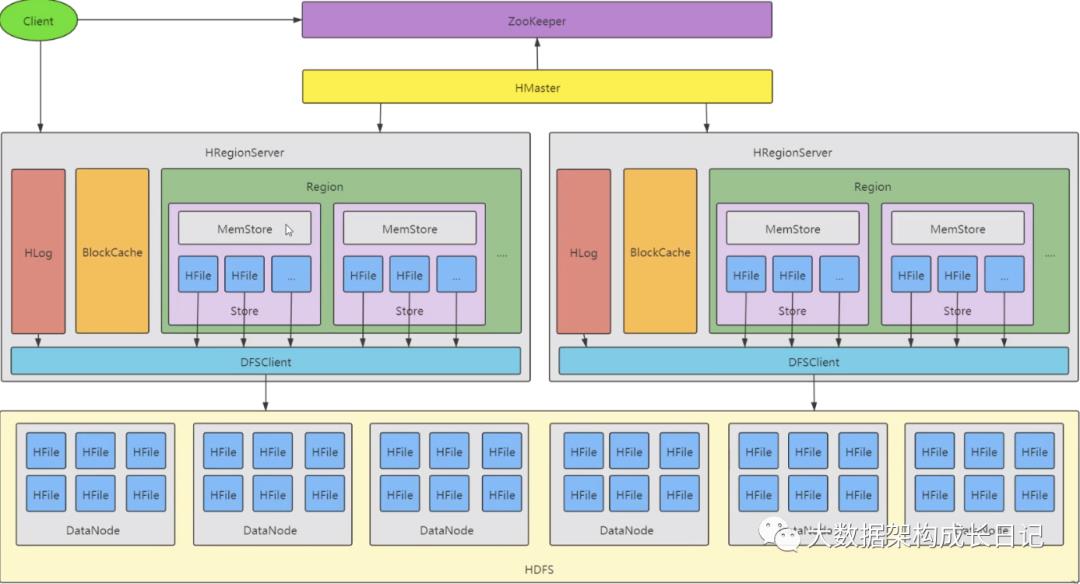
补充:
1. Table 中的所有行都按照 RowKey 的字典序排列。
2. Table 在行的方向上分割为多个 HRegion。
3. HRegion 按大小分割的(默认 10G),每个表一开始只有一个 HRegion,随着数据不断插入表,HRegion 不断增大,当增大到一个阀值的时候,HRegion 就会等分会两个新的 HRegion。当表中的行不断增多,就会有越来越多的 HRegion。
4. HRegion 是 HBase 中分布式存储和负载均衡的最小单元。最小单元就表示不同的 HRegion 可以分布在不同的 HRegionServer 上。但一个 HRegion是不会拆分到多个 Server 上的。
5. HRegion 虽然是负载均衡的最小单元,但并不是物理存储的最小单元。事实上,HRegion 由一个或者多个 Store 组成,每个 Store 保存一个Column Family。每个 Strore 又由一个 MemStore 和 0 至多个 StoreFile 组成
6. /hbase234/data/default/user_info/6e12e87c75fab6d0d7e895520e300c85/base_info/ea5e0a5c8cd04387b7a564d85b766f22
一个 hbase 集群有一个 Hmaster,有多个 HRegionserver
一个 HRegionserver 管理了多个 regoin
一个 region 内部有可能有个 store,一个列簇对应到一个 store
每个 store 里面有:
memstore 写缓存
blockcache 读缓存
storeFile HFile 磁盘文件
一张表在横向方向上,按照行健 rowkey 进行范围分区,拆分成多个 region,范围分区
一个 region 会在纵向上,进行拆分形成多个 store
每个 store 保存 就是一张表中的,一个 region 中的,一个列簇的所有数据
6. HBase的核心概念
架构概念:
HMaster 主节点,依赖于 zookeper 实现 HA
HRegionserver 管理 region
client 负责发起请求的:能缓存之前已经查询得到的 region 的位置
zookeeper 帮助 hbase 实现一些服务协调
HDFS 底层文件系统支撑,hbase 的数据文件,都存放在 HDFS 中
表的物理概念:
rowkey:行键,一个行键对应的所有数据就是一条记录,该记录中可以包含多个(qualifier-value)对
column family:列簇,多个qualifier可以被组织成一个列簇进行集中管理同时在物理上他们的存储也是分开的
qualifier:列
timestamp:用来表示列的值的版本,越大表示该数据越新
value:值
表的逻辑概念:
table 表
region 表中个一段rowkey范围中的数据, 都是按照rowkey进行数据排序的
store 如果这张表有多个列簇,那么就会生成多个 store
memstore 内存数据
storefile 磁盘文件 HFile
blockcache 读缓存
类比理解:
系统 |
数据管理抽象单元 |
数据分区 |
本质 |
HDFS |
文件 File |
文件数据块 Block |
分布式文件 |
HBase |
表 Table |
数据分区 Region |
分布式表 |
Spark |
分布式数据集合 RDD |
数据分区 Partition |
分布式集合 |
核心动作概念:
put 插入数据
get/scan 查询/扫描
flush memstore 的数据刷出来,形成磁盘文件
Split:当一个region变大的时候(一定的标准:10G),就会一分为二。分出来的两个region也都是有序
compact:当 storefile 达到一个个数的时候,就会触发 compact 操作:多个 HFile 合并成一个
Flush 动作是当 MemStore 达到阈值,将 Memstore 中的数据写到磁盘形成 StoreFile 也就是 HFile Compact 机制则是把 flush 出来的小文件合并成大的 StoreFile 文件
Split 则是当 Region 达到阈值,会把过大的 Region 一分为二
7. HBase Java API 设计详解
在使用和阅读了很多的分布式或者非分布式技术的 API 抽象,HBase的 API设计最能体现面向对象设计的思想。简单总结一下。
1、配置链接相关:
HBaseConfiguration
ConnectionFactory
Connection
2、管理相关:
Admin(DDL) Admin admin = connect.getAdmin()
HTable(DML) HTable table = connect.getTable()
3、表抽象相关
admin.createTable(HTableDescriptor)
HTableDescriptor(TableName, HColumnDescriptor[])
HColumnDescriptor
4、增删改查相关:
Put htable.put(Put)
Delete htable.delete(Delete)
Get htable.get(Get) = Result
Scan htable.getScanner(Scan) = ResultScanner
Put Delete Get Scan ===> Cell
table = map(rowkey, map(cf, map(qualifier, map(timestamp, value))))
table = map((rowkey, cf, qualifier, timestamp), value)
Cell = rowkey, cf, qualifier, timestamp, value
5、数据抽象相关:
ResultScanner
Result,表示一个 rowkey 锁对应的所有的 KeyValue 集合,Put,Delete,Get,Result 都是由一个 rowkey 对应的
Cell/KeyValue
6、其他:
Filter过滤器
Coprocessor协处理器
8. HBase的核心工作机制读写流程解析
8.1. HBase寻址机制
在使用 HBase 的时候,不管你做插入,还是查询,你都需要先确定你操作的数据是位于哪个 RegionServer 的 Region 中。这就是 HBase 的寻址。
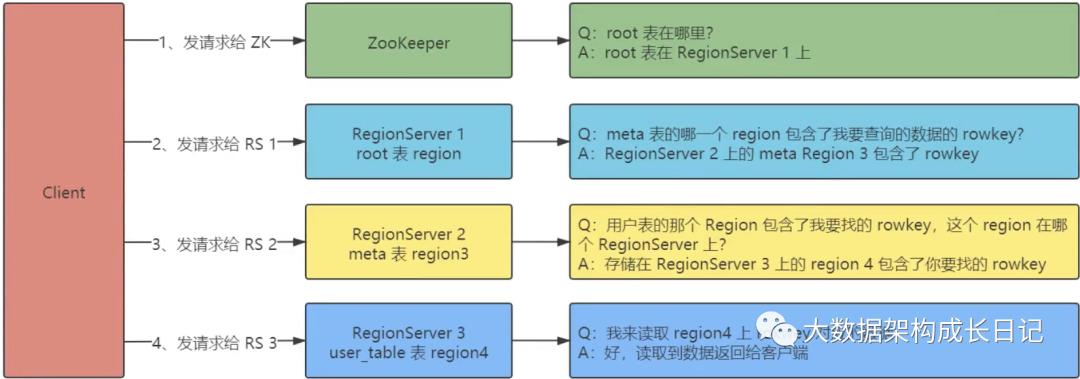
老版本(0.96x 以前)三层结构:
· 客户端先发送请求到 ZooKeeper 获取 root 这张表的位置
· 客户端扫描 root 表中的数据,获取 meta 表的位置
· 客户端扫描 meta 表的数据,获取用户表的位置
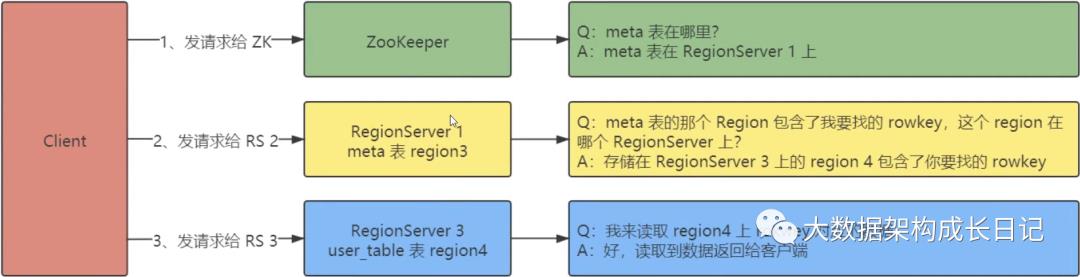
新版本(0.96x 以后)两层结构:
· 客户端先发送请求到 ZooKeeper 获取 meta 这张表的位置
· 客户端扫描 meta 表的数据,获取用户表的位置
再来一个更宏观的 Topo 图:
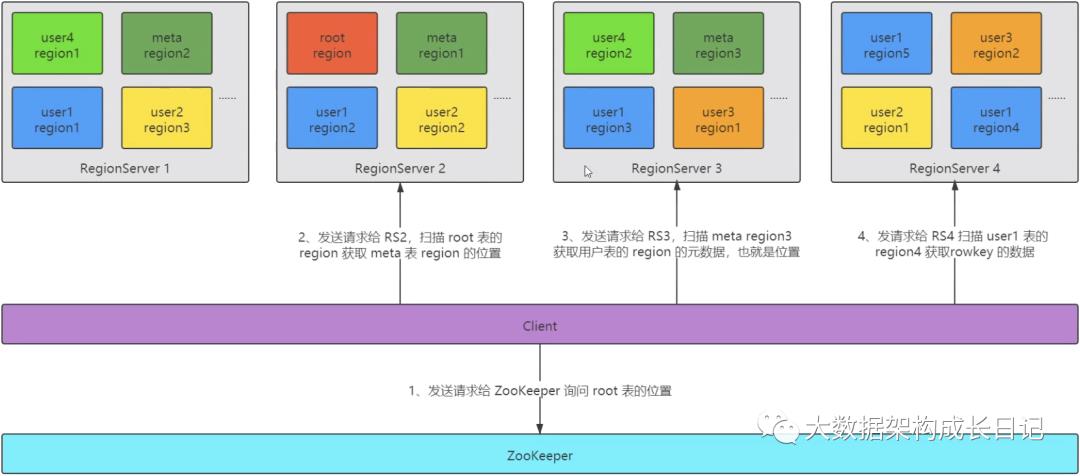
由此可见,新老版本最大的差别就是,新版本舍弃了 root 表,三层拓扑结构,变成了两层拓扑结构!
1、根据 BigTable 论文的描述,每一条元素大概 1kb 左右
2、假设一个 Region 大小为:128M
3、假设 root 表上涨到上限 128M,则 root 表中的元数据的条数:128M * 1024 = 2^17, 证明 meta 表有 2^17 个 region
4、那么 meta 表的总元数据条数:2^17 * 2^17 = 2^34 条
5、用户表的每个 Region 也是 128M,则用户表的数据理论上限:2^34 * 128M = 2^41M = 2^31G = 2^21T = 2^11P = 2^1E = 2EB
也就是说,如果每个 region 的最大大小是 128M,那么这样的三层结构,就可以存储 2EB 的总数据量!基本上数据体量到 EB 级别的是少之又少! 但是现在一个 Region 的理论上限是 10G,那么我们再算算三层结构能存储多少数据:
1、根据 BigTable 论文的描述,每一条元素大概 1kb 左右
2、假设一个 Region 大小为:10G = 10240M
3、假设root表上涨到上限10G,则root表中的元数据的条数:10240M*1024=10*2^20, 证明meta表有10 * 2^20 个region
4、那么 meta 表的总元数据条数:(10 * 2^20) * (10 * 2^20) = 100 * 2^40 条
5、用户表的每个 Region 也是 10G,则用户表的数据理论上限:100 * 2^40 * 10G = 1000 * 2^40G ≈ 2^40T = 2^30P = 2^20E = 1048576EB
那么不设置三层结构,设置两层结构,计算一下看看可以存储多少数据量?
1、根据 BigTable 论文的描述,每一条元素大概 1kb 左右
2、假设一个 Region 大小为:10G = 10240M
3、假设 meta 表上涨到上限 10G,则 meta 表中的元数据的条数:10240M * 1024 = 10 * 2^20, 证明所有用户表总共有 10 * 2^20 个 region
4、每个用户表的 Region 为 10G,总数据量为:10 * 2^20 * 10G = 104857600G = 100EB
所以,当 meta 表的数据量达到 10G 的时候,表明,整个集群理论上存储的数据量上限是 100EB,但是 meta 表其实可以超过 10G 的!
8.2. HBase 写数据流程
8.3. HBase 读数据流程
以上是关于HBase的主要内容,如果未能解决你的问题,请参考以下文章