Hbasehbase和phoenix的整合
Posted 星欲冷hx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbasehbase和phoenix的整合相关的知识,希望对你有一定的参考价值。
phoenix是Apache 出的一个全文检索,能够更清晰的帮助hbase存储数据
长篇幅预警!!!这一篇东西有点多,大家可以收藏学习!
目录
将配置好的hbase-site.xml文件复制到phoenix客户端也就是hadoop01的phoenix的bin目录下
apache phoenix简介
简介

Apache Phoenix让hadoop支持oltp和业务操作分析
olap和oltp
- olap:在线分析处理系统,hadoop、hbase
- oltp:在线事务处理系统,传统的关系数据库支持的
sql:结构化查询语言
acid:原子性、一致性、独立性和持久性
Phoenix的作用
- 提供标准的sql和acid事务支持
- 让NoSQL数据库具备了有模式的方式读取数据,可以使用sql来创建表、插入、修改和删除数据
- Phoenix通过协处理器在服务器端执行操作,无侵入式
- 可以很好的与其他hadoop生态组件整合,例如spark、hive、flume、flink以及MR
apache phoenix安装
下载
同样自取
https://pan.baidu.com/s/1JcvAQhQZqgQDD9-GHPZGog?pwd=1234 提取码:1234




上传到服务器

解压


修改hbase的配置文件
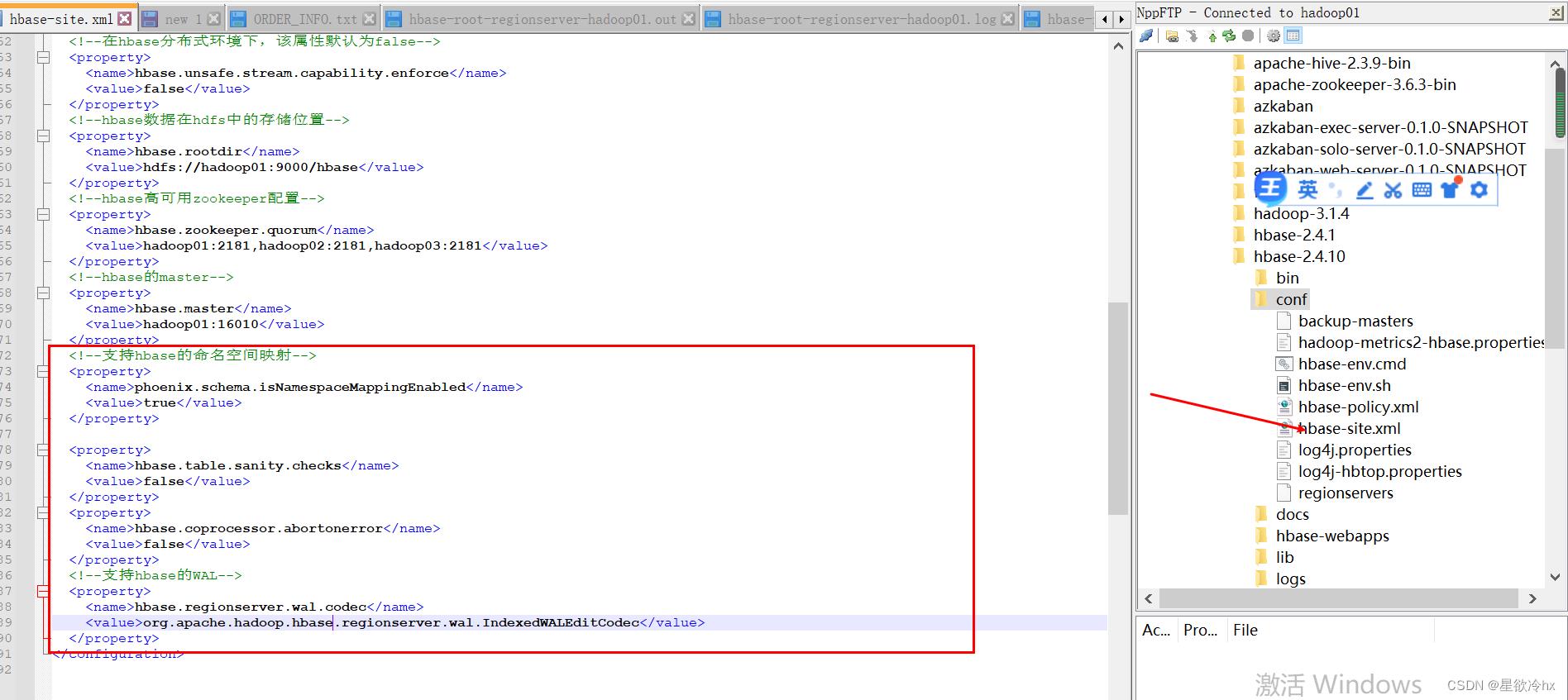
复制依赖包

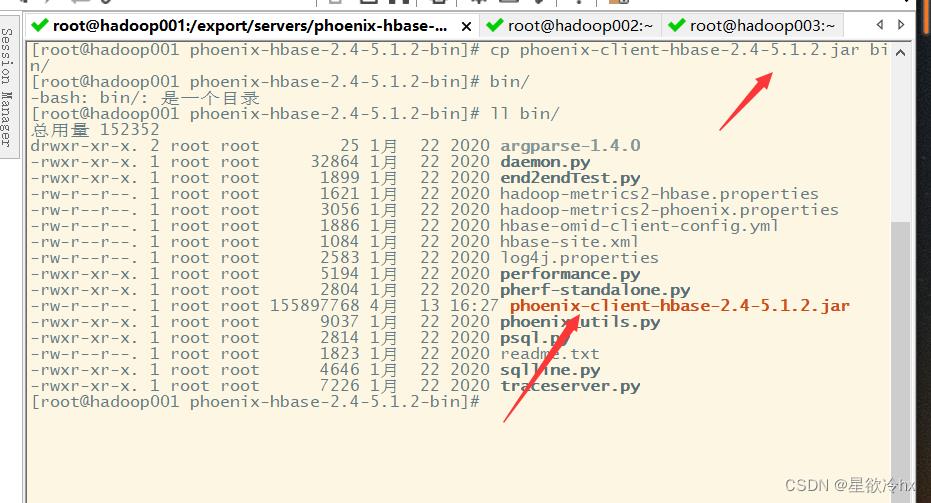
复制phoenix的服务端jar包到master和worker的hbase的lib文件夹


复制phoenix的客户端jar包到phoenix客户端也就是hadoop01的phoenix的bin文件夹下
分发hbase配置文件

将配置好的hbase-site.xml文件复制到phoenix客户端也就是hadoop01的phoenix的bin目录下

重启hbase

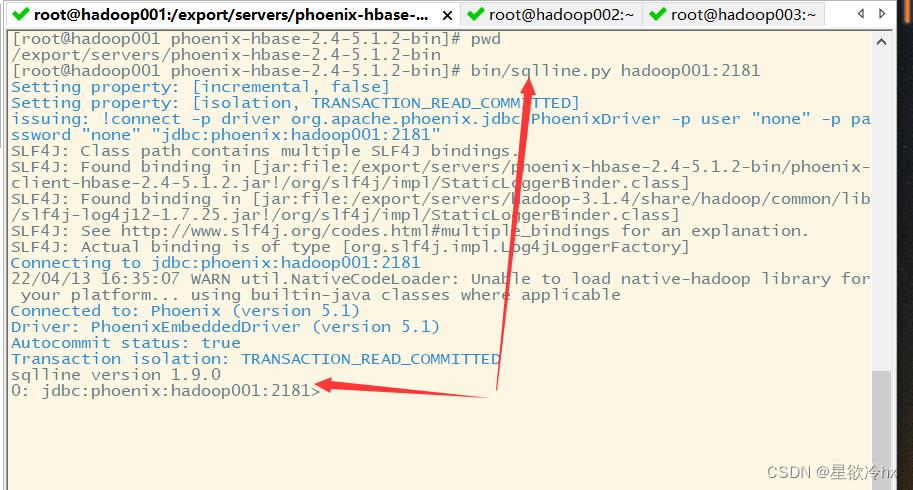
启动phoenix客户端
cd /export/servers/phoenix-hbase-2.4-5.1.2-bin
bin/sqlline.py hadoop001:2181

查看hbase的web ui

到这里phoenix的安装部署就结束了,接下来是使用知识介绍
phoenix的使用
需求
使用之前的订单数据,但是用phoenix来创建表,并进行数据的增删改查操作。
https://pan.baidu.com/s/1gjZWaOp5C5srC1_UeYXX0g?pwd=1234 提取码:1234

| 列名 | 说明 |
| ID | 订单id |
| STATUS | 状态 |
| PAY_MONEY | 支付金额 |
| PAY_WAY | 支付方式 |
| USER_ID | 用户id |
| OPERATION_DATE | 操作时间 |
| CATEGORY | 商品类别 |
创建表
语法:
create table if not exists 表名(
rowkey名称 类型 primary key,
列簇.列名 类型,
……
) ;
先用vscode之类的编辑工具,写好创建表的语句
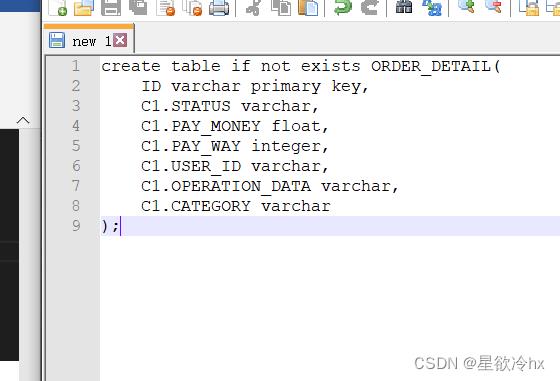
再复制到phoenix客户端执行
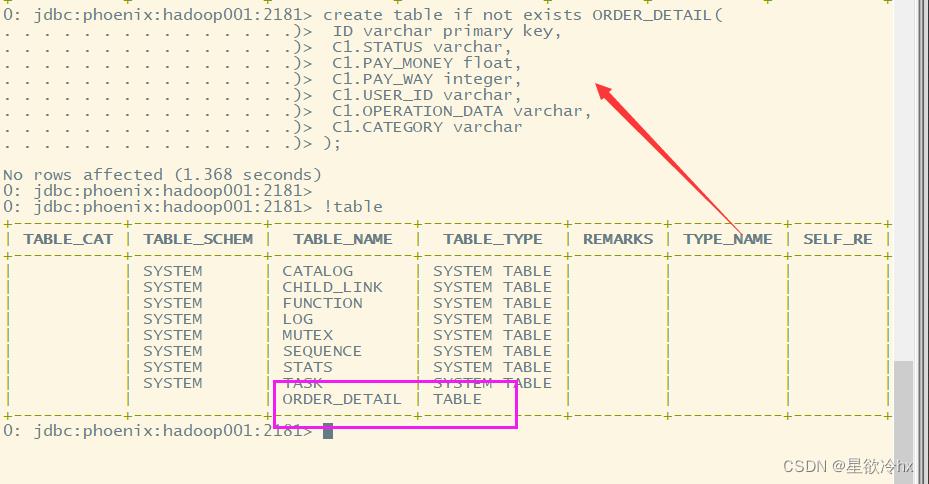
在hbase的web ui查看刚创建的表
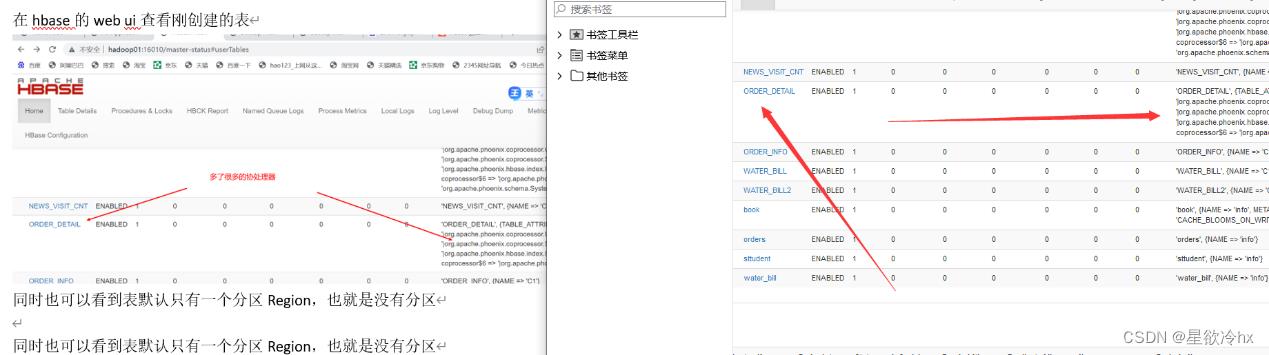
同时也可以看到表默认只有一个分区Region,也就是没有分区
查看表的详情
语法:
!desc ORDER_DETAIL

注意:一定要加上!
删除表
语法:
drop table if exists 表名;

大小写的问题
如果在使用列簇、列名的时候没有添加双引号,Phoenix会自动转换为大写。
如果要将列名改为小写,则要用双引号括起来
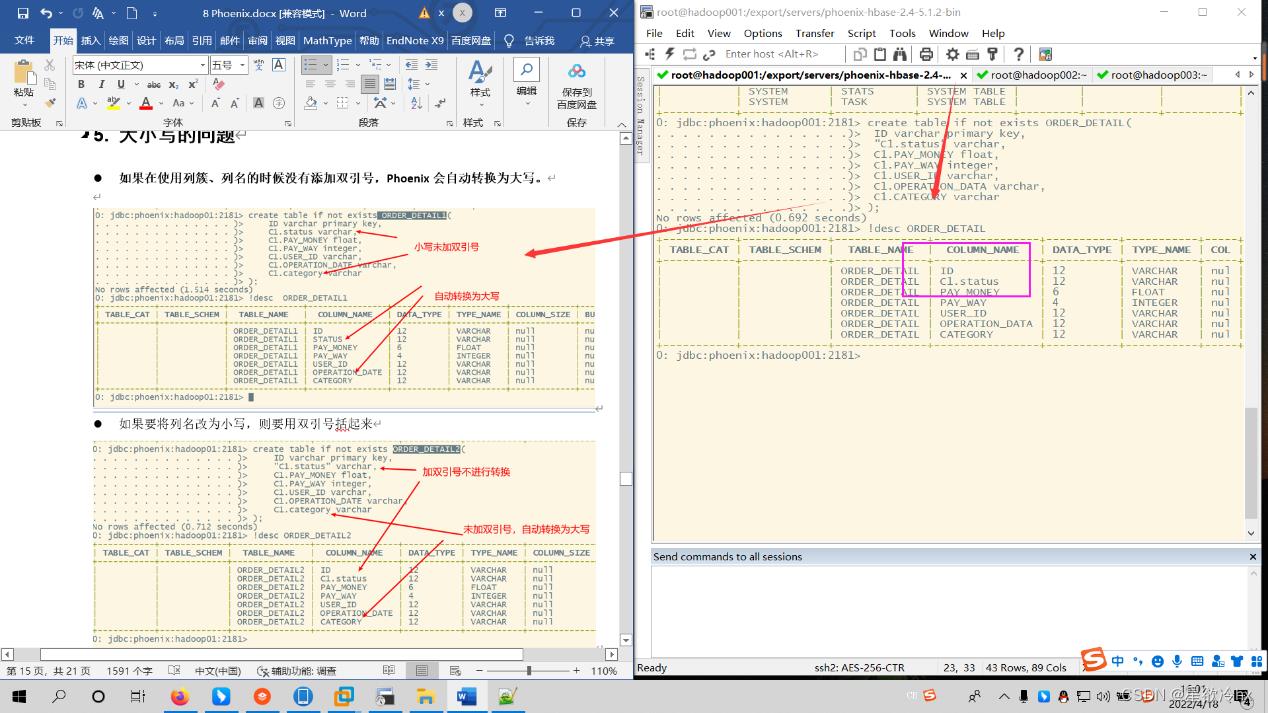
注意:如果一旦加了小写,后面任何使用该列的地方都得使用双引号,否则会报错
插入数据
在Phoenix中,插入数据并不是insert,而是upsert,相当于insert + update
,与hbase shell中的put想对应。如果不存在则插入,否则更新。
语法:
upsert into ORDER_DETAIL1(列簇名.列名,……) values (值1,值2,……);
upsert into ORDER_DETAIL1 values ('000001','已提交',3050,1,'494419','2020-04-25 12:09:30','手机');

查询数据
与标准的sql一样,Phoenix也是用select实现数据的查询

更新数据
在Phoenix中,更新数据也使用upsert。
语法:
upsert into 表名(列名,列簇名.列名,……) values(值1,值2,……);
upsert into ORDER_DETAIL1(ID,C1.STATUS) values('000001','已付款');
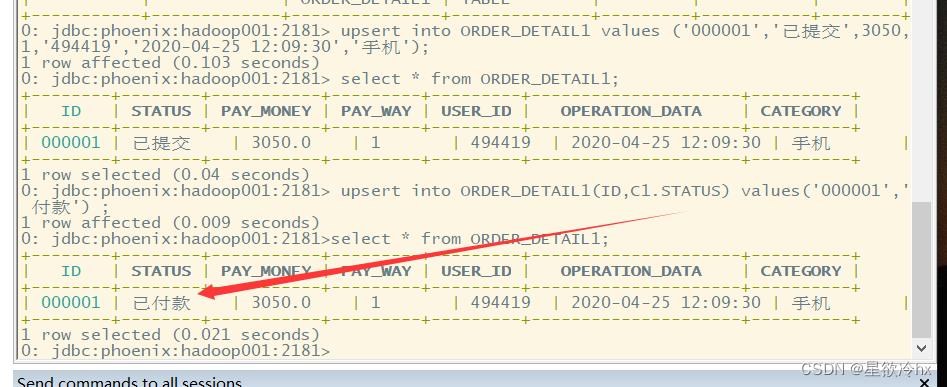
如果在创建表的时候,给列名一旦加了小写,后面任何使用该列的地方都得使用双引号,否则会报错
后来发现和老师创建的表名不一样,再改回来

正确的使用

删除数据
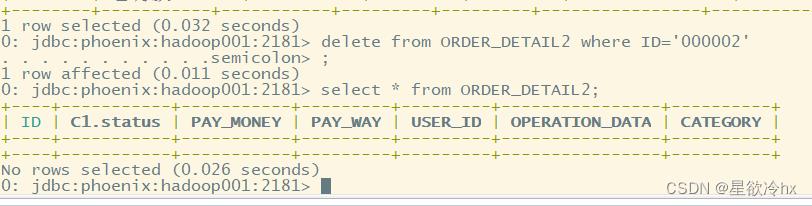
在phoenix中,删除数据与标准的sql一样,也是用delete from实现数据的删除
语法:
delete from 表名 where rowkey列名=值;
HBase的命名空间
简介
类似与mysql和hive中的数据库,对数据进行分类存放。按照业务域来划分类别,这些不同的业务域就叫做命名空间(namespace)。
- hbase有一个默认的命名空间是default,默认情况下,创建的表都在default命名空间下
- hbase中还有一个命名空间hbase,用于存放系统的内建表(namespace,meta)

创建命名空间
语法:
create_namespace 命名空间名
查看下图
查看命名空间列表
语法:
list_namespace

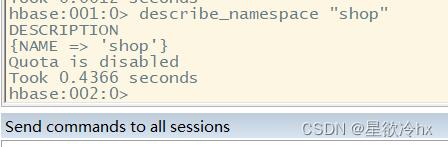
查看命名空间
describe_namespace 命名空间名
删除命名空间
语法:
drop_namespace 命名空间名
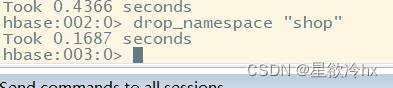

注意:
删除命名空间时,在该命名空间下必须没有表,否则无法删除
在指定命名空间下创建表
语法:
create "命名空间名:表名","列簇名"
create "shop:goods","C1"
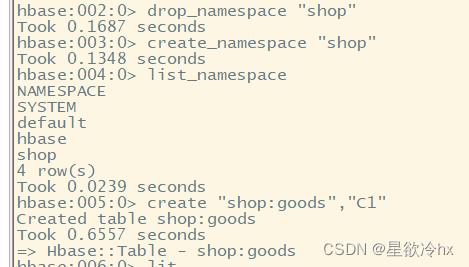

注意:
使用带有命名空间的表,使用冒号将命名空间和表名连接在一起
添加数据到命名空间表
语法:
put "命名空间名:表名","rowkey","列簇:列名",值
put "shop:goods","000001","C1:price",5800

列簇设计
HBase列簇的数量应该是越少越好
- 两个及以上的列簇,hbase的性能反而并不是很好
- 一个列簇存储的数据达到flush的阈值时,表中所有的列簇将同时进行flush操作
- 这将带来不必要的I/O开销,列簇越多,对性能的影响越大
一般情况下,只设计一个列簇
版本设计
版本数一一般设计为1
一般情况下,如果对数据不做修改,只保留一个版本,可以节省大量的存储空间

数据压缩
压缩算法
hbase默认创建的表是不进行数据压缩的,进行数据压缩可以节省大量的存储空间,hbase可以使用多种数据压缩编码,包括LZO、SNAPPY、GZIP。
| 压缩算法 | 压缩后占比 | 压缩 | 解压缩 |
| GZIP | 13.4% | 21MB/s | 118MB/s |
| LZO | 20.5% | 135MB/s | 410MB/s |
| Zippy/Snappy | 22.2% | 172MB/s | 409MB/S |
根据实际情况,选择合适的压缩算法
查看表的压缩方式
hbase创建的表默认是没有数据压缩的
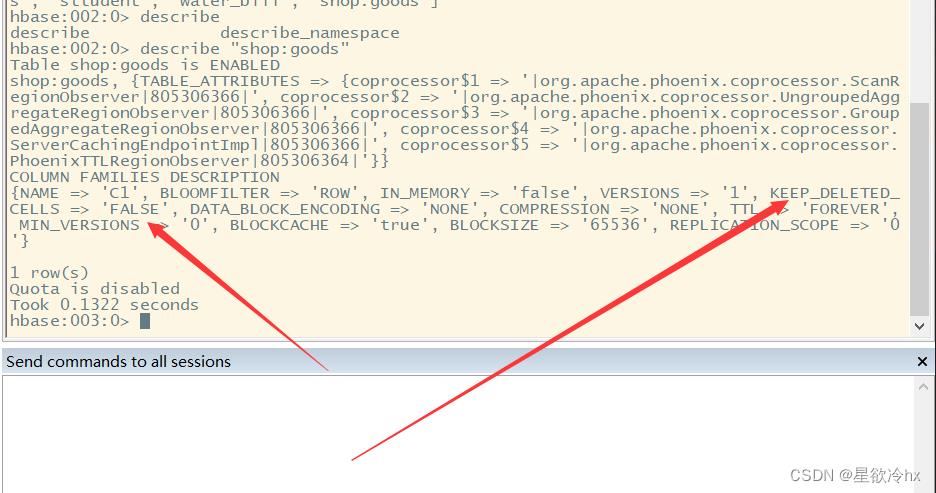
设置数据压缩
创建新表的时候
语法:
create "命名空间名:表名",NAME => '列簇名', COMPRESSION => '压缩算法名'
示例:
create "shop:orders",NAME => 'C1', COMPRESSION => 'GZ'

修改已有的表
语法:
alter "命名空间名:表名",NAME => '列簇名', COMPRESSION => '压缩算法名'
示例
alter "shop:goods",NAME => 'C1', COMPRESSION => 'GZ'

ROWKEY设计原则
避免使用递增行键/时序的数据
如果rowkey设计的都是按照顺序递增(例如:时间戳),这样当有很多的数据写入时,负载都在一台机器上。应该尽量将写入的数据均衡到各个RegionServer上。
避免rowkey和列的长度过大
在hbase中,要访问一个值,需要rowkey、列簇和列名,如果这些太长,就会占用较大的内存。
rowkey的最大长度是64kb,建议越短越好
使用long等类型比String类型更节省空间
long类型为8个字节,可以保存非常大的无符号数据,例如:174489340923423422424。如果使用字符串保存的话,是按照一个字符一个字节的方式,需要3倍多的存储空间。
rowkey唯一性
设计rowkey时,必须保证它的唯一性。如果不唯一,因为hbase采用key-value的存储方式,若向hbase的一张表中插入相同rowkey的数据,则原来的数据会被新的数据覆盖
避免数据热点
热点
是指大量的客户端直接访问(可能是读,也可能是写)集群的一个或者几个节点,可能会使得某个节点超出承受能力,出现宕机或者不可用的情况,导致整个集群性能的下降。
预分区
默认情况下,一个hbase表只有一个分区(region),被托管在一个RegionServer中
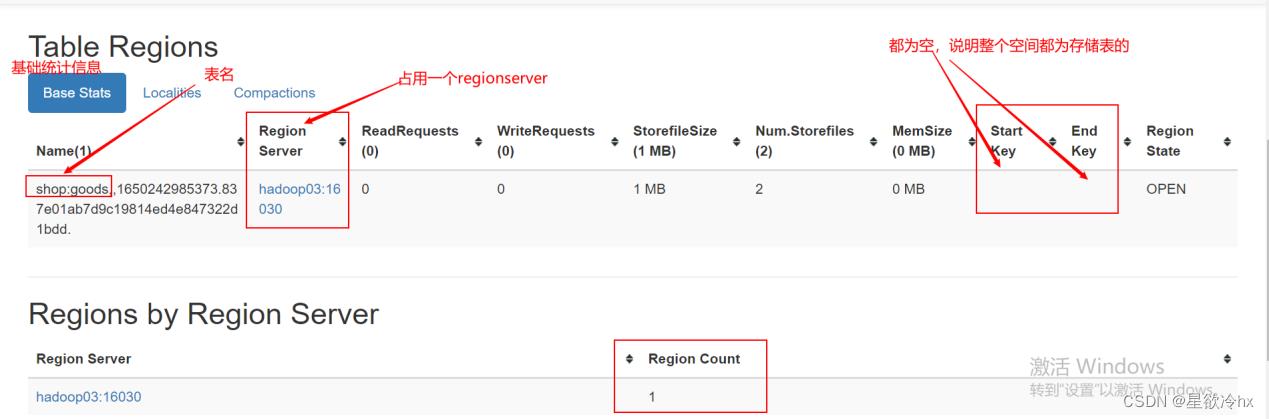
start key和end key
每个region有两个重要的属性:start key和end key,标识这个region维护的rowkey的范围。如果只有一个region,这它们都为空,没有边界。所有的数据都会存放在这个region中。但数据很大的时候,会将region通过去一个mid key来分成两个region。
预分区的个数
预分区的个数=节点的倍数,如果有三个节点,则预分区的个数为6。
默认region的大小为10G,假如进行预估接下来的一年时间数据的大小为10T,则需要的预分区数=10*1000G/10G=1000个region。
rowkey避免数据热点设计
反转策略
将rowkey翻转,或者直接将尾部的字符串提前到rowkey的开头
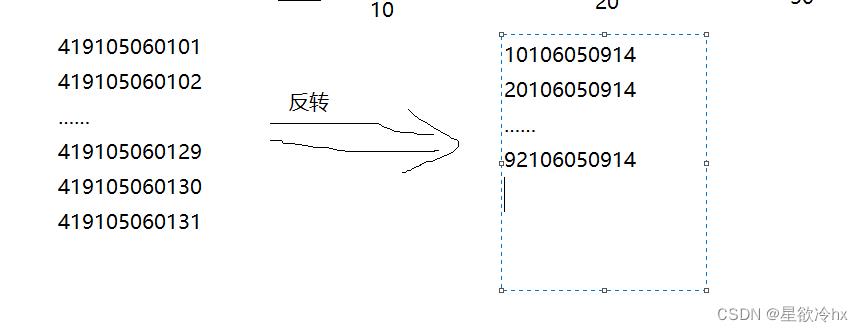
优点:实现简单
缺点:可以使得rowkey呈现一定的随机性,但是牺牲了rowkey的有序性,利于get操作,不利于scan操作。
加盐(salt)策略
在原来的rowkey的前面加上固定长度的随机数,这个随机数就叫做盐,这样使得rowkey具有随机性
优点:rowkey的随机性能保障数据在所有的regionserver之间的负载均衡
缺点:因为添加的是随机数,基于原来的rowkey查询时无法知道随机数是什么,会影响查询速度,不适合数据的读取
哈希(hash)策略
是对整个rowkey或其部分进行hash操作,然后将hash后的字符串替换真格rowkey或者rowkey的前缀部分,hash算法一般有MD5、sha1、sha256或者sha512D等
优点:同加油策略
缺点:也是不利于scan操作,因为打乱了rowkey原有的自然顺序
设置预分区
指定start key和end key来分区
首先得有这个命名空间才行
create_namespace "test"
创建预分区
语法:
create "test:t1",'C1',SPLITS=>['10','20','30','40']

hbase的web ui查看分区的占用情况
点击t1表,查看详情
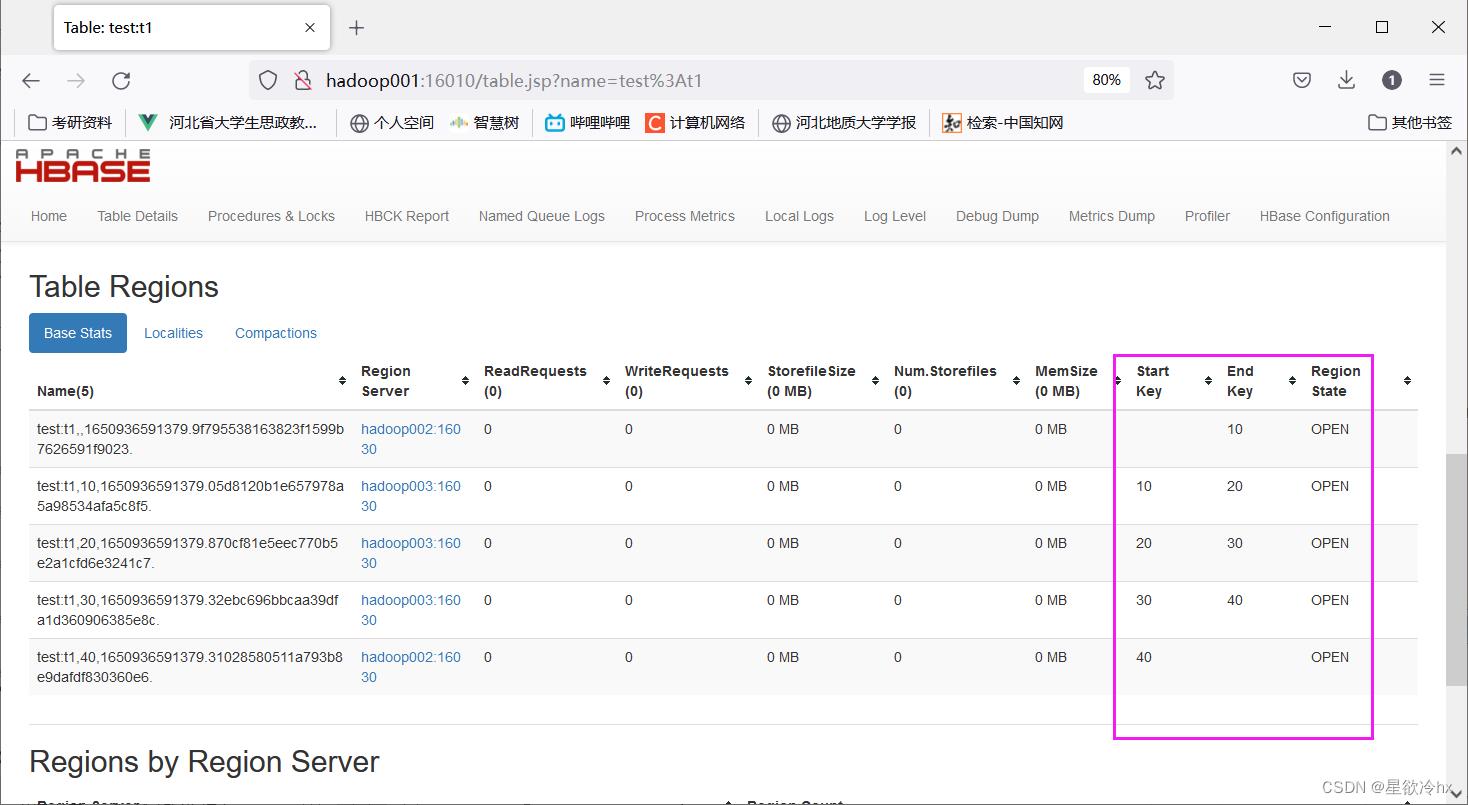
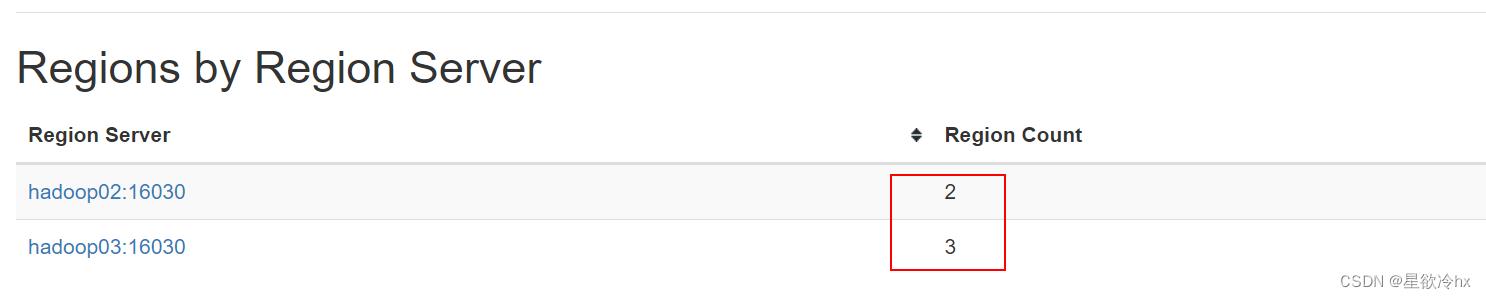

指定分区的数量、分区策略
创建预分区
create "test:t2","C1",NUMREGIONS=>6,SPLITALGO=>'HexStringSplit'

hbase的web ui查看分区的占用情况
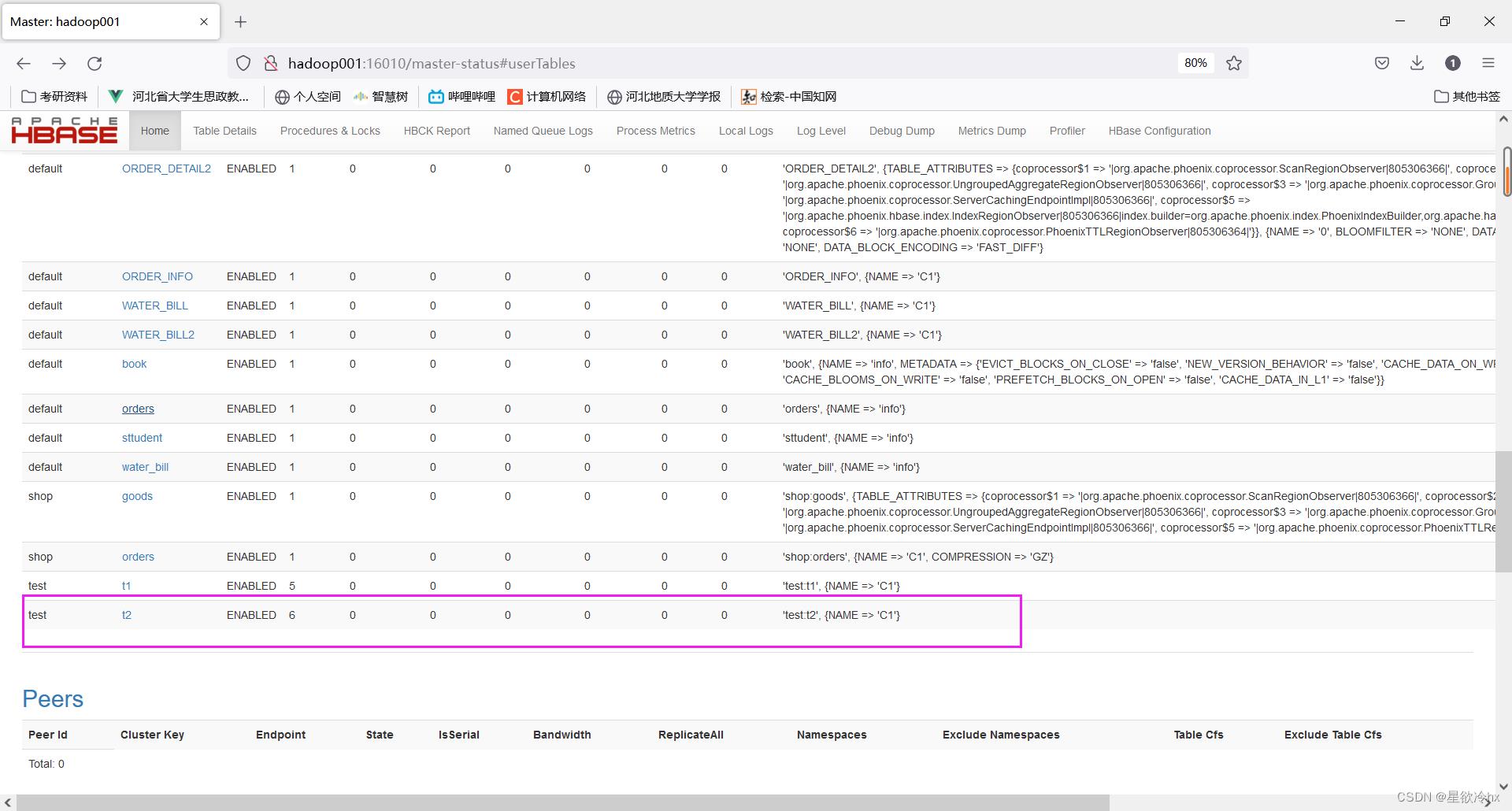
点击t2查看详情

分区数量
一般按照数据量来预估或者根据节点数的倍数来设定
分区策略
- HexStringSplit:rowkey是采用十六进制字符串作为前缀
- DecimalStringSplit:rowkey采用十进制数字字符串作为前缀
- UniformStringSplit:rowkey的前缀是随机的
Phoenix的视图
Phoenix的视图就是对已经创建的HBase表建立映射关系,从而实现对已有表的快速查询
创建视图
语法:
create view if not exists "shop"."goods" (
"id" varchar primary key,
"C1"."name" varchar,
"C1"."price" varchar
);

查询数据

版本数一般设计为1
一般情况下,如果对数据不做修改,只保留一个版本,可以节省大量的存储空间

二级索引
一般情况下,Hbase会根据rowkey建立索引,来提供查询的速度,这样的索引叫做一级索引。如果根据name进行查询,因为没有根据name建立索引,所以查询效率比较低,这是可以给name来创建二级索引。
索引分类
- 全局索引
- 本地索引
- 覆盖索引
- 函数索引
全局索引
全局索引适用于读多写少的业务
全局索引主要的负载发生在写入操作时,比如upsert、delete,Phoenix会拦截数据表的更新,构建索引更新,开销比较大
读取时,Phoenix会选择最快的能够查询出数据的索引。
全局索引一般要跟覆盖索引搭配使用
cd /export/servers/phoenix-hbase-2.4-5.1.2-bin
bin/sqlline.py hadoop001:2181
语法:
create index 索引名称 on 表名(列名1,列名2……);
举例:
create index idxname on ORDER_DETAIL1(CATEGORY);

注意:
Phoenix中的索引,其实底层还是Hbase的表结构,这些索引表是专门用来加快查询速度。

本地索引
本地索引适合写操作频繁的场景
在本地索引中,索引数据和业务表数据存储在同一个服务器上,加快写入的速度
本地索引的数据是保存在一个影子列簇中
创建语法:
create local index 索引名称 on 表名(列名1,列名2……);
覆盖索引
可以不需要在找到索引条目后返回到主表中,可以将关心的数据捆绑在索引行中,从而节省了读取的时间开销。
创建语法:
create index 索引名称 on 表名(列名1,列名2……) include(列名3);
create index idxcombo on ORDER_DETAIL1(CATEGORY,STATUS,PAY_MONEY) include(USER_ID);


函数索引
适用于高版本的phoenix,可以基于任意表达式(函数)创建索引
语法
create index 索引名称 on 表名(函数名(列名1),列名2……);
创建索引
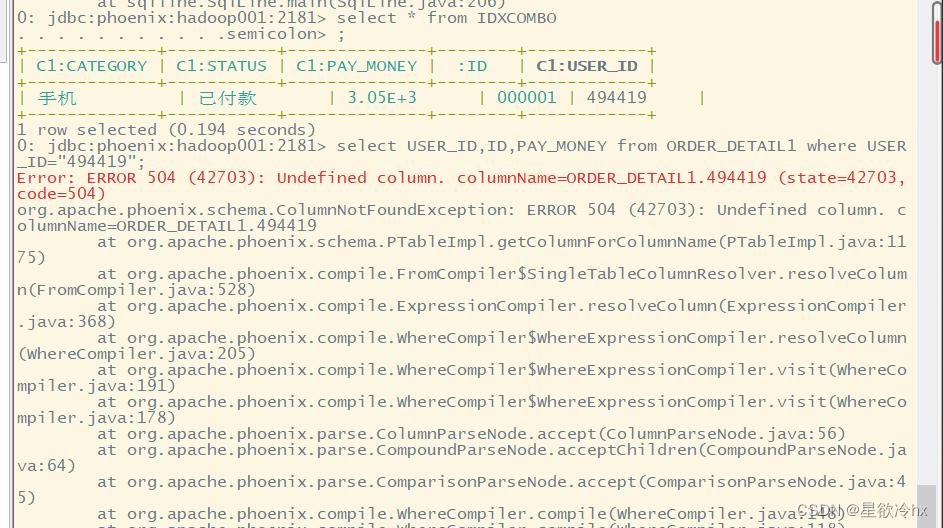
create index idxsuerid on ORDER_DETAIL1(C1.USER_ID) include(ID,C1.PAY_MONEY);

根据索引查询数据
select USER_ID,ID,PAY_MONEY from ORDER_DETAIL1 where USER_ID="494419";
删除索引
drop index 索引名 on 表名
drop index IDXCOMBO on ORDER_DETAIL1;

查看索引


hbase的所有基础知识和hbase分栏到这里就结束了,还有一个实习项目现在还不介绍
下篇文章应该是关于flink的了
希望大家一起学习,一起进步
如遇侵权,请联系删除。
以上是关于Hbasehbase和phoenix的整合的主要内容,如果未能解决你的问题,请参考以下文章