采集google搜索引擎的10个经典方法
Posted 近探数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了采集google搜索引擎的10个经典方法相关的知识,希望对你有一定的参考价值。
采集google搜索引擎的10个经典方法
google搜索引擎提供网站搜索、新闻搜索、网页数据抓取、全网搜索、网页爬虫、采集网站数据、网页数据采集软件、python爬虫、HTM网页提取、APP数据抓包、APP数据采集、一站式网站采集技术、BI数据的数据分析、数据标注等成为大数据发展中的热门技术关键词。那么采集google搜索引擎的方法有哪些呢?我给大家分享一下,我爬虫的个人经验,我们在采集类似google网站数据的时候会遇到什么技术问题,然后再根据这些问题给大家分享采集方案。
一、写爬虫采集网站之前:
(3)钓鱼网站爬虫技术:通过域名劫持技术,很多人heike去劫持银行网站、支付宝网站、充值交易的网站等,比如他们先做一个和银行一模一样的网站,功能和长相和银行的一模一样,这个网站我们称呼钓鱼网站,用户打开银行网址时候,其实已经被劫持走了,真正访问的是他们提供的钓鱼网站,但是因为网址是一样的,网站长相也是一样的,用户压根不会识别出来,等您输入银行账号密码后,您的银行卡的钱估计就自动被转走了,因为已经知道您的账号密码了。对技术感兴趣朋友欢迎交流我扣扣:2779571288
二、网站数据采集的10个经典方法:
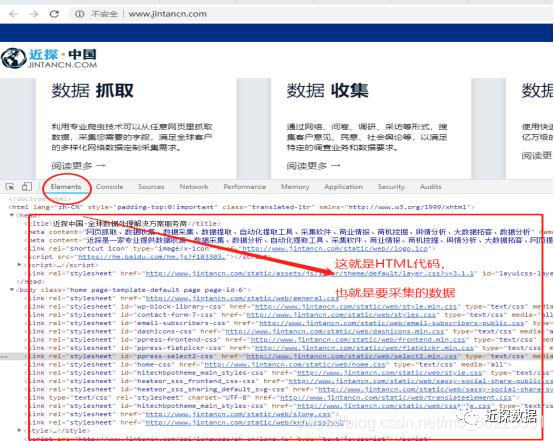
我们平时说的采集网站数据、数据抓取等,其实不是真正的采集数据,在我们的职业里这个最多算是正则表达式,网页源代码解析而已,谈不上爬虫采集技术难度,因为这种抓取主要是采集浏览器打开可以看到的数据,这个数据叫做html页面数据,比如您打开:www.jintancn.com这个网址,然后键盘按F12 ,可以直接看到这个网址的所有数据和源代码,这个网站主要是提供一些爬虫技术服务和定制,里面有些免费新工商数据,如果需要采集它数据,你可以写个正则匹配规则html标签,进行截取我们需要的字段信息即可。下面给大家总结一下采集类似这种工商、天眼、商标、专利、亚马逊、淘宝、app等普遍网站常用的几个方法,掌握这些访问几乎解决了90%的数据采集问题了。
方法一:用python的request方法
用python的request方法,直接原生态代码,python感觉是为了爬虫和大数据而生的,我平时做的网络分布式爬虫、图像识别、AI模型都是用python,因为python有很多现存的库直接可以调用,比如您需要做个简单爬虫,比如我想采集百度 几行代码就可以搞定了,核心代码如下:
import requests #引用reques库
response=request.get(‘https://www.tianyancha.com/’)#用get模拟请求
print(response.text) #已经采集出来了,也许您会觉好神奇!
方法二、用selenium模拟浏览器
selenium是一个专门采集反爬很厉害的网站经常使用的工具,它主要是可以模拟浏览器去打开访问您需要采集的目标网站了,比如您需要采集天眼查或者企查查或者是淘宝、58、京东等各种商业的网站,那么这种网站服务端做了反爬技术了,如果您还是用python的request.get方法就容易被识别,被封IP。这个时候如果您对数据采集速度要求不太高,比如您一天只是采集几万条数据而已,那么这个工具是非常适合的。我当时在处理商标网时候也是用selenum,后面改用JS逆向了,如果您需要采集几百万几千万怎么办呢?下面的方法就可以用上了。
方法三、用scrapy进行分布式高速采集
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。scrapy 特点是异步高效分布式爬虫架构,可以开多进程 多线程池进行批量分布式采集。比如您想采集1000万的数据,您就可以多设置几个结点和线程。Scrapy也有缺点的,它基于 twisted 框架,运行中的 exception 是不会干掉 reactor(反应器),并且异步框架出错后 是不会停掉其他任务的,数据出错后难以察觉。我2019年在做企业知识图谱建立的时候就是用这个框架,因为要完成1.8亿的全量工商企业数据采集和建立关系,维度比天眼还要多,主要是时候更新要求比天眼快。对技术感兴趣朋友欢迎交流我扣扣:2779571288
方法四:用Crawley
Crawley也是python开发出的爬虫框架,该框架致力于改变人们从互联网中提取数据的方式。它是基于Eventlet构建的高速网络爬虫框架、可以将爬取的数据导入为Json、XML格式。支持非关系数据库、支持使用Cookie登录或访问那些只有登录才可以访问的网页。
方法五:用PySpider
相对于Scrapy框架而言,PySpider框架是一支新秀。它采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器、任务监视器、项目管理器以及结果查看器。PySpider的特点是ython脚本控制,可以用任何你喜欢的html解析包,Web界面编写调试脚本、起停脚本、监控执行状态、查看活动历史,并且支持RabbitMQ、Beanstalk、Redis和Kombu作为消息队列。用它做个两个外贸网站采集的项目,感觉还不错。
方法六:用Aiohttp
Aiohttp 是纯粹的异步框架,同时支持 HTTP 客户端和 HTTP 服务端,可以快速实现异步爬虫。坑比其他框架少。并且 aiohttp 解决了requests 的一个痛点,aiohttp 可以轻松实现自动转码,对于中文编码就很方便了。这个做异步爬虫很不错,我当时对几个淘宝网站异步检测商城里面的商品和价格变化后处理时用过一段时间。
方法七:asks
Python 自带一个异步的标准库 asyncio,但是这个库很多人觉得不好用,甚至是 Flask 库的作者公开抱怨自己花了好长时间才理解这玩意,于是就有好事者撇开它造了两个库叫做 curio 和 trio,而这里的 ask 则是封装了 curio 和 trio 的一个 http 请求库。
方法八:vibora
号称是现在最快的异步请求框架,跑分是最快的。写爬虫、写服务器响应都可以用,用过1个月后 就很少用了。
方法九:Pyppeteer
Pyppeteer 是异步无头浏览器(Headless Chrome),从跑分来看比 Selenium + webdriver 快,使用方式是最接近于浏览器的自身的设计接口的。它本身是来自 Google 维护的 puppeteer。我经常使用它来提高selenium采集的一些反爬比较厉害的网站 比如裁判文书网,这种网站反爬识别很厉害。
方法十:Fiddle++node JS逆向+request (采集APP必用)
前面主要是对网站和APP 数据采集和解析的一些方法,其实对这种网站爬虫技术说无非就解决三个问题:首先是封IP问题,您可以自建代理IP池解决这个问题的,第二个问题就是验证码问题,这个问题可以通过python的图像识别技术来解决或者是您直接调取第三方的打码平台解决。第三问题就是需要会员账号登录后才看到的数据,这个很简单直接用cookie池解决。对技术感兴趣朋友欢迎交流我扣扣:2779571288。
——联系方式——

官方网站
http://www.jintancn.com/

24h在线 :17751719173
0512-36606771

意见反馈
jintancn@163.com

中国上海市嘉定区安亭地铁站附近500米

客服微信:
以上是关于采集google搜索引擎的10个经典方法的主要内容,如果未能解决你的问题,请参考以下文章