有了AI,你可以在几秒内数到1000+葵花籽
Posted 程序员石磊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了有了AI,你可以在几秒内数到1000+葵花籽相关的知识,希望对你有一定的参考价值。
本文翻自国外一篇博客,作者在Kernel 从事机器视觉。Kernel -世界领先和乌克兰最大的生产商葵花籽油的出口商。文章介绍了如果用ai来识别一个向日葵有多少瓜子并落地的思路。
今天来介绍下如何使用ai来计算用手机拍摄的照片中的葵花籽。
步骤:
1.业务需求
2.数据准备
3.模型结构
4.libs和工具
5.结果
6.误差分析
7.失败/假设
8.结论
9.参考文献
1.业务需求
对农学家来说,计算向日葵和玉米的种子是一项常见的任务,因为这些计算将被用来预测“生物收获”。另外,农学家计算1000粒的重量,这将进一步用来估计每个土地面积的总产量。
此外,产量预测是农业分析的主要功能。他们预测得越快、越准确,公司赚的钱就越多。
这些检查应该在每个领域进行推广。这是它现在的工作模式:
- 农学家到田间去
- 从地里不同的地方采10朵向日葵
- 把每棵向日葵分成四份
- 数种子,再乘以4,得到每棵向日葵上种子的总数
- 随机取1000粒种子称重
- 我们从其他的检查中获得每公顷土地上的植物密度(或使用计划的密度)
- 并计算(每公顷密度_向日葵平均种子数量_ 1000粒重量)/ 1000 =每公顷产量重量
这是一张常见的向日葵照片

可以看到白色(未成形)和黑色(成形)的种子,但只有黑色的种子将用于生产葵花籽油。
这种计算的一个缺点是,农学家必须计算向日葵上黑色的种子,这是非常不准确和不方便的。此外,每个农学家可能会在同一株向日葵上计算不同数量的种子,因为有些种子可能还没有形成(白色的,没有蜜蜂授粉),而且很难确定哪个种子形成了,哪个没有。
2.准备数据
为了解决任何机器学习问题,我们需要获取数据并训练模型。而且对于每个特定的任务,你无法找到任何可用的免费标记数据集。在我们的例子中,数据集应该包含数百张向日葵照片,每个种子都有对应的标签(黑色或白色,便于理解),所以我们收集了自己的数据集。
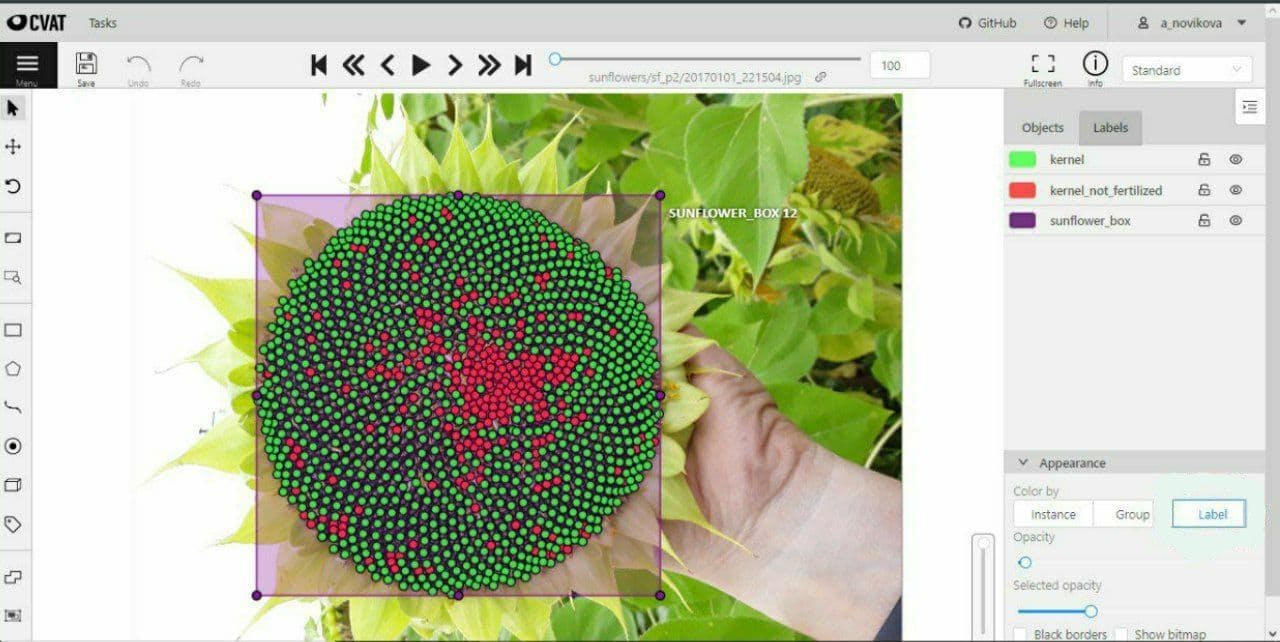
我们的农学家已经制作了大约1000张来自乌克兰不同地区的不同向日葵杂交品种的照片。随后,另一个团队在CVAT免费的数据标签工具中对照片进行标签。每个图像都应该有bounding_box(紫色框),以及黑色的种子(下图中的绿色点)和白色的种子(下图中的红色点)。
接下来,我们可以查看向日葵籽粒的分布情况
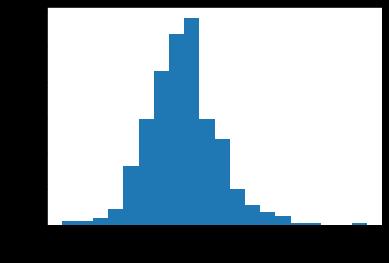
看起来很正常,平均值是1271。
同时也显示了黑白种子数量的相关性。
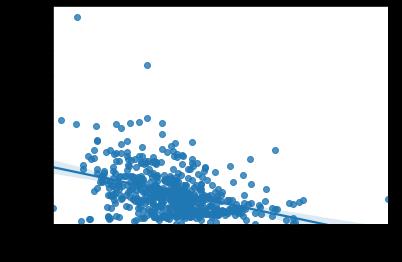
弱依赖性存在,但不能进一步利用。
3.模型结构
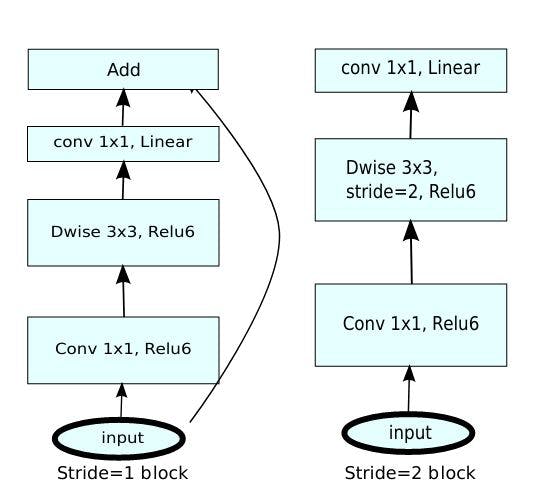
出于业务需要,所有的计算都应该在移动设备上完成。这就是为什么我使用U-net[1]与mobilenet_v2[2]编码器预先训练在imagenet。这一切意味着什么?
U-net是一种神经网络结构,其中神经网络获取一个输入图像并返回一个分割图(在我们的情况下热图),具有下采样和上采样数据。
我们的热图表示像素与某个核相关的概率。
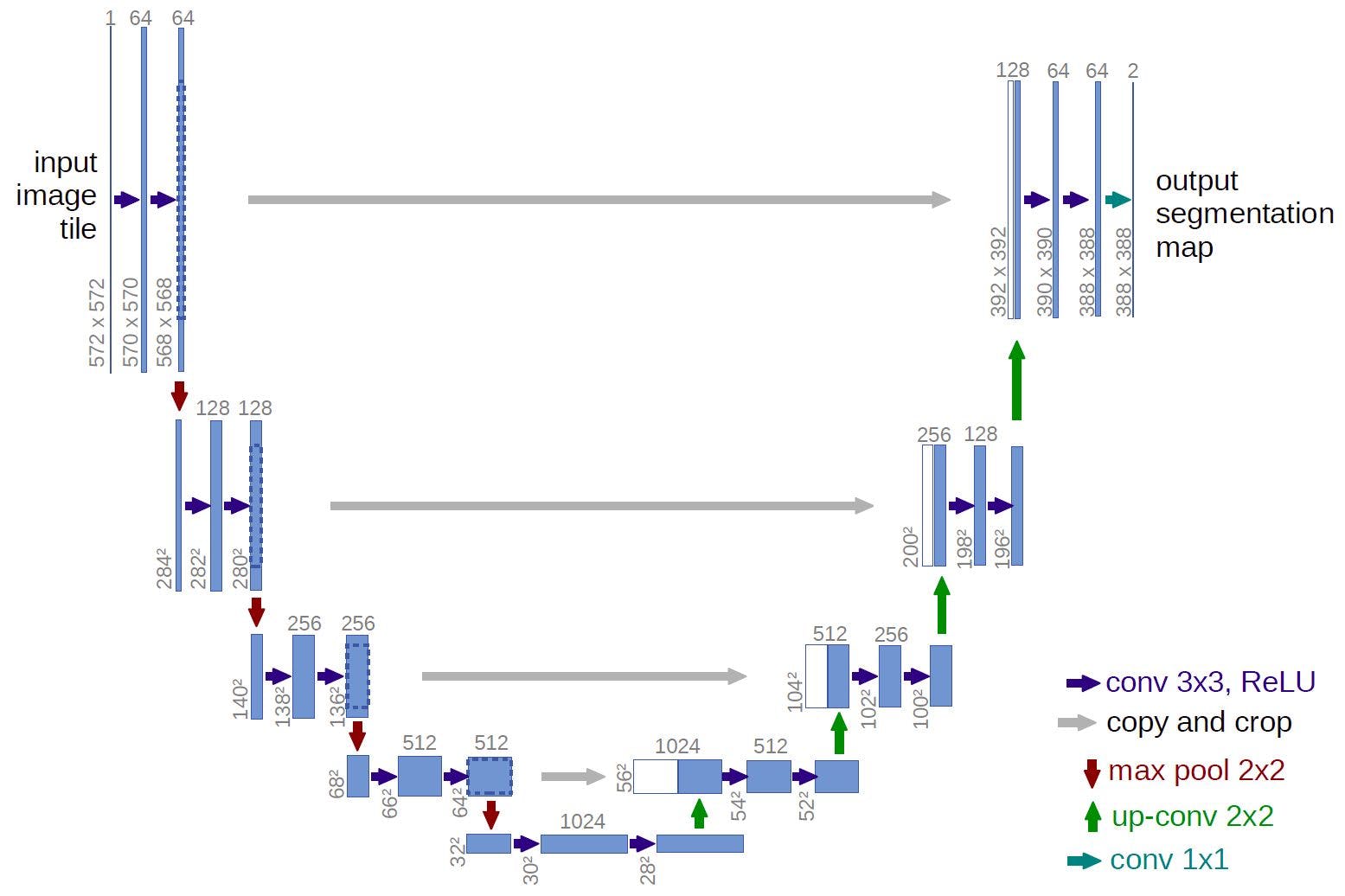
上/下采样块使用了mobilenet_v的权重
Imagenet是一个包含数百万张图片和数万个类的数据集。

坦白地说,对于这个任务,我训练了2个NN和1个算法。
第一个NN从图像中剪下向日葵,像这样:

第二个NN构建2个热图,每个类一个(黑色和白色)。
训练时,该网络的输入是裁剪图像(来自以前的神经网络),目标是在标记点上建立高斯的热图。
对于黑色的玉米粒,它是这样的:


根据该热图,像素越轻,模型越确定像素与核相关。
最后一种算法(高斯的拉普拉斯算法)搜索概率团的中心(相邻的明亮像素组),在下一张图像上,我使用绿色点作为裁剪图像上方的团中心。

白色内核的预测如下所示:

4. 使用libs和工具
为了训练,我使用了Python库,例如:
PyTorch和PyTorch Lightning训练模型
albumentations-用于图像增强
Segmentation_models_pytorch——使用预先训练的模型
Scikit_image -用于处理热图上的斑点
Hyperopt -为斑点检测调优超参数
wandb -跟踪训练实验
5.结果
我们如何验证整个解决方案?
为了计算平均绝对百分比误差(MAPE),我对每一张图像进行预测,并将模型发现的种子数和评审员发现的种子数进行比较。因此,我们得到均值为0的正态分布,效果非常好。
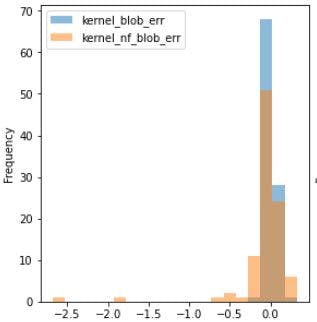
蓝条表示黑色的内核MAPE是3.6%
橙色条-是白色玉米粒,MAPE是8.8%。
6. 误差分析
最大的错误是有异常的向日葵,有异常多的玉米粒,或者太多的灰色玉米粒,或者有圆形的边缘,如下例所示:

在这里,模型比评估者多发现了16%,正如我们所看到的,大多数多余的种子都在向日葵的边缘。
或者最大的错误-257%的白色种子在这个例子中:


白色种子的总数是14个,模型找到了50个。就百分比而言,这确实是一个很大的数字,但就绝对数字而言,它并不重要。
7.失败/假设
有一次,我发现用数学解释了向日葵和其他一些具有分形结构植物的种子位置。位置可以用具有极坐标方程的费马螺旋来解释

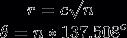
其中n是指标核数c是常数,我想对于每一株向日葵来说都是不同的。因此,我们应该得到以下位置

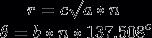
我得到的最佳结果是:

其中蓝点为(0,0)点。所以它在某种程度上很接近,但不适用于实际情况。
8.结论
目前,为了将人为因素排除在计算之外,我们公司已经加快并规范了这项任务。MAPE在业务需求上是可接受的,该解决方案目前在移动应用中也可以使用。
对于我来说,我们能够计算出超过1000个内核,将点划分为2个不同的类别,并且所有这些都可以通过移动设备完成,这让我感到难以置信。
9.参考
以上是关于有了AI,你可以在几秒内数到1000+葵花籽的主要内容,如果未能解决你的问题,请参考以下文章
Codeforces Round #500 (Div. 2) 游记