性能调优一次监控数据错误的性能调优经历
Posted sysu_lluozh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能调优一次监控数据错误的性能调优经历相关的知识,希望对你有一定的参考价值。
针对自建存储服务的回调接口调优时,qps一直卡在1w,但是从各种监控和分析并未找到性能瓶颈,最后发现竟然因为数据库cpu监控不准备误导,特此记录整个调优的过程
一、源码分析
回调接口源码性能分析:
- 1次redis查询
- 2次db操作,其中1次查询,1次写入操作
- 5次本地缓存读取
- 1次外部接口调用
其中最大的性能瓶颈很有可能在db操作中
二、资源配置
| 服务 | 配置 |
|---|---|
| mysql | 一主一从 16c 128g |
| redis | 16g 8节点 |
| callback服务 | 2c 4g |
三、试验分析
接下里根据并发数和callback节点为唯一变量进行压测验证
| 并发数 | qps | callback节点 | avg rt/ms | 95 rt/ms | 99 rt/ms | callback cpu |
|---|---|---|---|---|---|---|
| 5 * 10 | 1922 | 1 | 28.83 | 57 | 83 | 190% |
| 5 * 10 | 4103 | 2 | 11.89 | 27 | 48 | 180% |
| 10 * 10 | 4060 | 2 | 23.28 | 63 | 105 | 170% |
| 10 * 10 | 6028 | 3 | 13.94 | 42 | 77 | 180% |
| 15 * 10 | 6060 | 3 | 21.15 | 60 | 94 | 170% |
| 15 * 10 | 7560 | 4 | 15.87 | 52 | 94 | 160% |
| 20 * 10 | 7830 | 4 | 21.27 | 64 | 111 | 170% |
| 20 * 10 | 9860 | 5 | 16.08 | 51 | 89 | 170% |
| 25 * 10 | 9960 | 5 | 19.63 | 62 | 121 | 170% |
| 25 * 10 | 9790 | 6 | - | - | - | 170% |
| 30 * 10 | 10700 | 6 | 21.35 | 68 | 115 | 170% |
| 40 * 10 | 11170 | 6 | - | - | - | 180% |
| 40 * 10 | 10170 | 10 | 24.04 | 65 | 116 | 100% |
| 40 * 20 | 10700 | 10 | 41.78 | 109 | 142 | 100% |
综上数据可以发现,1个callback节点提供2000qps,5个节点后继续增加节点qps保持在1w
四、影响因素
前面在源码分析中列举了回调接口中影响的因素:
- redis查询
- db操作
- 本地缓存读取
- 外部接口调用
再次通过唯一变量排除的方式,在代码中注释掉其中的处理逻辑
| 因子 | qps |
|---|---|
| redis查询 | 1w |
| db操作 | 2.5w |
| 外部接口调用 | 1w |
ps:
由于多处读取本地缓存信息,如果变更如果修改的范围较大所以本地缓存读取没有试验
从这个信息上面可以排除redis查询、外部接口调用并不是性能的制约点,但是mysql是一个可能的点,但并没有证实mysql就是qps上不去原因
五、数据库监控
既然mysql是目前分析到的一个可疑点,那么我们进一步针对数据库进行分析
5.1 数据库cpu
首先查看数据库的cpu监控
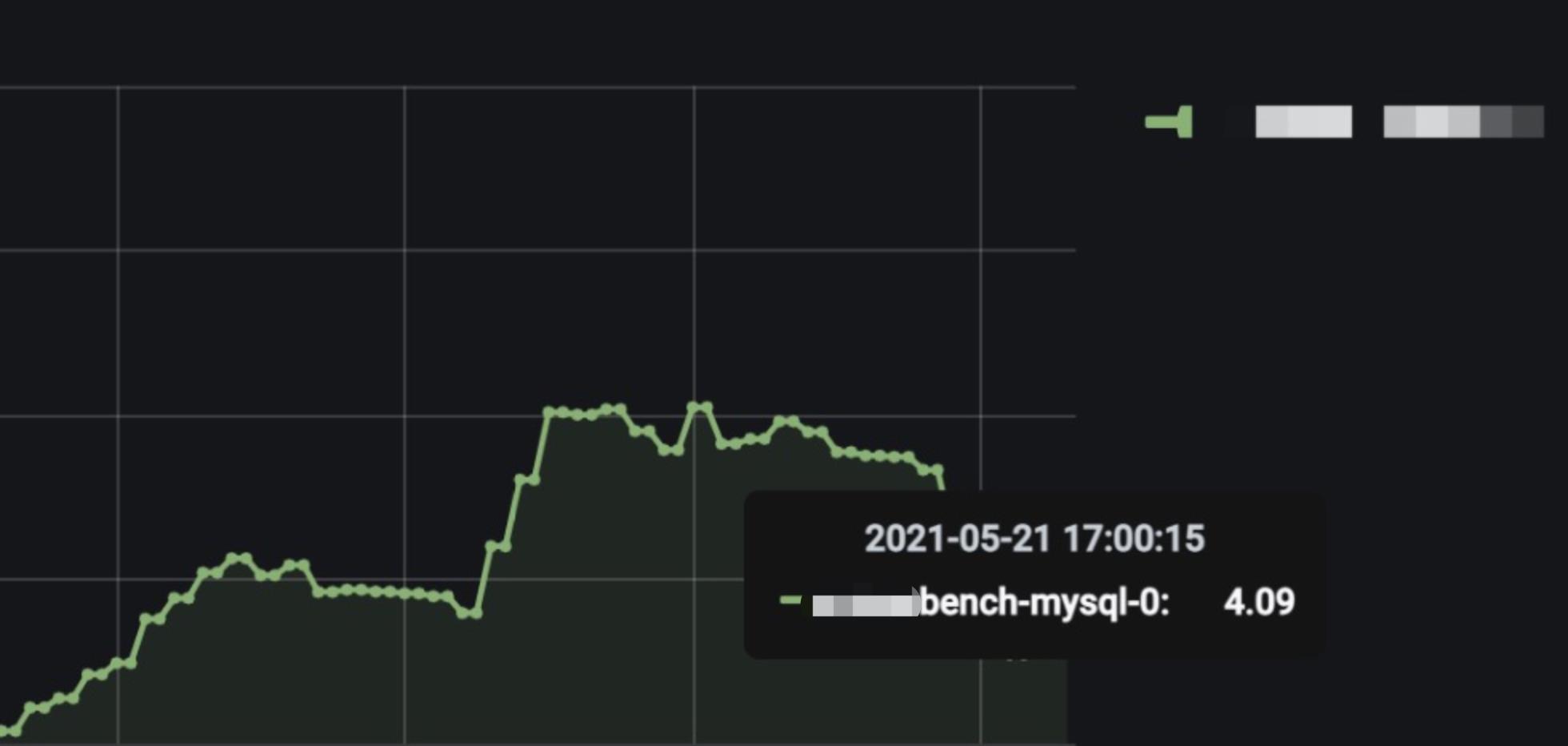
数据库部署的服务在16c的机器上,限制8c,从数据库的的cpu监控来看,cpu最高4c,仅占50%,远没达到瓶颈
5.2 Query Time
由于慢查询slow query设置的时间是0,所以慢查询的数据意义不大,那么看看那select和insert的sql在数据库中的处理时间

从监控中显示,insert Query Time平均时长6ms,select Query Time平均时长289us, 从试验中最后一组数据中,接口的平均响应时间art 41.78ms来看,其实6.289ms(6ms+289us)仅占15%的时间
六、客户端
不能通过监控直接分析出问题,接下来验证确认是否是因为发起压力客户端的问题导致,避免打脸
6.1 客户端资源监控
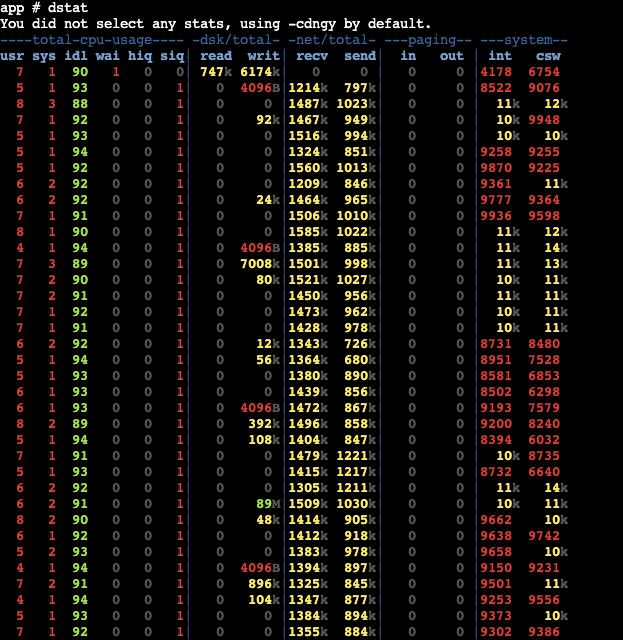
通过dstat监控可以看到,客户端的cpu、内存、带宽资源均未出现瓶颈
6.2 增加客户端
为排除是否是因为连接数等其他潜在因素的影响,客户端从20个增加到40个、60个,在总并发数不变或者倍增的情况下,qps依旧是1w左右,那是否是除了节点数的其他因素的影响呢?
6.3 influxdb升配
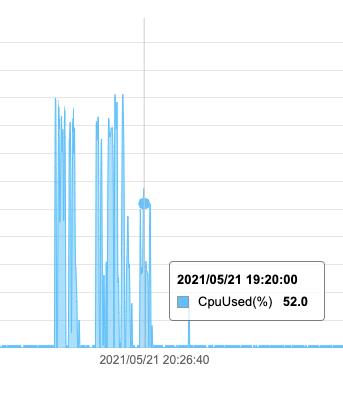
由于客户端数据上报依赖到influxdb,而且数据上报是同步的处理方式,故查看influxdb的监控发现其实influxdb的cpu使用率已经达到90%左右,但是将influxdb从4c升配为8c后,再次进行压测,influxdb的cpu仅占52%不到,但是此时qps仍然是1w左右
6.4 增加额外的压力
其实单纯从监控只能简单排除并非是cpu跑满导致,那需要设计实验的方案排查是否是客户端的原因
设计实验的方案:
- 客户端提供20*10并发,运行时间2min左右,查看qps曲线
- 额外系统提供50并发,此时客户端提供的压力持续,运行时间2min左右,查看qps曲线
- 停止额外系统提供的并发压力,客户端提供的压力持续,运行时间2min左右,查看qps曲线
根据以上方案实验的结果如下:
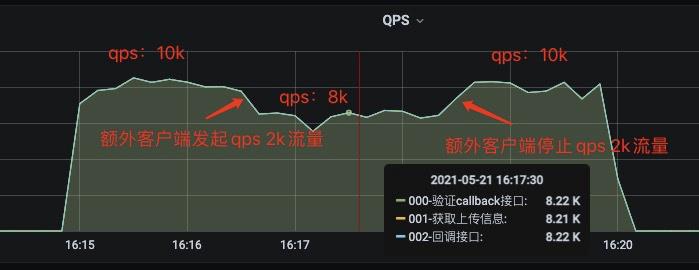
从这个实验结果可以肯定的排除了客户端发起压力的影响
七、线程锁
查看服务端是否有线程锁信息导致qps上不去
其实callback服务节点数从5个增加到10个qps依旧是1w,基本可以排除是因为线程锁等原因引起,但是可以抓取线程数据再次确认一下
7.1 获取线程快照
jstack 1 > 1.txt
具体的【调优工具】线程快照分析 ,使用jca工具打开
7.2 线程状态
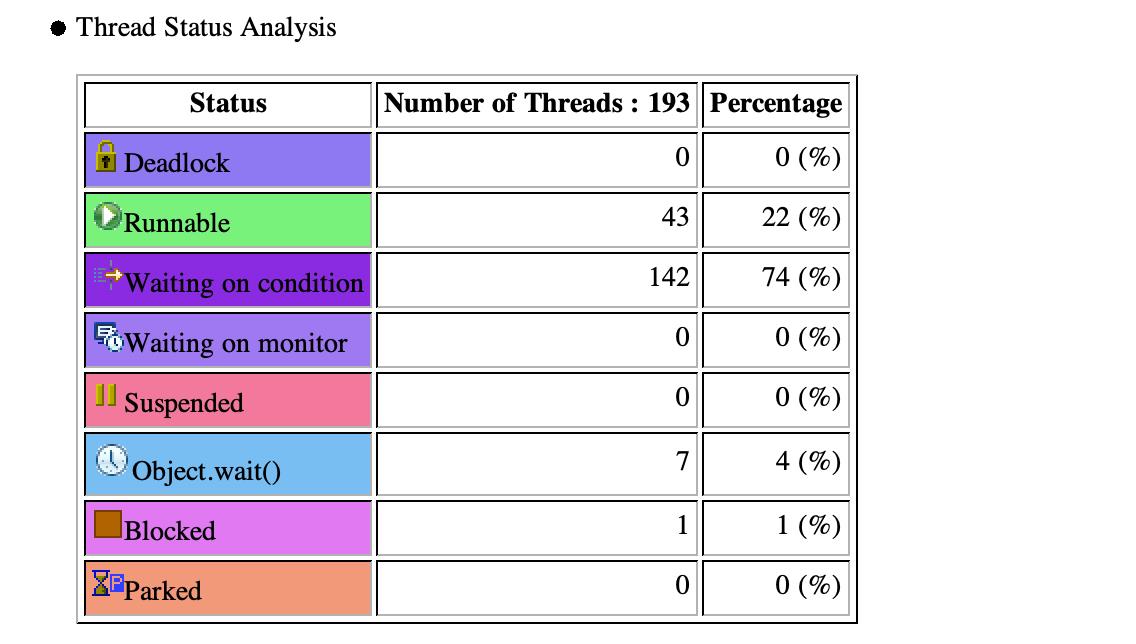 线程状态基本在
线程状态基本在Runnable和Waiting on condition
7.3 Waiting on condition
具体查看Waiting on condition的业务处理
大部分是在tomcat的poll
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078)
at java.util.concurrent.LinkedBlockingQueue.poll(LinkedBlockingQueue.java:467)
at org.apache.tomcat.util.threads.TaskQueue.poll(TaskQueue.java:89)
at org.apache.tomcat.util.threads.TaskQueue.poll(TaskQueue.java:33)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1073)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61)
at java.lang.Thread.run(Thread.java:748)
少部分在druid的getConnectionDirect
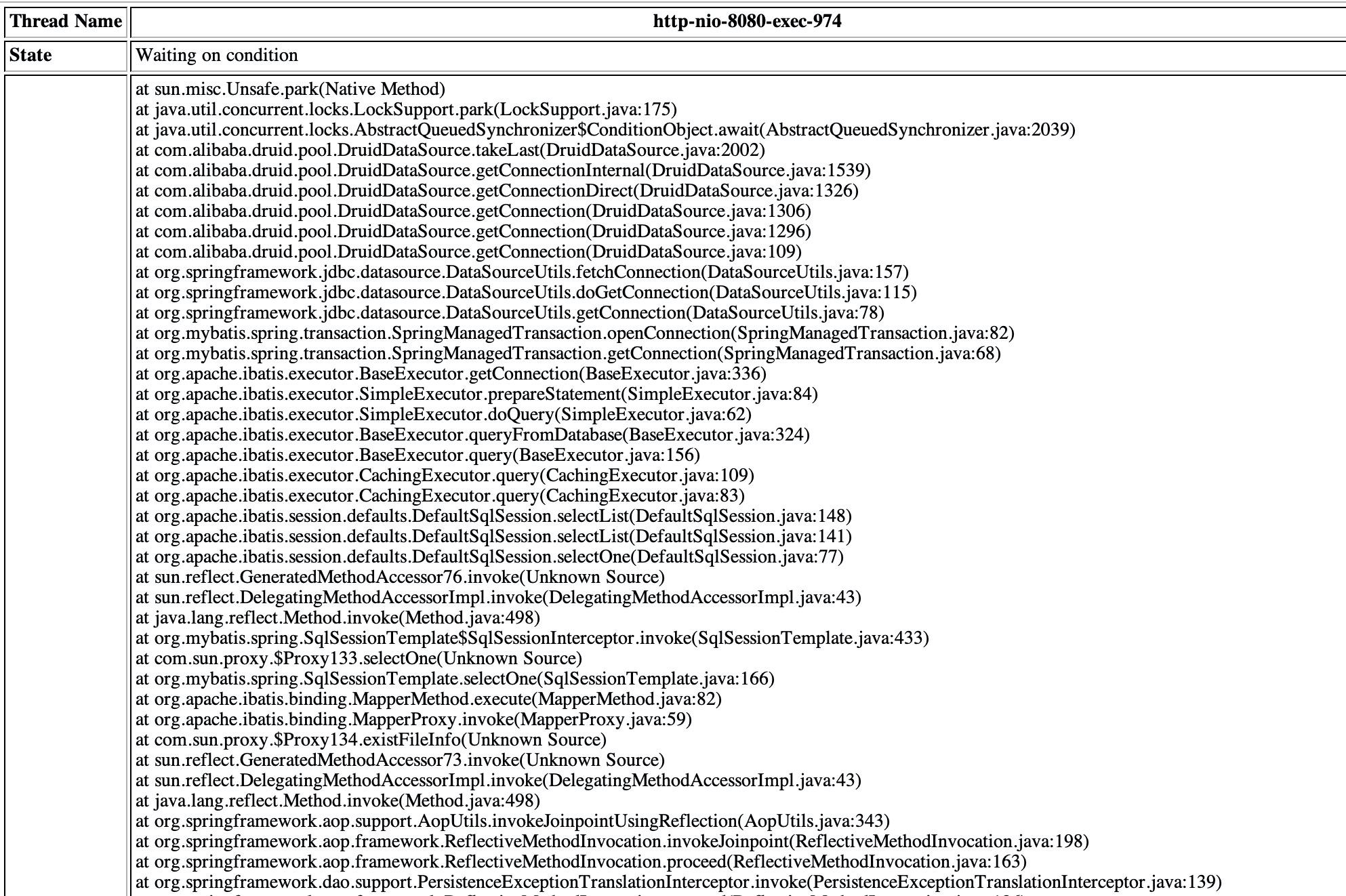
并无明显的异常可分析
八、火焰图
那既然并非是发起压力的客户端的问题,而且通过数据库的监控并不能分析出问题所在,那么看看服务端的堆栈信息分析接口处理时间消耗在哪里
使用arthas profiler抓取堆栈信息或者使用perf抓取数据,打开文件查看火焰图
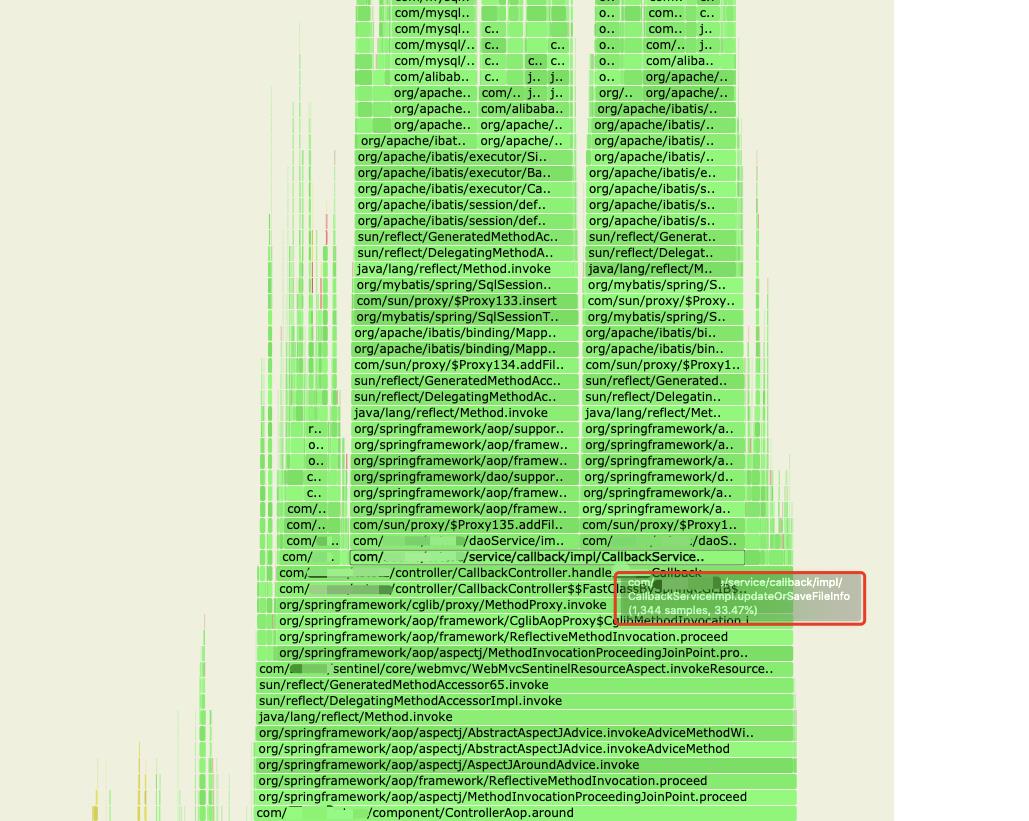
因为updateOrSaveFileInfo中首先执行select sql查询判断后再执行insert sql写入数据,故从火焰图中可以发现业务处理基本消耗在两个数据库的操作上
九、链路分析
9.1 方法入口
执行命令
trace com.lluozh.llz.controller.CallbackController handleLluozhCallback '#cost > 10' -n 10
获取的结果
`---ts=2021-05-21 20:32:17;thread_name=http-nio-8080-exec-2836;id=132e;is_daemon=true;priority=5;TCCL=org.springframework.boot.web.embedded.tomcat.TomcatEmbeddedWebappClassLoader@2b9aeedb
`---[35.16514ms] com.lluozh.llz.service.callback.impl.CallbackServiceImpl:updateOrSaveFileInfo()
+---[0.005561ms] com.lluozh.llz.model.po.FileInfoPo:getAppId() #88
+---[0.003188ms] com.lluozh.llz.model.po.FileInfoPo:getFileKey() #88
+---[21.122075ms] com.lluozh.llz.daoService.FileInfoService:existFileInfo() #88
`---[14.001955ms] com.lluozh.llz.daoService.FileInfoService:addFileInfo() #101
与火焰图抓取的结果基本一致
9.2 逐步向下获取
从上面的堆栈信息,逐步向下获取,接下来获取insert的sql操作
trace com.lluozh.llz.daoService.FileInfoService addFileInfo '#cost > 10' -n 10
获取的结果
`---ts=2021-05-21 20:45:31;thread_name=http-nio-8080-exec-457;id=32c;is_daemon=true;priority=5;TCCL=org.springframework.boot.web.embedded.tomcat.TomcatEmbeddedWebappClassLoader@49ced9c7
`---[21.410149ms] com.sun.proxy.$Proxy135:addFileInfo()
`---[21.38085ms] com.sun.proxy.$Proxy134:addFileInfo()
从这个堆栈信息中发现动态代理com.sun.proxy,而且时间基本全部在处理这个逻辑
9.3 动态代理的追踪
使用了动态代理,那怎么继续往下去获取更加细节的堆栈信息呢?
ps:
一开始捞druid的源码,发现都并没有很好的找到全部的调用方法链路,其实看火焰图分析是可以找到代理底层的所有调用方法
继续看看上面抓取的火焰图,可以发现com.sun.proxy背后执行的逻辑
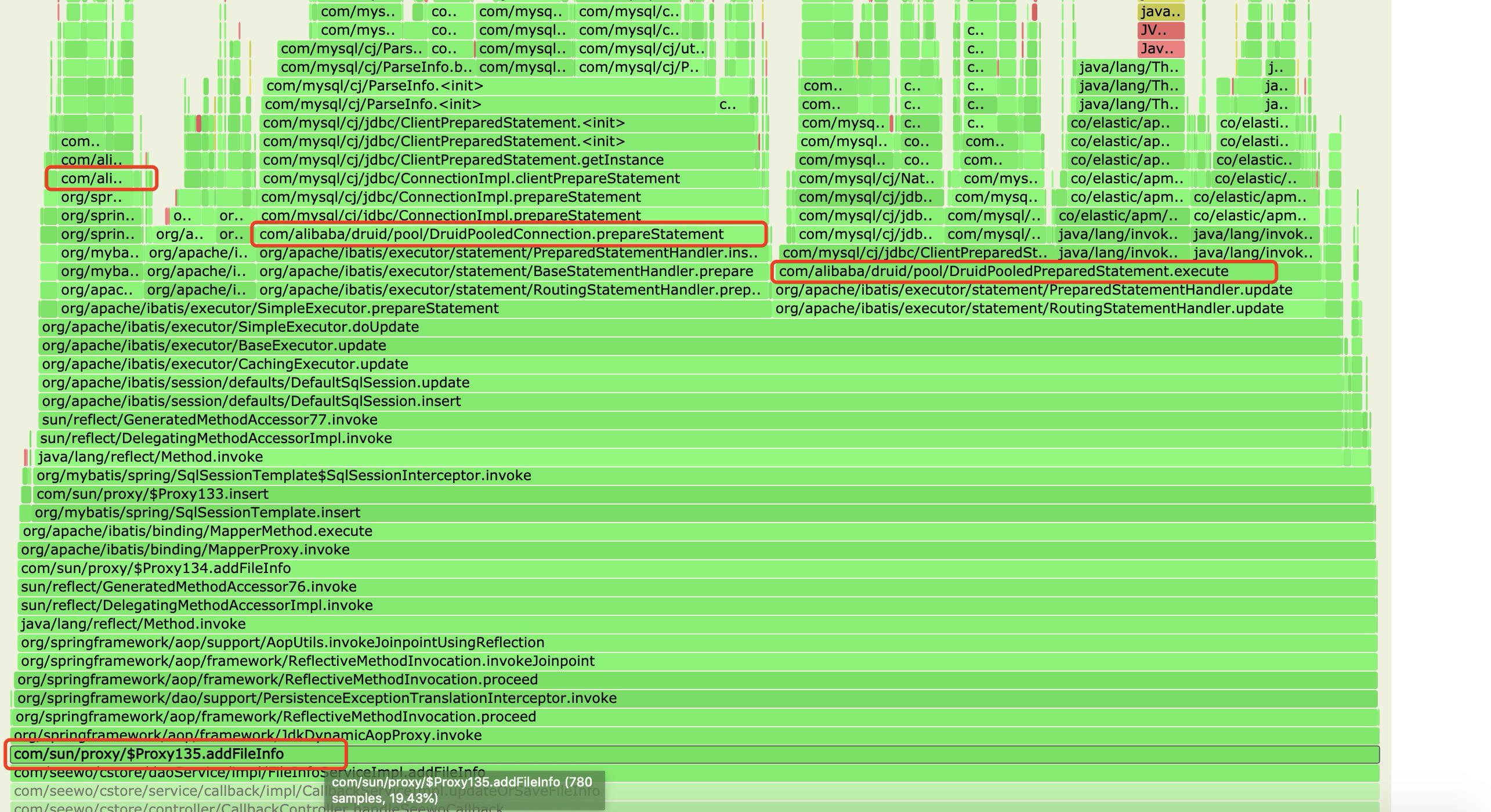
从火焰图中可以看出主要执行的druid方法为
com/alibaba/druid/pool/DruidDataSource.getConnection
com/alibaba/druid/pool/DruidPooledConnection.prepareStatement
com/alibaba/druid/pool/DruidPooledPreparedStatement.execute
9.4 druid执行trace
那接下来trace一下druid的执行
- getConnection
执行命令
trace com.alibaba.druid.pool.DruidDataSource getConnection '#cost > 10' -n 10
获取的结果
`---ts=2021-05-21 20:57:22;thread_name=http-nio-8080-exec-584;id=425;is_daemon=true;priority=5;TCCL=org.springframework.boot.web.embedded.tomcat.TomcatEmbeddedWebappClassLoader@49ced9c7
`---[19.703046ms] com.alibaba.druid.pool.DruidDataSource:getConnection()
`---[19.686816ms] com.alibaba.druid.pool.DruidDataSource:getConnection() #109
`---[19.678128ms] com.alibaba.druid.pool.DruidDataSource:getConnection()
`---[19.646259ms] com.alibaba.druid.pool.DruidDataSource:getConnection() #1296
`---[19.634726ms] com.alibaba.druid.pool.DruidDataSource:getConnection()
+---[0.003328ms] com.alibaba.druid.pool.DruidDataSource:init() #1300
`---[19.564124ms] com.alibaba.druid.pool.DruidDataSource:getConnectionDirect() #1306
抓取的是过滤后的时间较长的逻辑,从上面的火焰图可以看到,其实getConnection的处理时间(服务端执行数据库insert逻辑时间总占比18.48%,getConnection仅占1.07%)仅占整个数据库操作时间的一小部分,说明时间并没有大量消耗在获取连接上
ps:
在性能调优服务端的数据库连接数配置时,可以先trace获取getConnection耗时比重,方便有针对性的调优
- prepareStatement
执行命令
trace com.alibaba.druid.pool.DruidPooledConnection prepareStatement '#cost > 10' -n 10
获取的结果
[arthas@1]$ `---ts=2021-05-21 21:01:01;thread_name=http-nio-8080-exec-633;id=456;is_daemon=true;priority=5;TCCL=org.springframework.boot.web.embedded.tomcat.TomcatEmbeddedWebappClassLoader@49ced9c7
`---[29.744699ms] com.alibaba.druid.pool.DruidPooledConnection:prepareStatement()
+---[0.004268ms] com.alibaba.druid.pool.DruidPooledConnection:checkState() #335
+---[0.004607ms] com.alibaba.druid.pool.DruidPooledConnection:getCatalog() #338
+---[0.004426ms] com.alibaba.druid.pool.DruidPooledPreparedStatement$PreparedStatementKey:<init>() #338
+---[0.003182ms] com.alibaba.druid.pool.DruidConnectionHolder:isPoolPreparedStatements() #340
+---[0.004073ms] com.alibaba.druid.pool.PreparedStatementHolder:<init>() #348
+---[0.003288ms] com.alibaba.druid.pool.DruidConnectionHolder:getDataSource() #349
+---[0.003013ms] com.alibaba.druid.pool.DruidAbstractDataSource:incrementPreparedStatementCount() #349
+---[0.00486ms] com.alibaba.druid.pool.DruidPooledConnection:initStatement() #355
+---[0.005498ms] com.alibaba.druid.pool.DruidPooledPreparedStatement:<init>() #357
`---[0.003386ms] com.alibaba.druid.pool.DruidConnectionHolder:addTrace() #359
druid源码
@Override
public PreparedStatement prepareStatement(String sql) throws SQLException {
checkState();
PreparedStatementHolder stmtHolder = null;
PreparedStatementKey key = new PreparedStatementKey(sql, getCatalog(), MethodType.M1);
boolean poolPreparedStatements = holder.isPoolPreparedStatements();
if (poolPreparedStatements) {
stmtHolder = holder.getStatementPool().get(key);
}
if (stmtHolder == null) {
try {
stmtHolder = new PreparedStatementHolder(key, conn.prepareStatement(sql));
holder.getDataSource().incrementPreparedStatementCount();
} catch (SQLException ex) {
handleException(ex, sql);
}
}
initStatement(stmtHolder);
DruidPooledPreparedStatement rtnVal = new DruidPooledPreparedStatement(this, stmtHolder);
holder.addTrace(rtnVal);
return rtnVal;
}
通过堆栈信息和源码可知,时间消耗在prepareStatement回调耗时中,那再看看火焰图中这块代码的调用逻辑

其实底层调用的均是mysql的原生处理,尝试继续trace其中底层的方法
trace com.mysql.cj.jdbc.ClientPreparedStatement getInstance '#cost > 10' -n 10
获取的结果
`---ts=2021-05-21 21:03:43;thread_name=http-nio-8080-exec-697;id=497;is_daemon=true;priority=5;TCCL=org.springframework.boot.web.embedded.tomcat.TomcatEmbeddedWebappClassLoader@49ced9c7
`---[16.192273ms] com.mysql.cj.jdbc.ClientPreparedStatement:getInstance()
`---[16.181172ms] com.mysql.cj.jdbc.ClientPreparedStatement:<init>() #134
目前暂时无法如何继续往下分析
- execute
执行命令
trace com.alibaba.druid.pool.DruidPooledPreparedStatement execute '#cost > 10' -n 10
获取的结果
`---ts=2021-05-21 21:15:27;thread_name=http-nio-8080-exec-590;id=42b;is_daemon=true;priority=5;TCCL=org.springframework.boot.web.embedded.tomcat.TomcatEmbeddedWebappClassLoader@49ced9c7
`---[32.167451ms] com.alibaba.druid.pool.DruidPooledPreparedStatement:execute()
+---[0.002757ms] com.alibaba.druid.pool.DruidPooledPreparedStatement:checkOpen() #488
+---[0.002721ms] com.alibaba.druid.pool.DruidPooledPreparedStatement:incrementExecuteCount() #490
+---[0.00353ms] com.alibaba.druid.pool.DruidPooledPreparedStatement:transactionRecord() #491
+---[0.002565ms] com.alibaba.druid.pool.DruidPooledConnection:beforeExecute() #495
`---[0.003494ms] com.alibaba.druid.pool.DruidPooledConnection:afterExecute() #503
druid源码
@Override
public boolean execute() throws SQLException {
checkOpen();
incrementExecuteCount();
transactionRecord(sql);
// oracleSetRowPrefetch();
conn.beforeExecute();
try {
return stmt.execute();
} catch (Throwable t) {
errorCheck(t);
throw checkExcept以上是关于性能调优一次监控数据错误的性能调优经历的主要内容,如果未能解决你的问题,请参考以下文章