Flink从零搭建实时数据分析系统
Posted AINLP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink从零搭建实时数据分析系统相关的知识,希望对你有一定的参考价值。
最近在学 Flink,做了一个实时数据分析的 Demo,流程如下所示:

-
Data Mock:作为生产者模拟数据,负责从本地文件系统中读取数据并发往 Kafka; -
Zookeeper:Kafka 的依赖; -
KafKa:消息队列,可以用于发布和订阅消息; -
Flink:流式处理引擎,作为消费者订阅 Kafka 的消息; -
ElasticSearch:搜索引擎,也可以作为实时存储引擎; -
Kibana:可视化 ElasticSearch 中的数据。
除了看过两周 Flink 外,其他的框架都没有接触过,只是简单的拿来用一下,也并不是很了解,所以本篇教程如果有什么错误,欢迎指出。
1.准备
1.1 环境准备
首先是环境准备:
-
Java 8 -
Zookeeper:3.6.1; -
Kafka:2.6.0; -
Flink:1.11.1; -
ElasticSearch:7.8.1 -
Kibana:7.8.1(注意 ES 要与 Kibana 的版本相同)
因为用的是 mac,所以所有环境都可以通过 brew 一键安装,不过还是建议用 Docker 来安装各种环境。
1.2 数据准备
数据:https://tianchi.aliyun.com/dataset/dataDetail?dataId=649
数据集包含了 2017 年 11 月 25 日至 2017 年 12 月 3 日之间,约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢)。数据集的组织形式和 MovieLens-20M 类似,即数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。数据集中每一列的详细描述如下:
| 列名称 | 说明 |
|---|---|
| 用户ID | 整数类型,序列化后的用户ID |
| 商品ID | 整数类型,序列化后的商品ID |
| 商品类目ID | 整数类型,序列化后的商品所属类目ID |
| 行为类型 | 字符串,枚举类型,包括('pv', 'buy', 'cart', 'fav') |
| 时间戳 | 行为发生的时间戳 |
关于数据集大小的一些说明如下:
| 维度 | 数量 |
|---|---|
| 用户数量 | 987,994 |
| 商品数量 | 4,162,024 |
| 商品类目数量 | 9,439 |
| 所有行为数量 | 100,150,807 |
2.实战
2.1 Kafka
2.1.1 简介
先简单介绍下 Kafka。
Kafka 是分布式发布-订阅消息的系统,最初由LinkedIn公司开发的,之后成为Apache项目的一部分,Kafka是一个「分布式,可划分的,冗余备份的持久性的日志服务」,它主要用于处理活跃的流式数据。
kafka的作用「类似于缓存」,即活跃的数据和离线处理系统之间的缓存。
下图为 Kafka 的架构图:
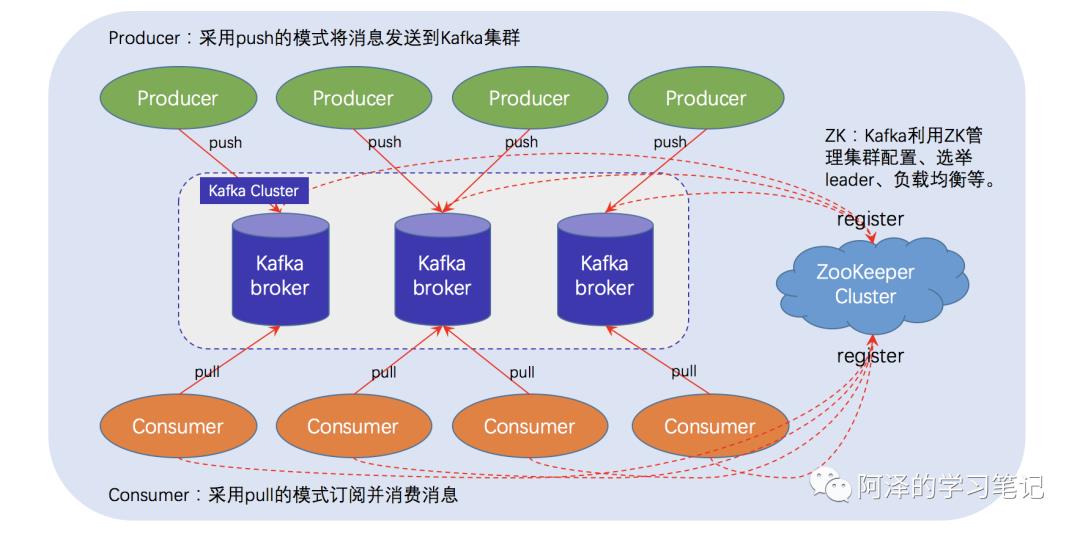
简单介绍一下:
-
Producer:消息生产者,向 Kafka Broker 发送消息(Push); -
Consumer:消费者,从 Kafka Broker 订阅消息(Pull); -
Broker:缓存代理,Kafka 集群中的服务器称为 Broker,每个 Broker 可以容纳多个 Topic; -
Topic:图上没有显示,消息的订阅和发布需要 Topic,相当于給消息取个名字,好分门别类; -
Zookeeper:Kafka 通过 Zookeeper 来管理集群,所以启动 Kafka 之前需要先启动 Zookeeper。
Mac 通过 brew install kafka 可以自动安装 zookeeper 和 kafka。
并通过下面的命令分别启动 zookeeper 和 kafka:
zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties & kafka-server-start /usr/local/etc/kafka/server.properties
注意观察启动信息,不要出现错误。
如果要关闭可可以运行下面的命令:
kafka-server-stop & zookeepker-sever-stop
注意:
-
不要关闭终端,关掉了服务也没了; -
通过 ctrl+c只能关闭 kafka,而无法关闭 kafka。
2.1.2 代码
由于没有线上接口,所以我们需要模拟一个消息源作为 Kafka 的消息生产者。
首先常见一个 maven 项目,建议先统一配置写环境的版本:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.11.1</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<kafka.version>2.6.0</kafka.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
</properties>
首先导入依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_${scala.binary.version}</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
然后创建一个 Kafka 生产者对象:
String kafkaTopic = "user_behavior";
// 使用本地和默认端口
String brokers = "localhost:9092";
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", brokers);
kafkaProps.put("key.serializer", ByteArraySerializer.class.getCanonicalName());
kafkaProps.put("value.serializer", ByteArraySerializer.class.getCanonicalName());
KafkaProducer producer = new KafkaProducer(kafkaProps);
最后我们需要读入用户行为数据,并发送到 kafka 中:
String file_path = "src/main/resources/user_behavior.log";
InputStream inputStream = new FileInputStream(new File(file_path));
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
while (reader.ready()) {
String line = reader.readLine();
System.out.println(line);
// 发送数据
producer.send(new ProducerRecord(kafkaTopic, line.getBytes()));
}
reader.close();
inputStream.close();
以上便完成了消息的发送,当然为了控制速度和断点恢复,我们还可以增加一些其他的操作。
IDEA 打印出来的效果如下:
907262,1081754,149192,pv,1511719039
62462,3472936,3607361,pv,1511719039
576622,4768884,4173315,pv,1511719039
308186,749954,3361496,pv,1511719039
396723,2738192,1464116,pv,1511719039
1262,1107525,1859277,pv,1511719039
49696,2387323,1879194,pv,1511719039
我们可以在终端中通过以下命令查看 Kafka 是否有消息产生:
kafka-console-consumer --bootstrap-server localhost:9092 --topic user_behavior --from-beginning
2.2 Flink
2.2.1 简介
Flink 是一个分布式大数据处理引擎,以数据并行和管道方式执行任意流数据程序,并且支持批处理和流处理程序。Flink 提供高吞吐量、低延迟的流数据引擎,并且支持事件时间处理和状态管理。
其架构我们就不看了,看一些更容易理解的内容,比如说如何写代码:
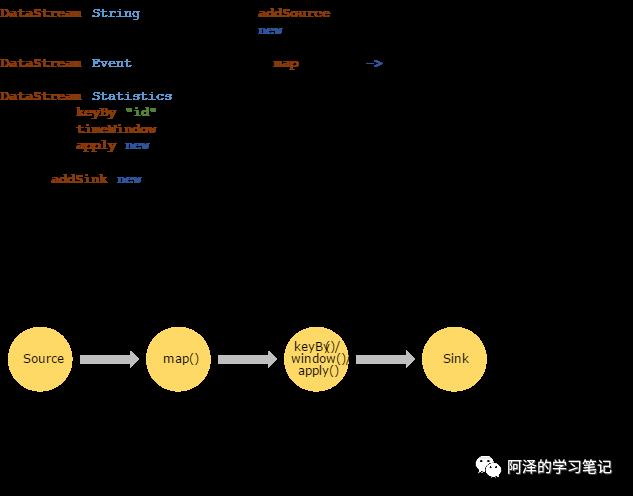
其实很简单,主要分为四块:
-
Environment:定义环境,比如说流处理还是批处理,图上没画; -
Source;数据源接入; -
Transformation:数据转换处理等操作; -
Sink:(下沉)也意味着数据存储。
Mac 通过 brew install apache-flink 可以一键安装 flink。
2.2.2 代码
我们来尝试一下。
首先导入必要的依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
然后定义个流处理环境,并设置事件时间:
// Environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
简单提一下事件时间,顾名思义:这个事件发生的时间,对应处理时间:事件被处理时的时间。我们在简介里提到 Flink 支持事件时间处理指的就是这个。
接着我们需要订阅 Kafka 的消息作为数据流的来源。
// Source
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "test");
DataStreamSource<String> stream = env.addSource(new FlinkKafkaConsumer<>("user_behavior",
new SimpleStringSchema(), properties));
user_behavior 是我们刚刚发布消息时指定的 topic。
为了更好的处理消息,我先把消息转换成一个名为 Behavior 的对象。
定义 Behavior 类:
public class Behavior{
private String user_id;
private String item_id;
private String category_id;
private String behavior;
private long timestamp;
}
构造方法、get、set 方法可以自己添加,为了节省篇幅就不写上去了。
然后我们将订阅的信息流转换成 Behavior 对象:
SingleOutputStreamOperator<Behavior> behaviorStream = stream
.map((MapFunction<String, Behavior>) s -> {String[] split = s.split(",");
Long ts = Long.parseLong(split[4]) * 1000;
Behavior behavior = new Behavior(split[0], split[1], split[2], split[3], ts);
return behavior;
}).assignTimestampsAndWatermarks(WatermarkStrategy
.<Behavior>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner((SerializableTimestampAssigner<Behavior>)
(behavior, l) -> behavior.getTimestamp())
);
这块稍微有些复杂,详细介绍一下。
仔细看一下可以发现这其实由两个操作组成:map 和 assignTimestampsAndWatermarks。
先来看 map 操作:
.map((MapFunction<String, Behavior>) s -> {String[] split = s.split(",");
Long ts = Long.parseLong(split[4]) * 1000;
Behavior behavior = new Behavior(split[0], split[1], split[2], split[3], ts);
return behavior;
})
这其实是一个 lambda 表达式,把输入进来的 String s,根据逗号先 split 成数组,把时间戳所在的位置 *1000,之所以乘上 1000 是为了将时间戳从秒改成毫秒。最后通过 Behavior 的构造函数构造一个对象,并返回。
再来看一下 assignTimestampsAndWatermarks 操作。
.assignTimestampsAndWatermarks(WatermarkStrategy
.<Behavior>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner((SerializableTimestampAssigner<Behavior>)
(behavior, ts) -> behavior.getTimestamp())
)
这部分主要是为该数据流分配一个事件时间和水位线,事件时间以及介绍过了很好理解,而水位线大致可以理解为:流处理过程中可能会有乱序,所以设置一个水位线相当于可以接受的最大的延迟时间,在这个时间内,我们可以进行顺序输出。forBoundedOutOfOrderness 是固定延迟的水位线,并设置了 3 秒的延迟。
接着我们可以做些统计数据:
behaviorStream.windowAll(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.process(new BehaviorCountWinFunc())
.print();
behaviorStream 主要执行了操作:windowAll、process 和 print。
windowAll 即开窗操作,并使用基于事件时间的滑动 SlidingEventTimeWindows,配上参数可以理解为每 5 秒统计一下过去 10 秒的窗口;
process 是对窗口进行的一些操作,我定一个 BehaviorCountWinFunc 类并继承 ProcessAllWindowFunction,主要用于统计窗口内的用户行为。
public class BehaviorCountWinFunc extends ProcessAllWindowFunction<Behavior, Object [], TimeWindow> {
@Override
public void process(Context ctx, Iterable<Behavior> iterable,
Collector<Object []> out) {
int buy = 0;
int fav = 0;
int cart = 0;
int pv = 0;
for (Behavior be : iterable) {
switch (be.getBehavior()) {
case "buy":
++buy;
break;
case "fav":
++fav;
break;
case "cart":
++cart;
break;
case "pv":
++pv;
default:
break;
}
}
Object statis[] = {buy, fav, cart, pv, ctx.window().getEnd()};
System.out.println(statis.toString());
out.collect(statis);
}
}
值得注意的是,我在返回的结果中,除了统计量外还放入了窗口的最后时间。因为之前设置了事件时间,所以该窗口的最后的时间即为窗口内最后一个事件的时间。
print 就是终端打印,也可以理解为另一种 sink。
我们看一下效果:
{Pv=116, Buy=1, Fav=3, Time=1511726210000, Cart=4}
{Pv=113, Buy=0, Fav=2, Time=1511726230000, Cart=5}
{Pv=124, Buy=3, Fav=4, Time=1511726240000, Cart=3}
{Pv=132, Buy=2, Fav=3, Time=1511726220000, Cart=5}
{Pv=120, Buy=2, Fav=3, Time=1511726235000, Cart=3}
{Pv=127, Buy=1, Fav=1, Time=1511726225000, Cart=6}
{Pv=121, Buy=1, Fav=6, Time=1511726205000, Cart=7}
{Pv=126, Buy=2, Fav=3, Time=1511726215000, Cart=4}
至此,实时处理数据流的操作就结束了。
2.3 ElasticSearch
我们再来看看 Elasticsearch。
2.3.1 简介
Elasticsearch 是一个搜索引擎,除此之外,它可以作为一个分布式的实时文件存储系统。
这里用 ES 作为 Flink 的 sink 的地方,主要是为了使用 Kibana 进行数据可视化,当然你也可以使用 ClickHouse+Tabxi。(注意 Flink 连接 ClinkHouse 目前还没有一个很好的依赖。)
由于只是将 ES 做为一个存储工具,所以对 ES 的了解止步于此,感兴趣的可以自行学习。
ES 在 Mac 上安装非常简单:brew install elasticsearch。
在终端上输入 elasticsearch 便可运行。
2.3.2 代码
Flink 的 sink 代码如下:
// ES 配置
List<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("127.0.0.1", 9200, "http"));
// 构建一个 ElasticsearchSink 的 bulider
ElasticsearchSink.Builder<Object[]> esSinkTenSec = new ElasticsearchSink.Builder<>(
httpHosts, new BehaviorCountSinkFunc("statis-user-behavior-10s"));
esSinkTenSec.setBulkFlushMaxActions(1);
behaviorStream.windowAll(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.process(new BehaviorCountWinFunc())
.addSink(esSinkTenSec.build());
首先是 ES 的基本配置:本机和默认端口。
然后构建一个 ElasticsearchSink.Builder,里面有一个我写的类——BehaviorCountSinkFunc,用于定义 sink 到 ES 的数据。
来看一下:
public class BehaviorCountSinkFunc implements ElasticsearchSinkFunction<Object []> {
private String indexName = "";
public BehaviorCountSinkFunc(String indexName) {
this.indexName = indexName;
}
public IndexRequest createIndexRequest(Object [] element) {
Map<String, Object> json = new HashMap<>();
json.put("Buy", element[0]);
json.put("Fav", element[1]);
json.put("Cart", element[2]);
json.put("Pv", element[3]);
json.put("Time", element[4]);
System.out.println(indexName + " 发送数据:" + json.toString());
return Requests.indexRequest().index(indexName).source(json);
}
@Override
public void process(Object[] element, RuntimeContext ctx, RequestIndexer indexer) {
indexer.add(createIndexRequest(element));
}
}
通过构造方法传入一个 indexName,这个 indexName 的功能类似与 Kafka 中的 Topic。类中重写了 process 方法,其将 Object[] element 传給 createIndexRequest 方法,并获得 IndexRequest。比较简单,看下代码应该就能理解。
然后 setBulkFlushMaxActions:
esSinkTenSec.setBulkFlushMaxActions(1);
这个可以理解为最大缓冲。
最后利用 addSink(esSinkTenSec.build()) 来替换 print。
因为打印了,所以可以看一下效果:
statis-user-behavior-10s 发送数据:{Pv=144, Buy=4, Fav=2, Time=1511731045000, Cart=8}
statis-user-behavior-10s 发送数据:{Pv=144, Buy=1, Fav=6, Time=1511731030000, Cart=13}
statis-user-behavior-10s 发送数据:{Pv=121, Buy=1, Fav=3, Time=1511731035000, Cart=14}
statis-user-behavior-10s 发送数据:{Pv=124, Buy=2, Fav=4, Time=1511731040000, Cart=11}
我们可以通过访问:http://localhost:9200/_cat/indices?v 来查看现有的 topic:

2.4 Kibana
Kibana 是一个开源的分析和可视化平台,设计用于和 Elasticsearch 一起工作。你用 Kibana 来搜索,查看,并和存储在 Elasticsearch 索引中的数据进行交互。也可以轻松的执行高级数据分析,并且以各种图标、表格和地图的形式可视化数据。
Mac 安装依旧简单:brew install kabana,并通过 kibana 进行启动。
通过访问 http://localhost:5601/ 可以访问到 kibana 的界面:
我们可以通过 Management -> Index patterns -> Create Index patterns 创建与 ES 中的 index 相关联的数据。
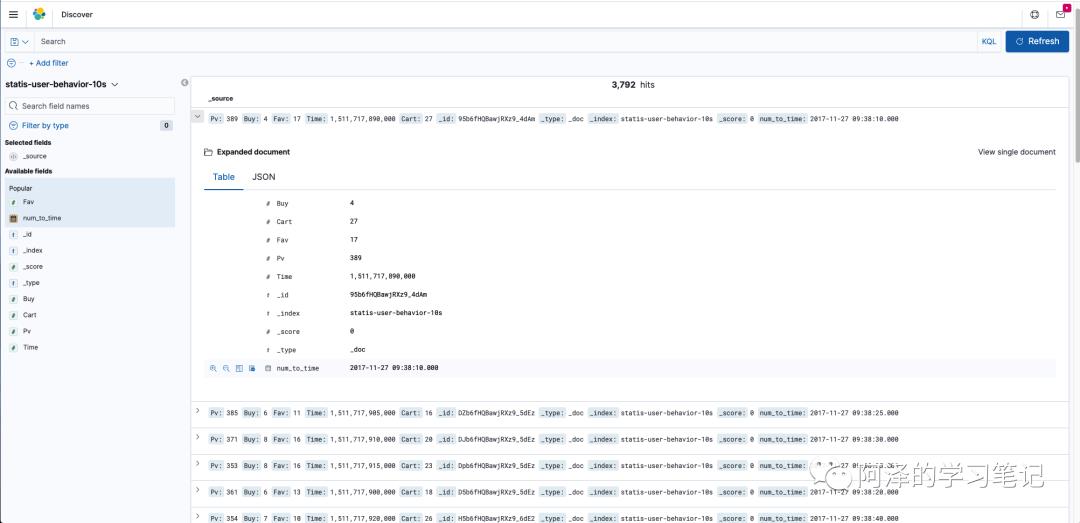
我们可以通过 discover 查看、检索数据:
当然,也可以进行可视化:
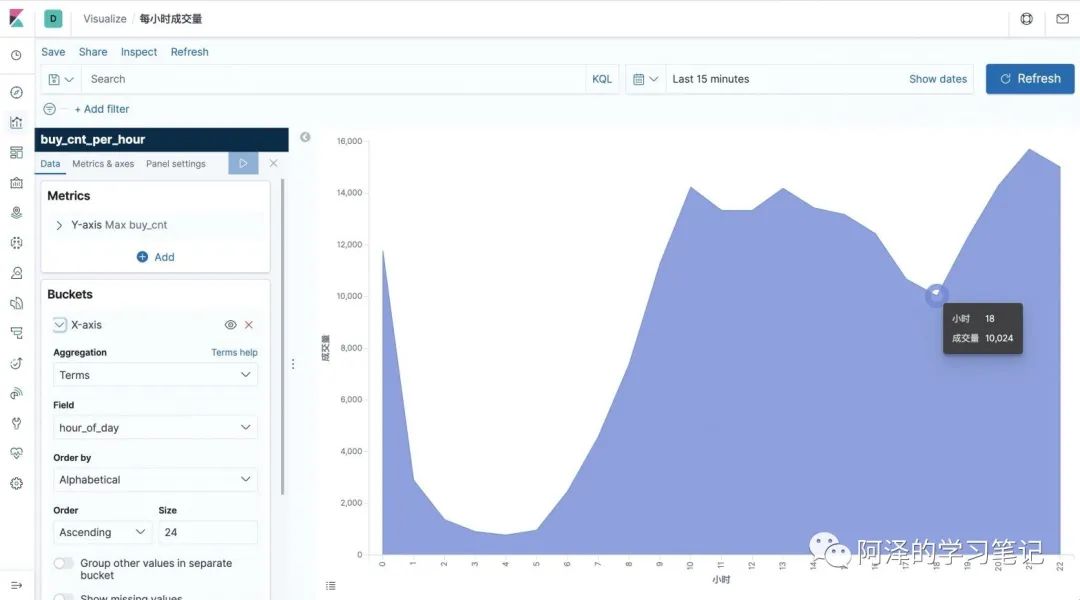
至此便全部讲解完毕来。
3.总结
本文介绍了如何使用 Kafka、Flink、ES、Kibana 搭建一个实时数据分析系统的 Demo,整个过程相对比较简单,但是想搭建一个完整的系统还是很花时间和精力的,特别是在 Kibana 上还遇到了一个很头疼至今未解决的 Bug = =。
当然,本文还是以学习 Flink 为主,其他的都是辅助工具,未来还会为该系统添加更多功能。如果系统做的不错的话会考虑开放源码,如果有感兴趣的同学也欢迎一起学习一起讨论。
4.参考
-
《Demo:基于 Flink SQL 构建流式应用》
-
《User Behavior Data from Taobao for Recommendation》
-
《Kafka介绍之概念》
推荐阅读
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
阅读至此了,分享、点赞、在看三选一吧 以上是关于Flink从零搭建实时数据分析系统的主要内容,如果未能解决你的问题,请参考以下文章