采用HAN网络模型的WebShell检测
Posted 小豹讲安全
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了采用HAN网络模型的WebShell检测相关的知识,希望对你有一定的参考价值。
引言
WebShell是一种常见的Web攻击技术,其基于Web脚本开发,主要由php、jsp、asp等语言编写,由攻击者通过文件上传、SQL注入等攻击手段植入Web应用内。常用于权限维持、数据窃取、内网探测等攻击目的。
通过对Web服务器植入WebShell,攻击者可以获得网站后台权限,进而隐蔽的对服务器进行远程控制。WebShell主要攻击行为有信息嗅探、权限维持、数据窃取和篡改、网络代理等。
WebShell主要有以下几种常见的隐蔽手段:
-
字符串编码与构造
即对脚本中的关键函数进行编码,如Base64、Rot13等方式,在运行的时候再进行解码,如此可以逃避关键字匹配的检测。此外还可对字符串进行混淆处理,在运行时重新构造。
代码混淆
在脚本中加入大量正常且无效的代码或html进行混淆,以逃避基于统计学的检测。
利用反射机制
通过Web语言支持的反射或序列化机制,逃避关键字的特征匹配。
文件包含
将WebShell脚本拆分为多个文件,再通过文件包含汇总。
流量加密
利用加密或编码技术对请求参数进行加密,以隐藏HTTP请求中的指令关键字。
隐蔽通道
例如将指令隐藏在脚本文件名中,根据脚本文件名执行指令。或者可以通过HTTP会话机制将指令隐藏在会话属性中。
针对WebShell的检测方法主要有四种:基于文件的检测、基于流量的检测、基于行为的检测、基于日志的检测。
基于文件的检测
基于文件的检测即直接分析源文件,通过对文件属性、内容、关键字进行静态分析。主要提取的文本特征包括API函数名称、变量名称、信息熵、最长字符串、文件压缩比、重合指数、字符串长度差等。或者可以依据不同的脚本语言,提取脚本编译的操作码的特征进行检测分析。
基于流量的检测
基于流量的检测通过分析攻击者与WebShell的交互流量中提取特征并进行检测。
基于行为的检测
基于行为的检测是对WebShell在运行中的异常行为进行分析,检测脚本运行时的文件读写、网络监听、数据库连接等行为。
基于日志的检测
基于日志的检测通过分析Web系统日志, 对日志的文本特征、访问统计特征、页面请求特征和页面关联特征等进行检测。
本次WebShell检测通过直接对Web脚本进行分析,实现对WebShell的检测。
Hierarchical Attention Networks
由于WebShell脚本本身就是文本文件,对Web脚本进行正常脚本和恶意脚本的分类判断很容易让人联想到NLP领域中的文本分类、情感分类等问题,自然而然可以考虑采用NLP的语言分类模型对Web脚本进行分类检测。
在WebShell检测中,早期的基于文件的检测通过提取文本特征,或者基于OPCode(操作码)、AST(抽象语法树)等信息,采用机器学习的方式进行分类。可以发现,采用信息熵、高危函数名称、重合指数等特征提取的方式比较依赖于脚本本身语言类型,尤其基于OPCode的方式更是依赖于语言本身,单一的机器学习模型难以对多种文件类型的脚本进行准确分类,况且提取特征信息的操作较为繁琐。
NLP领域中,文本分类模型已经发展的较为成熟,常见的模型比如有fastText、textCNN、charCNN、Bi-LSTM、RCNN、基于Transformer、基于预训练模型(BERT、GPT)等等。
此次WebShell检测将采用HAN(Hierarchical Attention Networks for Document Classification)模型。由名称可知,HAN是一种多层注意力模型。文本分类模型的目的是从单词中得出句子的含义,然后从这些句子中得出文档的含义,最后根据文本所描述的内容进行分类。但是并非所有单词都同样重要,其中的某些关键词比其他词汇更能描述句子。因此,HAN使用注意力模型,以便句子向量可以更多地关注“重要”单词。在对句子向量的处理中使用相同的方式,最终的向量体现了整个文档的要旨。HAN有两个显著特点:
利用文档原有的层次结构(词--句子--文档),即先使用单词的词向量表示句子,在此基础上以句子向量构建文本的信息表示。
由于在文档中,句子对文档的重要性贡献有差异,在句子中,每个单词对句子的重要性也有差异。因此模型分别在Word Level和Sentence Level中采用注意力机制(Attention),从而对文本中重要性不同的句子和词分配不同的“注意力” 。
Web脚本的每行代码类似于自然语言文档中的句子,每行代码中的关键字、函数名、变量名等信息类似于单词,不同的标识信息具有不同的意义。而且行间代码中具有语法结构信息,类比文档中的不同句子间的语义结构。由此可以尝试采用HAN网络模型对WebShell进行检测。
HAN模型结构如下:
由图可见,HAN包含一个词向量编码器、一个词级注意力层、一个句子序列编码器、一个句子级注意力层。
Word Encoder
通过GloVe、Word2Vec等方式将词转化成对应的词向量,然后用Bi-GRU网络,可以将单词的两个方向,即正向和反向的前后文信息结合起来,获得隐藏层输出。
Word Attention
通过Attention机制描述每个单词的重要性,即抽取句子中相对重要的单词,最后得到词向量的加权和,组成句子的向量表示。
Sentence Encoder
得到了句子向量表示后,与Word Encoder类似,对句子采用Bi-GRU获取句子上下文的信息表示。
Sentence Attention
同样对所有句子采取Attention操作,获得每个句子的加权平均作为整个输入的特征向量。
Document Classification
通过Softmax层进行最后的文本分类。
简单概述一下注意力机制,Attention常用的基本公式如下:
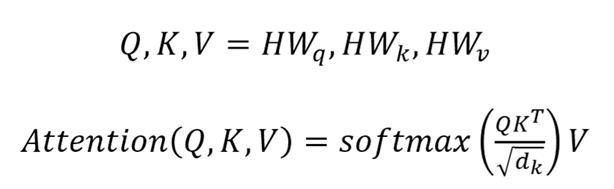
Attention核心代码
pythonfrom tensorflow.keras import backend as Kfrom tensorflow.keras import initializers, regularizers, constraintsfrom tensorflow.keras.layers import Layerclass Attention(Layer):def __init__(self, step_dim,W_regularizer=None, b_regularizer=None,W_constraint=None, b_constraint=None,bias=True, **kwargs):self.supports_masking = Trueself.init = initializers.get('glorot_uniform')self.W_regularizer = regularizers.get(W_regularizer)self.b_regularizer = regularizers.get(b_regularizer)self.W_constraint = constraints.get(W_constraint)self.b_constraint = constraints.get(b_constraint)self.bias = biasself.step_dim = step_dimself.features_dim = 0super(Attention, self).__init__(**kwargs)def build(self, input_shape):assert len(input_shape) == 3self.W = self.add_weight(shape=(input_shape[-1],),initializer=self.init,name='{}_W'.format(self.name),regularizer=self.W_regularizer,constraint=self.W_constraint)self.features_dim = input_shape[-1]if self.bias:self.b = self.add_weight(shape=(input_shape[1],),initializer='zero',name='{}_b'.format(self.name),regularizer=self.b_regularizer,constraint=self.b_constraint)else:self.b = Noneself.built = Truedef compute_mask(self, input, input_mask=None):return Nonedef call(self, x, mask=None):features_dim = self.features_dimstep_dim = self.step_dime = K.reshape(K.dot(K.reshape(x, (-1, features_dim)), K.reshape(self.W, (features_dim, 1))), (-1, step_dim))if self.bias:e += self.be = K.tanh(e)a = K.exp(e)if mask is not None:a *= K.cast(mask, K.floatx())a /= K.cast(K.sum(a, axis=1, keepdims=True) + K.epsilon(), K.floatx())a = K.expand_dims(a)c = K.sum(a * x, axis=1)return cdef compute_output_shape(self, input_shape):return input_shape[0], self.features_dim
HAN核心代码
pythonfrom tensorflow.keras import Input, Modelfrom tensorflow.keras.layers import Embedding, Dense, Dropout, Bidirectional, LSTM, TimeDistributedclass HAN(object):def __init__(self, maxlen_sentence, maxlen_word, max_features, embedding_dims,class_num=5,last_activation='softmax'):self.maxlen_sentence = maxlen_sentenceself.maxlen_word = maxlen_wordself.max_features = max_featuresself.embedding_dims = embedding_dimsself.class_num = class_numself.last_activation = last_activationdef get_model(self):# Word partinput_word = Input(shape=(self.maxlen_word,))x_word = Embedding(self.max_features, self.embedding_dims, input_length=self.maxlen_word)(input_word)x_word = Bidirectional(LSTM(128, return_sequences=True))(x_word) # LSTM or GRUx_word = Attention(self.maxlen_word)(x_word)model_word = Model(input_word, x_word)# Sentence partinput = Input(shape=(self.maxlen_sentence, self.maxlen_word))x_sentence = TimeDistributed(model_word)(input)x_sentence = Bidirectional(LSTM(128, return_sequences=True))(x_sentence) # LSTM or GRUx_sentence = Attention(self.maxlen_sentence)(x_sentence)output = Dense(self.class_num, activation=self.last_activation)(x_sentence)model = Model(inputs=input, outputs=output)return model
WebShell检测
首先从GitHub中收集并整理数据集,最后获得8296个正常样本,5225个WebShell样本。正常样本中php类型有6921个,jsp类型有584个,aspx类型有632个,asp类型有159个。WebShell样本中php类型有3386个,jsp类型有711个,aspx类型有371个,asp类型有757个。对数据集依据比例进行切分,获得相应的训练集和测试集。
接下来对样本进行预处理,先对Web脚本文本内容进行正则匹配,去除例如注释语句等冗余信息。然后对样本进行分词,分词的标准以函数名、变量名等关键字的结构信息进行切分。采用训练集的样本进行Word2Vec的词向量训练。
在训练阶段,首先对每个样本取固定长度的代码行,将文档内容逐字通过Word2Vec预训练模型词向量化,最后将并通过HAN模型进行训练。在10轮左右的epoch后取得较为稳定的结果,对1000个测试样本进行测试后结果如下:
AUC: 0.99537504ACC: 0.99519231Recall: 0.99620133F1-score: 0.99384178Precision: 0.99149338
还可以。
不足和提高
1. 数据样本可以根据业务情况进行针对性筛选。
2. 输出分类错误的样本进行分析,并依此优化模型。
3. 配合规则或机器学习方式,从多角度深化检测手段,提高检测器的泛化能力。
参考文献
1. Yang Z, Yang D, Dyer C, et al. Hierarchical attention networks for document classification[C]//Proceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies. 2016: 1480-1489.
2. 张昊祎. 基于语义分析和神经网络的 WebShell 检测方法[J]. 空间网络安全, 2019, 10(2): 1-7.
3. 周龙. 基于 LSTM 的 Webshell 检测方法研究[D]. 武汉邮电科学研究院, 2020.
猎豹安全中心技术分享频道


以上是关于采用HAN网络模型的WebShell检测的主要内容,如果未能解决你的问题,请参考以下文章
红蓝对抗之常见网络安全事件研判了解网络安全设备Webshell入侵检测