神经网络检测webshell
Posted Neil-Yale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络检测webshell相关的知识,希望对你有一定的参考价值。
从题目可以看到本次实验的主题有两个关键字,神经网络和webshell。
Webshell是黑客经常使用的一种恶意脚本,其目的是获得服务器的执行操作权限,比如执行系统命令、窃取用户数据、删除web页面、修改主页等,其危害不言而喻。黑客通常利用常见的漏洞,如SQL注入、远程文件包含(RFI)、FTP,甚至使用跨站点脚本攻击(XSS)等方式作为社会工程攻击的一部分,最终达到控制网站服务器的目的。实验室相关的实验有很多,这里不过多展开介绍。
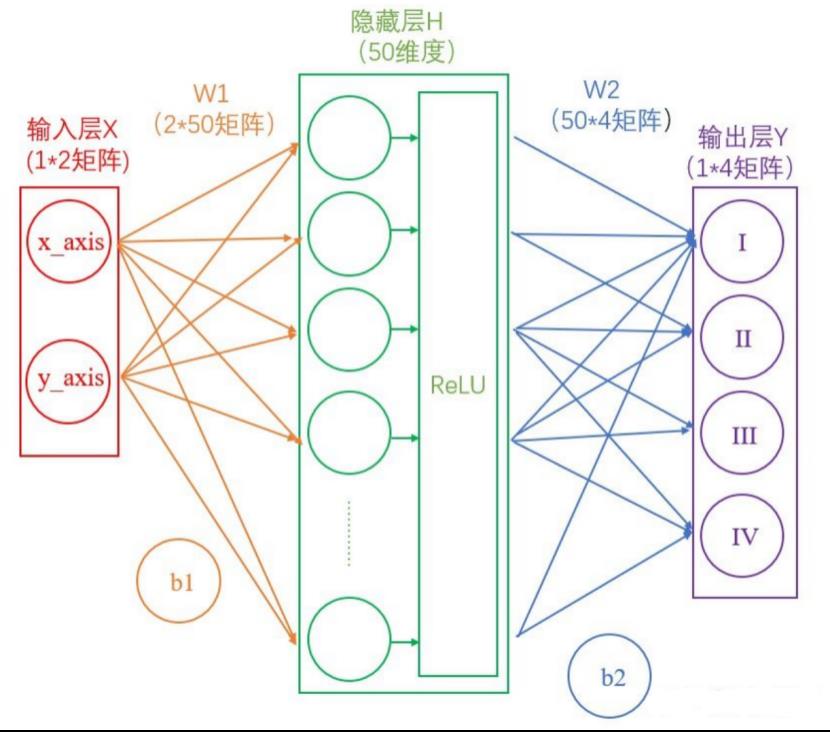
我们来学习什么是神经网络。我们以一个简单的分类任务为例,已知四个数据点(1,1)(-1,1)(-1,-1)(1,-1),这四个点分别对应I~IV象限,如果这时候给我们一个新的坐标点(比如(2,2)),那么它应该属于哪个象限呢?我们这里以两层神经网络为例进行分析。理论上两层神经网络已经可以拟合任意函数,结构如下所示
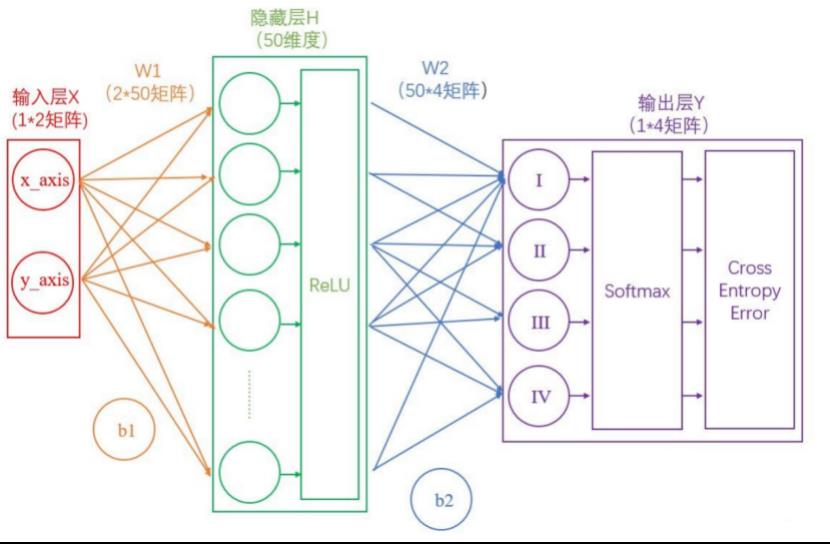
我们把ReLu,Softmax之类的专业术语去掉,简化一下,如下所示
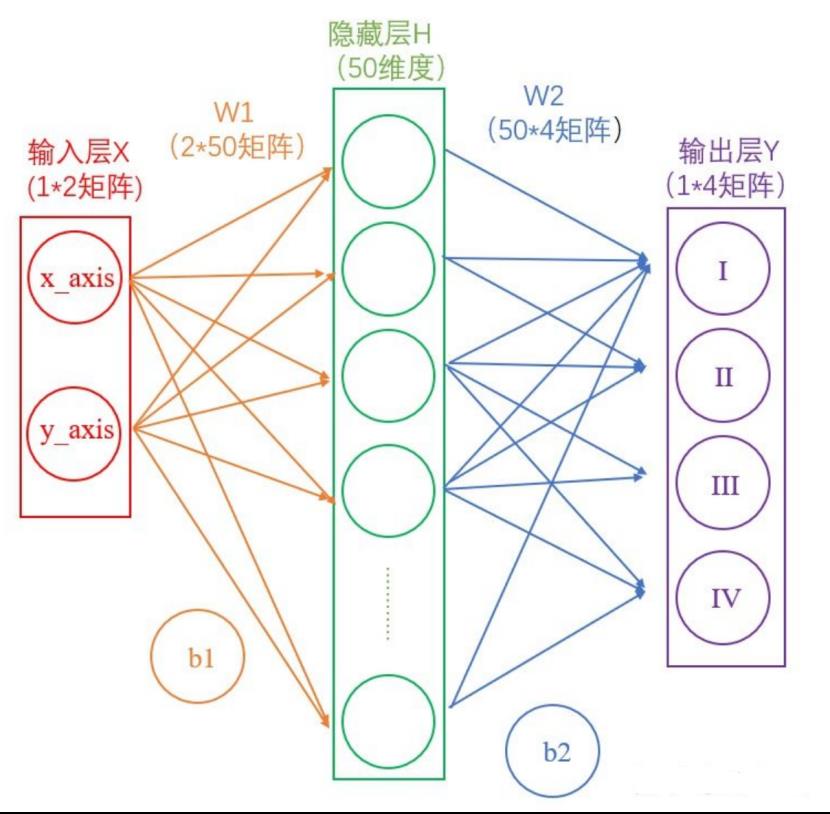
先看输入层。输入层是坐标值,例如(2,2),这是一个包含两个元素的数组,也可以看作是一个12的矩阵。输入层的元素维度与输入量的特征息息相关,如果输入的是一张3232像素的灰度图像,那么输入层的维度就是32*32
接着是输入层(红)到隐藏层(绿)。连接这两层是上图黄色的线,可以看到由X计算得到H,需要进行矩阵运算

如上图中所示,在设定隐藏层为50维(也可以理解成50个神经元)之后,矩阵H的大小为(1*50)的矩阵。
然后是隐藏层(绿)到输出层(紫),连接这两层是上图蓝色的线,同样需要进行矩阵运算

通过上述两个线性方程的计算,我们就能得到最终的输出Y了。
不过仅仅这样是不够的,这样只是一个线性变换;我们还需要激活层,为矩阵运算的结果添加非线性,这使得我们可以任意学习输入和输出之间的复杂变换。这就涉及到了激活函数
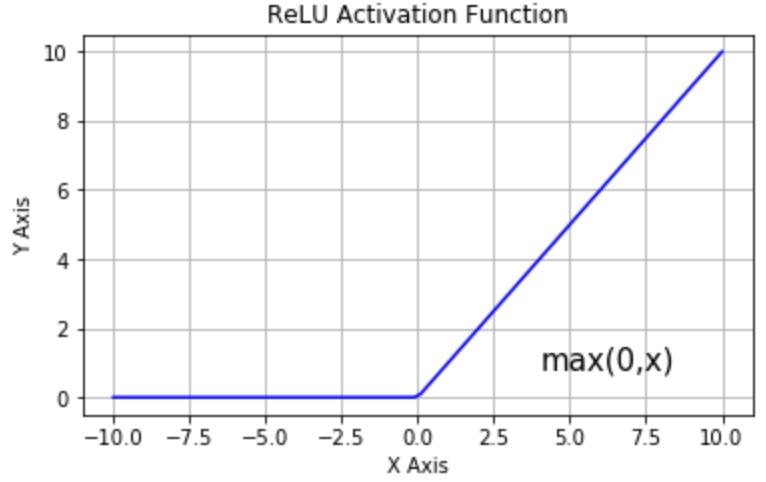
常用的激活函数有Sigmoid、ReLu等
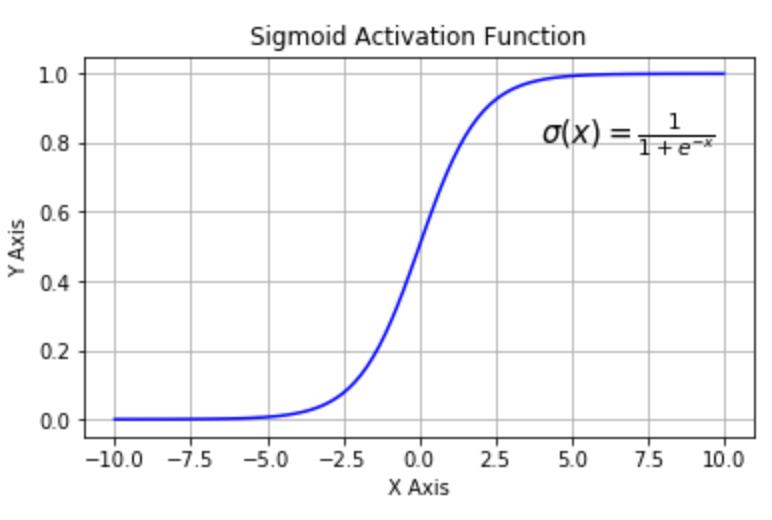
Sigmoid:当输入趋近于正无穷/负无穷时,输出无限接近于1/0。
ReLU:当输入小于0时,输出0;当输入大于0时,输出等于输入。
Sigmoid函数在当x的绝对值较大时,曲线的斜率变化很小(梯度消失),并且计算较复杂;ReLU是当前较为常用的激活函数
假如经过公式H=X*W1+b1计算得到的H值为:(1,-2,3,-4,7…),那么经过ReLU激活层之后会变为(1,0,3,0,7…)。
需要注意的是,每个隐藏层计算(矩阵线性运算)之后,都需要加一层激活层,要不然该层线性计算是没有意义的。
此时的神经网络变成了如下图所示的形式:
到这里还没结束,我们还需要对输出进行正则化。
我们想让最终的输出为概率,也就是说可以生成像(90%,5%,2%,3%)这样的结果,这样做不仅可以找到最大概率的分类,而且可以知道各个分类计算的概率值。
计算公式如下
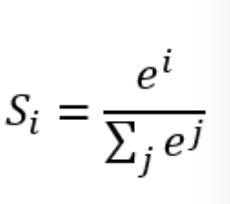
简单来说分三步进行:(1)以e为底对所有元素求指数幂;(2)将所有指数幂求和;(3)分别将这些指数幂与该和做商。
这样求出的结果中,所有元素的和一定为1,而每个元素可以代表概率值。
我们将使用这个计算公式做输出结果正规化处理的层叫做“Softmax”层。此时的神经网络将变成如下图所示:
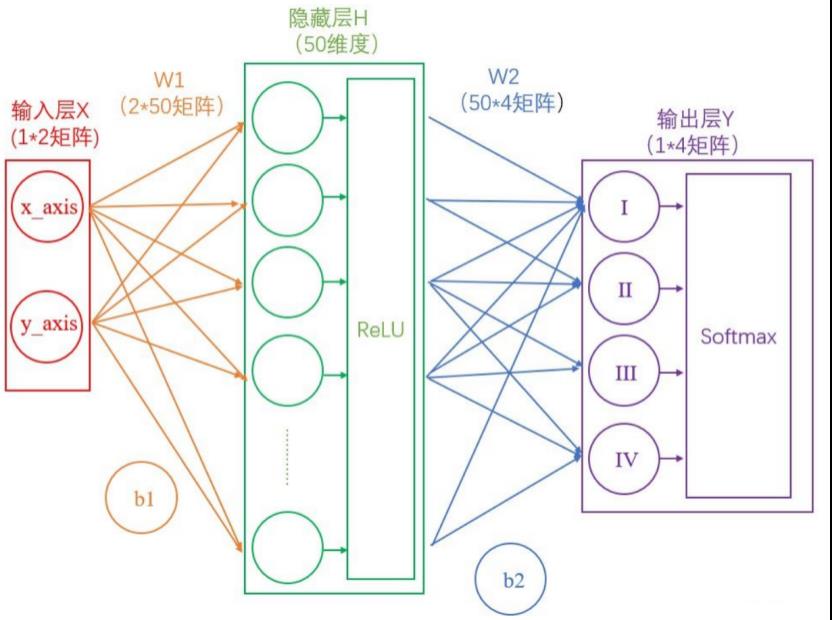
到这一步为止,我们通过我们得到了I,II,III和IV这四个类别分别对应的概率,但是要注意,这是神经网络计算得到的概率值结果,而非真实的情况。
比如,Softmax输出的结果是(90%,5%,3%,2%),真实的结果是(100%,0,0,0)。虽然输出的结果可以正确分类,但是与真实结果之间是有差距的,一个优秀的网络对结果的预测要无限接近于100%,为此,我们需要将Softmax输出结果的好坏程度做一个“量化”
一种直观的解决方法,是用1减去Softmax输出的概率,比如1-90%=0.1。不过更为常用且巧妙的方法是,求对数的负数。
还是用90%举例,对数的负数就是:-log0.9=0.046
可以想见,概率越接近100%,该计算结果值越接近于0,说明结果越准确,该输出叫做“交叉熵损失(Cross Entropy Error)”。
我们训练神经网络的目的,就是尽可能地减少这个“交叉熵损失”。
此时的网络如下图:
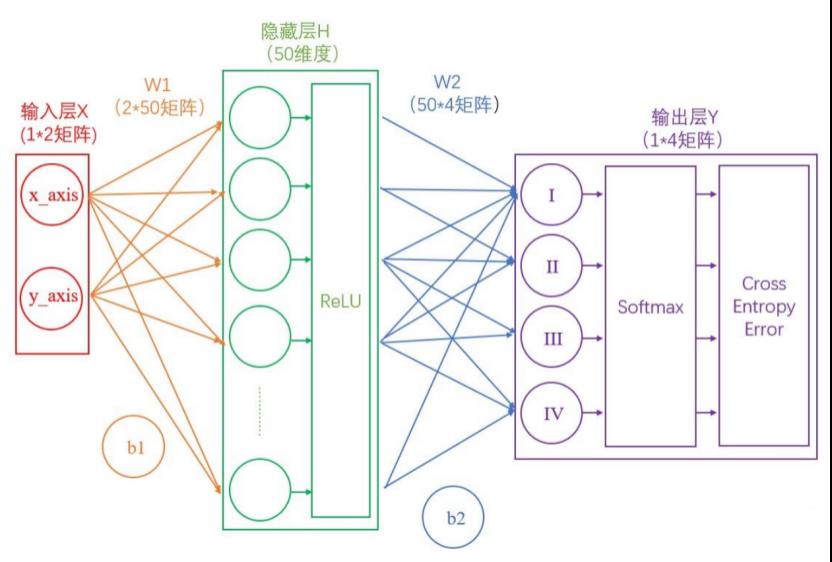
到这一步为止,是我们神经网络的正向传播过程,算出交叉熵损失后,就要开始反向传播了。其实反向传播就是一个参数优化的过程,优化对象就是网络中的所有W和b(因为其他所有参数都是确定的)。
参数优化的原理与方法在学校里也是有专业的课程的的,这里不展开讲。
假设我们操纵着一个球型机器行走在沙漠中

我们在机器中操纵着四个旋钮,分别叫做W1,b1,W2,b2。当我们旋转其中的某个旋钮时,球形机器会发生移动,但是旋转旋钮大小和机器运动方向之间的对应关系是不知道的。而我们的目的就是走到沙漠的最低点
此时我们该怎么办?只能挨个试。
如果增大W1后,球向上走了,那就减小W1。
如果增大b1后,球向下走了,那就继续增大b1。
如果增大W2后,球向下走了一大截,那就多增大些W2。。。
这个方法叫做梯度下降法。
当我们的球形机器走到最低点时,也就代表着我们的交叉熵损失达到最小(接近于0)
接下来我们的神经网络需要反复迭代。
第一次计算得到的概率是90%,交叉熵损失值是0.046;将该损失值反向传播,使W1,b1,W2,b2做相应微调;再做第二次运算,此时的概率可能就会提高到92%,相应地,损失值也会下降,然后再反向传播损失值,微调参数W1,b1,W2,b2。依次类推,损失值越来越小,直到我们满意为止。
此时我们就得到了理想的W1,b1,W2,b2。
此时如果将任意一组坐标作为输入,就能得到分类结果
我们接下里来看看如何通过sklearn中封装好的神经网络帮助我们进行训练
MLP在两个数组上训练:大小为X的数组(n_samples,n_features),用于保存表示为浮点特征向量的训练样本; 大小为(n_samples,)的数组y,用于保存训练样本的目标值(类标签):
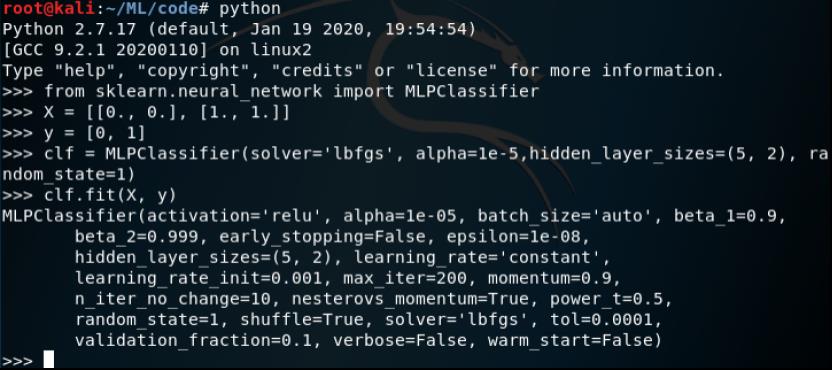
训练之后,模型就可以用于训练给出的新样本的标签了
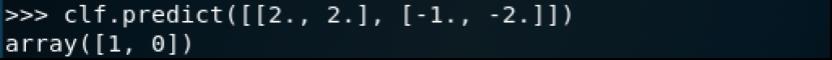
数据集使用ADFA-LD中的Traning_Data_Master和Attack_Data_Master中的Webshell相关数据。
训练集(Training_Data_Master)数据都是在主机的正常操作过程中收集的,包括从浏览web到准备latex文档的各种活动。调用序列通过auditd Unix程序生成,然后按大小进行过滤。其中训练集数据大小在300比特到6kb之间,验证集数据在300kb到10kb之间,这是为了有效权衡数据保真度和不必要的处理负担。
攻击数据集(Attack_Data_Master)里共有6种攻击方式,我们这次采用的是其中的webshell
打开任一文件,如下所示

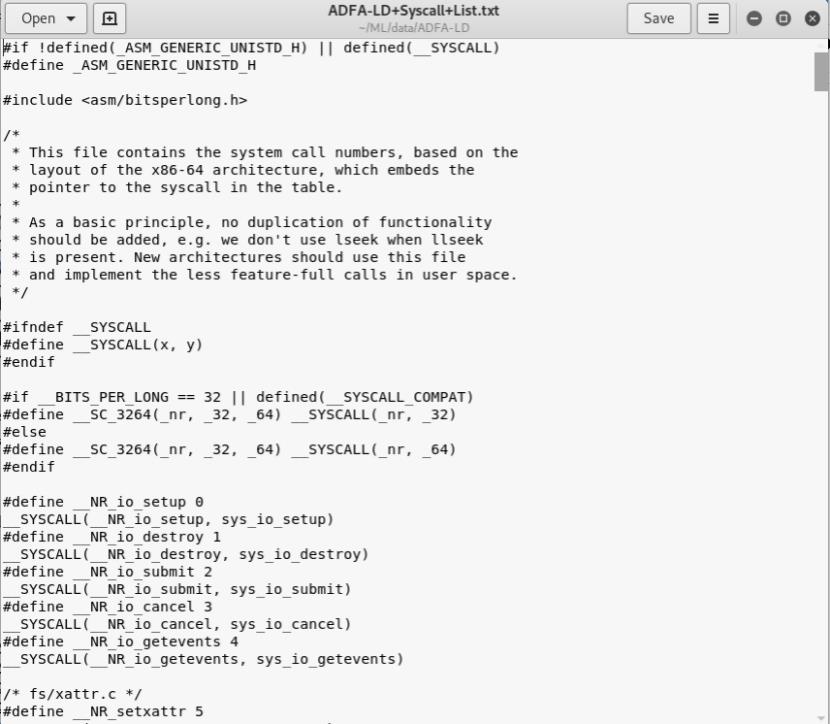
ADFA数据集已经对系统调用进行了处理,所以对于每一个系统调用函数,ADFA都已经用数字来编号了。对应的编号见ADFA-LD+Syscall+List.txt文件,如下所示
大概了解了数据集之后,我们来看看代码
读取数据部分:
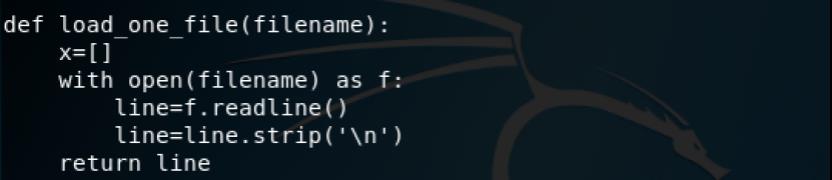
以下代码用于读取单个文件的内容
不过由于我们在数据集中看到webshell文件夹下都多个文件,所以我们需要遍历目录来依次读取,该功能由以下代码实现
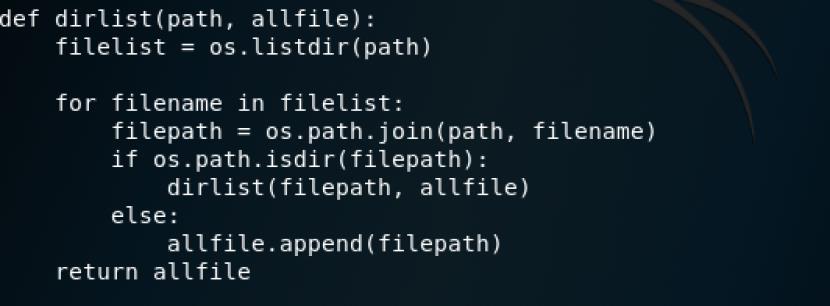
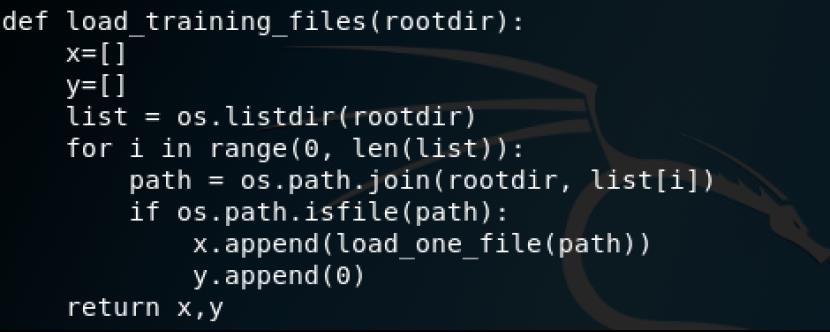
加载训练数据集
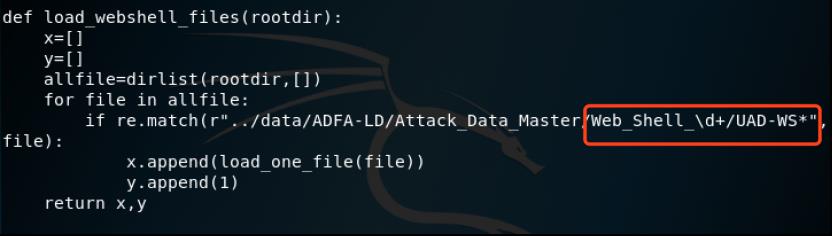
加载attack文件夹中的webshell数据集,这里注意一下红框标注中的正则表达式,这是为了匹配webshell相关文件
然后在main中分别调用上面这两个函数用于加载

然后通过词集模型进行处理,这里CountVectorizer类会将文本中的词语转换为词频矩阵,例如矩阵中包含一个元素a[i][j],它表示j词在i类文本下的词频。它通过fit_transform函数计算各个词语出现的次数,将list数据转为二维数组,通过toarray()可看到词频矩阵的结果,将每一行转换成由01组成的一维向量(关于词集模型的相关知识在《逻辑回归算法来检测java meterpreter》已经阐述,此处不再赘述)

然后就是实例化神经网络算法

MLPClassifier即Multi-layer Perceptron classifier,多层感知器分类器,该模型使用LBFGS或随机梯度下降来优化对数损失函数。这里的solver是用于指定进行权重优化的算法,我们这里指定为sgd。
最后采用10折交叉验证并打印结果
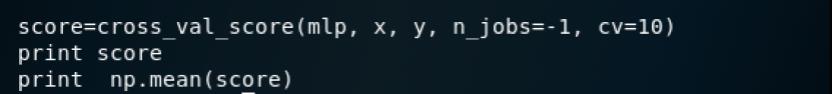
完整的代码在webshell.py,测试如下
得分如下

可以看到准确率大约达到了87.9%
参考
1.https://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPClassifier.html
2.https://zhuanlan.zhihu.com/p/65472471
3.https://www.jiqizhixin.com/articles/2017-11-02-26
4.https://scikit-learn.org/stable/modules/neural_networks_supervised.html
5.《机器学习与web安全》
6.https://github.com/duoergun0729/1book/
以上是关于神经网络检测webshell的主要内容,如果未能解决你的问题,请参考以下文章