从0到1Flink的成长之路(二十)-Flink 高级特性之存储 State 数据结构
Posted 熊老二-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从0到1Flink的成长之路(二十)-Flink 高级特性之存储 State 数据结构相关的知识,希望对你有一定的参考价值。
存储 State 数据结构
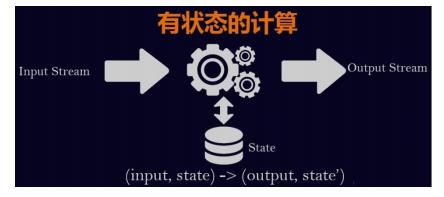
前面说过:有状态计算其实就是需要考虑历史数据,而历史数据需要搞个地方存储起来。
Flink为了方便不同分类的State的存储和管理,提供了如下API/数据结构来存储State。
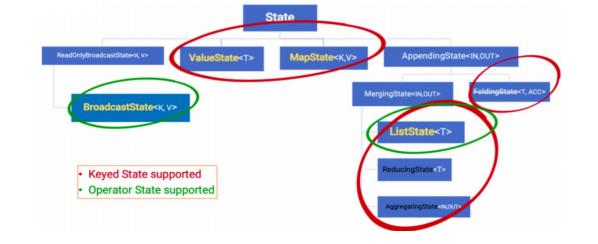
1)、Keyed State
Keyed State 通过 RuntimeContext 访问,这需要 Operator 是一个RichFunction。保存
Keyed state的数据结构: ValueState:即类型为T的单值状态。这个状态与对应的key绑定,是最简单的状态。它可以通过update方法更新状态值,通过value()方法获取状态值,如求按用户id统计用户交易总额
ListState:即key上的状态值为一个列表。可以通过add方法往列表中附加值;也可以通过get()方法返回一个Iterable来遍历状态值,如统计按用户id统计用户经常登录的IP
ReducingState:这种状态通过用户传入的reduceFunction,每次调用add方法添加值的时候,会调用reduceFunction,最后合并到一个单一的状态值
MapState<UK, UV>:即状态值为一个map,用户通过put或putAll方法添加元素需要注意的是,以上所述的State对象,仅仅用于与状态进行交互(更新、删除、清空等),而真正的状态值,有可能是存在内存、磁盘、或者其他分布式存储系统中,相当于只是持有了这个状态的句柄。
2)、Operator State
Operator State 需要自己实现 CheckpointedFunction 或 ListCheckpointed 接口,保存Operator state的数据结构:ListState和BroadcastState<K,V>。
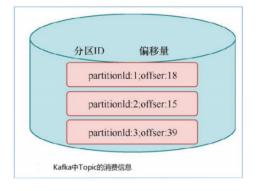
举例来说,Flink中的FlinkKafkaConsumer,就使用了operator state。它会在每个connector实例中,保存该实例中消费topic的所有(partition, offset)映射。
State 代码示例
1 Keyed State
下图以WordCount 的 sum 所使用的StreamGroupedReduce类为例,讲解了如何在代码中使用
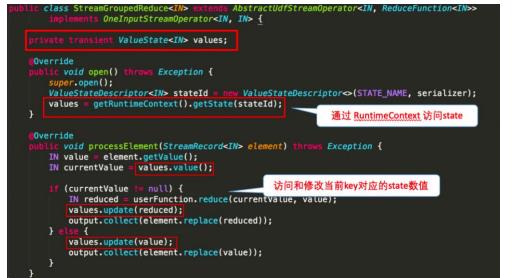
官网代码示例
managed-keyed-state
需求:
使用KeyState中的ValueState获取数据中的最大值(实际中直接使用maxBy即可)
编码步骤
//-1.定义一个状态用来存放最大值 private transient ValueState maxValueState;
//-2.创建一个状态描述符对象 ValueStateDescriptor descriptor = new
ValueStateDescriptor(“maxValueState”, Long.class); //-3.根据状态描述符获取State
maxValueState = getRuntimeContext().getState(maxValueStateDescriptor);
//-4.使用State Long historyValue = maxValueState.value(); //判断当前值和历史值谁大
if (historyValue == null || currentValue > historyValue) //-5.更新状态
maxValueState.update(currentValue);
代码示例
package xx.xxxxxx.flink.state;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/** Flink State 中KeyedState,默认情况下框架自己维护,此外可以手动维护 */
public class StreamKeyedStateDemo {
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 2. 数据源-source
DataStreamSource<Tuple3<String, String, Long>> tupleStream = env.fromElements(
Tuple3.of("上海", "普陀区", 488L), Tuple3.of("上海", "徐汇区", 212L),
Tuple3.of("北京", "西城区", 823L), Tuple3.of("北京", "海淀区", 234L),
Tuple3.of("上海", "杨浦区", 888L), Tuple3.of("上海", "浦东新区", 666L),
Tuple3.of("北京", "东城区", 323L), Tuple3.of("上海", "黄浦区", 111L)
);
// 3. 数据转换-transformation
// TODO:直接使用maxBy的状态,Flink自动维护了State
SingleOutputStreamOperator<Tuple3<String, String, Long>> maxOperator = tupleStream
.keyBy(0)
.maxBy(2);
/*
maxBy> (上海,普陀区,488)
maxBy> (上海,普陀区,488)
maxBy> (北京,西城区,823)
maxBy> (北京,西城区,823)
maxBy> (上海,杨浦区,888)
maxBy> (上海,杨浦区,888)
maxBy> (北京,西城区,823)
maxBy> (上海,杨浦区,888)
*/
maxOperator.printToErr("maxBy");
// TODO: 使用KeyedState中的ValueState来模拟maxBy的底层,手动维护状态
SingleOutputStreamOperator<String> stateOperator = tupleStream
.keyBy(0)
.map(new RichMapFunction<Tuple3<String, String, Long>, String>() {
// a. 定义一个状态存储最大值
private transient ValueState<Long> maxValueState;
@Override
public void open(Configuration parameters) throws Exception {
// b. 创建状态描述符
ValueStateDescriptor<Long> stateDescriptor = new ValueStateDescriptor<Long>(
"maxValueState", Long.class
);
// c. 实例化状态对象
maxValueState = getRuntimeContext().getState(stateDescriptor);
}
@Override
public String map(Tuple3<String, String, Long> value) throws Exception {
// d. 获取历史状态
Long historyValue = maxValueState.value();
// max 最大值比较
Long currentValue = value.f2;
if (null == historyValue || currentValue > historyValue) {
// e. 更新状态
maxValueState.update(currentValue);
return value.f0 + ", " + value.f1 + ", " + currentValue ; } else {
return value.f0 + ", " + value.f1 + ", " + historyValue ; } }
});
/*
state> 上海, 普陀区, 488
state> 上海, 徐汇区, 488
state> 北京, 西城区, 823
state> 北京, 海淀区, 823
state> 上海, 杨浦区, 888
state> 上海, 浦东新区, 888
state> 北京, 东城区, 823
state> 上海, 黄浦区, 888
*/
stateOperator.print("state");
// 5. 触发执行-execute
env.execute(StreamKeyedStateDemo.class.getSimpleName());
} }
2 Operator State
下图对WordCoun示例中的FromElementsFunction类进行详解并分享,如何在代码中使用operator state:
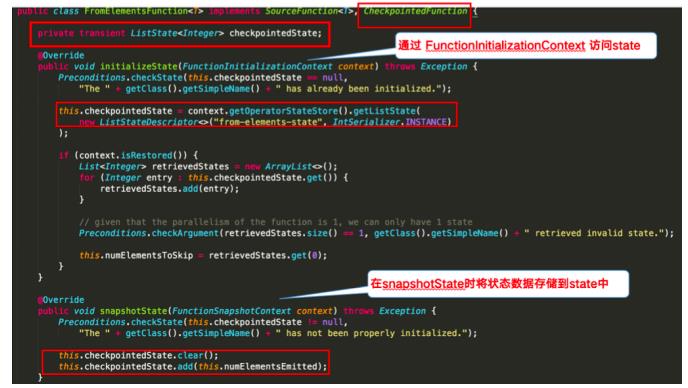
官网代码示例
managed-operator-state
需求:
使用ListState存储offset,模拟Kafka的offset维护
编码步骤:
//-1.声明一个OperatorState来记录offset private ListState offsetState =
null; private Long offset = 0L; //-2.创建状态描述器 ListStateDescriptor
descriptor = new ListStateDescriptor(“offsetState”, Long.class);
//-3.根据状态描述器获取State offsetState =
context.getOperatorStateStore().getListState(descriptor);
//-4.获取State中的值 Iterator iterator =
offsetState.get().iterator(); if (iterator.hasNext()) {//迭代器中有值
offset = iterator.next();//取出的值就是offset } offset += 1L;
ctx.collect(“subTaskId:” + getRuntimeContext().getIndexOfThisSubtask()
- “,当前的offset为:” + offset); if (offset % 5 == 0) {//每隔5条消息,模拟一个异常 //-5.保存State到Checkpoint中
offsetState.clear();//清理内存中存储的offset到Checkpoint中 //-6.将offset存入State中
offsetState.add(offset);
代码示例
package xx.xxxxx.flink.state;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import java.util.Arrays;
import java.util.concurrent.TimeUnit;
/**
* Flink State 中OperatorState,自定义数据源Kafka消费数据,保存消费偏移量数据并进行Checkpoint
*/
public class StateOperatorStateDemo {
/**
* 自定义数据源Source,模拟从Kafka消费数据(类似FlinkKafkaConsumer),并实现offset状态维护
*/
private static class FlinkKafkaSource extends RichParallelSourceFunction<String>
implements CheckpointedFunction {
private volatile boolean isRunning = true ;
// TODO:a. 声明OperatorState存储offset
private ListState<Long> offsetState = null ;
private Long offset = 0L ; @Override
public void initializeState(FunctionInitializationContext context) throws Exception {
// TODO: b. 创建状态描述
ListStateDescriptor<Long> descriptor = new ListStateDescriptor<>(
"offsetState", Long.class
);
// TODO: c. 实例化状态对象
offsetState = context.getOperatorStateStore().getListState(descriptor);
// 判断状态是否从Checkpoint或SnapShot恢复,是的话获取偏移量
if(context.isRestored()){
// TODO:d. 从State获取值
offset = offsetState.get().iterator().next();
} }
// 快照方法会在Checkpoint的时候执行,把当前的State存入到Checkpoint中
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
// TODO: e. 将状态数据保存至Checkpoint中
offsetState.clear();
// TODO: f. 将list存储State中
offsetState.update(Arrays.asList(offset));
}@Override
public void run(SourceContext<String> ctx) throws Exception {
while (isRunning){
// 获取索引,分区ID
int partitionId = getRuntimeContext().getIndexOfThisSubtask();
// 更新偏移量信息
offset = offset + 1L ;
// 输出操作
ctx.collect("partition: " + partitionId + ", offset: " + offset);
TimeUnit.SECONDS.sleep(1);
// 每隔5条消息,模拟一个异常
if(offset % 5 == 0){
throw new RuntimeException("程序出现异常,遇到Bug啦................") ; } } }@Override
public void cancel() {
isRunning = false ; } }
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// TODO: 设置检查点Checkpoint相关属性,保存状态
env.enableCheckpointing(1000) ; // 每隔1s执行一次Checkpoint
env.setStateBackend(new FsStateBackend("file:///D:/ckpt/")) ; // 状态数据保存本地文件系统
env.getCheckpointConfig().enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION
);// 当应用取消时,Checkpoint数据保存,不删除
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 固定延迟重启策略: 程序出现异常的时候,重启2次,每次延迟3秒钟重启,超过2次,程序退出
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(2, 3000));
// 2. 数据源-source
DataStreamSource<String> kafkaDataStream = env.addSource(new FlinkKafkaSource());
// 4. 数据终端-sink
kafkaDataStream.printToErr();
// 5. 触发执行-execute
env.execute(StateOperatorStateDemo.class.getSimpleName());
} }
以上是关于从0到1Flink的成长之路(二十)-Flink 高级特性之存储 State 数据结构的主要内容,如果未能解决你的问题,请参考以下文章
从0到1Flink的成长之路(二十)-Flink 高级特性之状态分类
从0到1Flink的成长之路(二十)-Flink 高级特性之Flink 状态管理
从0到1Flink的成长之路(二十)-Flink 高级特性之 Flink 容错机制