从0到1Flink的成长之路(二十)-Flink 高级特性之Flink 状态管理
Posted 熊老二-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从0到1Flink的成长之路(二十)-Flink 高级特性之Flink 状态管理相关的知识,希望对你有一定的参考价值。
Flink 状态管理
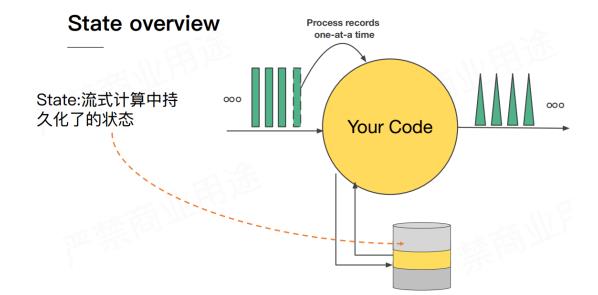
state
1 Flink 有状态计算
注意:Flink中已经对需要进行有状态计算的API,做了封装,底层已经维护好了状态!例如,之前下面代码,直接使用即可,不需要像SparkStreaming那样还得自己写updateStateByKey。
学习的State只需要掌握原理,实际开发中一般都是使用Flink底层维护好的状态或第三方维护好的状态(如Flink整合Kafka的offset维护底层就是使用的State,已经实现好的)。
package xx.xxxxx.flink.start;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* 使用Flink DataStream实现词频统计WordCount,从Socket Source读取数据。
*/
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 1. 执行环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
// 2. 数据源-source
DataStreamSource<String> lineDataStream = env.socketTextStream("node1.itcast.cn", 9999);
// 3. 数据转换-transformation
// 3.1 过滤数据,使用filter函数
SingleOutputStreamOperator<String> filterOperator = lineDataStream.filter(
new FilterFunction<String>() { @Override
public boolean filter(String line) throws Exception {
return null != line && line.trim().length() > 0; } }
);
// 3.2 转换数据,分割每行为单词
SingleOutputStreamOperator<String> wordOperator = filterOperator.flatMap(
new FlatMapFunction<String, String>() { @Override
public void flatMap(String line, Collector<String> out) throws Exception {
String[] words = line.trim().toLowerCase().split("\\\\W+");
for (String word : words) {
out.collect(word);
} } }
);
// 3.3 转换数据,每个单词变为二元组
SingleOutputStreamOperator<Tuple2<String, Integer>> tupleOperator = wordOperator.map(
new MapFunction<String, Tuple2<String, Integer>>() { @Override
public Tuple2<String, Integer> map(String word) throws Exception {
return Tuple2.of(word, 1);
} }
);
// 3.4 分组
SingleOutputStreamOperator<Tuple2<String, Integer>> countOperator = tupleOperator
.keyBy(0)
.sum(1);
// 4. 数据终端-sink
countOperator.printToErr();
// 5. 触发执行-execute
env.execute(StreamWordCount.class.getSimpleName());
} }
执行 netcat,然后在终端输入 spark flink,执行程序会输出什么?
答案很明显:(spark, 1)和 (flink,1)
那么问题来了,如果再次在终端输入 spark flink,程序会输入什么?
答案其实也很明显:(spark, 2)和(flink, 2)
为什么 Flink 知道之前已经处理过一次 spark和flink,这就是 state 发挥作用了,这里是被称为keyed state 存储了之前需要统计的数据,所以Flink 知道 spark 和 flink 分别出现过一次。
未完待续…
以上是关于从0到1Flink的成长之路(二十)-Flink 高级特性之Flink 状态管理的主要内容,如果未能解决你的问题,请参考以下文章