kafka 消费者分区分配策略
Posted 顧棟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka 消费者分区分配策略相关的知识,希望对你有一定的参考价值。
文章目录
kafka 消费者分区分配策略
Note:采用kafka1.1版本源码进行分析
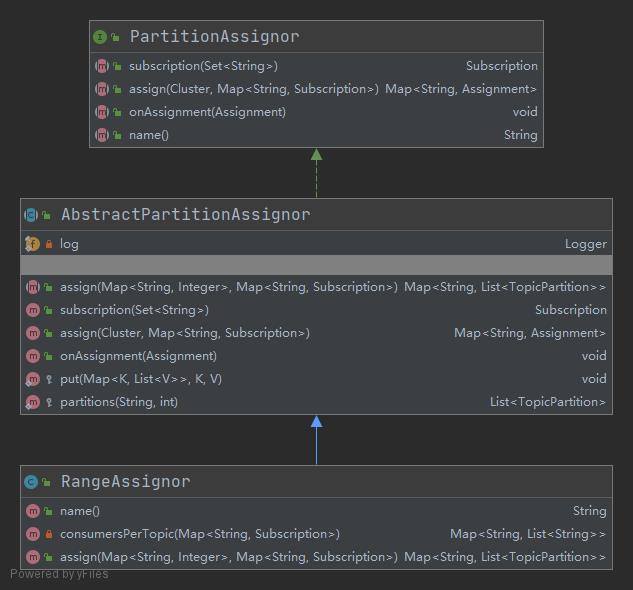
在消费者客户端中有一个参数配置partition.assignment.strategy,是用来配置消费者Client和Topic的分区分配策略,就是指消费者客户端消费订阅的topic的哪些分区,默认值是org.apache.kafka.clients.consumer.RangeAssignor,这是一个默认的分区分配策略。
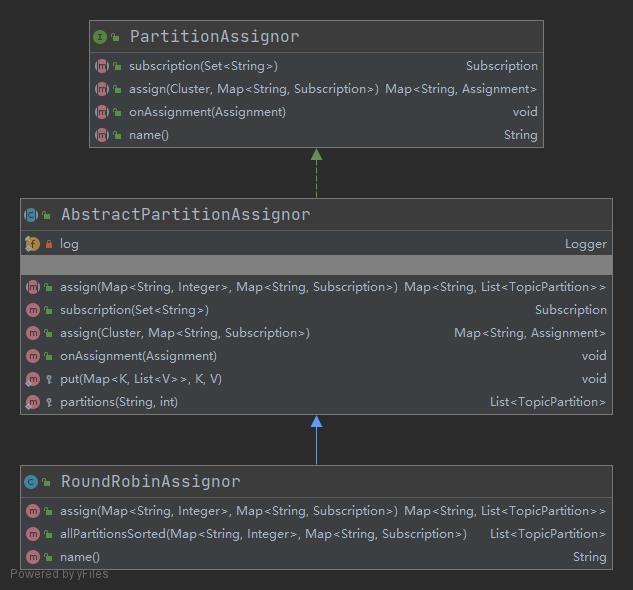
通过这个类的继承关系,可以发现其父类是一个实现了PartitionAssignor接口的抽象类AbstractPartitionAssignor。这个抽象类目前在1.1版本中一共有3个子类。
-
RangeAssignor
范围分配器
-
RoundRobinAssignor
轮询分配器
-
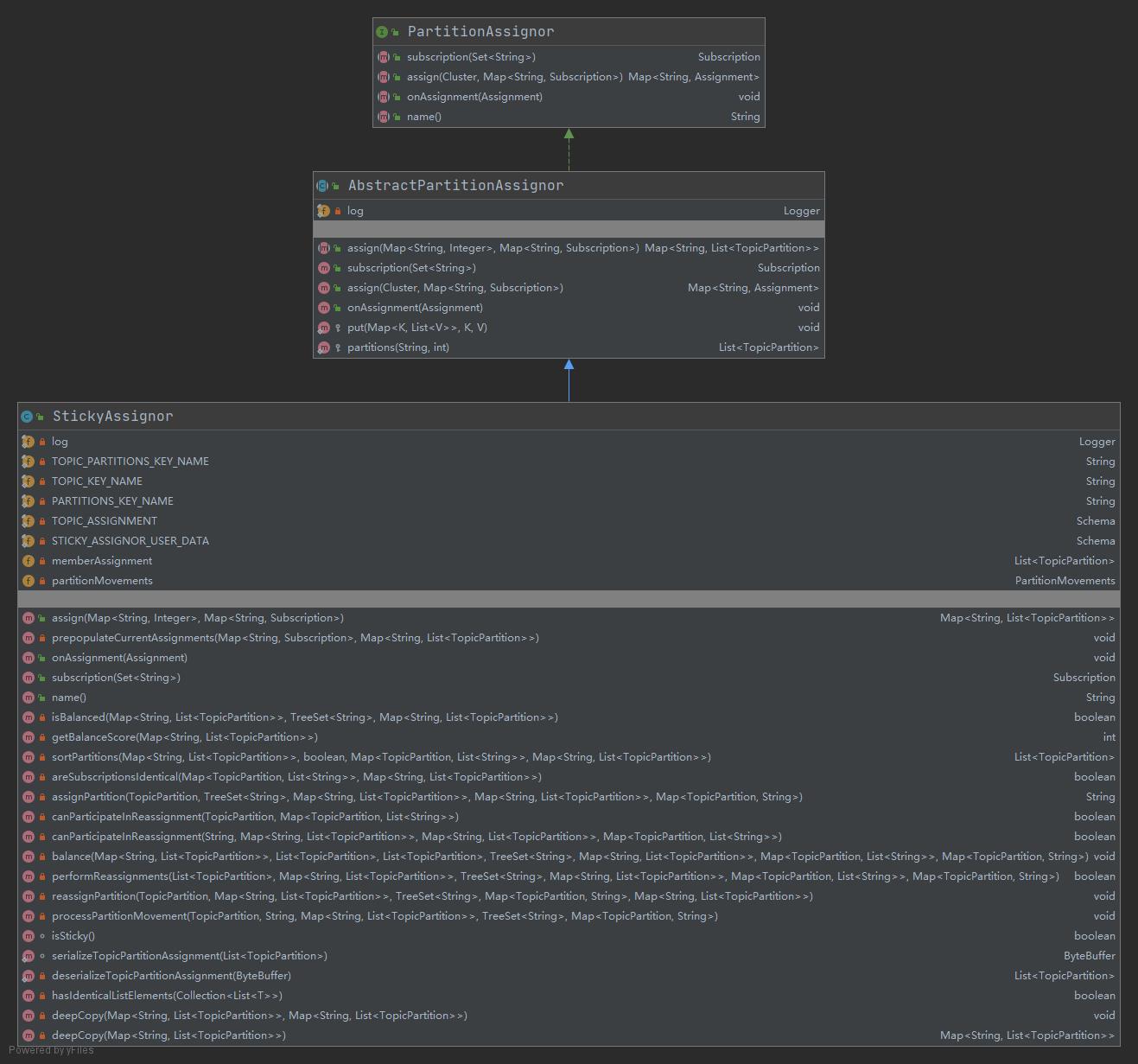
StickyAssignor
粘性分配器
以上分配器都重写在类AbstractPartitionAssignor中的抽象方法assign,这个方法是分配器具体的分配实现方法。
public abstract Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions);
- 入参
-
Map<String, Integer> partitionsPerTopic
key:topic
Value:分区数量(大于0)
-
Map<String, Subscription> subscriptions
key:numberid 消费者组协调器为消费者分配的组成员id,其值是Client与UUID的组合
val memberId = clientId + "-" + UUID.randomUUID().toStringvalue;Subscription 消费者订阅了哪些topic和自定义数据
- 结果
-
Map<String, Assignment> assignment
key:numberid,消费者的组成员id
Value:List<TopicPartition>,topic分区对象的列表
/**
* 构建出Topic分区对象列表
*
* @param topic Topic名称
* @param numPartitions 分区数量
* @return List<TopicPartition>
*/
protected static List<TopicPartition> partitions(String topic, int numPartitions) {
List<TopicPartition> partitions = new ArrayList<>(numPartitions);
for (int i = 0; i < numPartitions; i++)
partitions.add(new TopicPartition(topic, i));
return partitions;
}
范围分配 RangeAssignor
假设m=Topic的分区数/订阅这个Topic的消费者数量,n=Topic的分区数%订阅这个Topic的消费者数量。那么前m个消费者会订阅n+1个分区,剩余的消费者订阅n个分区。
数据演示
若有两个消费者C0和C1,两个拥有4个分区的Topic(t0,t1),分区列表为t0p0,t0p1,t0p2,t0p3,t1p0,t1p1,t1p2,t1p3
C0:[t0p0, t0p1, t1p0, t1p1]
C1:[t0p2, t0p3, tt1p2, t1p3]
若有两个消费者C0和C1,两个拥有3个分区的Topic(t0,t1),分区列表为t0p0,t0p1,t0p2,t1p0,t1p1,t1p2
C0:[t0p0, t0p1, t1p0, t1p1]
C1:[t0p2, t1p2]
部分源码分析
RangeAssignor类中的有个assign方法 这是用来计算分配的。
@Override
public Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
// 获取topic与消费者id关系的map, key为Topic Value为订阅这个topic的消费者的id的List
Map<String, List<String>> consumersPerTopic = consumersPerTopic(subscriptions);
Map<String, List<TopicPartition>> assignment = new HashMap<>();
for (String memberId : subscriptions.keySet())
assignment.put(memberId, new ArrayList<TopicPartition>());
for (Map.Entry<String, List<String>> topicEntry : consumersPerTopic.entrySet()) {
String topic = topicEntry.getKey();
List<String> consumersForTopic = topicEntry.getValue();
// 获取每个Topic的partition数量
Integer numPartitionsForTopic = partitionsPerTopic.get(topic);
if (numPartitionsForTopic == null)
continue;
// 对Topic的消费者的id进行升序排序
Collections.sort(consumersForTopic);
// Topic的分区数/订阅这个Topic的消费者数量的整数商
int numPartitionsPerConsumer = numPartitionsForTopic / consumersForTopic.size();
// Topic的分区数%订阅这个Topic的消费者数量的余数
int consumersWithExtraPartition = numPartitionsForTopic % consumersForTopic.size();
// 构建主题分区列表
List<TopicPartition> partitions = AbstractPartitionAssignor.partitions(topic, numPartitionsForTopic);
for (int i = 0, n = consumersForTopic.size(); i < n; i++) {
int start = numPartitionsPerConsumer * i + Math.min(i, consumersWithExtraPartition);
int length = numPartitionsPerConsumer + (i + 1 > consumersWithExtraPartition ? 0 : 1);
assignment.get(consumersForTopic.get(i)).addAll(partitions.subList(start, start + length));
}
}
return assignment;
}
轮询分配RoundRobinAssignor
将所有的Topic分区进行排序后,依次遍历Topic分区,轮询所有的消费者依次为这些Topic分区分配消费者。
数据演示
若有两个消费者C0和C1,两个拥有3个分区的Topic(t0,t1),分区列表为t0p0, t0p1, t0p2, t1p0, t1p1, t1p2
C0:[t0p0, t0p2, t1p1]
C1:[t0p1, t1p0, t1p2]
若有3个消费者C0,C1,C2,有3个Topic(t0, t1, t2),分区列表为t0p0,t1p0,t1p1,t2p0, t2p1, t2p2
C0: [t0p0]
C1: [t1p0]
C2: [t1p1, t2p0, t2p1, t2p2]
部分源码分析
public Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
Map<String, List<TopicPartition>> assignment = new HashMap<>();
for (String memberId : subscriptions.keySet())
assignment.put(memberId, new ArrayList<TopicPartition>());
// 循环迭代器- 根据消费者id进行排序 升序
CircularIterator<String> assigner = new CircularIterator<>(Utils.sorted(subscriptions.keySet()));
// 根据Topics排序,在获取每个topic的分区数,确保顺序的一致性,遍历分区
for (TopicPartition partition : allPartitionsSorted(partitionsPerTopic, subscriptions)) {
final String topic = partition.topic();
// 寻找订阅了这个topic的消费者,为消费者分配这个topic的分区
while (!subscriptions.get(assigner.peek()).topics().contains(topic))
assigner.next();
assignment.get(assigner.next()).add(partition);
}
return assignment;
}
对Topic进行排序去重,根据Topic的顺序进行其下分区的创建填充分区列表。
public List<TopicPartition> allPartitionsSorted(Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
SortedSet<String> topics = new TreeSet<>();
for (Subscription subscription : subscriptions.values())
topics.addAll(subscription.topics());
List<TopicPartition> allPartitions = new ArrayList<>();
for (String topic : topics) {
Integer numPartitionsForTopic = partitionsPerTopic.get(topic);
if (numPartitionsForTopic != null)
allPartitions.addAll(AbstractPartitionAssignor.partitions(topic, numPartitionsForTopic));
}
return allPartitions;
}
循环的迭代器
public class CircularIterator<T> implements Iterator<T> {
int i = 0; // 下标
private List<T> list; // 数据项
public CircularIterator(List<T> list) {
if (list.isEmpty()) {
throw new IllegalArgumentException("CircularIterator can only be used on non-empty lists");
}
this.list = list;
}
@Override
public boolean hasNext() {
return true;
}
/**
* 任何遍历 下标+1后与元素数量取模 i的取值在 [0,size-1]中循环
*/
@Override
public T next() {
T next = list.get(i);
i = (i + 1) % list.size();
return next;
}
/**
* 获取元素
*/
public T peek() {
return list.get(i);
}
/**
* 不支持移除元素
*/
@Override
public void remove() {
throw new UnsupportedOperationException();
}
}
粘性分配法 StickyAssignor
使用黏性分配法是为了以下两点,第一点的优先级高于第二点。
- 是的分区和消费者的分配尽量均衡
- 尽可能的对上次的分配结果不进行大的调整
数据演示
原来的 3个消费者(C0,C1,C2),3个Topic(t0,t1,t2),分区列表 t0p0,t1p0,t1p1,t2p0,t2p1,t2p1,C0没有订阅t1,t2
C0: t0p0
C1:t1p0,t1p1
C2:t2p0,t2p1,t2p1
现在C0下线,重新分配
C1:t1p0,t1p1, t0p0
C2:t2p0,t2p1,t2p1
结果中原来的分区并没有动,而是将 t0p0分配给了分区数少的C1,使得分配变得均衡和尽可能不改变原来的分配结果。这样优化了在再分配分区时造成的重复消费和资源浪费,以及减少其他异常的发生。
分配主流程
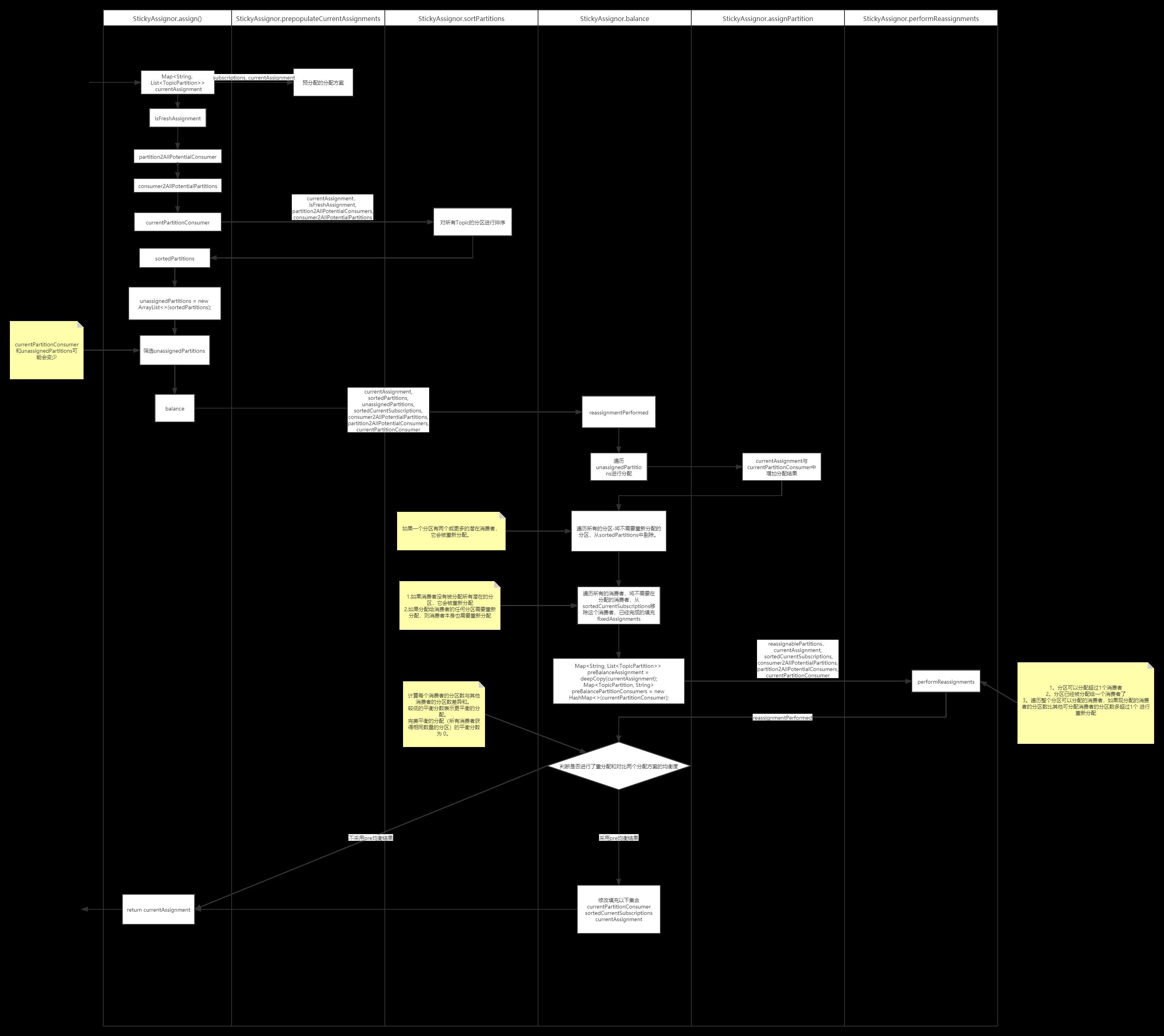
部分源码分析
public Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
Map<String, List<TopicPartition>> currentAssignment = new HashMap<>();
partitionMovements = new PartitionMovements();
// 预分配的分配方案--此时的currentAssignment中是通过Subscription中的UserData来确认分配的
prepopulateCurrentAssignments(subscriptions, currentAssignment);
// 如果预分配的结果为空,表明是一个全新的分配
boolean isFreshAssignment = currentAssignment.isEmpty();
// a mapping of all topic partitions to all consumers that can be assigned to them
// key为分区 Value是消费者id的list
final Map<TopicPartition, List<String>> partition2AllPotentialConsumers = new HashMap<>();
// a mapping of all consumers to all potential topic partitions that can be assigned to them
// key为消费者id Value为分区的list
final Map<String, List<TopicPartition>> consumer2AllPotentialPartitions = new HashMap<>();
// initialize partition2AllPotentialConsumers and consumer2AllPotentialPartitions in the following two for loops
// 遍历topic与分区数的Map,为partition2AllPotentialConsumers填充值,每个分区都是一个map的key,此时Value是空
for (Entry<String, Integer> entry: partitionsPerTopic.entrySet()) {
for (int i = 0; i < entry.getValue(); ++i)
partition2AllPotentialConsumers.put(new TopicPartition(entry.getKey(), i), new ArrayList<String>());
}
// 遍历消费者与订阅的topic关系的map
for (Entry<String, Subscription> entry: subscriptions.entrySet()) {
String consumer = entry.getKey();
// 取出消费者的id,每个消费者都是consumer2AllPotentialPartitions的一个key,此时对应的Value是空
consumer2AllPotentialPartitions.put(consumer, new ArrayList<TopicPartition>());
// 遍历每个消费者订阅的topics
for (String topic: entry.getValue().topics()) {
// 获取每个topic的分区数,遍历每个分区
for (int i = 0; i < partitionsPerTopic.get(topic); ++i) {
TopicPartition topicPartition = new TopicPartition(topic, i);
// 为consumer2AllPotentialPartitions每个消费者填充Value中的分区数
consumer2AllPotentialPartitions.get(consumer).add(topicPartition);
// 为partition2AllPotentialConsumers中每个分区填充Value中的消费者
partition2AllPotentialConsumers.get(topicPartition).add(consumer);
}
}
// add this consumer to currentAssignment (with an empty topic partition assignment) if it does not already exist
// 一般不是全新分配的时候 没有currentAssignment中没有元素,需要填充每个消费者进行初始化
if (!currentAssignment.containsKey(consumer))
currentAssignment.put(consumer, new ArrayList<TopicPartition>());
}
// a mapping of partition to current consumer
// 现有的每个分区与对应消费者的Map
Map<TopicPartition, String> currentPartitionConsumer = new HashMap<>();
//遍历现有的分配结果
for (Map.Entry<String, List<TopicPartition>> entry: currentAssignment.entrySet())
// 遍历每一个分区
for (TopicPartition topicPartition: entry.getValue())
// 填充currentPartitionConsumer,key是分区,Value是消费者id
currentPartitionConsumer.put(topicPartition, entry.getKey());
List<TopicPartition> sortedPartitions = sortPartitions(
currentAssignment, isFreshAssignment, partition2AllPotentialConsumers, consumer2AllPotentialPartitions);
// all partitions that need to be assigned (initially set to all partitions but adjusted in the following loop)
// 将需要进行分配的分区列表
List<TopicPartition> unassignedPartitions = new ArrayList<>(sortedPartitions);
// 遍历分配结果
for (Iterator<Map.Entry<String, List<TopicPartition>>> it = currentAssignment.entrySet().iterator(); it.hasNext();) {
Map.Entry<String, List<TopicPartition>> entry = it.next();
// 如果分配结果中的消费者不存在了则清除这个消费者的订阅的topic的分区数
if (!subscriptions.containsKey(entry.getKey())) {
// if a consumer that existed before (and had some partition assignments) is now removed, remove it from currentAssignment
for (TopicPartition topicPartition: entry.getValue())
currentPartitionConsumer.remove(topicPartition);
it.remove();
} else {
// otherwise (the consumer still exists)
// 遍历消费者的分配的分区们
for (Iterator<TopicPartition> partitionIter = entry.getValue().iterator(); partitionIter.hasNext();) {
TopicPartition partition = partitionIter.next();
// 如果此消费者的此主题分区不再存在,则将其从消费者的 currentAssignment 中删除
if (!partition2AllPotentialConsumers.containsKey(partition)) {
// if this topic partition of this consumer no longer exists remove it from currentAssignment of the consumer
partitionIter.remove();
currentPartitionConsumer.remove(partition);
}
// 如果原来消费者订阅的主题与分区的主题不对应 则为currentAssignment的消费者删除该分区
else if (!subscriptions.get(entry.getKey()).topics().contains(partition.topic())) {
// if this partition cannot remain assigned to its current consumer because the consumer
// is no longer subscribed to its topic remove it from currentAssignment of the consumer
partitionIter.remove();
}
// 说明此分区不需要调整,保持原有的分配结果,从需要分配分区的集合中删除它
else
// otherwise, remove the topic partition from those that need to be assigned only if
// its current consumer is still subscribed to its topic (because it is already assigned
// and we would want to preserve that assignment as much as possible)
unassignedPartitions.remove(partition);
}
}
}
// at this point we have preserved all valid topic partition to consumer assignments and removed
// all invalid topic partitions and invalid consumers. Now we need to assign unassignedPartitions
// to consumers so that the topic partition assignments are as balanced as possible.
// an ascending sorted set of consumers based on how many topic partitions are already assigned to them
TreeSet<String> sortedCurrentSubscriptions = new TreeSet<>(new SubscriptionComparator(currentAssignment));
sortedCurrentSubscriptions.addAll(currentAssignment.keySet());
balance(currentAssignment, sortedPartitions, unassignedPartitions, sortedCurrentSubscriptions,
consumer2AllPotentialPartitions, partition2AllPotentialConsum以上是关于kafka 消费者分区分配策略的主要内容,如果未能解决你的问题,请参考以下文章