Zookeeper详细解析+简单实例
Posted 甜_tian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zookeeper详细解析+简单实例相关的知识,希望对你有一定的参考价值。
zookeeper的搭建请移步这里https://blog.csdn.net/weixin_39033058/article/details/117705815
目录
zookeeper概念:
zookeeper是一个主从分布式框架,对其它的分布式框架提供协调服务。
zookeeper有一个文件系统存储数据,可以维护和监控存储数据的状态变化,管理集群。
主要用来解决分布式集群中应用系统的一致性问题。
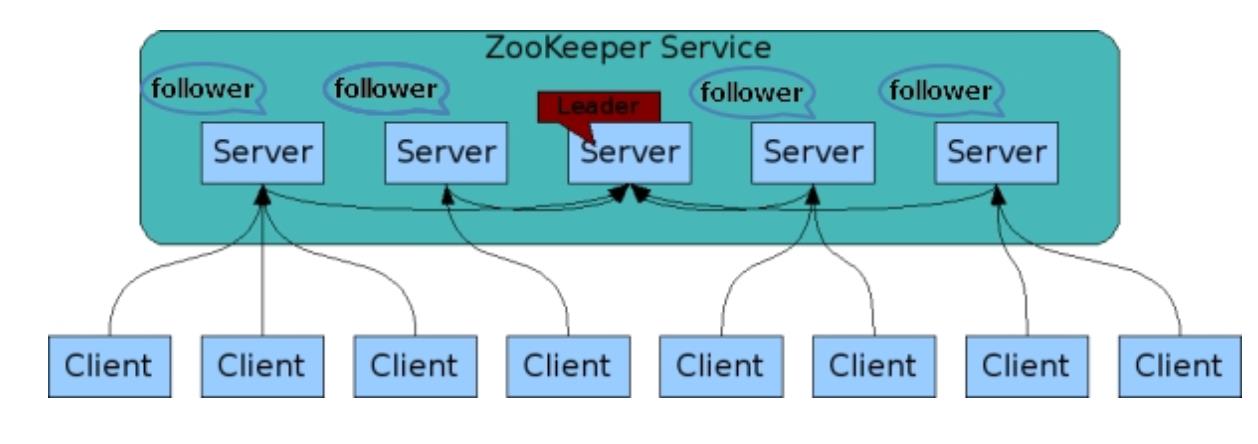
zk的数据结构:
主要是 文件系统(树状) + 原语 + watcher监听器机制
session会话:
客户端和集群的节点,创建的Tcp的长链接就是session会话。在一个session中,多个请求保持fifo(先进先出)的顺序
事务:
每个请求会生成一个事务,每个事务有一个全局唯一的事务id,id自增
分布式通信方式:
1.网络连接,两个节点通过网络连接的方式通信
2.共享存储,简单来说就是,假如有node1和node2两个节点要进行通信,node1向一个存储器发送信息,node2节点轮询存储器的数据,实现通信,这样就是共享存储。
zookeeper使用第二种
为什么要使用zookeeper:
现在的分布式框架是由多个独立的程序组成,协同工作比较复杂,耗费过多精力,需要有一个工具去统一管理,解决协同工作的问题。
zookeeper简单易用,可以很好的解决上述问题。
比如:集群的主备切换(例如hdfs配置两个namenode,一个处于活跃状态,一个是待命状态,当活跃状态的namenode突然宕机,zk可以很快检测到,并切换另一个namenode,用户无感知。)
节点上下线的感知(集群中有若干个服务器,当有新的服务器添加上,zk可以及时感知到)
统一命名服务,状态同步服务,集群管理,分布式应用配置管理,分布式锁等等协调问题
zookeeper客户端:
启动客户端有两种方式:1.zkcli命令行 ,2.代码形式
命令行模式:
启动客户端,在zk的bin目录下运行以下命令:
sh zkCli.sh -server hdp-1:2181,hdp-2:2181,hdp-3:2181server后追加多个节点的目的是,如果客户端连接某个节点失败,则下一个节点重试
如下则是启动成功:
![]()
使用Help 查看命令的使用方式:
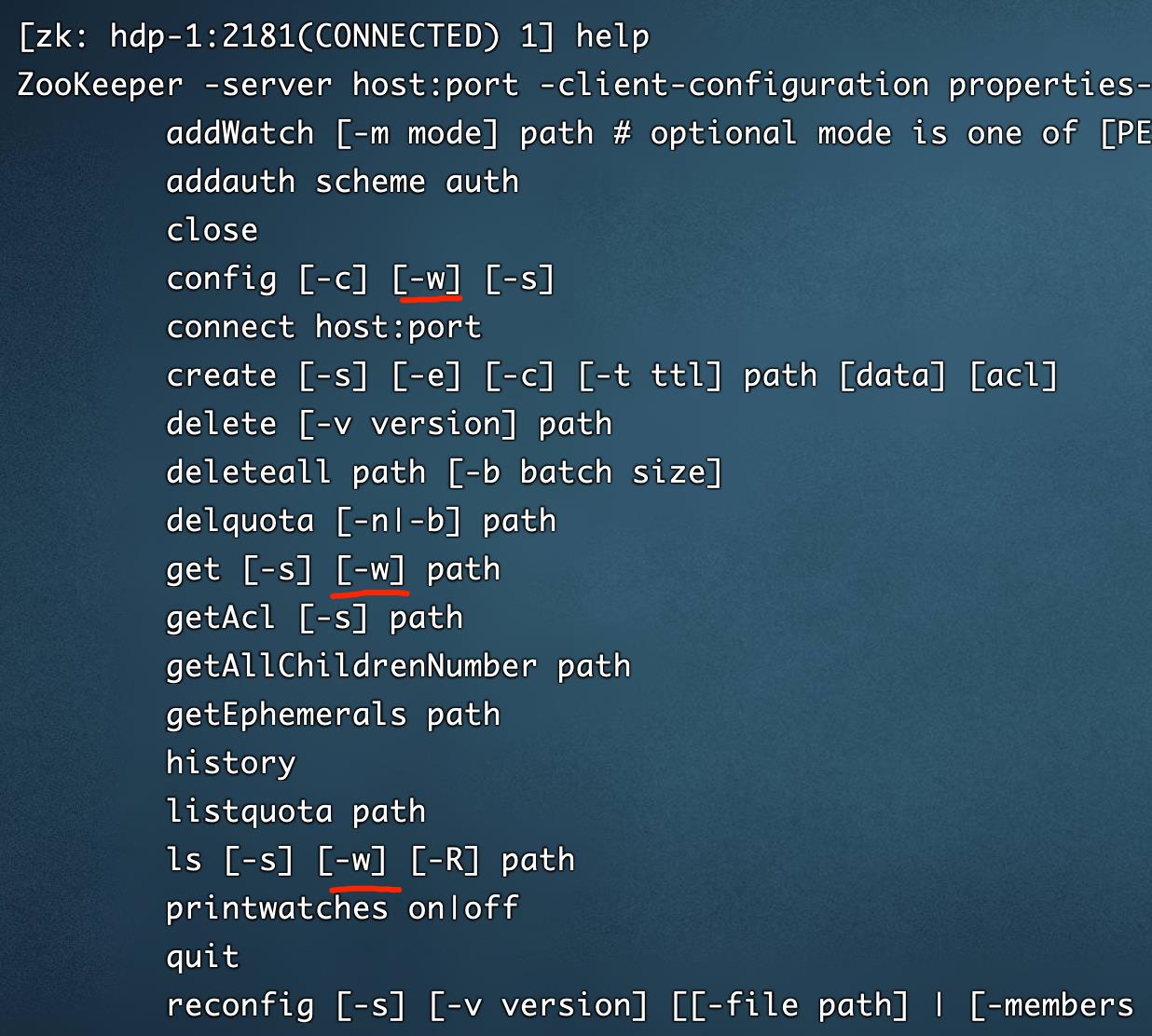
可以看到列出来的有很多命令,create创建,ls查看等等
[-w] 是可以创建watcher监听器的标识,后面详细说明作用。在zk中比较重要。
Ls / 查看根目录下的znode,也就是zk下的节点,

这是我根目录下的znode
代码模式:
maven依赖:
<dependencies>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.13</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.3.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>代码:
简单写了一些
public class CuratorClientTest {
private static final String ZK_ADDRESS="node01:2181,node02:2181,node03:2181";
private static final String ZK_PATH = "/zk_test";
private static final String ZK_PATH01 = "/beijing/goddess/anzhulababy";
private static final String ZK_PATH02 = "/beijing/goddess";
//初始化,建立连接
@Before
public void init() {
//重试连接策略,失败重试次数;每次休眠5000毫秒
//RetryPolicy policy = new ExponentialBackoffRetry(3000, 3);
RetryNTimes retryPolicy = new RetryNTimes(10, 5000);
// 1.设置客户端参数,参数1:指定连接的服务器集端口列表;参数2:重试策略
client = CuratorFrameworkFactory.newClient(ZK_ADDRESS, retryPolicy);
//启动客户端,连接到zk集群
client.start();
System.out.println("zookeeper客户端启动成功");
}
static CuratorFramework client = null;
@After
//关闭连接
public void clean() {
System.out.println("close session");
client.close();
}
@Test
public void createPersistentZNode() throws Exception {
String zNodeData = "小甜";
///a/b/c
// 创建永久节点
client.create().
creatingParentsIfNeeded(). //如果父目录不存在,则创建
withMode(CreateMode.PERSISTENT). //创建永久节点
forPath(ZK_PATH01, zNodeData.getBytes());//指定路径及节点数据
// 创建临时节点
client.create().
creatingParentsIfNeeded().
withMode(CreateMode.EPHEMERAL).
forPath("/beijing/star", zNodeData2.getBytes());
// 查看子znode
client.getChildren().forPath("/");
//查询节点数据
client.getData().forPath(ZK_PATH01)
// 修改节点数据
client.setData().forPath(ZK_PATH01, data2.getBytes());
// 删除节点
client.delete().forPath(ZK_PATH01);
}
} @Test
//监听ZNode
public void watchZNode() throws Exception {
//cache: TreeCache\\PathChildrenCache\\DataCache
/**
* TreeCache:可以将指定的路径节点作为根节点,对其所有的子节点操作进行监听,呈现树形目录的监听
* PathChildrenCache:监听节点下一级子节点的增、删、改操作
* NodeCache:监听节点对应增、删、改操作
*
* TreeCache:将指定的path下所有的子znode的数据缓存起来;
* 该类将监控path,可监控更新、创建、删除、获取数据等事件
* 可以注册一个监听器,当以上事件发生时,将都到通知
*/
//设置节点的cache
TreeCache treeCache = new TreeCache(client, ZK_PATH02);
//设置监听器、及收到通知后的处理过程
treeCache.getListenable().addListener(new TreeCacheListener() {
@Override
public void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {
ChildData data = event.getData();
if (data != null) {
switch (event.getType()) {
case NODE_ADDED:
System.out.println("NODE_ADDED : " + data.getPath() + " 数据:" + new String(data.getData()));
break;
case NODE_REMOVED:
System.out.println("NODE_REMOVED : " + data.getPath() + " 数据:" + new String(data.getData()));
break;
case NODE_UPDATED:
System.out.println("NODE_UPDATED : " + data.getPath() + " 数据:" + new String(data.getData()));
break;
default:
break;
}
} else {
System.out.println("data is null : " + event.getType());
}
}
});
//开始监听
treeCache.start();
Thread.sleep(10000);
//关闭cache
System.out.println("关闭treeCache");
treeCache.close();
}znode节点:
类型分为持久化节点和临时节点两大类,往下又分为无序和有序节点
持久化节点:
除非Delete,否则这个节点永久存在
create path data 去创建节点,则是持久化节点
create /test test临时节点:
当创建临时节点的客户端和服务器关闭后,临时节点被删除
create -e path data 临时节点
create -e /test test创建的节点,每个zk服务器都存在,并不是在某个节点创建就只存在于某个节点
有序节点:
防止不同的客户端在同一目录下,创建同名的znode,重名导致创建失败。会在同名的znode后,加上序号
create -s path data(持久化)
create -s /test test无序节点:
普通节点就是无序节点
watcher监听与通知:
watcher可以监听到znode数据的修改,节点的增删,监听到事件后,watcher会通知客户端
客户端想要获取zookeeper服务器上znode最新数据有以下两种方式:
1,轮询,客户端一直轮询的访问zookeeper是否有最新数据的产生(代价大)
2,通知,在节点下创建一个监听器,如果有znode数据变化,那么就会通知客户端
举个很简单的例子:
在第一个客户端创建一个节点
create /zk_test test在第二个客户端监听这个节点
ls /zk_test watch在第一个客户端,在zk_test节点下创建一个子节点
create /zk_test/node1 node1此时,第二个客户端收到到了zk_test节点有所变化的通知

要注意的是,zookeeper原生监听器只监听一次,第二次再有修改就不会监听到。
zookeeper的读写操作:
首先搞清楚几个概念:
- quorum 是zookeeper的一种投票方式,当发起proposal时,只要多数派同意,即可生效。多数派指的是,意思是至少过半的节点响应,才可以进行下面的操作。quorum数 = 节点数/2 +1
- 为了保证事务的顺序一致性,ZooKeeper采用了递增的事务id号(zxid)来标识事务,所有提议(proposal)都有zxid
- 每次事务的提交,必须符合quorum多数派
- leader选举投票vote的信息结构为(sid,zxid),sid是节点的id,zxid是事务id。选举leader的规则是zxid大的server胜出,若zxid相等,sid大的胜出。zxid数值大,说明是最新更新。
读操作:
读操作比较简单,客户端与某个zookeeper服务建立session,从这个服务器读取数据,返回给客户端,最后关闭session
写操作:
写操作相对复杂些
1.客户端向zookeeper集群写入数据,与一个follower建立Session连接,假设为follower01
2.follower01将写请求转发给leader
3.leader收到消息后,把本次写入操作,转化为事务proposal提案发送给每个follower,每个follower先记录下要本次写入操作
4.超过半数quorum(包括leader自己)发回反馈,则leader提交commit提案,leader执行写入操作
5.leader通知所有follower,也commit提案,follower各自在本地写入
6.follower01响应客户端
zookeeper的zab算法
ZAB是原子广播协议。在zookeeper中,主要依赖ZAB协议来实现分布式数据一致性,基于该协议,zookeeper实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
协议Zab协议有两种模式,它们分别是:
-
①恢复模式(选主):因为ZooKeeper也是主从架构;当ZooKeeper集群没有主的角色leader时,从众多服务器中选举leader时,处于此模式;
-
②广播模式(同步):当集群有了leader后,客户端向ZooKeeper集群读写数据时,集群处于此模式;
当发生脑裂时,zookeeper是如何解决的:
1.首先我们搞清楚,脑裂是什么?
脑裂简单来说,就是集群中出现了两个leader
2.是如何出现的?
网络通信故障,集群被分为了两部分。
假设我们有五个节点,其中三台可以正常通信,而另外两台因为网络原因,无法与别的机器通信,所以,整个集群被分割成了两部分。两部分同时进行leader选取,自然出现了两个leader。
3.zookeeper是如何解决的?
前面有提到过,zookeeper提交的每次proposal,都至少需要过半的节点响应,操作才会进行下去。
当发生网络分区后,三台节点的leader,我们称之为leader1。而因为网络原因分割出去的两个节点,选举出来的leader,我们称之为leader2。
这时有两个客户端,c1和c2,c1请求leader1写入一个znode为1。c2请求leader2写入一个znode为2。
c1的请求,leader1向另外两个节点发出proposal,两个节点响应加上leader本身,quorum = 3,符合多数派原则,则操作生效,同步到另外两个节点。
c2的请求,leader2往另一个节点发出proposal,quorum = 2,不符合多数派原则,操作则不生效。
所以,因为网络原因导致的两个leader,只有一个操作会生效。
当网络修复后,leader1的zxid肯定比leader2大,leader2变为follower状态,leader1同步操作。
码字真的太累了!!!!
以上是关于Zookeeper详细解析+简单实例的主要内容,如果未能解决你的问题,请参考以下文章
Zookeeper 详细解析!分布式架构中的协调服务框架的最佳选型
Zookeeper详细使用解析!分布式架构中的协调服务框架最佳选型实践
Android 逆向使用 Python 解析 ELF 文件 ( Capstone 反汇编 ELF 文件中的机器码数据 | 创建反汇编解析器实例对象 | 设置汇编解析器显示细节 )(代码片段