cgb2105-day03
Posted cgblpx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了cgb2105-day03相关的知识,希望对你有一定的参考价值。
文章目录
一,统计练习
–1,代码
#统计 名字里包含a的员工人数
select * from emp
select count(1) from emp where ename like '%a%'
#统计 普通员工 的平均工资
select avg(sal) from emp where job='员工'
#统计 2019年入职的员工的总人数
select count(1) from emp where year(hiredate)=2019
#统计 2号部门每年的工资开销
select sum(sal+ ifnull(comm,0) )*12 年开销 from emp where deptno=2
二,分组
–1,概述
使用group by实现分组,使用having在分组后的结果上继续添加过滤条件
–2,测试
#分组 group by 字段名 -- 按照指定字段分组
#如果查询时,出现了聚合列和非聚合列,通常要按照非聚合列分组
#查询 每个部门里 的最高薪和人名
select deptno,ename,max(sal) from emp
group by deptno
#查询 每种岗位 的平均工资和岗位名称
select avg(sal),job from emp group by job #按非聚合列分组
#查询 每个部门 的平均工资
select avg(sal) from emp group by deptno #分析需求,要按照部门分组
#统计 部门 出现的次数
select count(1) from emp GROUP BY deptno
#having 在分组后的结果中,继续添加过滤条件
#查询 每种岗位 的平均工资和岗位名称 --进一步查员工的
select avg(sal),job from emp
#where job='员工' #分组前需要过滤,使用where --高效
group by job
#having job='员工' #分组后需要过滤,使用having --相对低效
#统计 部门 出现的次数--再过滤次数>1的
select count(1),deptno from emp
#where count(1) > 1 #分组前过滤用where,但是where里不能出现聚合函数
group by deptno
having count(1) > 1 #分组后过滤用having
#查询 每个部门 的平均工资 --再过滤>10000的
select avg(sal),deptno from emp
#where avg(sal)>10000 #where里不能有聚合函数
group by deptno
having avg(sal)>10000 #分组后过滤having
三,事务
–1,概述
能保证多条SQL要么全成功要么全失败
4个特性:ACID
原子性:多个SQL处于同一个事务里,要么全成功要么全失败
一致性:保证数据在不同的电脑里是一致的
隔离性:数据库支持并发访问,保证事务间是隔离的,互不影响
持久性:对数据库的操作是永久的
–2,事务的隔离级别
读未提交:性能最好,数据的安全性最差
读提交:Oracle的默认的隔离级别 – 性能较好,安全性较差
可重复读:mysql的默认的隔离级别 – 性能较差,安全性较好
串行化:安全性最高,但是表级的锁,效率低
–3,事务的处理
#Mysql默认就开启了事务,但是每条SQL一个事务
begin;#开启事务
insert into dept values(null,'java开发部','北京');
insert into dept values(null,'php开发部','上海');
commit;#提交事务--会对数据库产生持久影响
#rollback;#回滚事务--不会对数据库产生持久影响
四,字段约束
–1,概述
外键约束:把两张表之间的关系,通过两个表的主键来表示
默认约束:给指定的字段设置默认值
检查约束:给字段增加检查条件,符合才能操作,不符合不能操作
–2,测试
create table h(
id int primary key auto_increment,
sex char(3) default '女' #default设置默认值,给指定的字段设置默认值
)
create table i(
id int primary key auto_increment,
age int,
check(age>0 and age<=150)#检查约束:给字段增加检查条件,符合才能操作,不符合不能操作
)
–3,外键约束
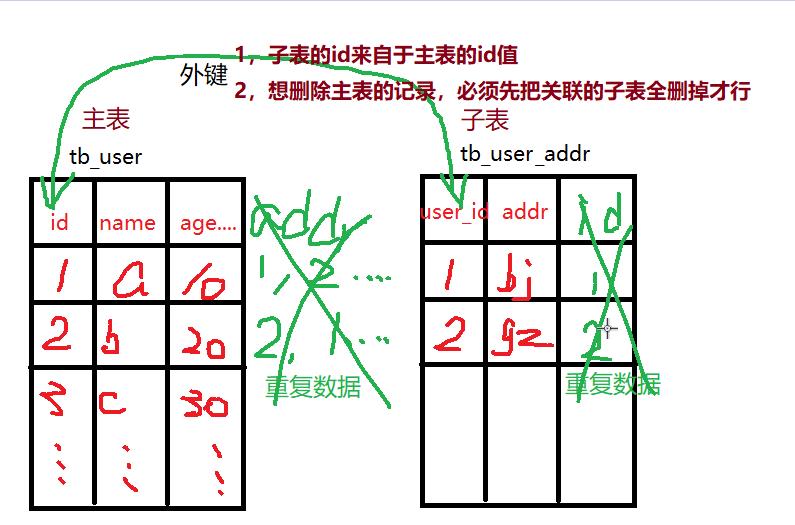
#外键约束
create table tb_user(
id int primary key auto_increment,
name varchar(20),
age int
)
create table tb_user_addr(
user_id int primary key auto_increment,
addr varchar(200) ,
#描述了两张表之间通过哪个字段关联着--外键约束
# 外键 (子表的字段) 参考 主表名称(主表的字段)
foreign key(user_id) references tb_user(id)
)
五,索引
–1,概述
好处:给加完索引的列,提高查询效率
坏处:索引本质上就是一张表,如果表的体积太大,比较占内存
主键本身就有索引、
分类:
单值索引(一个索引只包含着一个列)
复合索引(一个索引包含着多个列)
唯一索引(一个索引只包含着一个列,但是要求列的值不能相同)
–2,创建索引
#1. 创建 普通索引: create index 索引名 on 表名(字段名)
#经常被查询的字段建议加索引,
create index dname_index on dept(dname)
#2. 查看索引(观察三列:表名/字段名/索引名)
show index from dept
#3. 使用索引,按照索引列查的快
explain
select * from dept where dname like '%a%'
#4. 创建 唯一索引:alter table 表名 add unique(字段名)
#alter table dept add unique(loc) loc的值已经重复了,不能使用唯一索引
alter table dept add unique(dname)
#5. 创建 复合索引:给多个字段加一个索引
alter table dept add index fuhe(dname,loc)
#6. 删除 索引 :alter table 表名 drop index 索引名
alter table dept drop index dname_index
以上是关于cgb2105-day03的主要内容,如果未能解决你的问题,请参考以下文章