yyds!用深度学习框架玩明日方舟,高端!
Posted OSC开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了yyds!用深度学习框架玩明日方舟,高端!相关的知识,希望对你有一定的参考价值。
每个游戏玩家都有一个梦,希望自己在虚拟世界中成为万众瞩目、无所不能的英雄。然后…然后…闹钟响了梦醒了,又到了挤地铁上班的时间。

不过,在这个项目中,我将带大家暂时忘却现实的烦恼,用飞桨深度强化学习框架PARL来实现这个“英雄梦”!先放效果图:
知识回顾
大家是不是迫不及待了呢?且慢,要实现《明日方舟》游戏的深度强化学习,还是先让我带大家回顾一下深度强化学习算法历史。DQN是深度强化学习算法开山之作,在经典街机游戏上取得了非常好的效果。它使用了ReplyMemory来存储和回放经验,这是Off-policy类型算法的常用技巧。但是,DQN在应对手机游戏时,能力就不够看了。于是我把目光投向了更为强大的算法--- A3C。
A3C算法与DQN不同,它设计了异步多线程的Actor-Critic,每个Agent在自己的线程中运行,然后全局共享学习到的网络参数。这样,每时每刻都能有大量的交互数据,并且这些多线程采集到的数据没有关联性(关联性问题:请参考DDQN算法原理)。因此,A3C算法通过“异步多线程+共享全局参数”达到了和ReplyMemory类似的效果。而且,它既有大量数据可以解决训练过程不稳定问题,同时又解决了参数关联性的问题。
在经典算法PG中,我们的Agent又被称为Actor,Actor对于一个特定的任务,都有自己的一个策略π。策略π通常用一个神经网络表示,其参数为θ。从一个特定的状态State出发,一直到任务的结束,被称为一个完整的Episode。在每一步,我们都能获得一个奖励r,一个完整的任务所获得的最终奖励被称为R。
如果我们用Q函数来预估未来的累积奖励,同时创建一个Critic网络来计算Q函数值,那么我们就得到了Actor-Critic方法。
Q函数在A3C里的主要作用是增加一个基线,使得反馈有正有负,这里的基线通常用状态价值函数V来表示。但是,当我们应用这样的方法,则需要同时计算Q函数和V函数,这并不容易。Q函数可以用“Step t+1的V函数”加上“从Step t到Step t+1的r”来代替。这样,我们就可以得到用V来表示的Q值计算,我们一般称为Advantage(优势函数),此时的Critic网络变为计算优势函数A的网络。
A3C是Asynchronous Advantage Actor-Critic的缩写,中文翻译为异步的优势动作评价算法。其中,Advantage就是指优势函数A。因此,从名字这里我们可以解读出来A3C实质就是求解πθ网络和Aπ(s, a)网络。
在A3C算法论文中,论文作者对比了四种算法——异步Sarsa、异步Q-Learning、DQN和A3C。论文发表后,各路算法大神验证一个问题——是异步更新让算法表现优于其他算法?。结果非常有趣:多线程是A3C算法快的原因,但是”异步更新“反而是它的缺点。于是,科学家提出同步更新算法A2C(Advantage Actor-Critic),让它可以更有效利用CPU资源。
PS:算法大神照样被打脸,啪啪啪!
在下面部分,我会先对PARL库内置的A2C算法进行简单解读,这样大家在看项目实践部分时,就能少阅读一些代码。
Learner
这个类有意思的地方是,PARL库用了A3C的名字。原因是A2C和A3C是同源算法。它们实现上的主要区别是step函数(后面会讲到)。
env = gym.make(config['env_name'])
env = wrap_deepmind(env, dim=config['env_dim'], obs_format='NCHW')
obs_shape = env.observation_space.shape
act_dim = env.action_space.n
self.config['obs_shape'] = obs_shape
self.config['act_dim'] = act_dim
model = AtariModel(act_dim)
algorithm = parl.algorithms.A3C(
model, vf_loss_coeff=config['vf_loss_coeff'])
self.agent = AtariAgent(algorithm, config)
create_actors
这段代码有意思的地方是,它把自己连接到了XPARL集群,然后去执行run_remote_sample。阅读过DQN源码的同学应该很好理解,它的意思就是在独立进程运行“取样”。
def create_actors(self):
# 先把自己连接到XPARL集群上去
parl.connect(self.config['master_address'])
for i in six.moves.range(self.config['actor_num']):
...
remote_thread = threading.Thread(
# 在工作线程中运行run_remote_sample函数
# 通过params_queue传递模型的参数
target=self.run_remote_sample, args=(params_queue, ))
remote_thread.setDaemon(True)
remote_thread.start()
...step函数
step函数是A2C算法中最重要、独特的函数,作用是同步等待更新操作。因为A2C算法会同步等待所有Agent(Actor)完成一轮训练后,把π网络的参数θ同步上来,更新全局的π网络参数。
Actor函数
注解@parl.remote_class表明Actor类是在独立的本机进程中执行(因为A2C是利用本机多CPU)。通过两行命令部署了PARL分布式集群,Actor实际是在远程server中运行了。
注意,Actor的init方法中保存了env数组,用同样的参数实例化了模型,用同样的模型实例化了算法并作为参数传入到了Agent中。
@parl.remote_class
class Actor(object):
def __init__(self, config):
...
# Actor保存了env数组
self.envs = []
for _ in range(config['env_num']):
env = gym.make(config['env_name'])
env = wrap_deepmind(env, dim=config['env_dim'], obs_format='NCHW')
self.envs.append(env)
...
model = AtariModel(act_dim)
algorithm = parl.algorithms.A3C(
model, vf_loss_coeff=config['vf_loss_coeff'])
self.agent = AtariAgent(algorithm, config)大家还要关注的点是,每个Actor对应一个Agent。
sample函数
Actor中的sample函数会调用Agent的sample函数和Agent的value函数来分别更新本地的π网络和v网络,最终返回sample_data给中心节点。
...
actions_batch, values_batch = self.agent.sample(np.stack(self.obs_batch))
...
next_value = self.agent.value(next_obs)
...sample_data的数据结构:
sample_data['obs'].extend(env_sample_data[env_id]['obs'])
sample_data['actions'].extend(env_sample_data[env_id]['actions'])
sample_data['advantages'].extend(advantages)
sample_data['target_values'].extend(target_values)其中,优势函数的的计算如下:
# gae:generalized advantage estimator
advantages = calc_gae(rewards, values, next_value,
self.config['gamma'],
self.config['lambda'])
target_values = advantages + valuesVectorEnv函数
这个类是PARL对env环境的封装。我们的模拟真机环境,也采用了同样的定义,主要是为了同时跑多个环境,增加并行计算的效率,如下所示:
class VectorEnv(object):
def __init__(self, envs):
def reset(self):
...
def step(self, actions):
# env需要实现step方法
obs, reward, done, info = self.envs[env_id].step(actions[env_id])
...
if done:
# env需要实现reset方法
obs = self.envs[env_id].reset()
...
return obs_batch, reward_batch, done_batch, info_batch模拟器的源数据是由此类中的step方法批量返回。
实战编程
1.游戏模拟器编写&训练
因为《明日方舟》是手机网络游戏,数据生产速度实在太慢了!!!为了提高训练速度,需要自己开发模拟器。用模拟器后速度可提升50-100倍。
修改Learner的初始化方法:
#=========== Create Agent ==========
game = ArKnights()
env = PMGE(game)
obs_shape = (3, 108, 192)
act_dim = 650
定义新的env.py:
class PMGE(object):
def __init__(self, game):
self.game = game
def step(self, action):
# 模拟器简化了状态判断
# 实际项目应该实时生成:当前屏幕--> stateCode 的关系
s1 = [ self.game.stateCode ]
# 产生状态变化
self.game.act(action, s1)
reward = self.game.getScore(s1)
isOver = self.game.gameOver()
next_obs = self.game.render()
# 为了匹配标准的API
return next_obs, reward, isOver, 0
def reset(self):
return self.game.reset()
修改Actor:
class Actor(object):
def __init__(self, config):
self.config = config
self.envs = []
for _ in range(config['env_num']):
game = ArKnights()
env = PMGE(game)
self.envs.append(env)
self.vector_env = VectorEnv(self.envs)
self.obs_batch = self.vector_env.reset()
model = Model(config['act_dim'])
algorithm = parl.algorithms.A3C(
model, vf_loss_coeff=config['vf_loss_coeff'])
self.agent = Agent(algorithm, config)
定义训练用的模拟环境:
class ArKnights(object):
def __init__(self):
"""
游戏《明日方舟》智能体定义
"""
self.stateCode = 990
# 1920x1080 ----- 1920/80 x 1080/40 = 24x27
self.tap_dim = 24*27
self.swipe_dim = 4 # 上下左右
def render(self):
imgDir = IMAGE_DIR + str(self.stateCode) + '/'
filenames = os.listdir(imgDir)
# 在stateCode目录下随机取一张图片
filename = random.choice(filenames)
return self.transform_img(imgDir + filename)
def act(self, action, stateCode):
if stateCode[0] == 990:
if action in [442,443,444,445,466,467,468,469]:
self.stateCode = 970
if stateCode[0] == 970:
if action in [111,112,113,114,115,
135,136,137,138,139,
159,160,161,162,163,
183,184,185,186,187,
207,208,209,210,211]:
self.stateCode = 965
def getScore(self, s1):
# 状态没变扣一分
if s1[0] == self.stateCode:
return -1
return 1
def gameOver(self):
code = self.stateCode
# if (code == 910 or code == 1010):
# for debug 让算法快速收敛
if (code == 965):
return True
return False
def reset(self):
self.stateCode = 990
imgDir = IMAGE_DIR + str(self.stateCode) + '/'
filenames = os.listdir(imgDir)
# 在990目录下随机取一张图片
filename = random.choice(filenames)
return self.transform_img(imgDir + filename)
def transform_img(self, filepath):
# 直接读取 (h,w)
img = cv2.imread(filepath, cv2.IMREAD_COLOR)
# 将图片尺寸缩放道 (image, (w,h)) 192x108
img = cv2.resize(img, (192, 108))
# 因为cv2的数组长宽是反的,所以用numpy转置一下 (C,H,W)
img = np.transpose(img, (2, 0, 1))
obs = img.astype('float32')
return obs
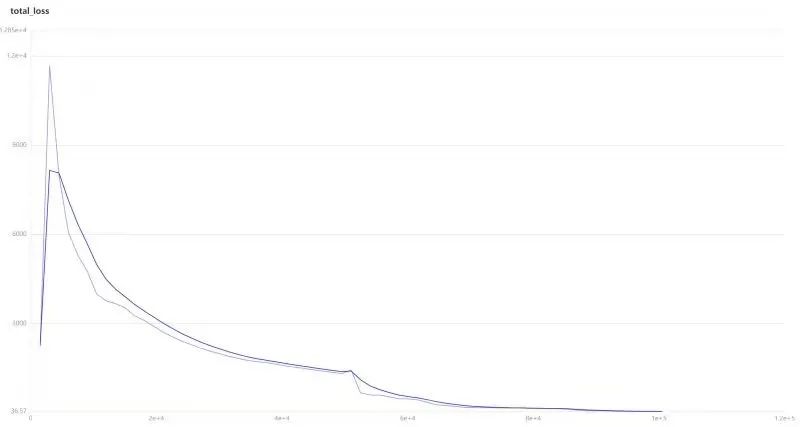
在模拟器中经过大约10万个steps,模型的loss就收敛了。
2.编写状态推理引擎
新建项目ARKNIGHT_CLASSIFY,使用残差神经网络对《明日方舟》中的主要游戏界面做了预定义。利用这个引擎,在真机部署的时候可以推断出当前游戏的state,用于计算reward和game over这两个重要参数。
3.评估强化学习模型
在深度强化学习中,效果评估非常重要,因为我们要知道算法从数据中学到了什么?
我们在第一步中得到了模型,在第二步中得到了真机环境下的reward和game over函数。
那么我们就要在真机环境中去测试。
def test():
game = ArKnights()
env = PMGE(game)
obs_shape = (3, 108, 192)
act_dim = 650
config['obs_shape'] = obs_shape
config['act_dim'] = act_dim
model = Model(act_dim)
algorithm = parl.algorithms.A3C(model, vf_loss_coeff=config['vf_loss_coeff'])
agent = Agent(algorithm, config)
agent.restore("./model_dir")
# 初始状态
obs = env.reset()
MAX_STEP = 20
step = 0
while True:
state_code = env.game.stateCode
action = agent.predict(obs)
obs, reward, isOver, _ = env.step(action)
next_state_code = env.game.stateCode
step += 1
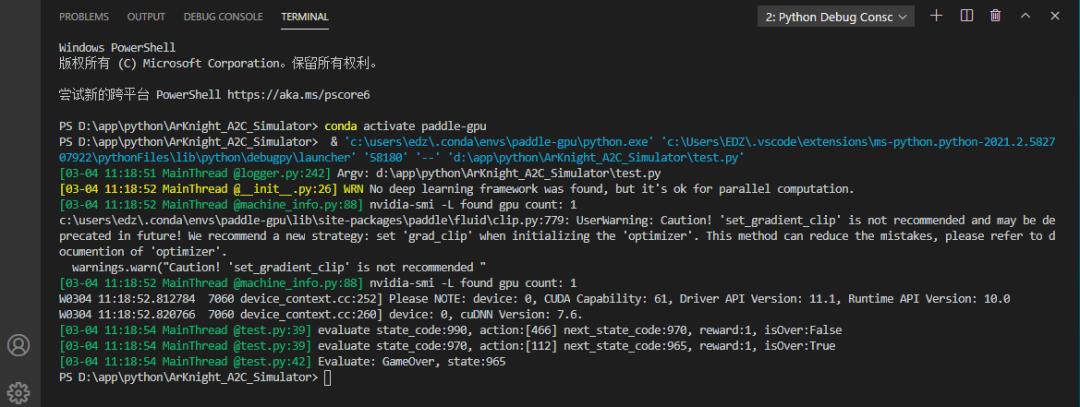
logger.info("evaluate state_code:{}, action:{} next_state_code:{}, reward:{}, isOver:{}".format(state_code, action, next_state_code, reward, isOver))
if isOver or step >MAX_STEP:
logger.info("GameOver, state:{}".format(next_state_code))
break;可以看到,我只用了2步,算法就成功达到了设定的终止状态[965]。新建部署项目ArKnight_A2C,把模型导入,效果如下:
4.模型和状态推理引擎部署到真机
定义真机环境:
import time
import cv2
from PIL import Image
import numpy as np
from adbutil import AdbUtil
from resnet import ResNet
import paddle
import paddle.fluid as fluid
class ArKnights(object):
def __init__(self):
self.adbutil = AdbUtil()
# 加载推理模型
with fluid.dygraph.guard():
# 加载状态推断引擎
self.model = ResNet('resnet', 50)
#加载模型参数
model_state_dict, _ = fluid.load_dygraph("arknights")
self.model.load_dict(model_state_dict)
self.model.eval()
def _restart(self):
"""
打开游戏进程
如果已经打开,先关闭再重新打开
"""
self.adbutil.stopArKnights()
self.adbutil.startArKnights()
# 每隔1秒在屏幕中心点击1下,持续20秒
self.adbutil.taptap(960,540,20,1)
def _stop(self):
"""
关闭游戏进程
"""
self.adbutil.stopArKnights()
def act(self, action):
# 点击动作code映射成动作
if action < 648:
x = (action % 24) * 80 + 40 # 取余
y = (action // 24) * 40 + 20 # 取商
self.adbutil.taptap(x,y,1,0.01) # x,y,count,frequency
elif action == 648:
self.adbutil.rightswipeswipe(2,0.5)
elif action == 649:
self.adbutil.leftswipeswipe(2,0.5)
else:
raise("No such action error!" + str(action))
time.sleep(2) # 等动作执行完
def render(self):
# TODO check shape
img = self.adbutil.screencap()
img = img.resize((192, 108), Image.ANTIALIAS)
# 因为图片的数组长宽是反的,所以用numpy转置一下 (C,H,W)
img = np.transpose(img, (2, 0, 1))
obs = img.astype('float32')
return obs
def reset(self):
self._restart()
return self.render()
def gameOver(self):
state = self.inferState()
print("state"+str(state))
if state[0] == 965:
return True
else:
return False
def inferState(self):
"""
图片推断
"""
...这里的游戏状态推断引擎,就是ARKNIGHT_CLASSIFY项目输出的推理模型。有了状态的推理值,代码中的reward和game over就可以和真机环境匹配上。同时,用AdbUtil类来执行真实动作,就可以操作真机执行算法动作。最终真机运行效果如下(手机屏幕的变化请看视频):
在这个文章中,我给大家展示了如何构建明日方舟的交互环境,以及如何通过PARL快速调用A3C算法实现并行训练,整体实现起来简单易懂。
看到这儿,大家是不是迫不及待地想要自己动手尝试!
“英雄们”,快用飞桨去实现你们的美梦吧,yyds(永远滴神)!
欲知详情,请戳PARL开源链接:
https://github.com/PaddlePaddle/PARL


觉得不错,请点个在看呀
以上是关于yyds!用深度学习框架玩明日方舟,高端!的主要内容,如果未能解决你的问题,请参考以下文章
实践:《21个项目玩转深度学习基于TensorFlow的实践详解》PDF+源代码