TCP/IP网络编程学习记录一
Posted 杨书落
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TCP/IP网络编程学习记录一相关的知识,希望对你有一定的参考价值。
博客说明:本博客为了记录博主学习TCP/IP网络编程的知识点和个人理解,上面的很多术语和图片都来自书上,环境是Linux , 本文参考了部分博客都放上了博客地址,不会谋取任何利益,如有任何侵犯请私信联系我。
目录
一、Socket
偷懒,这里放一篇专门讲解socket的博客,讲的很详细,先看这个socket技术详解链接
因为这篇博客把常用到的socket都讲到了,而且说的很好,所以这里只写一点简单的补充。
补充一、网络字节顺序与本地字节顺序之间的转换函数
cpu向内存保存数据的方式有两种:大端序(Big Endian)和小端序(Little Endian)
- 大端序:高位字节存放到低位地址
- 小端序:高位字节存放到高位地址
简单来说:比如从地址0x20开始保存一个4字节的int类型0x12345678大端序:
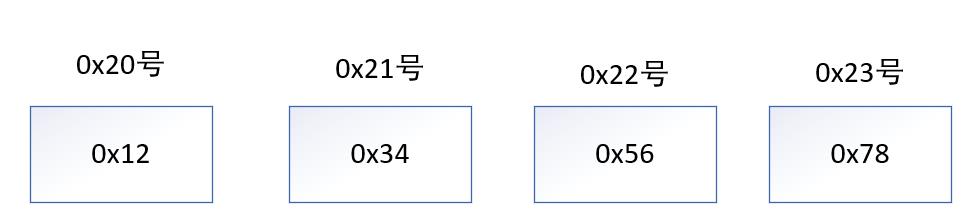
小端序:

因为不同的cpu数据保存的方式不同(大多以小端序保存),所以为了保证在不同计算机之间传输数据不发生错误,要给网络传输数据时的约定统一,这种约定称为网络字节序,都统一成大端序再进行数据交换。将主机的数据成为本地/主机字节序,接收的数据应为网络字节序。
转换函数主要有下面4个,h代表host(主机字节序),n代表network(网络字节序),s代表short(2个字节),l代表long(4个字节),to就是转换
htonl()–“Host to Network Long” —把long型数据从本地字节序转换到网络字节序
ntohl()–“Network to Host Long” —把long型数据从网络字节序转换成本地字节序
htons()–“Host to Network Short” —把short型数据从本地字节序转换到网络字节序
ntohs()–“Network to Host Short” —把short型数据从网络字节序转换成本地字节序
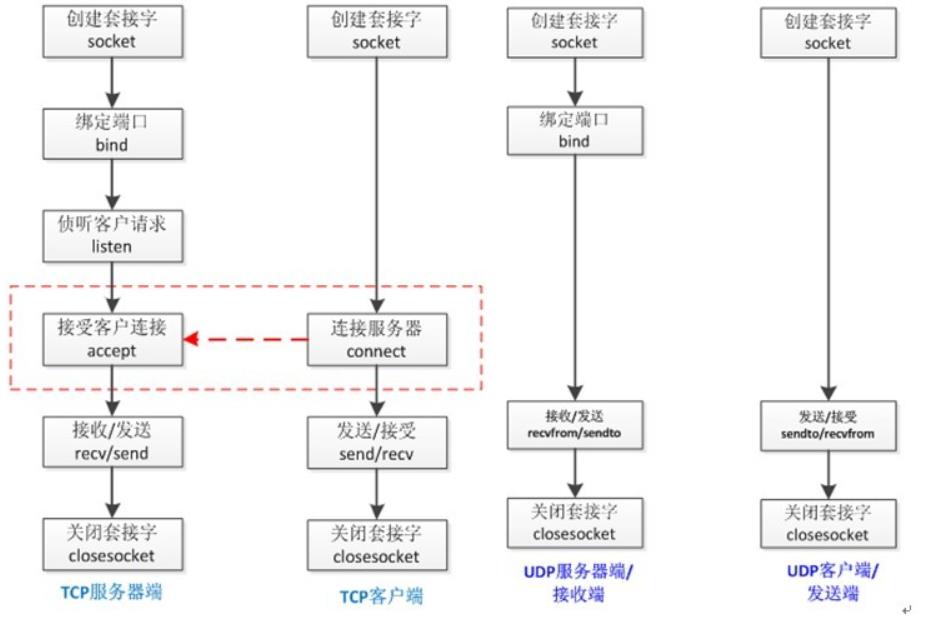
- socket服务端使用
bind()时需要通信域(地址族)、IP地址、端口号,这三个元素由SOCKADDR_IN结构体定义,为了简化编程一般将IP地址设置为INADDR_ANY,如果需要使用特定的IP地址则需要使用inet_addr和inet_ntoa完成字符串和in_addr结构体的互换。 - 上述应用如下
//创建套接字
int serv_sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
//创建sockaddr_in结构体变量
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof(serv_addr)); //每个字节都用0填充
serv_addr.sin_family = AF_INET; //使用IPv4地址
serv_addr.sin_addr.s_addr = inet_addr("127.0.0.1"); //具体的IP地址
serv_addr.sin_port = htons(1234); //端口
//将套接字和IP、端口绑定
bind(serv_sock, (struct sockaddr*)&serv_addr, sizeof(serv_addr));
补充二、UDP与TCP在这部分的区别
- UDP中的服务器段端和客户端没有连接
即UDP服务器端和客户端不需要像TCP那样在连接状态下交换数据,不需要连接的过程。对应的就是不需要
listen()和accept()两个函数
- UDP服务器端和客户端只需要一个套接字
TCP中套接字之间时一一对应的,即向多少个客户端提供服务就需要多少个服务端套接字+一个守门的服务器套接字。UDP则只需要一个套接字就可以向任意主机传输数据
- UDP存在数据边界,TCP不存在数据边界
在默认的阻塞模式下
对于TCP协议,客户端连续发送数据,只要服务端的这个函数的缓冲区足够大,会一次性接收过来,即客户端是分好几次发过来,是有边界的,而服务端却一次性接收过来,所以无边界的;
对于UDP协议,客户端连续发送数据,即使服务端的这个函数的缓冲区足够大,也只会一次一次的接收,发送多少次接收多少次,即客户端分几次发送过来,服务端就必须按几次接收,UDP的通讯模式是有边界的。
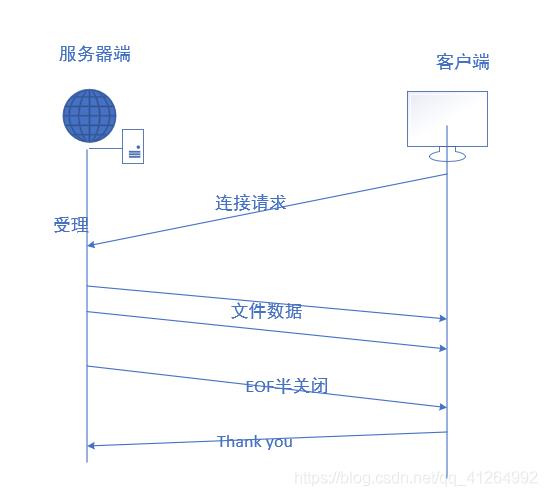
补充三、优雅的断开连接shutdown
优雅的断开连接其实就是基于TCP的半关闭状态,所谓半关闭就是
shutdown的第二个参数调用下面三个,直到调用close()函数socket才全关闭。半关闭的原因就是为了防止CS的一方最后仍有数据传输,另一方接收不到。
SHUT_RD:断开输入流
SHUR_WR:断开输出流
SHUT_RDWR:同时断开输入/输出流,相当于调用了两次shutdown
这里的Thank you就是数据传输结束后客户端给服务端的一个反馈,如果这里直接用close就会接收不到这个反馈。
二、 多进程服务器
定义:占用内存空间的正在运行的程序
2.1 创建进程
步骤:
- 创建进程
fork()
函数
pid_t fork(void)成功时返回进程ID,失败时返回-1。
借用下面这段程序解释下我的理解
#include <stdio.h>
#include <unistd.h>
int gval = 10;
int main(int argc, char argv[])
{
pid_t pid;
int lval = 20;
gval++, lval+=5;
pid = fork();
if(pid == 0) {
gval+=2, lval+=2;
} else {
gval-=2, lval-=2;
}
if(pid = 0) {
printf("child proc:[%d, %d] \\n", gval, lval);
} else {
printf("parent proc:[%d, %d] \\n", gval, lval);
}
}
首先
fork()并非根据完全不同的程序创建的进程,而是复制正在运行的、调用函数的进程, 也就是说在调用fork()函数前只存在一个进程,调用fork()函数后变成了两个同步的进程,区分这两个进程的就是fork()函数的返回值,当fork()返回值等于0进入子进程,返回子进程ID时进入父进程。也就是说调用fork()一次返回两个值,这里父子进程的执行顺序应该是不确定的。
运行结果:gcc fork.c -o fork
./fork()
child proc:[13, 27]
parent proc:[9, 23]
2.2 僵尸进程
当fork()建立一个新的子进程后,当这个子进程结束的时候,调用exit/return命令返回值给操作系统而操作系统不会销毁子进程,所以子进程并没有真正的被销毁,而是留下一个称为僵尸进程。当父进程结束时向操作系统发起请求获得子进程的结束返回值时子进程才能销毁,但是如果父进程是一个循环,不会结束,那么子进程就会一直保持僵尸状态。僵尸进程会占用系统资源,如果很多,则会严重影响服务器的性能。 所以我们要预防僵尸进程的出现,出现了也要杀死它。
- 调用
wait/waitpid函数可以杀死僵尸进程
这两个函数的实质就是让父进程主动请求获取子进程的返回值。
pid_t wait(int *statloc)将子进程结束信息保存到statloc中
pid_t wait_pid(pid_t pid, int *statloc, int options)
参数解释:如果pid=-1则与wait函数一致,可以等待任意子进程终止,statloc保存子进程结束的信息,options这个是与wait函数区别最大的一个参数,当option=WNOHANG时,即使没有终止的子进程也不会进入阻塞函数,而是返回0并退出函数,而wait如果没有子进程终止会一直阻塞程序直到有子进程终止。
wait/waitpid的使用链接这个链接讲的比较清楚大家可以看下这个。
- 信号处理
signal/sigaction函数
虽然我们知道如何创建和销毁子进程,但是子进程何时终止我们仍然不晓得。于是就出现了信号处理函数,当子进程结束时操系统发出信号给父进程告知子进程结束,这时父进程调用
wait函数进行回收。
void (*signal(int signo, void (*func)(int)))(int)—注意这个函数的参数类型是int,返回类型是void型函数指针
参数:signo对应下面三个宏参数,第二个参数对应的是调用的注册函数
SIGALRM:到alarm函数注册的时间
SIGINT:输入ctrl+c
SIGCHLD:子进程终止
unsigned int alarm(unsigned int seconds); //alarm函数参数为秒s
借用书上的例子说下理解,看注释
#include <stdio.h>
#include <unistd.h>
#include <signal.h>
void timeout(int sig) //信号处理函数
{
if(sig == SIGALRM)
puts("time out");
alarm(2);
}
void keycontrol(int sig) //信号处理函数
{
if(sig == SIGINT)
puts("CTRL+C pressed");
}
int main(int argc, char *argv[])
{
int i;
//注册函数
signal(SIGALRM, timeout);
signal(SIGINT, keycontrol);
//2s后发出SIGALRM信号,signal接收到信号后调用注册函数timeout
alarm(2);
for(i = 0; i < 3; i++) {
puts("wait……");
sleep(100);
}
return 0;
}
补充解释:我的理解信号类似于中断,当主函数接收到信号后优先去处理注册函数,注册函数结束后继续进行下面的主函数。
alarm的作用就是一个闹钟,时间到达后发出信号执行注册函数就失效了,上述在注册函数中又设置了alarm形成了一个循环闹钟,每次的时间是2s所以for循环每次进入2s就会中断一次进入注册函数,当三次之后for循环退出,程序结束。程序中每次for循环sleep 100s实际上程序不到10s就结束,如果你按ctrl+c会立即结束。
alarm函数存在刷新,例如开始设置alarm(5)当5s倒计时还未结束时又设置alarm(7),这时倒计时会从7开始。
alarm(5);
……………do something………………
alarm(7);
int sigaction(int signo, const struct sigaction *act, struct sigaction *oldact)
参数解释:signo用于指定动作的信号;
act是一个指向struct sigaction结构的指针,对应于signo的信号处理函数信息;
oldact通过此参数获取之前注册的信号处理函数指针,不需要就传0;
//结构体sigaction
struct sigaction
{
void (*sa_handler)(int);
void (*sa_sigaction)(int, siginfo_t *, void *);
sigset_t sa_mask;
int sa_flags;
void (*sa_restorer)(void);
};
signal和sigaction的区别链接
下面所指的signal都是指以前的older signal函数,现在大多系统都用sigaction重新实现了signal函数
1、signal在调用handler之前先把信号的handler指针恢复;sigaction调用之后不会恢复handler指针,直到再次调用sigaction修改handler指针。
:这样,(1)signal就会丢失信号,而且不能处理重复的信号,而sigaction就可以。因为signal在得到信号和调用handler之间有个时间把handler恢复了,这样再次接收到此信号就会执行默认的handler。(虽然有些调用,在handler的以开头再次置handler,这样只能保证丢信号的概率降低,但是不能保证所有的信号都能正确处理)
2、signal在调用过程不支持信号block;sigaction调用后在handler调用之前会把屏蔽信号(屏蔽信号中自动默认包含传送的该信号)加入信号中,handler调用后会自动恢复信号到原先的值。
(2)signal处理过程中就不能提供阻塞某些信号的功能,sigaction就可以阻指定的信号和本身处理的信号,直到handler处理结束。这样就可以阻塞本身处理的信号,到handler结束就可以再次接受重复的信号。
3、sigaction提供了比signal多的多的功能,可以参考man
下面是利用信号处理技术消灭僵尸进程的代码
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <signal.h>
#include <sys/wait.h>
void read_childproc(int sig)
{
int status;
pid_t id = waitpid(-1, &status, WNOHANG);
if(WIFEXITED(status)) {
printf("remove proc id : %d \\n", id);
printf("child send: %d \\n", WEXITSTATUS(status));
}
}
int main(int argc, char *argv[])
{
system("date");
pid_t pid;
struct sigaction act;
act.sa_flags = 0;
sigemptyset(&act.sa_mask);
act.sa_handler = read_childproc;
sigaction(SIGCHLD, &act, 0);
pid = fork();
if (pid == 0) {
puts("hi, i am child process");
sleep(10);
return 12;
} else {
printf("child proc id : %d \\n", pid);
pid = fork();
if (pid == 0) {
puts("hi, i am child process");
sleep(10);
exit(24);
} else {
int i;
printf("child proc id : %d \\n", pid);
for (int i = 0; i < 5; i++) {
puts("wait~~~~~");
sleep(5);
}
}
}
system("date");
return 0;
}
三、进程间通信
两个不同的进程间相互数据交换
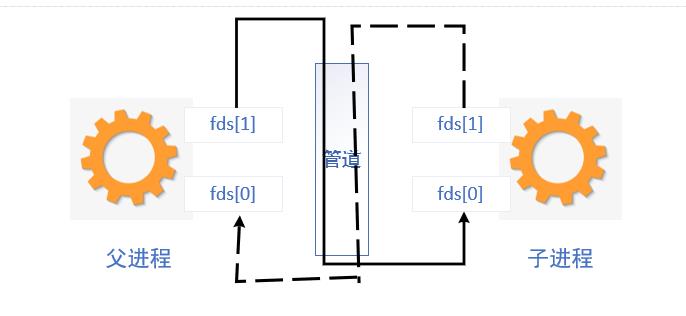
- 通过管道函数
pipe函数实现进程通信
int pipe(int filedes[2])
filedes[0] 管道入口,接收数据
filedes[1] 管道出口, 传输数据
单管道如下图,注意点就是单管道实现数据传输注意读写顺序,因为管道通信实际上是将数据写入管道然后这些管道的数据成了无主数据,只要有read就可以将数据读走,后面再来读取时因为没有数据而进入无休止的阻塞状态。
解决单管道通信的办法就是用双管道
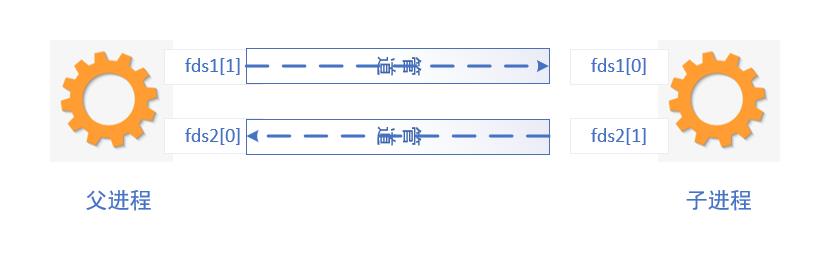
#include <stdio.h>
#include <unistd.h>
#define BUF_SIZE 30
int main(int argc, char *argv[])
{
int fds1[2], fds2[2]; //数组用来保存I/O的文件描述符
char std1[] = "who are you";
char std2[] = "Thank you for your name";
char buf[BUF_SIZE];
pid_t pid;
pipe(fds1), pipe(fds2); //建立两个管道
pid = fork(); //fork一个进程
if(pid == 0) { //子进程
write(fds1[1], std1, sizeof(std1)); //向管道fds1中写数据
//sleep(2);
read(fds2[0], buf, BUF_SIZE); //读取fds2中的数据
printf("Child proc output: %s \\n", buf);
} else { //父进程
read(fds1[0], buf, BUF_SIZE); //读取子进程向fds1中写入的数据
printf("father proc output: %s \\n", buf);
write(fds2[1], std2, sizeof(std2));//向fds2中写入数据,子进程会读取
//sleep(3);
}
return 0;
}
注意:
1、 管道用来做进程间的通讯,所以数据自己读不能自己写。
2、当管道中的数据被读取后,管道为空,不可反复读取。一个随后的read()调用将默认的被阻塞,等待某些数据写入。若需要设置为非阻塞,调用fcntl函数:
fcntl(filedes[0], F_SETFL, O_NONBLOCK);
fcntl(filedes[1], F_SETFL, O_NONBLOCK);
以上是关于TCP/IP网络编程学习记录一的主要内容,如果未能解决你的问题,请参考以下文章