线上大量CLOSE_WAIT的原因深入分析
Posted linux大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线上大量CLOSE_WAIT的原因深入分析相关的知识,希望对你有一定的参考价值。
linux服务器开发相关视频解析:
c/c++ linux服务器开发学习地址:c/c++ linux后台服务器高级架构师
这一次重启真的无法解决问题了:一次 mysql 主动关闭,导致服务出现大量 CLOSE_WAIT 的全流程排查过程。
近日遇到一个线上服务 socket 资源被不断打满的情况。通过各种工具分析线上问题,定位到问题代码。这里对该问题发现、修复过程进行一下复盘总结。
先看两张图。一张图是服务正常时监控到的 socket 状态,另一张当然就是异常啦!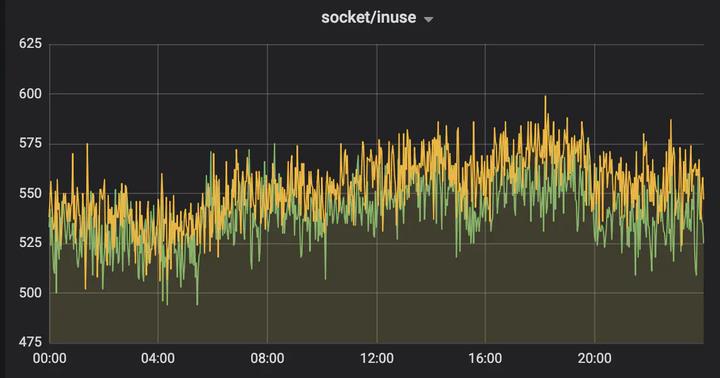
图一:正常时监控
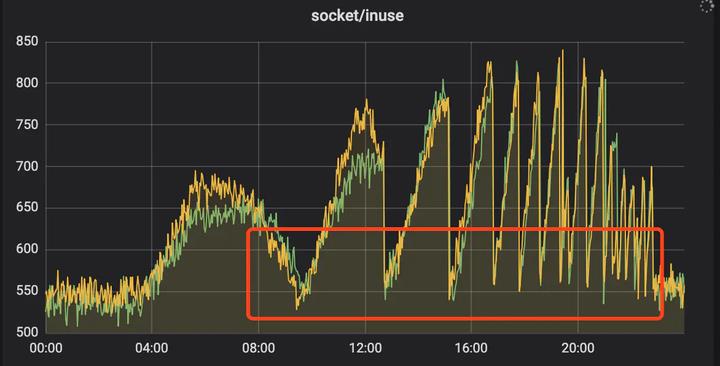
图二:异常时监控
从图中的表现情况来看,就是从 04:00 开始,socket 资源不断上涨,每个谷底时重启后恢复到正常值,然后继续不断上涨不释放,而且每次达到峰值的间隔时间越来越短。
重启后,排查了日志,没有看到 panic ,此时也就没有进一步检查,真的以为重启大法好。
情况说明
该服务已经上线正常运行将近一年,提供给其它服务调用,主要底层资源有DB/Redis/MQ。
为了后续说明的方便,将服务的架构图进行一下说明。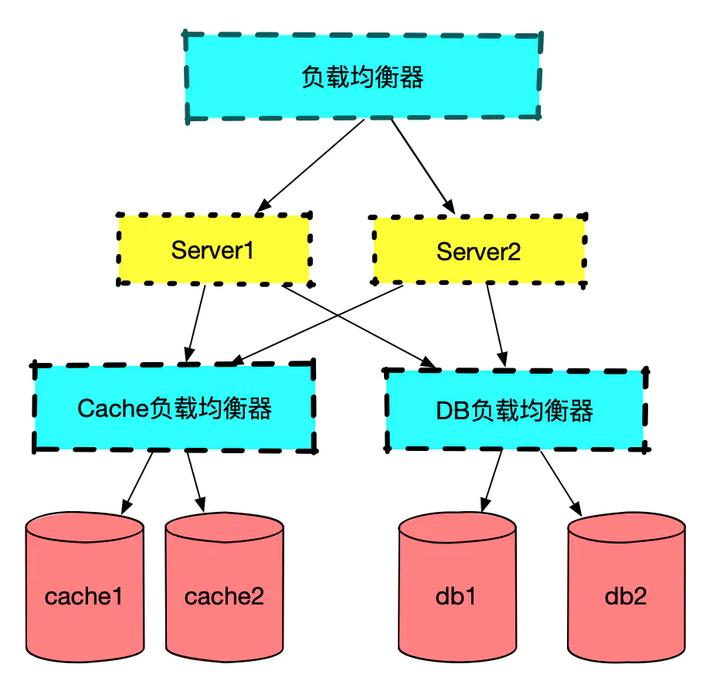
图三:服务架构
架构是非常简单。 问题出现在早上 08:20 左右开始的,报警收到该服务出现 504,此时第一反应是该服务长时间没有重启(快两个月了),可能存在一些内存泄漏,没有多想直接进行了重启。也就是在图二第一个谷底的时候,经过重启服务恢复到正常水平(重启真好用,开心)。
将近 14:00 的时候,再次被告警出现了 504 ,当时心中略感不对劲,但由于当天恰好有一场大型促销活动,因此先立马再次重启服务。直到后续大概过了1小时后又开始告警,连续几次重启后,发现需要重启的时间间隔越来越短。此时发现问题绝不简单。这一次重启真的解决不了问题老,因此立马申请机器权限、开始排查问题。下面的截图全部来源我的重现demo,与线上无关。
发现问题
出现问题后,首先要进行分析推断、然后验证、最后定位修改。根据当时的表现是分别进行了以下猜想。
推断一
socket 资源被不断打满,并且之前从未出现过,今日突然出现,怀疑是不是请求量太大压垮服务
经过查看实时 qps 后,放弃该想法,虽然量有增加,但依然在服务器承受范围(远远未达到压测的基准值)。
推断二
两台机器故障是同时发生,重启一台,另外一台也会得到缓解,作为独立部署在两个集群的服务非常诡异
有了上面的的依据,推出的结果是肯定是该服务依赖的底层资源除了问题,要不然不可能独立集群的服务同时出问题。
由于监控显示是 socket 问题,因此通过 netstat 命令查看了当前tcp链接的情况(本地测试,线上实际值大的多)
/go/src/hello # netstat -na | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
LISTEN 2
CLOSE_WAIT 23 # 非常异常
TIME_WAIT 1
发现绝大部份的链接处于CLOSE_WAIT状态,这是非常不可思议情况。然后用netstat -an命令进行了检查。
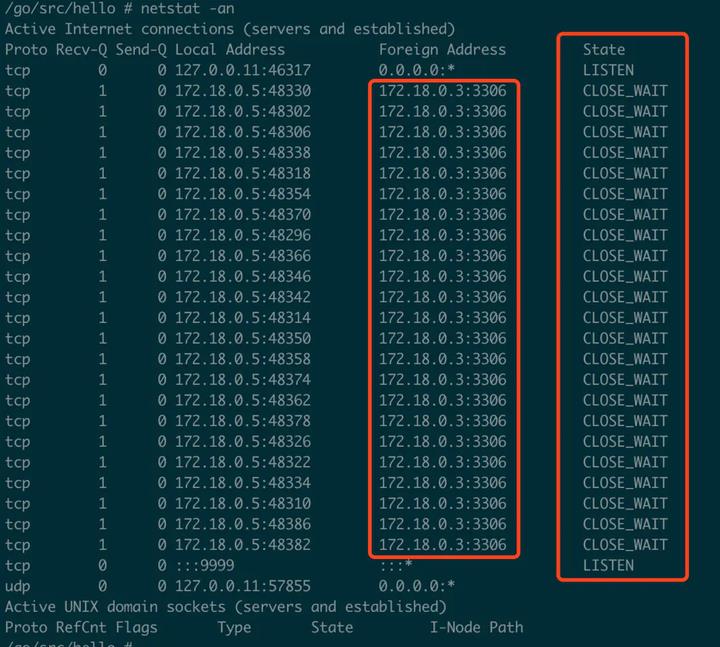
图四:大量的CLOSE_WAIT
CLOSED 表示socket连接没被使用。 LISTENING 表示正在监听进入的连接。 SYN_SENT 表示正在试着建立连接。SYN_RECEIVED 进行连接初始同步。 ESTABLISHED 表示连接已被建立。 CLOSE_WAIT表示远程计算器关闭连接,正在等待socket连接的关闭。 FIN_WAIT_1 表示socket连接关闭,正在关闭连接。 CLOSING先关闭本地socket连接,然后关闭远程socket连接,最后等待确认信息。 LAST_ACK 远程计算器关闭后,等待确认信号。 FIN_WAIT_2 socket连接关闭后,等待来自远程计算器的关闭信号。 TIME_WAIT 连接关闭后,等待远程计算器关闭重发。
然后开始重点思考为什么会出现大量的mysql连接是CLOSE_WAIT呢?为了说清楚,我们来插播一点TCP的四次挥手知识。
【文章福利】需要C/C++ Linux服务器架构师学习资料加群812855908(资料包括C/C++,Linux,golang技术,nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等)
TCP四次挥手
我们来看看TCP的四次挥手是怎么样的流程:
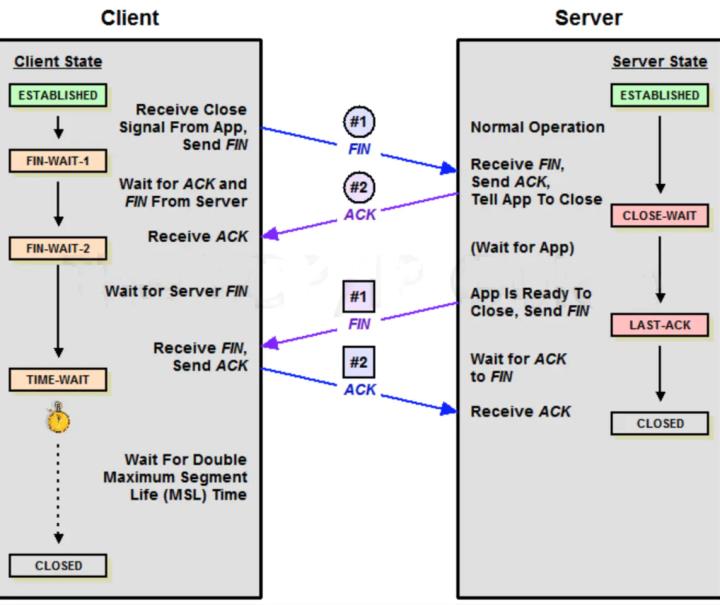
用中文来描述下这个过程:
Client: 服务端大哥,我事情都干完了,准备撤了,这里对应的就是客户端发了一个FIN
Server:知道了,但是你等等我,我还要收收尾,这里对应的就是服务端收到 FIN 后回应的 ACK
经过上面两步之后,服务端就会处于 CLOSE_WAIT 状态。过了一段时间 Server 收尾完了
Server:小弟,哥哥我做完了,撤吧,服务端发送了FIN
Client:大哥,再见啊,这里是客户端对服务端的一个 ACK
到此服务端就可以跑路了,但是客户端还不行。为什么呢?客户端还必须等待 2MSL 个时间,这里为什么客户端还不能直接跑路呢?主要是为了防止发送出去的 ACK 服务端没有收到,服务端重发 FIN 再次来询问,如果客户端发完就跑路了,那么服务端重发的时候就没人理他了。这个等待的时间长度也很讲究。
Maximum Segment Lifetime报文最大生存时间,它是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃
这里一定不要被图里的 client/server 和项目里的客户端服务器端混淆,你只要记住:主动关闭的一方发出 FIN 包(Client),被动关闭(Server)的一方响应 ACK 包,此时,被动关闭的一方就进入了 CLOSE_WAIT 状态。如果一切正常,稍后被动关闭的一方也会发出 FIN 包,然后迁移到 LAST_ACK 状态。 既然是这样,TCP抓包分析下:
/go # tcpdump -n port 3306
# 发生了 3次握手
11:38:15.679863 IP 172.18.0.5.38822 > 172.18.0.3.3306: Flags [S], seq 4065722321, win 29200, options [mss 1460,sackOK,TS val 2997352 ecr 0,nop,wscale 7], length 0
11:38:15.679923 IP 172.18.0.3.3306 > 172.18.0.5.38822: Flags [S.], seq 780487619, ack 4065722322, win 28960, options [mss 1460,sackOK,TS val 2997352 ecr 2997352,nop,wscale 7], length 0
11:38:15.679936 IP 172.18.0.5.38822 > 172.18.0.3.3306: Flags [.], ack 1, win 229, options [nop,nop,TS val 2997352 ecr 2997352], length 0
# mysql 主动断开链接
11:38:45.693382 IP 172.18.0.3.3306 > 172.18.0.5.38822: Flags [F.], seq 123, ack 144, win 227, options [nop,nop,TS val 3000355 ecr 2997359], length 0 # MySQL负载均衡器发送fin包给我
11:38:45.740958 IP 172.18.0.5.38822 > 172.18.0.3.3306: Flags [.], ack 124, win 229, options [nop,nop,TS val 3000360 ecr 3000355], length 0 # 我回复ack给它
... ... # 本来还需要我发送fin给他,但是我没有发,所以出现了close_wait。那这是什么缘故呢?
src > dst: flags data-seqno ack window urgent options src > dst表明从源地址到目的地址 flags 是TCP包中的标志信息,S 是SYN标志, F(FIN), P(PUSH) , R(RST)"."(没有标记) data-seqno 是数据包中的数据的顺序号 ack 是下次期望的顺序号 window 是接收缓存的窗口大小urgent 表明数据包中是否有紧急指针 options 是选项
结合上面的信息,我用文字说明下:MySQL负载均衡器 给我的服务发送 FIN 包,我进行了响应,此时我进入了 CLOSE_WAIT 状态,但是后续作为被动关闭方的我,并没有发送 FIN,导致我服务端一直处于 CLOSE_WAIT 状态,无法最终进入 CLOSED 状态。 那么我推断出现这种情况可能的原因有以下几种:
1、负载均衡器异常退出了,
这基本是不可能的,他出现问题绝对是大面积的服务报警,而不仅仅是我一个服务
2、MySQL负载均衡器的超时设置的太短了,导致业务代码还没有处理完,MySQL负载均衡器就关闭tcp连接了
这也不太可能,因为这个服务并没有什么耗时操作,当然还是去检查了负载均衡器的配置,设置的是60s。
3、代码问题,MySQL连接无法释放
目前看起来应该是代码质量问题,加之本次数据有异常,触发到了以前某个没有测试到的点,目前看起来很有可能是这个原因
查找错误原因
由于代码的业务逻辑并不是我写的,我担心一时半会看不出来问题,所以直接使用perf把所有的调用关系使用火焰图给绘制出来。既然上面我们推断代码中没有释放mysql连接。无非就是:
- 确实没有调用close
- 有耗时操作(火焰图可以非常明显看到),导致超时了
- mysql的事务没有正确处理,例如:rollback 或者 commit
由于火焰图包含的内容太多,为了让大家看清楚,我把一些不必要的信息进行了折叠。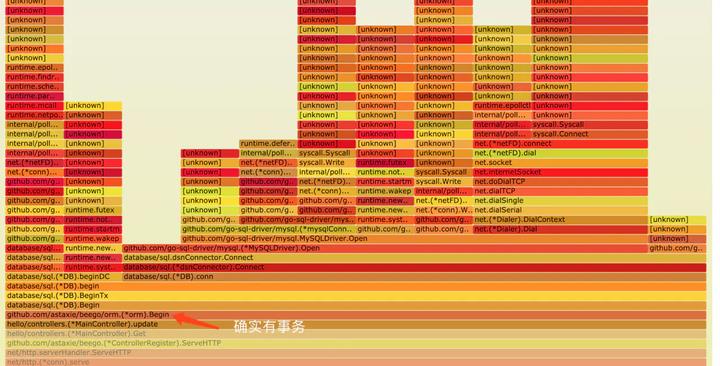
图五:有问题的火焰图
火焰图很明显看到了开启了事务,但是在余下的部分,并没有看到Commit或者是Rollback操作。这肯定会操作问题。然后也清楚看到出现问题的是:
MainController.update方法内部,话不多说,直接到 update 方法中去检查。发现了如下代码:
func (c *MainController) update() (flag bool) {
o := orm.NewOrm()
o.Using("default")
o.Begin()
nilMap := getMapNil()
if nilMap == nil {// 这里只检查了是否为nil,并没有进行rollback或者commit
return false
}
nilMap[10] = 1
nilMap[20] = 2
if nilMap == nil && len(nilMap) == 0 {
o.Rollback()
return false
}
sql := "update tb_user set name=%s where id=%d"
res, err := o.Raw(sql, "Bug", 2).Exec()
if err == nil {
num, _ := res.RowsAffected()
fmt.Println("mysql row affected nums: ", num)
o.Commit()
return true
}
o.Rollback()
return false
}
至此,全部分析结束。经过查看getMapNil返回了nil,但是下面的判断条件没有进行回滚。
if nilMap == nil {
o.Rollback()// 这里进行回滚
return false
}
总结
整个分析过程还是废了不少时间。最主要的是主观意识太强,觉得运行了一年没有出问题的为什么会突然出问题?因此一开始是质疑 SRE、DBA、各种基础设施出了问题(人总是先怀疑别人)。导致在这上面费了不少时间。
理一下正确的分析思路:
1、出现问题后,立马应该检查日志,确实日志没有发现问题;
2、监控明确显示了socket不断增长,很明确立马应该使用 netstat 检查情况看看是哪个进程的锅;
3、根据 netstat 的检查,使用 tcpdump 抓包分析一下为什么连接会被动断开(TCP知识非常重要);
4、如果熟悉代码应该直接去检查业务代码,如果不熟悉则可以使用 perf 把代码的调用链路打印出来;
5、不论是分析代码还是火焰图,到此应该能够很快定位到问题。 那么本次到底是为什么会出现CLOSE_WAIT呢?大部分同学应该已经明白了,我这里再简单说明一下:
由于那一行代码没有对事务进行回滚,导致服务端没有主动发起close。因此 MySQL负载均衡器 在达到 60s 的时候主动触发了close操作,但是通过tcp抓包发现,服务端并没有进行回应,这是因为代码中的事务没有处理,因此从而导致大量的端口、连接资源被占用。在贴一下挥手时的抓包数据:
# mysql 主动断开链接
11:38:45.693382 IP 172.18.0.3.3306 > 172.18.0.5.38822: Flags [F.], seq 123, ack 144, win 227, options [nop,nop,TS val 3000355 ecr 2997359], length 0 # MySQL负载均衡器发送fin包给我
11:38:45.740958 IP 172.18.0.5.38822 > 172.18.0.3.3306: Flags [.], ack 124, win 229, options [nop,nop,TS val 3000360 ecr 3000355], length 0 # 我回复ack给它
希望此文对大家排查线上问题有所帮助。为了便于帮助大家理解,下面附上正确情况下的火焰图与错误情况下的火焰图。大家可以自行对比。
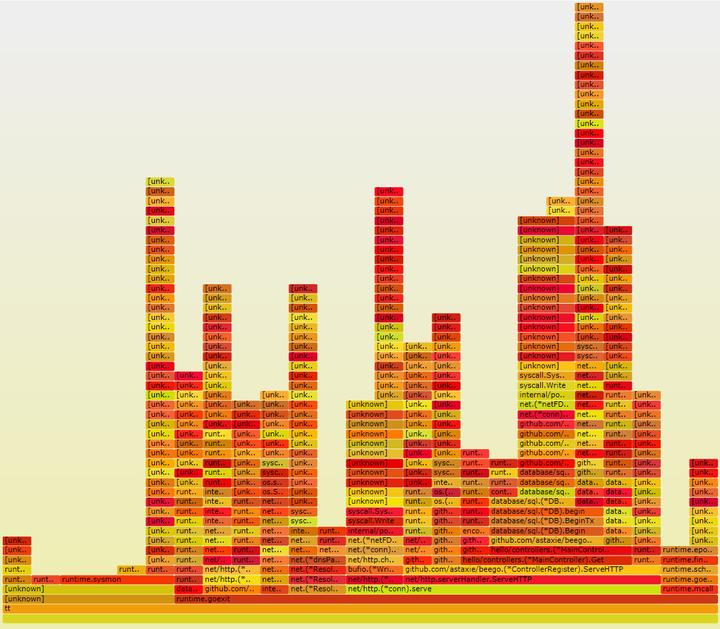
正确的火焰图
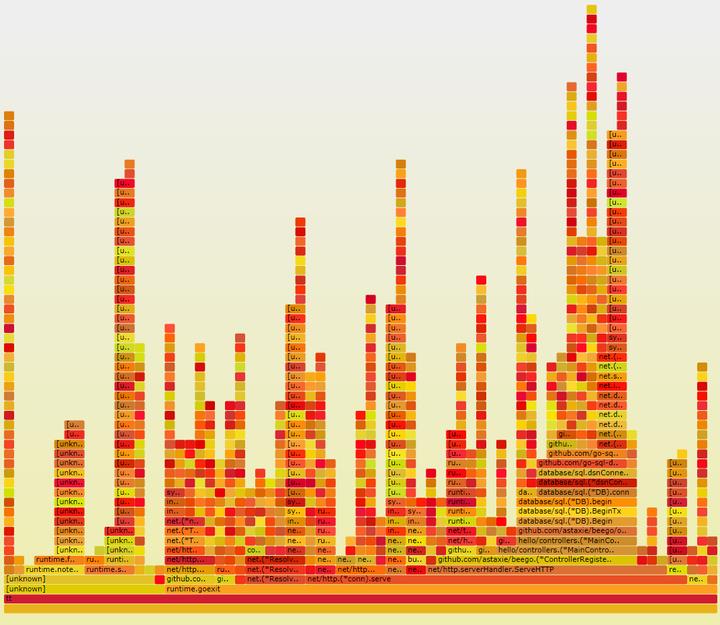
错误的火焰图
这里提出两个思考题,我觉得非常有意义,大家自己思考下:
- 为什么一台机器几百个 CLOSE_WAIT 就导致不可继续访问?我们不是经常说一台机器有 65535 个文件描述符可用吗?
- 为什么我有负载均衡,而两台部署服务的机器确几乎同时出了 CLOSE_WAIT ?
以上是关于线上大量CLOSE_WAIT的原因深入分析的主要内容,如果未能解决你的问题,请参考以下文章