全面学习Prometheus Posted 2021-04-02 分布式实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全面学习Prometheus相关的知识,希望对你有一定的参考价值。
Prometheus是继Kubernetes后第2个正式加入CNCF基金会的项目,容器和云原生领域事实的监控标准解决方案。在这次分享将从Prometheus的基础说起,学习和了解Prometheus强大的数据处理能力,了解如何使用Prometheus进行白盒和黑盒监控,以及Prometheus在规模化监控下的解决方案等。最后将从0开始构建完整的Kubernetes监控架构。
在《SRE:Google运维解密》一书中指出,监控系统需要能够有效的支持白盒监控和黑盒监控。通过白盒能够了解其内部的实际运行状态,通过对监控指标的观察能够预判可能出现的问题,从而对潜在的不确定因素进行优化。而黑盒监控,常见的如HTTP探针,TCP探针等,可以在系统或者服务在发生故障时能够快速通知相关的人员进行处理。通过建立完善的监控体系,从而达到以下目的:
长期趋势分析:通过对监控样本数据的持续收集和统计,对监控指标进行长期趋势分析。例如,通过对磁盘空间增长率的判断,我们可以提前预测在未来什么时间节点上需要对资源进行扩容。
对照分析:两个版本的系统运行资源使用情况的差异如何?在不同容量情况下系统的并发和负载变化如何?通过监控能够方便的对系统进行跟踪和比较。
告警:当系统出现或者即将出现故障时,监控系统需要迅速反应并通知管理员,从而能够对问题进行快速的处理或者提前预防问题的发生,避免出现对业务的影响。
故障分析与定位:当问题发生后,需要对问题进行调查和处理。通过对不同监控指标以及历史数据的分析,能够找到并解决根源问题。
数据可视化:通过可视化仪表盘能够直接获取系统的运行状态、资源使用情况、以及服务运行状态等直观的信息。
而对于上一代监控系统而言,在使用过程中往往会面临以下问题:
与业务脱离的监控:监控系统获取到的监控指标与业务本身也是一种分离的关系。好比客户可能关注的是服务的可用性、服务的SLA等级,而监控系统却只能根据系统负载去产生告警;
运维管理难度大:Nagios
可扩展性低: 监控系统自身难以扩展,以适应监控规模的变化;
问题定位难度大:当问题产生之后(比如主机负载异常增加)对于用户而言,他们看到的依然是一个黑盒,他们无法了解主机上服务真正的运行情况,因此当故障发生后,这些告警信息并不能有效的支持用户对于故障根源问题的分析和定位。
在上述需求中,我们可以提取出以下对于一个完善的监控解决方案的几个关键词:数据分析、趋势预测、告警、故障定位、可视化。
除此以外,当前越来越多的产品公司迁移到云或者容器的情况下,对于监控解决方案而言还需要另外一个关键词:云原生。
今天将从以下几个方面来介绍下一代监控解决方案Prometheus是如何解决以上问题的:
初识Prometheus
让数据会说话:PromQL与可视化
Alertmanager与告警处理;
白盒与黑盒监控
规模化监控解决方案
从0开始监控Kubernetes集群
Prometheus受启发于Google的Brogmon监控系统(相似的Kubernetes是从Google的Brog系统演变而来),从2012年开始由前Google工程师在Soundcloud以开源软件的形式进行研发,并且于2015年早期对外发布早期版本。2016年5月继Kubernetes之后成为第二个正式加入CNCF基金会的项目,同年6月正式发布1.0版本。2017年底发布了基于全新存储层的2.0版本,能更好地与容器平台、云平台配合。
从https://prometheus.io/download/获取最新的node exporter版本的二进制包后直接运行即可:
$ node_exportersource =" source ="node_exporter.go:50" source ="node_exporter.go:52" source ="node_exporter.go:52" source ="node_exporter.go:52" source ="node_exporter.go:52" source ="node_exporter.go:52" source ="node_exporter.go:52" source ="node_exporter.go:52" source ="node_exporter.go:52" source ="node_exporter.go:76"
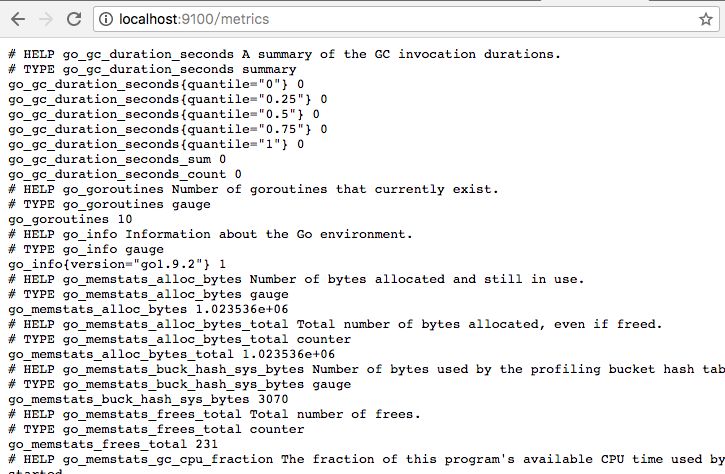
访问http://localhost:9100/metrics,可以看到Node Exporter获取到的当前主机的所有监控数据,如下所示:
每一个监控指标之前都会有一段类似于如下形式的信息:
# HELP node_cpu Seconds the cpus spent in each mode. # TYPE node_cpu counter node_cpu {cpu="cpu0" ,mode="idle" } 362812.7890625# HELP node_load1 1m load average. # TYPE node_load1 gauge node_load1 3.0703125
Node Exporter通过指标名称和标签返回了当前主机的监控样本数据。
从https://prometheus.io/download/找到最新版本的Prometheus Sevrer软件包,目前这里采用最新的稳定版本2.x.x。
创建配置文件prometheus.yml,如下所示:
global :15 s'node' 'localhost:9100' ]'prometheus' 'localhost:9090' ]$ prometheus --config.file=prometheus.yml --storage.tsdb.path=/data/prometheus"Server is ready to receive web requests." "scrape manager" msg="Starting scrape manager..."
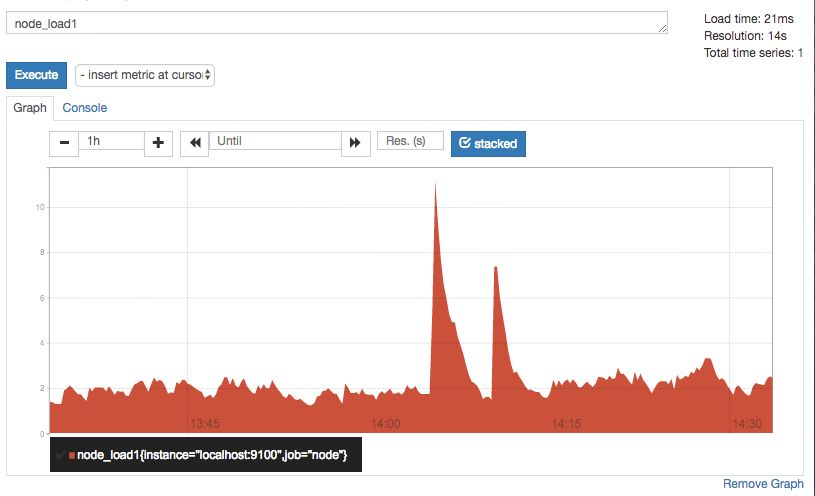
访问http://localhost:9090,进入到Prometheus Server。通过指标名称node_load1,可以找到当前采集到的主机负载的样本数据。
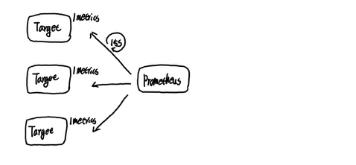
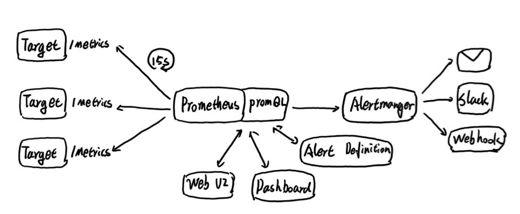
在上述的例子中,我们主要使用到了Node Exporter实例去获取主机的监控数据,一个运行的Node Exporter实例称为一个Target。Promthues周期性的从Node Exporter实例中获取监控样本,并保存到Promtheus基于本地磁盘实现的时间序列数据库中。
在Node Exporter的/metrics接口中返回的每一行监控数据,在Prometheus下称为一个样本。采集到的样本由以下三部分组成:
指标(metric):指标和一组描述当前样本特征的labelsets唯一标识;
时间戳(timestamp):一个精确到毫秒的时间戳,一般由采集时间决定;
样本值(value): 一个folat64的浮点型数据表示当前样本的值。
Prometheus会将所有采集到的样本数据以时间序列(time-series)的方式保存在内存数据库中,并且定时保存到硬盘上。每条time-series通过指标名称(metrics name)和一组标签集(labelset)命名。如下所示,可以将time-series理解为一个以时间为X轴的二维矩阵:
这种多维度的数据存储方式,可以衍生出很多不同的玩法。 比如,如果数据来自不同的数据中心,那么我们可以在样本中添加标签来区分来自不同数据中心的监控样本,例如:
node_cpu {cpu="cpu0" ,mode="idle" , dc="dc0" }
从内部实现上来看Prometheus中所有存储的监控样本数据没有任何差异,均是一组标签,时间戳以及样本值。
从存储上来讲所有的监控指标metric都是相同的,但是在不同的场景下这些metric又有一些细微的差异。 例如,在Node Exporter返回的样本中指标node_load1反应的是当前系统的负载状态,随着时间的变化这个指标返回的样本数据是在不断变化的。而指标node_cpu所获取到的样本数据却不同,它是一个持续增大的值,因为其反应的是CPU的累积使用时间,从理论上讲只要系统不关机,这个值是会无限变大的。
为了能够帮助用户理解和区分这些不同监控指标之间的差异,Prometheus定义了4中不同的指标类型(metric type):Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)。
Counter是一个简单但有强大的工具,例如我们可以在应用程序中记录某些事件发生的次数,通过以时序的形式存储这些数据,我们可以轻松的了解该事件产生速率的变化。PromQL内置的聚合操作和函数可以用户对这些数据进行进一步的分析:
例如,通过rate()函数获取HTTP请求量的增长率:
rate (http_requests_total [5m] )
与Counter不同,Gauge类型的指标侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。常见指标如:node_memory_MemFree(主机当前空闲的内容大小)、node_memory_MemAvailable(可用内存大小)都是Gauge类型的监控指标。
通过Gauge指标,用户可以直接查看系统的当前状态:
node_memory_MemFree
对于Gauge类型的监控指标,通过PromQL内置函数delta()可以获取样本在一段时间返回内的变化情况。例如,计算CPU温度在两个小时内的差异:
delta (cpu_temp_celsius{host="zeus" }[2h])
还可以使用deriv()计算样本的线性回归模型,甚至是直接使用predict_linear()对数据的变化趋势进行预测。例如,预测系统磁盘空间在4个小时之后的剩余情况:
predict_linear (node_filesystem_free{job="node" }[1h], 4 * 3600)
使用Histogram和Summary分析数据分布情况
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如CPU的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统API调用的平均响应时间为例:如果大多数API请求都维持在100ms的响应时间范围内,而个别请求的响应时间需要5s,那么就会导致某些WEB页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在010ms之间的请求数有多少而1020ms之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram和Summary都是为了能够解决这样问题的存在,通过Histogram和Summary类型的监控指标,我们可以快速了解监控样本的分布情况。
例如,指标prometheus_tsdb_wal_fsync_duration_seconds的指标类型为Summary。 它记录了Prometheus Server中wal_fsync处理的处理时间,通过访问Prometheus Server的/metrics地址,可以获取到以下监控样本数据:
prometheus_tsdb_wal_fsync_duration_seconds {quantile="0.5" } 0.012352463prometheus_tsdb_wal_fsync_duration_seconds {quantile="0.9" } 0.014458005prometheus_tsdb_wal_fsync_duration_seconds {quantile="0.99" } 0.017316173prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002prometheus_tsdb_wal_fsync_duration_seconds_count 216
从上面的样本中可以得知当前Promtheus Server进行wal_fsync操作的总次数为216次,耗时2.888716127000002s。其中中位数(quantile=0.5)的耗时为0.012352463,9分位数(quantile=0.9)的耗时为0.014458005s。
Prometheus对于数据的存储方式就意味着,不同的标签就代表着不同的特征维度。用户可以通过这些特征维度对查询,过滤和聚合样本数据。
例如,通过node_load1,查询出当前时间序列数据库中所有名为node_load1的时间序列:
node_load1
如果找到满足某些特征维度的时间序列,则可以使用标签进行过滤:
node_load1 {instance="localhost:9100" }
通过以标签为核心的特征维度,用户可以对时间序列进行有效的查询和过滤,当然如果仅仅是这样,显然还不够强大,Prometheus提供的丰富的聚合操作以及内置函数,可以通过PromQL轻松回答以下问题:
avg (irate(node_cpu{mode!="idle" }[2m])) without (cpu, mode)topk (5, avg(irate(node_cpu{mode!="idle" }[2m])) without (cpu, mode))predict_linear (node_filesystem_free{job="node" }[2h], 4 * 3600)
其中avg(),topk()等都是PromQL内置的聚合操作,irate(),predict_linear()是PromQL内置的函数,irate()函数可以计算一段时间返回内时间序列中所有样本的单位时间变化率。predict_linear函数内部则通过简单线性回归的方式预测数据的变化趋势。
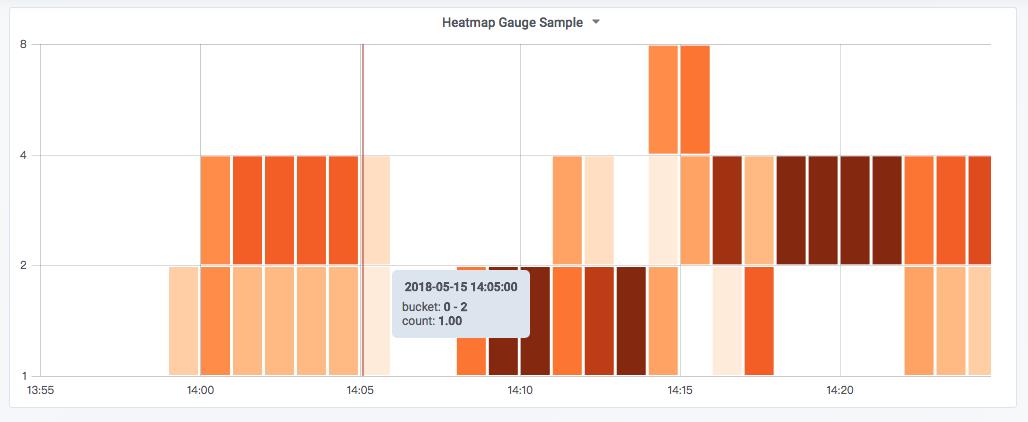
以Grafana为例,在Grafana中可以通过将Promtheus作为数据源添加到系统中,后再使用PromQL进行数据可视化。在Grafana v5.1中提供了对Promtheus 4种监控类型的完整支持,可以通过Graph Panel,Singlestat Panel,Heatmap Panel对监控指标数据进行可视化。
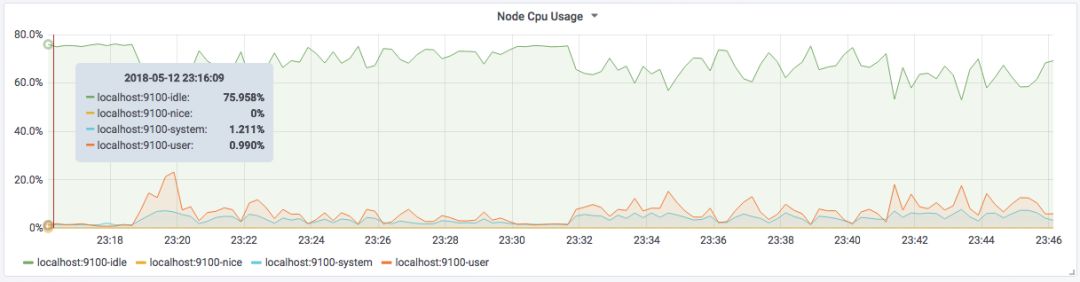
使用Graph Panel可视化主机CPU使用率变化情况:
Prometheus通过PromQL提供了强大的数据查询和处理能力。对于外部系统而言可以通过Prometheus提供的API接口,使用PromQL查询相关的样本数据,从而实现如数据可视化等自定义需求,PromQL是Prometheus对内,对外功能实现的主要接口。
关于Grafana与Promthues的使用案例详情可以参考:https://github.com/yunlzheng/prometheus-book/blob/master/grafana/README.md。
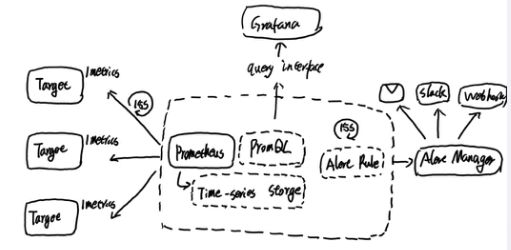
告警在Prometheus的架构中被划分成两个独立的部分:告警产生和告警处理。
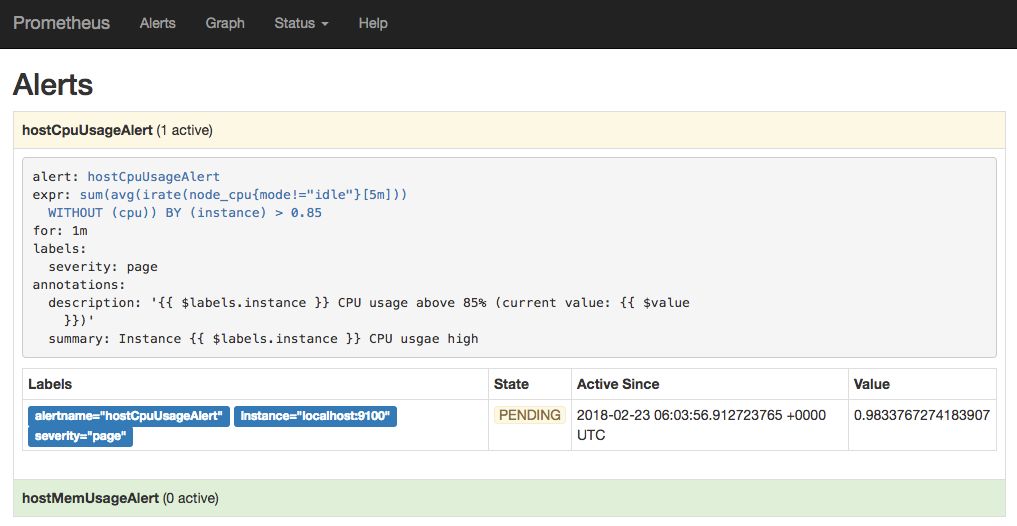
在Prometheus可以通过文件的形式定义告警规则,Promthues会周期性的计算告警规则中的PromQL表达式判断是否达到告警触发条件,如果满足,则在Prometheus内部产生一条告警。
yaml'idle' }[5 m]))) by (instance) > 0.85 for : 1 m"Instance {{ $labels .instance }} CPU usgae high" "{{ $labels .instance }} CPU usage above 85% (current value: {{ $value }})"
这里定义当主机的CPU使用率大于85%时,产生告警。告警状态将在Promethues的UI中进行展示。
到目前为止Promethues通过周期性的校验告警规则文件,从而在内部处罚告警。
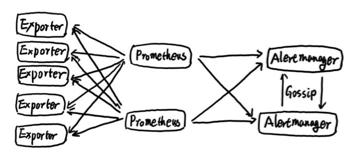
而后续的告警处理则由Alertmanager进行统一处理。Alertmanager作为一个独立的组件,负责接收并处理来自Prometheus Server(也可以是其它的客户端程序)的告警信息。Alertmanager可以对这些告警信息进行进一步的处理,比如消除重复的告警信息,对告警信息进行分组并且路由到正确的接受方,Alertmanager内置了对邮件,Slack等通知方式的支持,同时还支持与Webhook的通知集成,以支持更多的可能性,例如可以通过Webhook与钉钉或者企业微信进行集成。同时AlertManager还提供了静默和告警抑制机制来对告警通知行为进行优化。
关于Alertmanager的详细内容可以参考:https://github.com/yunlzheng/prometheus-book/blob/master/alert/README.md。
Prometheus作为是一个开源的完整监控解决方案,其对传统监控系统的check-alert模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。
在前面的部分中,我们主要介绍了Node Exporter的使用,对于这类Exporter而言,它们主要监控服务或者基础设施的内部使用状态,即白盒监控。通过对监控指标的观察能够预判可能出现的问题,从而对潜在的不确定因素进行优化。
而从完整的监控逻辑的角度,除了大量的应用白盒监控以外,还应该添加适当的黑盒监控。黑盒监控即以用户的身份测试服务的外部可见性,常见的黑盒监控包括HTTP探针、TCP探针等用于检测站点或者服务的可访问性,以及访问效率等。
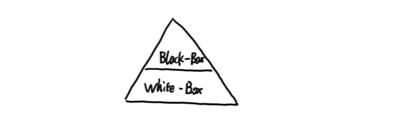
黑盒监控相较于白盒监控最大的不同在于黑盒监控是以故障为导向当故障发生时,黑盒监控能快速发现故障,而白盒监控则侧重于主动发现或者预测潜在的问题。一个完善的监控目标是要能够从白盒的角度发现潜在问题,能够在黑盒的角度快速发现已经发生的问题。
这里类比敏捷中著名的敏捷测试金字塔,对于完整的监控而言,我们需要大量的白盒监控,用于监控服务的内部运行状态,从而可以支持有效的故障分析。 同时也需要部分的黑盒监控,用于检测主要服务是否发生故障。
Blackbox Exporter是Prometheus社区提供的官方黑盒监控解决方案,其允许用户通过:HTTP、HTTPS、DNS、TCP以及ICMP的方式对网络进行探测。用户可以直接使用go get命令获取Blackbox Exporter源码并生成本地可执行文件。
Blackbox Exporter运行时,需要指定探针配置文件,例如blackbox.yml:
modules:
启动blackbox_exporter即可启动一个探针服务:
blackbox_exporter --config.file=/etc/ prometheus/blackbox.yml
启动后,通过访问http://127.0.0.1:9115/probe?module=http_2xx&target=baidu.com可以获得blackbox对baidu.com站点探测的结果。
probe_http_duration_seconds {phase="connect" } 0.055551141 probe_http_duration_seconds {phase="processing" } 0.049736019probe_http_duration_seconds {phase="resolve" } 0.011633673probe_http_duration_seconds {phase="tls" } 0probe_http_duration_seconds {phase="transfer" } 3.8919e-05# HELP probe_http_redirects The number of redirects # TYPE probe_http_redirects gauge probe_http_redirects 0# HELP probe_http_ssl Indicates if SSL was used for the final redirect # TYPE probe_http_ssl gauge probe_http_ssl 0# HELP probe_http_status_code Response HTTP status code # TYPE probe_http_status_code gauge probe_http_status_code 200# HELP probe_http_version Returns the version of HTTP of the probe response # TYPE probe_http_version gauge probe_http_version 1.1# HELP probe_ip_protocol Specifies whether probe ip protocol is IP4 or IP6 # TYPE probe_ip_protocol gauge probe_ip_protocol 4# HELP probe_success Displays whether or not the probe was a success # TYPE probe_success gauge probe_success 1
在Prometheus中可以通过添加响应的监控采集任务,即可获取对相应站点的探测结构样本数据:
- job_name: 'blackbox' params ://prometheus.io # Target to probe with http. //prometheus.io # Target to probe with https. //example.com:8080 # Target to probe with http on port 8080. 127.0 .0 .1 :9115
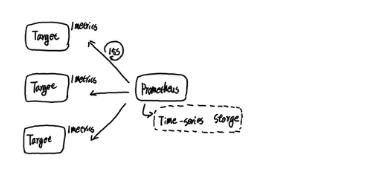
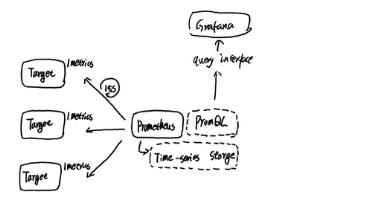
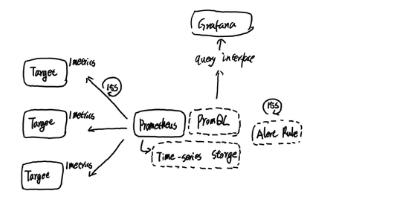
到目前为止,我们了解了Prometheus的基础架构和主要工作机制,如下所示:
Prometheus周期性的从Target中获取监控数据并保存到本地的time-series中,并且通过PromQL对外暴露数据查询接口。 内部周期性的检查告警规则文件,产生告警并有Alertmanager对告警进行后续处理。
那么问题来了,这里Prometheus是单点,Alertmanager也是单点。 这样的结构能否支持大规模的监控量?
对于Prometheus而言,要想完全理解其高可用部署模式,首先我们需要理解Prometheus的数据存储机制。
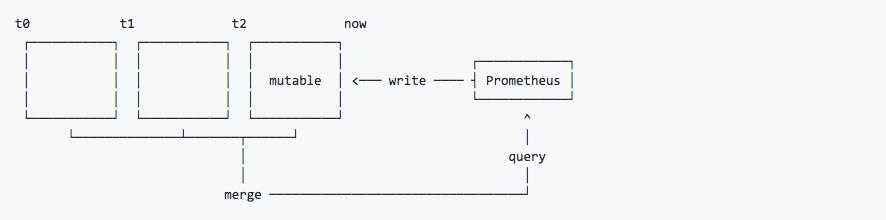
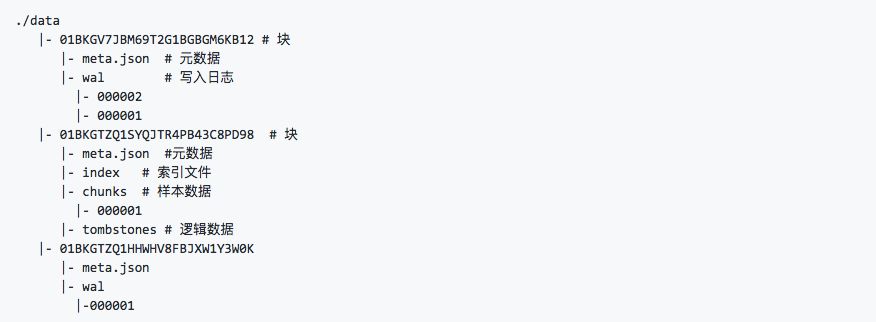
如上所示,Prometheus 2.x采用自定义的存储格式将样本数据保存在本地磁盘当中。按照两个小时为一个时间窗口,将两小时内产生的数据存储在一个块(Block)中,每一个块中包含该时间窗口内的所有样本数据(chunks),元数据文件(meta.json)以及索引文件(index)。
当前时间窗口内正在收集的样本数据,Prometheus则会直接将数据保存在内存当中。为了确保此期间如果Prometheus发生崩溃或者重启时能够恢复数据,Prometheus启动时会从写入日志(WAL)进行重播,从而恢复数据。此期间如果通过API删除时间序列,删除记录也会保存在单独的逻辑文件当中(tombstone)。
通过时间窗口的形式保存所有的样本数据,可以明显提高Prometheus的查询效率,当查询一段时间范围内的所有样本数据时,只需要简单的从落在该范围内的块中查询数据即可。而对于历史数据的删除,也变得非常简单,只要删除相应块所在的目录即可。
对于单节点的Prometheus而言,这种基于本地文件系统的存储方式能够让其支持数以百万的监控指标,每秒处理数十万的数据点。为了保持自身管理和部署的简单性,Prometheus放弃了管理HA的复杂度。
因此首先,对于这种存储方式而言,我们需要明确的几点:
Prometheus本身不适用于持久化存储长期的历史数据,默认情况下Prometheus只保留15天的数据。
本地存储也意味着Prometheus自身无法进行有效的弹性伸缩。
而当监控规模变得巨大的时候,对于单台Prometheus而言,其主要挑战包括以下几点:
服务的可用性,如何确保Prometheus不会发生单点故障;
监控规模变大的意味着,Prometheus的采集Job的数量也会变大(写)操作会变得非常消耗资源;
同时也意味着大量的数据存储的需求。
由于Prometheus的Pull机制的设计,为了确保Prometheus服务的可用性,用户只需要部署多套Prometheus Server实例,并且采集相同的Exporter目标即可。
基本的HA模式只能确保Prometheus服务的可用性问题,但是不解决Prometheus Server之间的数据一致性问题以及持久化问题(数据丢失后无法恢复),也无法进行动态的扩展。因此这种部署方式适合监控规模不大,Promthues Server也不会频繁发生迁移的情况,并且只需要保存短周期监控数据的场景。
在基本HA模式的基础上通过添加Remote Storage存储支持,将监控数据保存在第三方存储服务上。
当Prometheus在获取监控样本并保存到本地的同时,会将监控数据发送到Remote Storage Adaptor,由Adaptor完成对第三方存储的格式转换以及数据持久化。
当Prometheus查询数据的时候,也会从Remote Storage Adaptor获取数据,合并本地数据后进行数据查询。
在解决了Prometheus服务可用性的基础上,同时确保了数据的持久化,当Prometheus Server发生宕机或者数据丢失的情况下,可以快速的恢复。 同时Prometheus Server可能很好的进行迁移。因此,该方案适用于用户监控规模不大,但是希望能够将监控数据持久化,同时能够确保Prometheus Server的可迁移性的场景。
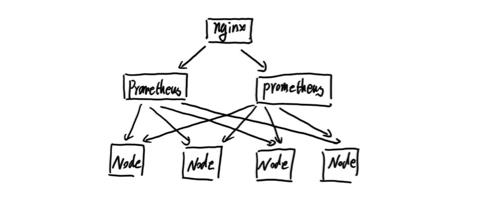
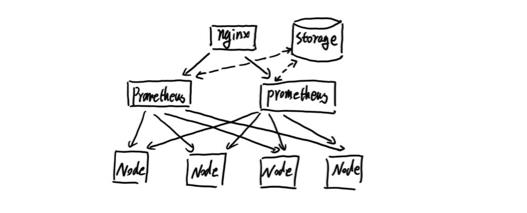
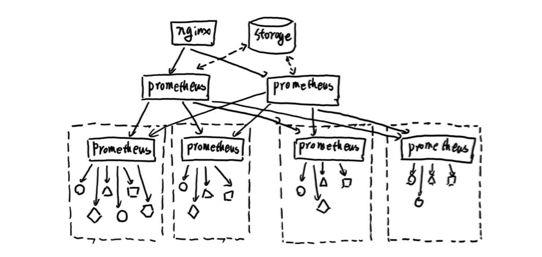
当单台Prometheus Server无法处理大量的采集任务时,用户可以考虑基于Prometheus联邦集群的方式将监控采集任务划分到不同的Prometheus实例当中即在任务级别功能分区。
这种场景下Prometheus的性能瓶颈主要在于大量的采集任务,因此用户需要利用Prometheus联邦集群的特性,将不同类型的采集任务划分到不同的Prometheus子服务中,从而实现功能分区。例如一个Prometheus Server负责采集基础设施相关的监控指标,另外一个Prometheus Server负责采集应用监控指标。再有上层Prometheus Server实现对数据的汇聚。
这种模式也适合与多数据中心的情况,当Prometheus Server无法直接与数据中心中的Exporter进行通讯时,在每一个数据中部署一个单独的Prometheus Server负责当前数据中心的采集任务是一个不错的方式。这样可以避免用户进行大量的网络配置,只需要确保主Prometheus Server实例能够与当前数据中心的Prometheus Server通讯即可。 中心Prometheus Server负责实现对多数据中心数据的聚合。
上面的部分,根据不同的场景演示了3种不同的高可用部署方案。当然对于Prometheus部署方案需要用户根据监控规模以及自身的需求进行动态调整,下表展示了Prometheus和高可用有关3个选项各自解决的问题,用户可以根据自己的需求灵活选择。
选项/需求 服务可用性 数据持久化 水平扩展
主备HA √
× ×
远程存储 × √
×
联邦集群 × × √
对于Alertmanager而言,Alertmanager集群之间使用Gossip协议相互传递状态,因此对于Prometheus而言,只需要关联多个Alertmanager实例即可,关于Alertmanager集群的详细详细可以参考:https://github.com/yunlzheng/prometheus-book/blob/master/ha/alertmanager-high-availability.md
对于诸如Kubernetes这类容器或者云环境,对于Prometheus而言,需要解决的一个重要问题就是如何动态的发现部署在Kubernetes环境下的需要监控的所有目标。
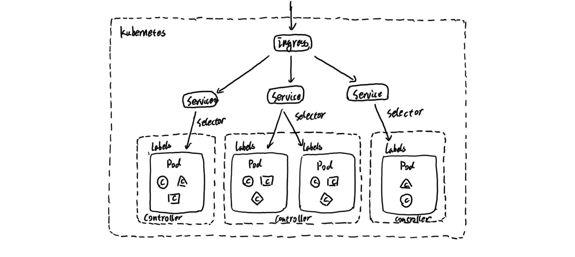
对于Kubernetes而言,如上图所示,我们可以把当中所有的资源分为几类:
基础设施层(Node):集群节点,为整个集群和应用提供运行时资源
容器基础设施(Container):为应用提供运行时环境
用户应用(Pod):Pod中会包含一组容器,它们一起工作,并且对外提供一个(或者一组)功能
内部服务负载均衡(Service):在集群内,通过Service在集群暴露应用功能,集群内应用和应用之间访问时提供内部的负载均衡
外部访问入口(Ingress):通过Ingress提供集群外的访问入口,从而可以使外部客户端能够访问到部署在Kubernetes集群内的服务
因此,在不考虑Kubernetes自身组件的情况下,如果要构建一个完整的监控体系,我们应该考虑,以下5个方面:
集群节点状态监控:从集群中各节点的kubelet服务获取节点的基本运行状态;
集群节点资源用量监控:通过Daemonset的形式在集群中各个节点部署Node Exporter采集节点的资源使用情况;
节点中运行的容器监控:通过各个节点中kubelet内置的cAdvisor中获取个节点中所有容器的运行状态和资源使用情况;
从黑盒监控的角度在集群中部署Blackbox Exporter探针服务,检测Service和Ingress的可用性;
如果在集群中部署的应用程序本身内置了对Prometheus的监控支持,那么我们还应该找到相应的Pod实例,并从该Pod实例中获取其内部运行状态的监控指标。
而对于Prometheus这一类基于Pull模式的监控系统,显然也无法继续使用的static_configs的方式静态的定义监控目标。而对于Prometheus而言其解决方案就是引入一个中间的代理人(服务注册中心),这个代理人掌握着当前所有监控目标的访问信息,Prometheus只需要向这个代理人询问有哪些监控目标控即可, 这种模式被称为服务发现。
Prometheus提供了对Kubernetes的完整支持,通过与Kubernetes的API进行交互,Prometheus可以自动的发现Kubernetes中所有的Node、Service、Pod、Endpoints以及Ingress资源的相关信息。
通过服务发现找到所有的监控目标后,并通过Prometheus的Relabling机制对这些资源进行过滤,metrics地址替换等操作,从而实现对各类资源的全自动化监控。
例如,通过以下流程任务配置,可以自动从集群节点的kubelet服务中内置的cAdvisor中获取容器的监控数据:
- job_name: 'kubernetes-cadvisor' var /run/secrets/kubernetes.io/serviceaccount/ca.crtvar /run/secrets/kubernetes.io/serviceaccount/tokendefault .svc:443 1 }/proxy/metrics/cadvisor
由或者是通过集群中部署的blackbox exporter对服务进行网络探测:
- job_name: 'kubernetes-services' metrics_path: /probeparams: module : [http_2xx ]kubernetes_sd_configs: role: servicerelabel_configs: source_labels: [__address__ ]target_label: __param_targettarget_label: __address__ replacement: blackbox-exporter.example.com: 9115 source_labels: [__param_target]target_label: instanceaction: labelmapregex: __meta_kubernetes_service_label_ (.+)source_labels: [__meta_kubernetes_namespace]target_label: kubernetes_namespacesource_labels: [__meta_kubernetes_service_name]target_label: kubernetes_name
由于线上分享的形式无法事无巨细的分享关于Prometheus的所有内容,但是希望大家能够通过今天的分享能够对Prometheus有更好的理解。
这里我也将关于Prometheus的相关实践通过电子书的形式进行了整理:https://github.com/yunlzheng/prometheus-book,希望能对大家学习和使用Prometheus起到一定的帮助作用,当然关于Prometheus的相关问题,也可以通过Github Issue来相互交流。
Q:Prometheus的数据能否自动同步到InfluxDB中?
A:可以,通过remote_write可以实现,可以参考:https://github.com/prometheus/prometheus/tree/master/documentation/examples/remote_storage/remote_storage_adapter。Prometheus通过将采集到的数据发送到Adaptor,再由Adaptor完成对数据格式的转换存储到InfluxDB即可。
Q:Prometheus一个Server最多能运行多少个Job?
A:这个没有做具体的试验,不过需要注意的是Job任务量(写操作),会直接影响Prometheus的性能,最好使用federation实现读写分离。
Q:请问告警由Grafana实现比较好,还是Alertmanager,常用的metric列表有没有汇总的清单链接分享下,历史数据默认保留时间如何设置?
A:Grafana自身是支持多数据源,Promethues只是其中之一。 如果只使用Promthues那用Alertmanager就好了,里面实现了很多告警去重和静默的机制,不然收到邮件轰炸也不太好。 如果需要基于Grafana中用到的多种数据源做告警的话,那就用Grafana。
Q:Prometheus监控数据推荐存哪里是InfluxDB,或者ES里面,InfluxDB单节点免费,多节的似乎收费的?
A:默认情况下,直接是保存到本地的。如果要把数据持久化到第三方存储只要实现remote_write接口就可以。理论上可以对接任意的第三方存储。 InfluxDB只是官方提供的一个示例之一。
Q:请问“再有上层Prometheus Server实现对数据的汇聚。”是表示该Prometheus会对下层Prometheus进行数据收集吗?使用什么接口?
A:请参考Prometheus Fedreation(https://prometheus.io/docs/prometheus/latest/federation/),这里主要是指由一部分Prometheus实例负责采集任务,然后Global的Prometheus汇集数据,并对外提供查询接口。 减少Global Prometheus的压力。
Q:两台Prometheus server 可否用Keepalived?
A:直接负载均衡就可以了,对于Prometheus而言,实例之间本身并没有任何的直接关系。
Q:用Prometheus监控业务的API接口,有什么好的方法吗,能监控数据库的慢查询吗?
A:在系统中集成client_library,直接在代码中埋点。可以参考这个例子:https://github.com/yunlzheng/prometheus-book/blob/master/exporter/custom_app_support_prometheus.md。
本次培训内容包括:Docker基础、容器技术、Docker镜像、数据共享与持久化、Docker三驾马车、Docker实践、Kubernetes基础、Pod基础与进阶、常用对象操作、服务发现、Helm、Kubernetes核心组件原理分析、Kubernetes服务质量保证、调度详解与应用场景、网络、基于Kubernetes的CI/CD、基于Kubernetes的配置管理等, 。
以上是关于全面学习Prometheus的主要内容,如果未能解决你的问题,请参考以下文章
此应用小部件片段中所有意图 (PendingIntents) 的逻辑流
详细实例说明+典型案例实现 对动态规划法进行全面分析 | C++
prometheus配置详解
普罗米修斯Prometheus介绍
在 Prometheus 中添加两个值
ROS实验笔记之——基于Prometheus的控制模块