这年头,机器翻译都会通过文字脑补画面了 | NAACL 2021
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了这年头,机器翻译都会通过文字脑补画面了 | NAACL 2021相关的知识,希望对你有一定的参考价值。
博雯 发自 凹非寺
量子位 报道 | 公众号 QbitAI
现在,想象一个外国人面前摆了句「金石迸碎荡尘埃,磐山纡水尽为开」。
除了痛苦地死抠复杂单词和长难句语法,他还能怎么去理解这句话呢?
——想象。
想象这句诗词中的“金石”、“尘埃”、“山水”各个词汇的意象,再将意象汇聚成一个具体的画面或场景。

而这时就有研究者灵机一动:
人类不是能根据非母语文本脑补画面,进而做到更深入的理解吗?
那机器是不是也能根据输入文本脑补图像,最终实现更好的翻译呢?
于是,一个以视觉想象为引导的机器翻译模型ImagiT就诞生了。

△已被NAACL 2021收录。
论文作者来自南洋理工大学和字节跳动人工智能实验室。
缺少图片也能利用视觉
提到“利用视觉”,我们首先会想到多模态机器翻译。
比起纯文本的机器翻译,多模态机器翻译能够利用语音、图像这样的模态信息来提高翻译质量。
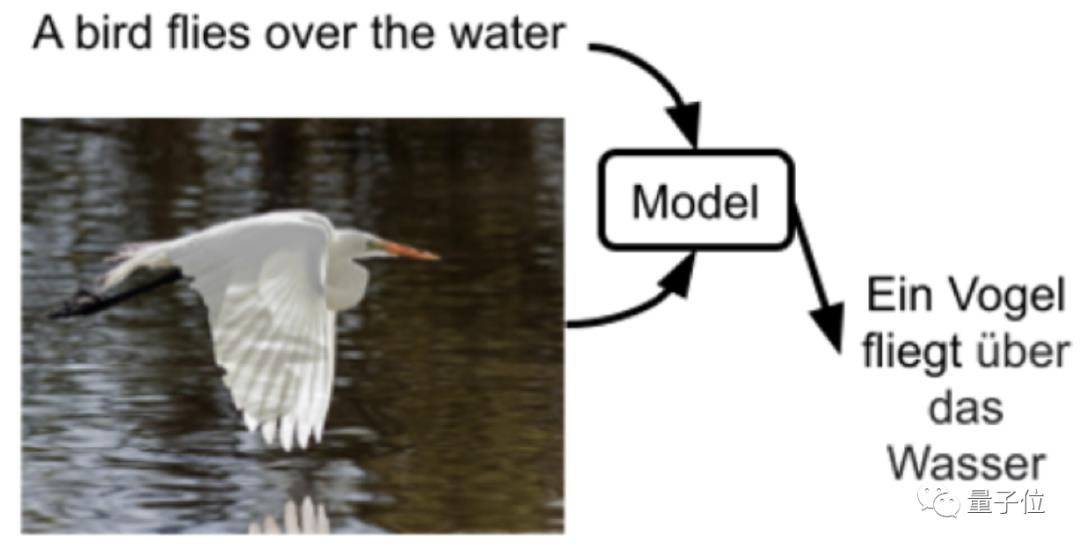
△多模态机器翻译的输入:源语言+标注的图片
但多模态机器翻译的质量是和数据集的可用性直接挂钩的。
换句话说就是标注图片的数量和质量会非常影响模型翻译的有效性。
但偏偏人工图片标注的成本又不低……所以现阶段的多模态机器翻译大都应用在Multi30K,一个包含了3万张图片标注的数据集上。
而新提出的ImagiT翻译模型呢?
它在推理阶段不需要标注图片作为输入,而是通过想象的方式利用视觉信号,在训练阶段将视觉语义蕴含到模型内部。

△多模态机器翻译的输入:源语言
做到了在缺少图片标注的情况下也能利用视觉信息。
基于想象的翻译模型到底什么样
这是一个端到端的对抗学习架构。
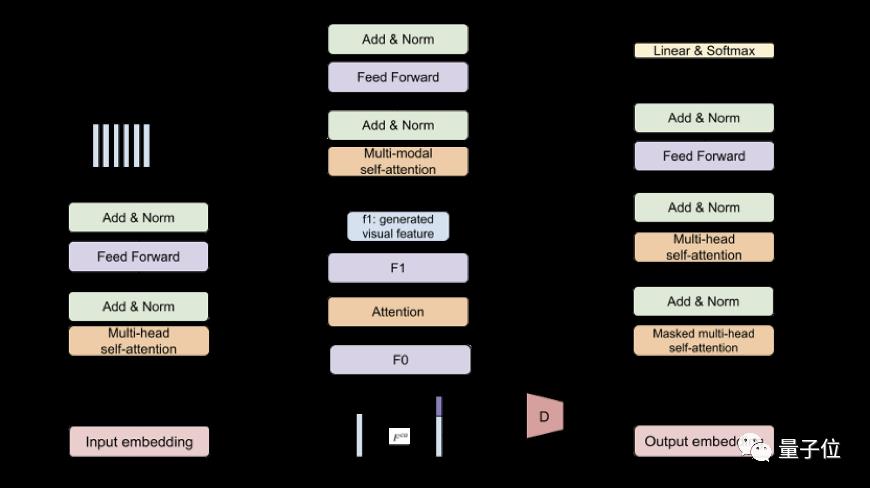
架构左右端是我们熟悉的transformer的编码器和解码器,而中间则是这一框架独特的生成想象网络。
这一生成想象网络主要由两个转化器和一个注意力层组成,具体做转化时:
一、源文本通过F0输入
F0包含一个全连接层和四个去卷积层。
基于GAN的思想,句子特征与噪声拼接后会通过F0转化成视觉表征。
二、将注意力放在词层面
在注意力层关注源文本中的相关词汇,并生成图像不同子区域的细粒度细节,让图像特征的子区域与词对应。
最终得到更加语义一致的视觉表征。
三、视觉表征通过F1输出
F1包含两个全连接层和一个去卷积层,以及一个残差层。
通过这一转化器,捕捉多层次(词级和句级)的语义,输出生成的视觉特征f1。
四、多模态聚合
把原本的文本模态和新合成的视觉特征聚合在一起。
五、翻译
模型的学习目标结合了文本到图片的生成,以及逆任务的图像字幕和翻译。
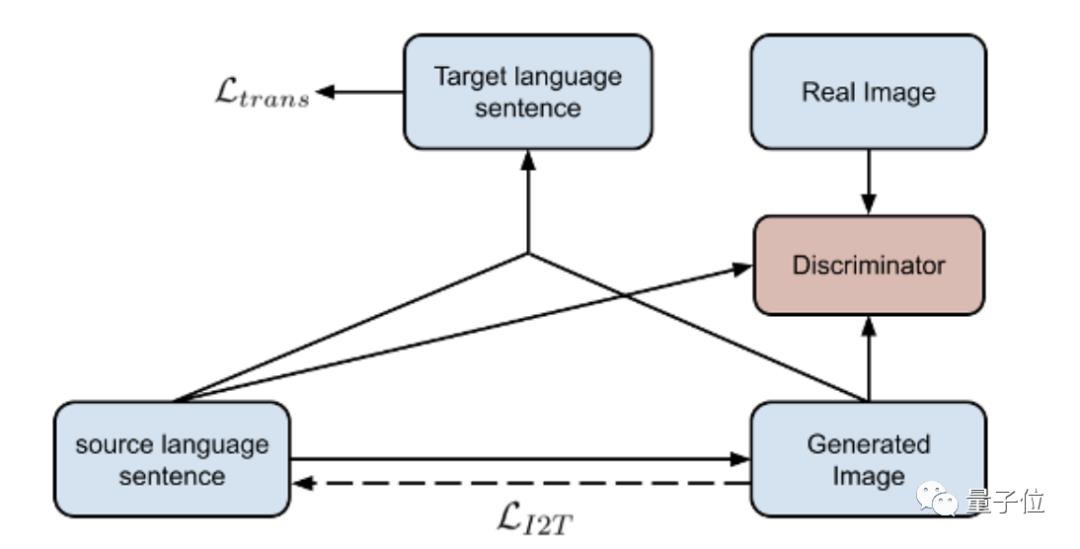
其中鉴别器源文本、生成图像和真实图像作为输入,用来评估合成图像是否与真实图片一致。
同时,也会使用条件对抗损失来评估合成的图像是否与源语言具有相同的语义。
“脑补”如何帮助翻译?
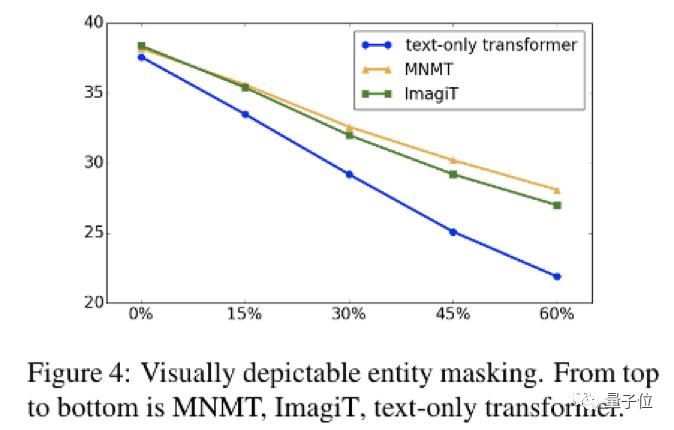
研究者使用了一种退化策略,即用特殊字符替换源语言文本中的重要词语,来观察模型的翻译表现会下降多少。
在这这种情况下,纯文本的翻译模型只能通过丢失词语的上下文和偏置来推理句子的翻译。
多模态机器翻译则会利用标注的图片进行翻译。
而ImagiT在缺少图片标注的情况下,还能根据退化的文本想象并恢复丢失的信息。
通过这一特殊的探索实验,可以看到ImagiT能在训练阶段学习特定词语(色彩,可被具象化的实体词等)与其他词语之间相关性和共现。
△将源语言文本中所有的色彩词全部替换为特殊字符。
而对比纯文本翻译,通过想象恢复被替换文本的ImagiT模型在翻译质量上下降的幅度也最少。
效果如何?
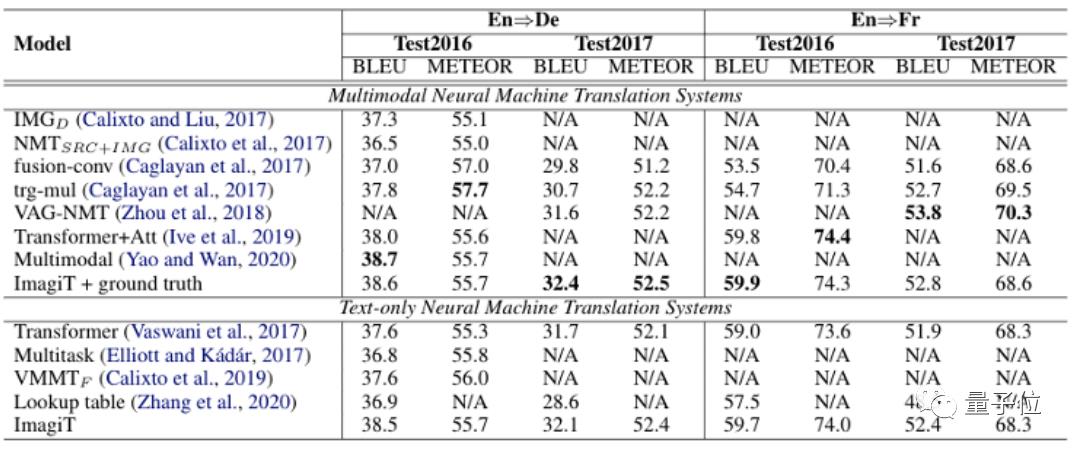
由于ImagiT不需要图片作为输入,所以在测试时选用纯文本的transformer模型作为baseline。
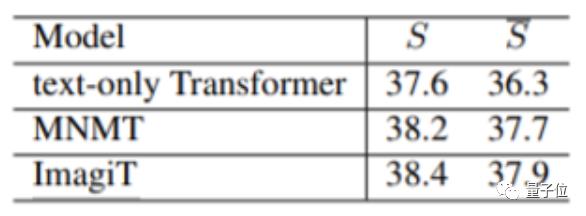
在Multi30K的英法、英德Test2016,Test2017上进行测试时,ImagiT得到了与SOTA多模态翻译系统相当的表现:
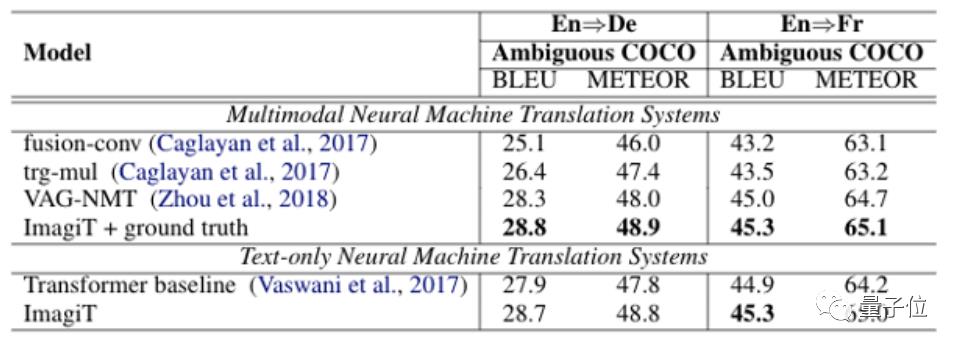
而在Ambiguous COCO上也展现出了不错的测试结果:
论文地址:
https://arxiv.org/abs/2009.09654
以上是关于这年头,机器翻译都会通过文字脑补画面了 | NAACL 2021的主要内容,如果未能解决你的问题,请参考以下文章
这年头不会Python看来是不行了,推荐一份Python书单!
只用一张图+相机走位,AI就能脑补周围环境,来自华人团队 | CVPR2022