清华&旷视让全连接层“内卷”,卷出MLP性能新高度
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了清华&旷视让全连接层“内卷”,卷出MLP性能新高度相关的知识,希望对你有一定的参考价值。
丰色 发自 凹非寺
量子位 报道 | 公众号 QbitAI
此前,清华大学与旷视科技曾通过结构重参数化将7年老架构VGG“升级”为性能直达SOTA的RepVGG模型。
如今,这个结构重参数化系列研究又添“新成员”:
他们提出一个基于多层感知器式的RepMLP模型,将卷积融合进全连接层 (FC)进行图像识别。

该模型同时组合了全连接层的全局建模、位置感知特性与卷积层的局部结构提取能力。
结果在ImageNet数据集、人脸识别任务及语义分割三方面都实现了识别精度的提升,且在大幅增加参数的同时不会造成推理速度的显著降低(增加47%参数,速度只下降2.2%)。
用卷积强化全连接,使之具有局部性又不失全局性
为什么要用卷积来强化全连接?
因为卷积网络具有局部先验特性,识别效果很不错。
在一张图片中,一个像素点跟它周围的像素点的关系往往比远在天边的另一个像素点更密切,这称为局部性。人类在识别图片的时候潜意识地利用这一点,称为局部先验。
而比起卷积层,全连接层的图像识别由于参数增多往往导致推理速度较慢和过拟合,但它具有更好的全局建模、位置感知能力。
所以研究人员将两者结合,在训练阶段,研究人员在RepMLP内部构建卷积层,而在推理阶段,将这些卷积层合并到全连接层内。
整个流程分为3步:
1、训练时,既有全连接层又有卷积,把两者的输出相加;
2、训练完成后,先把BN的参数“吸”到卷积核或全连接层中去,然后把每一个卷积转换成全连接层,把所有全连接层加到一起,等效去掉卷积。
3、保存并部署转换后的模型。
详细过程如下:
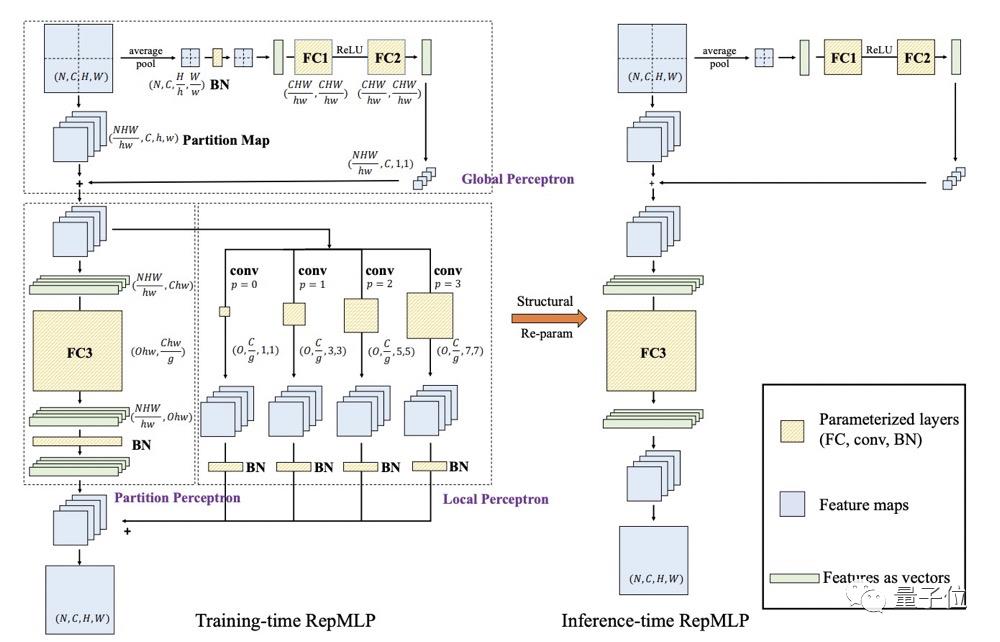
其中N、C、H、W分别代表batch size、输入通道数、高度和宽度;h 、 w 、 g 、p 、 O分别代表每一块分块(partition)的高度、宽度、组数、填充像素和输出通道。
首先将输入特征进行分块,分块会打破相同通道不同分块之间的相关性,因此全局感知(Global Perceptron)对每个分块添加相关性。
接着,分块感知(Partition Perceptron) 以分块特征作为输入,包含全连接层与BN层,进一步减少参数和计算量。
局部感知(Local Perceptron )将分块特征经由卷积核大小分别为1、3、5,、7的卷积层进行处理 ,将所有卷积分支的输出与分块感知的输出相加作为最终的输出 。
那如何将训练阶段的卷积转换为推理阶段的全连接层呢?

思路和RepVGG一样,利用了结构重参数化 (通过参数的等价转换实现结构的等价转换),将局部感知和分块感知的输出合并到全连接层进行推理,并去除卷积。
具体来说,
由于矩阵乘法的可加性(AX + BX = (A+B)X),一个稀疏且共享参数的全连接层(Toeplitz矩阵)加一个不稀疏不共享参数的FC(全自由度的矩阵),可以等价转换为一个全连接层(其参数是这两个矩阵之和),就可以在推理阶段将这些卷积等效地去掉。
另外,研究人员表示,之所以卷积和全连接层之间能建立联系,是因为卷积可以看成一个稀疏且存在重复参数的全连接层。
并“戏谑”道:
RepMLP这样做看起来像是让全连接层的“内部”含有卷积,所以也可以称为“内卷”。
实验结果
消融研究结果如下表,可以发现:
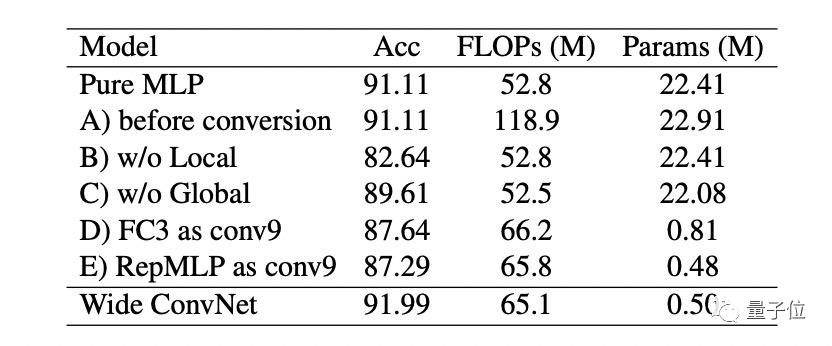
A为转换前的模型,计算量非常大,说明了结构重参数的重要性;
B为没有Local Perceptron的变体,精度下降8.5%,说明了局部先验的重要性;
C为没有Gloabl Perceptron的变体,精度下降1.5%,说明了全局建模的重要性;
D替换FC3为卷积,尽管其感受野更大,但仍造成精度下降3.5.%,说明全连接层比conv更强大,因为conv是降级的全连接层。
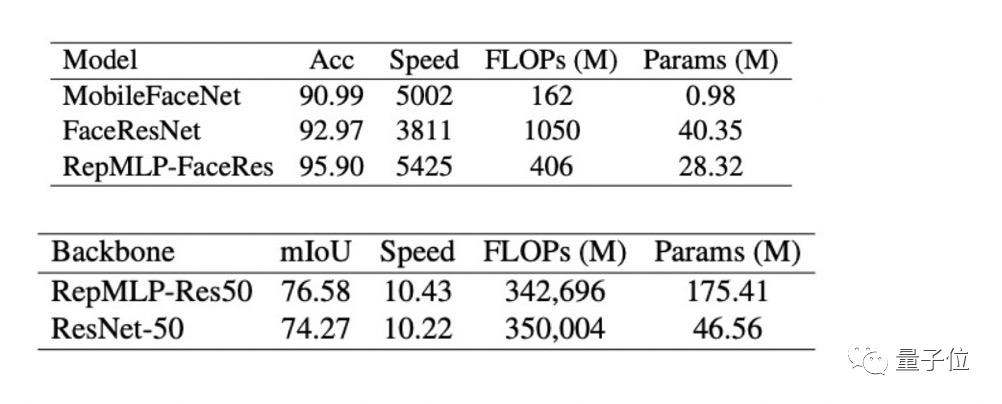
所以,用RepMLP替换Res50中的部分结构,将ResNets在ImageNet上的准确率提高了1.8%。
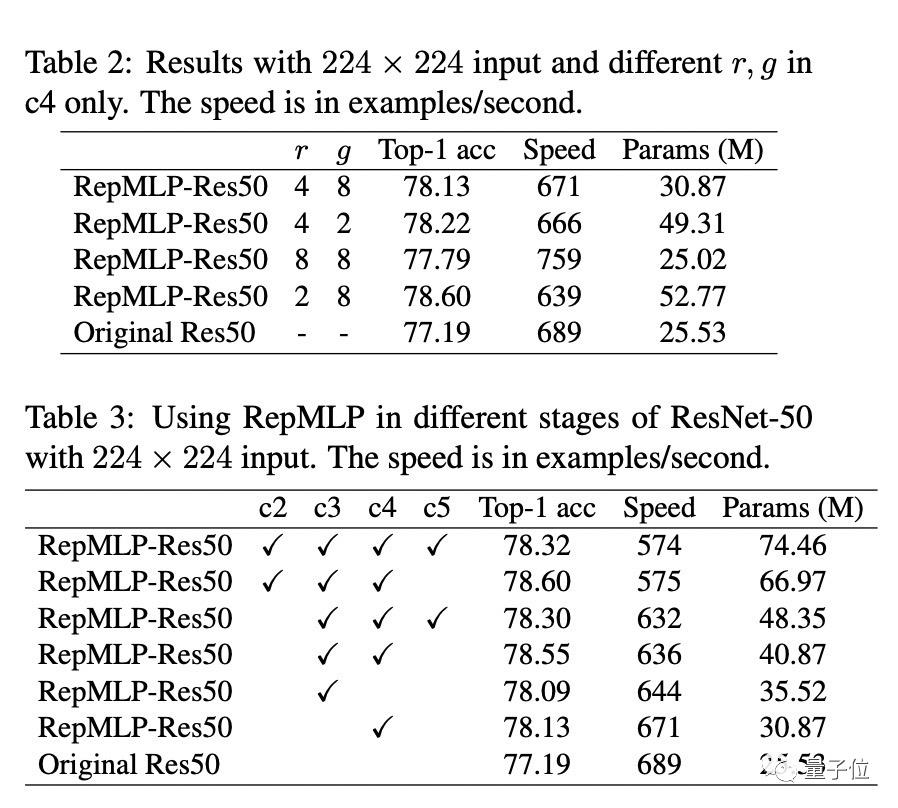
将ImageNet 预训练模型迁移到人脸识别和语义分割上,也都有性能提升,分别提升2.9%的准确率和2.3%的mIoU。
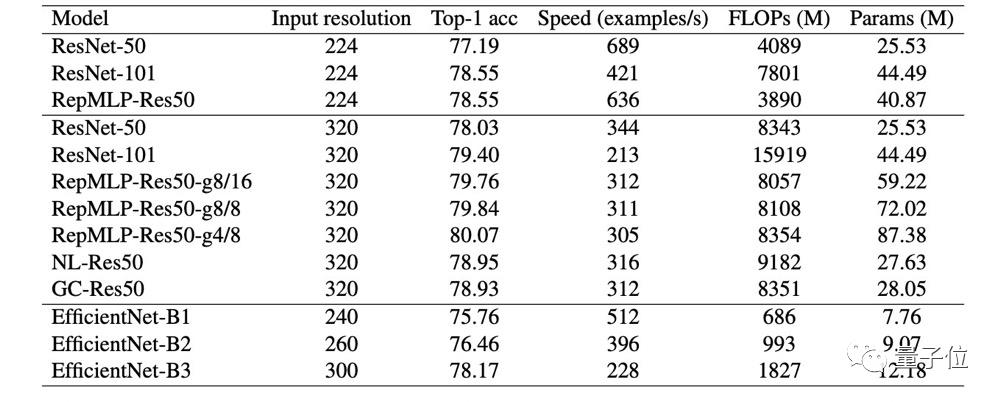
另外,在速度方面,RepMLP可以大幅增加参数的同时而对速度影响不大(参数增加47%,ImageNet精度提升0.31%,速度仅降低2.2%)。
论文地址:https://arxiv.org/abs/2105.01883
代码:https://github.com/DingXiaoH/RepMLP
以上是关于清华&旷视让全连接层“内卷”,卷出MLP性能新高度的主要内容,如果未能解决你的问题,请参考以下文章