实战派 | PaddlePaddle 你其实也可以真正地上手
Posted UAI人工智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实战派 | PaddlePaddle 你其实也可以真正地上手相关的知识,希望对你有一定的参考价值。
目录
0. 写在前面
1. 一些习惯及方法提炼
2. 图像识别入门
2.1 vgg 16网络
2.2 classification_cost函数
2.3 Momentum更新方法
2.4 其他
3. 总结
0. 写在前面:
百度开发的PaddlePaddle 作为一款开源深度学习框架,刚刚问世两年左右,虽然现在使用者数量和普及程度并不及 Caffe, TensorFlow 或者 Pytorch,但是毕竟是国产,这说明我们正在紧跟时代的浪潮,所以很有必要体验并且支持下百度的PaddlePaddle。这也是我写的第一篇深度学习框架体验笔记,如果大家有任何问题,也欢迎并期待大家可以和我多多交流。
百度官网上对这个框架的介绍是:PaddlePaddle (PArallel Distributed Deep Learning)是百度研发的深度学习平台,具有易用,高效,灵活和可伸缩等特点,为百度内部多项产品提供深度学习算法支持。这样一句话看起来也许可以很好的定义但似乎又抽象了一点。因为如何开始是摆在一些从未有过PaddlePaddle经验的工程师面前的问题。
作为一个资深工程师,我本人习惯以代码的角度切入,但我并不打算写一篇事无巨细的代码分析报告,在这里,我更愿意跟大家分享一种方法,我正在用这种方法学习 PaddlePaddle。当然,这种方法也有一定的适用范围,但是对我来说不管学习什么开源软件都是屡试不爽。更多的内容也许你们可以在观看视频的时候获得一些灵感。
在文章中我会显示或隐示地回答下面的一些问题:我们应该以一种什么方式开始学习?如何利用paddlepaddle?我们在学习之前应该具备哪些基本的能力?
本文将以一个具体例子来说明vgg模型和图像识别的流程(这也是PaddlePaddle官方的一个例子),虽然PaddlePaddle官网上也有一些说明,但是在这里我会以一个程序员的角度,从文档和源代码层面对一些比较重要的函数进行说明。
1. 一些习惯及方法提炼
对于上文所述的方法,我先用一个大家比较好懂的语言概括一下,那就是直接用工程师的方法看代码,再上手代码,如果需要学习paddlepaddle,我还同时建议大家可以再多会一两个其他框架,也便于更好的互相理解(这里先假定大家应该也已经有一定的其他框架的经验了,所以我就不详细展开了).
那应该具体怎么看代码,怎么上手代码呢?
首先我建议的是大家可以“粗略”浏览下代码先就好,看一个类的代码也要注意,如果类的命名不怎么好理解,这个时候就别吝啬自己动手记下来,如果有考虑修改,也可以做个标记,以后项目上手了,就直接动刀子,改成符合规范、命名清晰的。再次,对于看代码,需要粗看,就是看方法,看看这个类都干了什么,怎么跟其他的类进行数据交互等等这些。不要钻进去研究每句代码的实现,我们需要的是快速上手,所以,对代码有个整体的认识。
在对代码有了一定程度的了解之后,我们需要在实践中去熟悉代码,一行行的看代码,只会让你感觉疲倦,如果有人工智能项目相关的开发需求和任务,那么我们就可以充分利用起来,一边写代码,然后对关联类加以了解,这个时候,一行行的看代码,就不会疲倦了,因为有目的性,完成之后也有成就感。而代码就是在这样一点点的积累中熟悉起来的。
接下去就是上手了,既然是开源软件,所以我强烈建议大家下载源码并采用源码安装。还有一点就是要养成阅读各种文档的好习惯,比如源码路径下 doc/howto 中的文档,闲来无事的时候可以读一下,里面既有 build 整个工程的方法也有教大家贡献代码的方法(比如,new_op_cn.md 这个文件就如何写新的Operator进行了详细的说明,这对于阅读源代码也会有很大的帮助)。
下面闲话少叙,直奔主题
2. 图像识别入门
本文介绍的图像识别是 PaddlePaddle 官方的一个具体实例(http://www.paddlepaddle.org/docs/develop/book/03.image_classification/index.cn.html)这个例子的是利用 cifar-10 图像训练集对vgg 网络进行训练,整体流程在 train.py 文件里。实际上,这是个很通用的流程,从训练集来说,我们即可以用 cifar-10,也可以用其他训练集,比如ImageNet,甚至是自己标注的训练集;对于网络来说,我们即可以用 vgg16,也可以用ResNet,当然也可以用自己搭建的网络结构,在这个例子中,我们可以随意的使用各种我们想实现的网络和数据集的组合。
2.1 vgg 16网络
我们首先来看其中用到的网络模型 vgg16
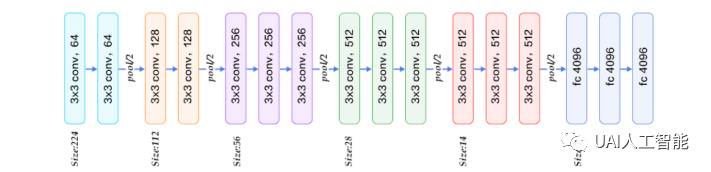
图1(引用自http://www.paddlepaddle.org/docs/develop/book/03.image_classification/index.cn.html图六)
vgg 是一个非常简洁的深度神经网络,我们这里主要关注的是上图中的网络结构。
为了有个直观的理解,我们在看paddlepaddle代码之前先浏览下 keras 实现 vgg的代码,之后在对比 paddlepaddle的实现,大家可以下载keras源码查看,以下代码位于keras-master/keras/applications/vgg16.py:
111 # Block 1
112 x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(img_input)
113 x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
114 x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
115
116 # Block 2
117 x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
118 x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
119 x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
120
121 # Block 3
122 x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
123 x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2')(x)
124 x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3')(x)
125 x = MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
126
127 # Block 4
128 x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
129 x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2')(x)
130 x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3')(x)
131 x = MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
132
133 # Block 5
134 x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
135 x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2')(x)
136 x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3')(x)
137 x = MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
keras的一大优点就是接口封装的相当简洁,命名规则也是一目了然,从接口名字就可以猜到功能,从参数名字就能知道作用。以上代码就是一个典型的例子,对照图1从Block1 到 Block5的描述和图中的结构完全一致,每个 Block 都是由两到三个卷积层加上一个池化层构成。具体的接口说明在这里不做过多的说明,有兴趣的同学可以参看 keras 相关的文档对接口参数做更详细的了解。
我们下面主要看下paddlepaddle对 vgg 网络的描述,代码在 vgg.py文件。
其中只定义了一个函数vgg_bn_drop,这个函数把整个 vgg16 都封装在 conv_block 函数里面,而 conv_block 本身只用到了一个 paddlepaddle 内部定义的函数 img_conv_group。
21 def conv_block(ipt, num_filter, groups, dropouts, num_channels=None):
22 return paddle.networks.img_conv_group(
23 input=ipt,
24 num_channels=num_channels,
25 pool_size=2,
26 pool_stride=2,
27 conv_num_filter=[num_filter] * groups,
28 conv_filter_size=3,
29 conv_act=paddle.activation.Relu(),
30 conv_with_batchnorm=True,
31 conv_batchnorm_drop_rate=dropouts,
32 pool_type=paddle.pooling.Max())
33
34 conv1 = conv_block(input, 64, 2, [0.3, 0], 3)
35 conv2 = conv_block(conv1, 128, 2, [0.4, 0])
36 conv3 = conv_block(conv2, 256, 3, [0.4, 0.4, 0])
37 conv4 = conv_block(conv3, 512, 3, [0.4, 0.4, 0])
38 conv5 = conv_block(conv4, 512, 3, [0.4, 0.4, 0])
简单的说, vgg.py文件最需要说明的是 img_conv_group,我们对照文档来看下函数的相关参数(文档位置:Documentation →API → Networks → img_conv_group):
Image Convolution Group, Used for vgg net.
Parameters: |
· conv_batchnorm_drop_rate (list) – if conv_with_batchnorm[i] is true, conv_batchnorm_drop_rate[i] represents the drop rate of each batch norm. · input (LayerOutput) – input layer. · conv_num_filter (list|tuple) – list of output channels num. · pool_size (int) – pooling filter size. · num_channels (int) – input channels num. · conv_padding (int) – convolution padding size. · conv_filter_size (int) – convolution filter size. · conv_act (BaseActivation) – activation funciton after convolution. · conv_with_batchnorm (list) – if conv_with_batchnorm[i] is true, there is a batch normalization operation after each convolution. · pool_stride (int) – pooling stride size. · pool_type (BasePoolingType) – pooling type. · param_attr (ParameterAttribute) – param attribute of convolution layer, None means default attribute. |
Returns: |
layer’s output |
从 conv1 到 conv5 对应了vgg16 模型的5个 block(图1中颜色相同的层组成一个 block,除去最后三个全连接层一共有5个block)
第一个Block –-→ conv1 = conv_block(input, 64, 2, [0.3, 0], 3)
input 是输入图像;64代表了这一个 block 中的每个卷积层有 64 个 feature map;2 代表了有两个卷积层;[0.3 0] 分别代表每个卷积层 dropout 的概率;3 代表了输入图像的 chanel 个数(RGB或者 BGR,这里如果是第一层的输入要有个这个参数)。
第二个Block –-→ conv2 = conv_block(conv1, 128, 2, [0.4, 0]):
conv1 代表整个 block 的输入,也就是上一个 block的输出;128 代表了这一个 block 中的每个卷积层有 128 个 feature map; 2 代表了有两个卷积层;[0.4 0] 分别代表每个卷积层 dropout 的概率。
以下 conv3 ~ conv5 参数的含义相同,不再赘述。
但是这里有个问题,图中每个 block 都是有两个或三个卷积层加上一个 pooling 层组成的(在 keras 代码里非常清楚), 而 conv_block 中只表明了卷积层的个数以及与之相关的参数,并没有对 pooling 层做任何说明,所以猜测 pooling 层肯定是被封装到了 img_conv_group 里面,为了验证,我们看下 img_conv_group 函数的源代码(Paddle-develop/python/paddle/trainer_config_helpers/networks.py):
336 def img_conv_group(input,
337 conv_num_filter,
338 pool_size,
339 num_channels=None,
340 conv_padding=1,
341 conv_filter_size=3,
342 conv_act=None,
343 conv_with_batchnorm=False,
344 conv_batchnorm_drop_rate=0,
345 pool_stride=1,
346 pool_type=None,
347 param_attr=None):
…
434 return img_pool_layer(
435 input=tmp, stride=pool_stride, pool_size=pool_size, pool_type=pool_type)
果然, 我们发现img_conv_group函数最后有一层 pooling。这样的检查是有必要的,因为在不确定的情况下,我们需要检查源码以保证封装的正确性,以免后来补救,这样花费的时间成本极大。
再下面就是两个全连接层,中间夹着一个 batch_norm,vgg 就此结束。
40 drop = paddle.layer.dropout(input=conv5, dropout_rate=0.5)
41 fc1 = paddle.layer.fc(input=drop, size=512, act=paddle.activation.Linear())
42 bn = paddle.layer.batch_norm(
43 input=fc1,
44 act=paddle.activation.Relu(),
45 layer_attr=paddle.attr.Extra(drop_rate=0.5))
46 fc2 = paddle.layer.fc(input=bn, size=512, act=paddle.activation.Linear())
47 return fc2
(这里的batch_norm其实并非是一个真正的层,它的作用就是将网络上一层的输出数据转换成正态分布)
这里还是有个问题,图1中vgg最后是三个全连接层,但是代码在这里只定义了两个,读到这里感觉很困惑。
其实在 train.py 文件里 vgg_bn_drop 被调用的下面紧接着还有一个全连接层:
39 net = vgg_bn_drop(image)
40
41 out = paddle.layer.fc(
42 input=net, size=classdim, act=paddle.activation.Softmax())
至此,vgg16 整个网络的所有结构才算全部定义完成。
2.2 classification_cost函数
cost = paddle.layer.classification_cost(input=out, label=lbl)
这里的 classification_cost函数,搜遍整个文档没有找到函数说明,所以只能上源代码(Paddle-develop/python/paddle/trainer_config_helpers/layers.py):
4576 def classification_cost(input,
4577 label,
4578 weight=None,
4579 name=None,
4580 evaluator=classification_error_evaluator,
4581 layer_attr=None,
4582 coeff=1.):
…
4612 Layer(
4613 name=name,
4614 type="multi-class-cross-entropy",
4615 inputs=ipts,
4616 coeff=coeff,
4617 **ExtraLayerAttribute.to_kwargs(layer_attr))
我想说明的是,这里使用了 Layer,并指明type="multi-class-cross-entropy",即多类交叉熵。
一般来说,像数学模型,比如multi-class-cross-entropy的真正实现都是底层c++(Paddle-develop/paddle/gserver/layers/Layer.cpp):
106 if (type == "multi-class-cross-entropy")
107 return LayerPtr(new MultiClassCrossEntropy(config));
MultiClassCrossEntropy定义(Paddle-develop/paddle/gserver/layers/CostLayer.h):
59 /**
60 * The cross-entropy loss for multi-class classification task.
61 * The loss function is:
62 *
63 * f[
64 * L = - sum_{i}{t_{k} * log(P(y=k))}
65 * f]
66 */
67 class MultiClassCrossEntropy : public CostLayer {
68 public:
69 explicit MultiClassCrossEntropy(const LayerConfig& config)
70 : CostLayer(config) {}
71
72 bool init(const LayerMap& layerMap,
73 const ParameterMap& parameterMap) override;
74
75 void forwardImp(Matrix& output, Argument& label, Matrix& cost) override;
76
77 void backwardImp(Matrix& outputValue,
78 Argument& label,
79 Matrix& outputGrad) override;
80 };
从函数说明的注释看,这个函数就是在实现多类交叉熵,注释中的公式说明这一点,而且这个类分别实现了forward和 backward。并且注意到 Layer.cpp里面每一层都有 forward和 backward的实现。
以上就从根本上解决了 classification_cost没有文档说明的问题。
2.3 Momentum更新方法
51 # Create optimizer
52 momentum_optimizer = paddle.optimizer.Momentum(
53 momentum=0.9,
54 regularization=paddle.optimizer.L2Regularization(rate=0.0002 * 128),
55 learning_rate=0.1 / 128.0,
56 learning_rate_decay_a=0.1,
57 learning_rate_decay_b=50000 * 100,
58 learning_rate_schedule='discexp')
关于momentum 的算法文档里有数学描述(Documentation →API → Optimizer → Momentum):
这里参数sparse=False,这种是默认情况,momentum的更新公式:
其中 k 是 momentum,lambda 是衰减率,gamma_t是第 t 次迭代的学习率,有关momentum更新方式的说明,强烈推荐 stanford 公开课 cs231n,其中有关网络训练的说明(http://cs231n.github.io/neural-networks-3/)对各种参数更新方法有详细的说明。
就代码而言, paddle.optimizer.Momentum 中的第一个参数 momentum会用作实例化MomentumOptimizer(Paddle-develop/python/paddle/trainer_config_helpers)类型的对象,其他参数会被传递到 Optimizer类(Paddle-develop/python/paddle/v2)构造函数的__impl__里面(代码中的31行):
25 class Optimizer(object):
26 def __init__(self, **kwargs):
27 import py_paddle.swig_paddle as swig_api
28 if 'batch_size' in kwargs:
29 del kwargs['batch_size'] # not important for python library.
30
31 def __impl__():
32 v1_optimizers.settings(batch_size=1, **kwargs)
33
34 self.__opt_conf_proto__ = config_parser_utils.parse_optimizer_config(
35 __impl__)
36 self.__opt_conf__ = swig_api.OptimizationConfig.createFromProto(
37 self.__opt_conf_proto__)
v1_optimizers.settings的定义在Paddle-develop/python/paddle/trainer_config_helpers/optimizers.py
358 def settings(batch_size,
359 learning_rate=1e-3,
360 learning_rate_decay_a=0.,
361 learning_rate_decay_b=0.,
362 learning_rate_schedule='poly',
363 learning_rate_args='',
364 learning_method=None,
365 regularization=None,
366 is_async=False,
367 model_average=None,
368 gradient_clipping_threshold=None):
2.4 其他
后面就是一些中规中矩的流程,包括回调函数 event_handler 打印一些中间结果,并保存权重训练的中间结果,再后面就是对网络的训练以及 test 集的测试。
3. 总结:
本文对一个具体的图像识别的例子做了说明,但并不是每一个步骤都很具体,这是因为本文想带来一种方法而不是简单的代码解释。
这种方法就是通过示例代码---->文档---->源代码的阅读顺序一步一步理解示例中一些重要函数背后的实现,当文档描述不清楚甚至根本没有对示例代码中某些接口进行说明时,我们只有阅读源码才能理解示例中究竟用了什么数学方法,这就体现了源代码的价值。
由于准备时间比较仓促,其中可能会有些不清楚甚至错误,希望大家指出来共同进步。
点击“阅读原文”报名AI成长社
以上是关于实战派 | PaddlePaddle 你其实也可以真正地上手的主要内容,如果未能解决你的问题,请参考以下文章