不懂高数也能入门深度学习--PaddlePaddle入门和实战
Posted 云算计
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不懂高数也能入门深度学习--PaddlePaddle入门和实战相关的知识,希望对你有一定的参考价值。
百度PaddlePaddle之新手入门培训视频(http://bit.baidu.com/course/detail/id/137.html)是一篇很好的机器学习的基础知识普及教程,该视频作者是百度乔龙飞,我认真学几遍以后,写了这个学习笔记。
从本文的重点也可以看到两个问题,为什么模型训练过程不可控,为什么清洗过的数据可以给外人去计算。
PaddlePaddle课程公开的链接:http://ai.baidu.com/paddlepaddle 有更多PaddlePaddle学习资料请登录该网站查看。
1. 学前准备
本原始视频和学习笔记的目标读者是从事IT工作,想学习AI技术的专业人员;本视频讲的就是AI基础知识,让新用户打好理论基础,并且希望通过本次视频和学习笔记,逐步将AI爱好者引导至百度PaddlePaddle开源框架。如果是非IT人员仅仅想了解行业,还是建议看《》这篇文章。
本视频讲了主要这些内容:
什么是机器学习/深度学习,以及简单分类。
什么是模型。
什么是假设函数。
什么是损失函数。
(重点)梯度下降训练模型。
一个典型案例的说明和准备
(重点)数据预处理
设计假设函数和损失函数
训练和观测结果
多数人对AI学习的概念很模糊,以为这是个半年时间就能学有所成的技术,但是“做AI”和“用AI”的区别很大。“做AI”的要求很高,我从各个渠道获取的信息,不是藤校硕博就别梦想自研算法了;但“用AI”的要求并不高。
以这一节入门培训视频为例,有数学基础更好,没有高数基础听起来会很吃力,但多听几次查查百科也能听懂;实验实操部分使用的Docker部署环境和Jupyter电子书操作,对计算机水平要求也不高,能安装运行起Docker,能读懂Python常规语法即可。
2. 深度学习和机器学习的关系
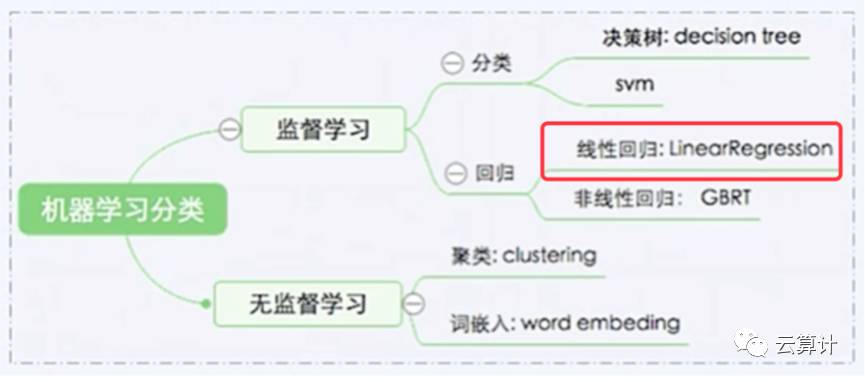
深度学习是机器学习的最热门分支,这句话足以解释深度学习和机器学习的关系。机器学习可以分为有监督学习和无监督学习,监督学习主要解决分类和回归问题,无监督学习最主流的算法是聚类和词嵌入。
今天的课程只讲解监督学习的线性回归问题,这个经典的模型足以解释在深度学习中遇到的大部分基础问题。
3. 模型是什么
在监督学习过程中,一个Feature(特征)和对应的Label(标签)被称为一个样本(example),所有样本的集合被称为数据集(dataset)。图片识别过程中,原始图片是特征,图片的实际内容是标签;语音翻译过程中,原始语音是特征,输出的文字是标签;本节课的房价预测实验中,房价有关的13类信息是特征,预估出的房价是标签。
监督学习中,模型就是尝试描述已知数据特征和数值的关系,来推演出新的数据特征对应的新的数值的关系。
模型有两大关键概念,拟合描述和泛化预测。其中拟合描述已有数据之间的映射关系(Fit)就是日常说的样本训练,根据模型对未知数据做泛化预测(GeneraLization)就是推演。
我们看一个极简版的线性回归模型场景,假设第一个数字是2,第二个数字是4,第四个数字是8,第三个数字应该是多少?这个场景虽然简单,但麻雀虽小五脏俱全,将前文提到的几个概念全部列出来了。

4. 模型的质量
机器学习的主要工作就是训练合格的模型,这一步有两个重要概念,分别是假设函数(Hypothesis Function)和损失函数(Cost Function)。
首先看假设函数,假设函数就是用数学方法描述自变量X和因变量Y的关系,就是上文模型中的那个“y=θx”中的“saita(θ)”,这个例子只是一个最简单的线型假设函数,后面实验部分就能看到13个θ的复杂函数。
下图是一个房价和人口关系的预测场景,这里最简单的趋势就是人口越多房价越高,做出来一个单变量先行假设函数,在下图中用一条蓝色的直线标识。
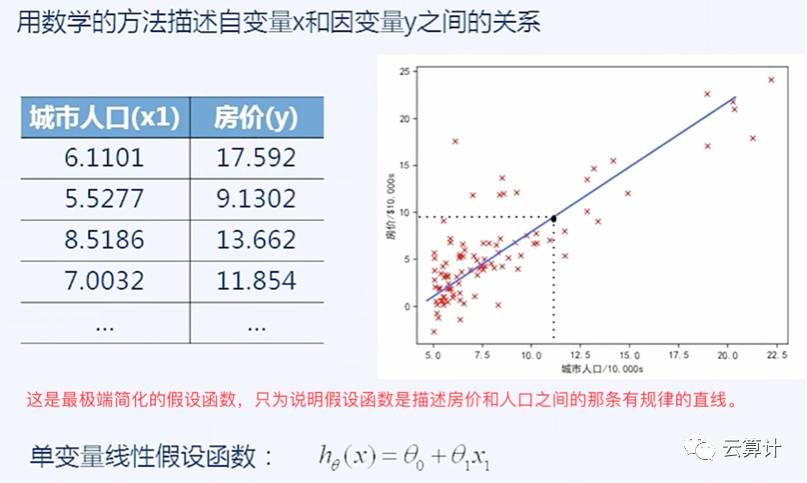
上图中是极简化抽象的假设函数的例子很简单,但实际上可能非常复杂。比如说可能假设函数不是“y=θx”,而是“y=θ0+θ1x+θ2x+θ3x+θ4x……”,本文中打字不方便用下标,只是想说明假设函数可能有几十上百甚至上万个θ值,即上万个模型参数。
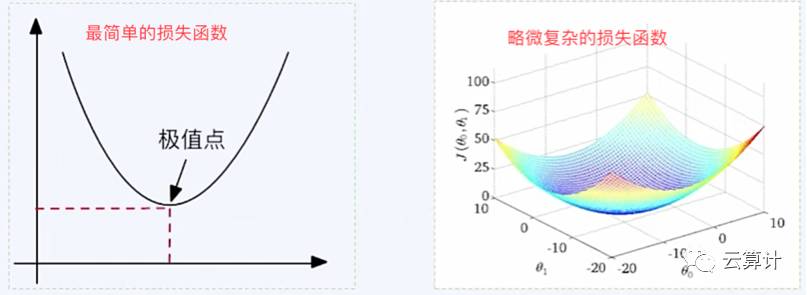
损失函数是用来描述使用这个假设函数的预测结果和真实数据之间的误差,用误差的均方差做数值描述。当误差均方差最小的时候即为极值点,即假设函数质量最优。
比如说我们在上图中总结出的规律是“A城市有十万人,房价为8万;B城市有20万人房价为16万,即y=θx中,房价y=0.8*人数x,模型参数θ=0.8。”这个模型过于简化生硬,因为C城市有15万人,但房价是10万,D城市有25万人,但房价为25万,则该模型均方差约为5.4。我们需要找到有没有更贴合实际房价的函数,让损失函数进一步减小,即无限贴近极值点,但几乎不可能直接达到极值点。
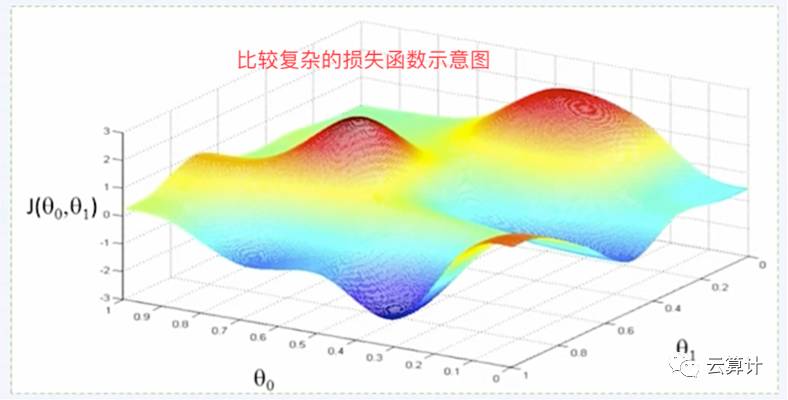
上图中是极简化抽象的损失函数的例子,但实际上可能非常复杂,因为要涉及的Feature特征会非常多,特征的规律也未必是简单的一次函数。下文三个图是Feature特征逐步复杂导致损失函数逐渐复杂的示意图。
5. 模型训练的概念
通过寻找合适的假设函数,不断的降低损失函数的均方差,让损失函数逐渐靠近极值的过程就是模型训练的过程。训练过程中有多种可选的优化方法,本次课程讲的是最通用的梯度下降算法。梯度下降是为了找到损失函数的极值点,然后通过一步步迭代尝试的方式无限接近极值点。
首先我们看为什么是无限迭代?人脑看到样本A中x=10,y=8,样本B中x=20,y=16,则稍微有数学基础的人都能看到y=0.8*x,但计算机不是人脑,这么简单的函数也要通过猜测重试的方法去测可能的θ。计算机很笨但速度很快,而且永不疲倦,人类很聪明但速度慢且有生理上限;自然人去写简单规律的程序的效率比AI高的多,因为自然人一眼就能看到最优雅的θ值,但复杂到上万个参数的数学规律能让数学家打字打到手抽筋,只能由AI来做。
具体梯度下降的过程是如下图的一步步重试,如果顺着正确的方向去测试则损失函数越来越接近极值点,但如果测试的方向错了则离极值点会越来越远,即无法完成收敛。详细梯度下降过程可以看视频内容,但看不太懂也可以继续。
梯度下降过程中需要人类指定一个叫学习率的参数,学习率太小了则是自我束缚,小碎步跑到极值点附近的时间可能是几天甚至几年;学习率太大了函数可能越来越发散,最终无法收敛。我们人类可以看到这些简单函数里计算机在乱撞,但计算机自己看不到,我们也看不清楚复杂函数(如上文的多个波峰波谷的三维函数)到底是接近极值点还是远离极值点了。
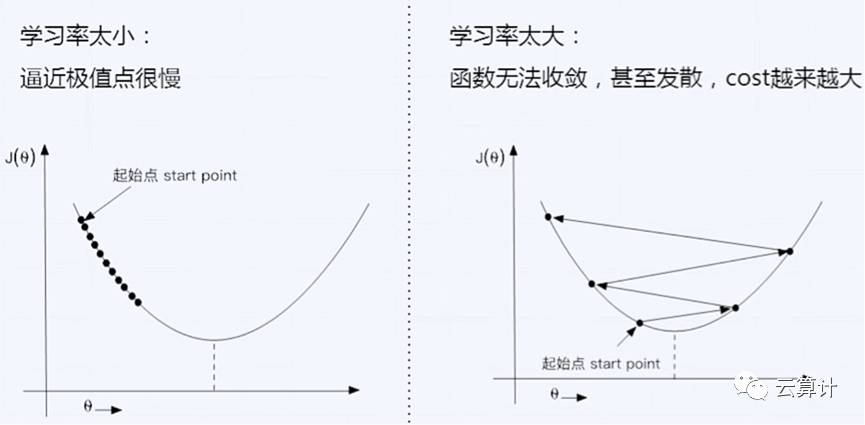
(如果这里能换个稍微复杂点有多个局部极值点的图,即函数从U形变成了W或则WvV型,模型训练的过程会更直观的展示出来。)。
因为计算机比较笨,人类又受到生理条件的限制,所以梯度下降的过程有一定的运气成分。模型训练有大致的规律趋势,也能逼近极值点,但没有教科书式的普遍性规律,而且也很难从逼近变为到达极值点。
常见的三种梯度下降优化框架中,最推荐小批量梯度下降,因为另外两种方式或者太笨重或者太随机。但选择小批量样本要兼备脑子和运气,样本选择要足以表述全局数据集的特征,且数据要和算法、硬件有向量化匹配才能快速运算。
6. 课间休息
我们看一下前文知识点的总结,对没数学基础的同学们,看懂前面25分钟的内容是很吃力的,但打好基础就能轻松上阵做下一步工作了。
我们要知道什么是假设函数和损失函数,更要深度理解梯度下降算法,相关的知识点都在下图中有标明:
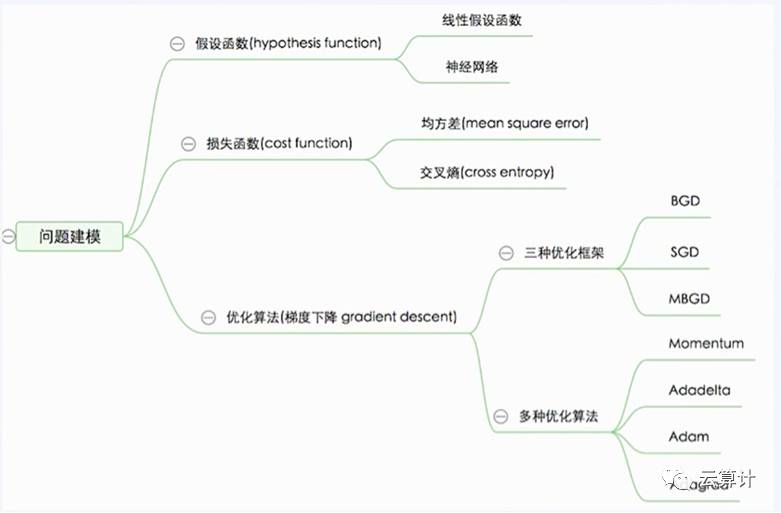
再接下来的实验中,我们拿一份房价的数据集,首先要观察和预处理这些房价相关数据,然后设计假设函数和损失函数,最终训练和观测结果,完成一个数据训练从思考分析到技术实现的全过程。这一部分最难也最重要的数据预处理。
7. 数据预处理
数据预处理是数据方(甲方)能做的最重要的工作,模型训练的过程太难且有随机性,数据方完全可以将训练的工作外抛给专业团队或者外部厂商去做模型训练,甚至挂到众包市场上让乙方自由竞争。
如下图是我们手头这份数据,按照前文学习的内容,我们应该将下图表述为,这个数据集有506个样本,每个样本有13个Feature,具体的房价数字就是Label。
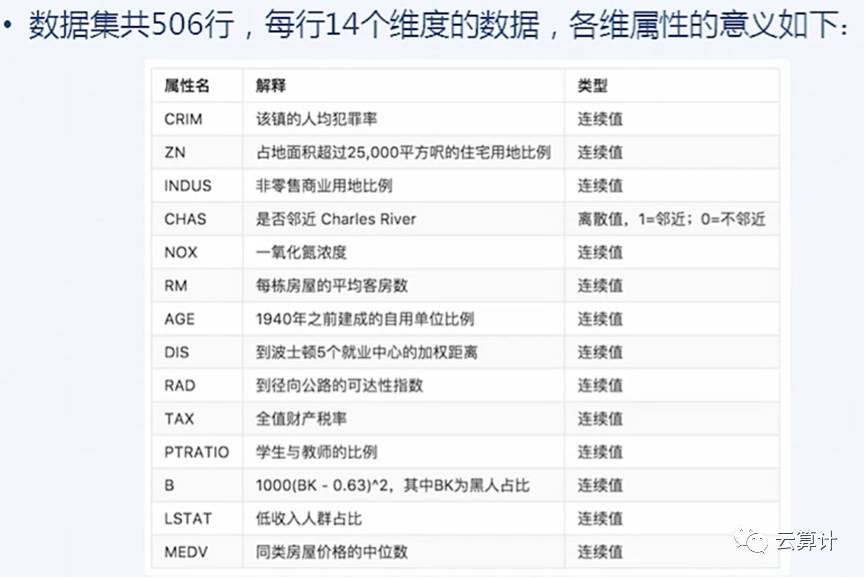
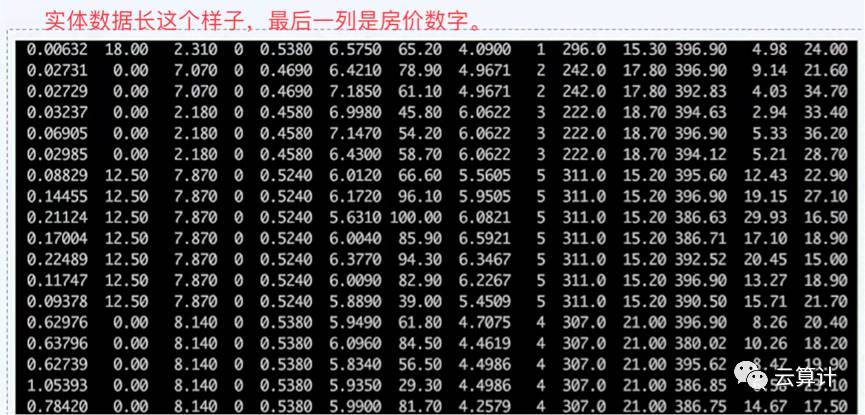
在这个时候我们就可以看到一个很有意思的特性,如果没有前一个图中对数据的标识,模型训练者只拿着数据集可以训练模型,但很难理解和解释这个模型中每个Feature是什么意思,也不知道最后的Label就是房价。对于数据拥有方来说,并不太担心模型训练方会泄密这份数据集,或者将训练好的模型同时卖给几个友商。
即使模型训练方能从原始样本中猜出来这是什么信息,数据集预处理过后就更不用担心泄密问题了,甚至银行的交易数据都可以脱敏导出来。
数据预处理主要不是为了保密脱敏,而是因为Feature的数值提供的是“趋势”和“相关性”参考,而非绝对值参考,用绝对数值无法描述Feature和Label的相关性。首先数值范围太大可能造成浮点溢出,比如到说房价信息用美分甚至津巴布韦币来表示,很快就会超出计算机可处理的数值范围。这些数值只能用于在样本之间同Feature进行对比的,样本内不同Feature之间没有可比性;比如说房价信息跟距离河流是1500米还是1800米有关系,也跟该社区的犯罪率是0.01%还是1%有关系;但如果不做数据预处理就直接做运算,距离米数的1500肯定会将犯罪率的0.01压缩到忽略不计的地步。此外还有属性用0或1表示“Ture”和“False”的离散值,并没有谁大谁小的关系。
基于上述原因,我们需要将原始样本数做“归一化”处理,即将大部分数据处理成“-1到0到+1”的趋势指向数据,很多机器学习的框架和技巧对归一化数据都有很好的优化。
归一化处理过的数据会变成这个样子,可想而知这类数据并不怕泄密。
上述工作描述起来复杂但执行很简单,使用PaddlePaddle的处理框架,一行代码即可完成读取数据集、数据归一化、生成小批量样本三个工作。
8. 房价预测实验
接下来我们要进行一个房价预测实验,培训视频详解了做每一步实验的目的,但信息量太大新名词太多,我还是从实验本身来看这个房价预测实验。
首先需要搭建Docker环境,在已经安装了docker的主机上运行下列命令即可安装和运行PaddlePaddle的docker镜像。
docker run -d -p 8888:8888 paddlepaddle/book
然后我们打开这个网页即可进行本节课所涉及的波士顿房价数据进行训练。
http://localhost:8888/notebooks/01.fit_a_line/README.cn.ipynb
从这个网页搭建完成开始,我们就可以跟着PaddlePaddle的官方Jupyter电子书进行8个经典实验了,有基础的Python能力的人都能读懂这些代码。
在设计设计假设函数和损失函数阶段,视频比文档更详细说明了模型配置中“输入数据x”、“模型输出y_predict”、“标注数据y_label”和“损失函数cost”的样例代码和各自真实含义,这是一个模型的骨架定义。
在模型训练阶段,视频里建议调优optimizer,加上“learning_rate”参数,通过不同的学习率观测不同的训练结果,而Jupyter电子书里将读取和打印训练的中间信息的过程一并show出来了。在这个实验中,我们最重要的工作是通过微调学习率和训练次数来观察不同的模型收敛速度,看如何配置cost损失函数能接近极值,或者因为学习率过大而始终无法收敛。后续我们拿着别人训练好的现成模型,根据训练cost函数变化,也有评估模型好坏的基本能力。
然后我们拿着新的测试数据进行一次模型推演,简单来说推演结果越接近真实值,这个模型在这一批测试数据的效果越好。(另换一批测试数据怎么样,咳咳……)
9. 后记
PaddlePaddle是百度开源的项目,所以实验材料有完善的中文文档,社区也有很好的中文支持;其诞生之初就是兼顾了技术情怀和工程效率,即有完善的顶层设计,又考虑到了一线用户的执行力度,是一个优秀的深度学习开发框架。PaddlePaddle的官方电子书教程默认有8个经典实验,同时提供了完善的文档说明,希望大家多多尝试在PaddlePaddle上进行深度学习开发工作。
本实验用的是线性回归模型而非神经网络,是因为对初学者而言,线性回归的形式简单易于建模,麻雀虽小五脏俱全,机器学习中的主要基本概念都有出现;线性回归模型可解释性很好,人类可见可理解的表达个属性在预测中的权重,比如说我们很容易认可犯罪率对房价会产生重要影响;而且我们可以将多个线性回归组合成一个功能强大的非线性模型,简单的零部件可以组合出强大的工具链。
以上是关于不懂高数也能入门深度学习--PaddlePaddle入门和实战的主要内容,如果未能解决你的问题,请参考以下文章
看完这篇还不懂高并发中的线程与线程池你来打我(内含20张图)
对比学习资料《深度学习入门:基于Python的理论与实现》+《深度学习原理与实践》+《深度学习理论与实战基础篇》电子资料