本科生学深度学习-大白话说清楚CNN,没有公式
Posted 香菜聊游戏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了本科生学深度学习-大白话说清楚CNN,没有公式相关的知识,希望对你有一定的参考价值。
推荐阅读
1、再不入坑就晚了,深度神经网络概念大整理,最简单的神经网络是什么样子
3、深度学习基础之numpy,轻松入门numpy4、深度学习基础之三分钟轻松搞明白tensor到底是个啥!看不懂的话我倒立洗头~~
5、本科生学深度学习-史上最容易懂的RNN文章,小白也能看得懂
6、本科生学深度学习一最简单的LSTM讲解,多图展示,源码实践,建议收藏
7、本科生学深度学习-GRU最简单的讲解,伪代码阐述逻辑,实例展示效果
上一篇文章好久了,马上过年了,有点懒,今天这篇文章也是墨迹了好久才写,坚持。
cnn 是图片识别的基础模型,也是最出名的,是相对简单有效的模型,所以需要学会,对于以后进入强化学习,和强化学习相结合很有帮助,今天希望能用最简单的,最通俗易懂的话说明白这个cnn,并且搞个例子,简单试试CNN,也算是入门卷积神经网络了。
1、cnn预览

1.1 通俗的解释下CNN
CNN 卷积神经网络所做的事情就是对图片的识别,机器是没有眼睛的,他不能记住图形是什么样子。这就像盲人摸象一样。
假如有100个盲人想知道大象是什么样子的,大家看不见怎么办?那就每个盲人摸一遍大象,然后各自记下自己摸到的特征,有一个盲人总结大家记住的明显特征。所有人都确认了长鼻子,大粗腿,长尾巴,大象牙,设置皮肤的纹理等等特征,下次再遇到大象的时候大家比对特征也有极大的概率认出来是大象的。这就是卷积神经网络的基本原理
1.2 概念理解
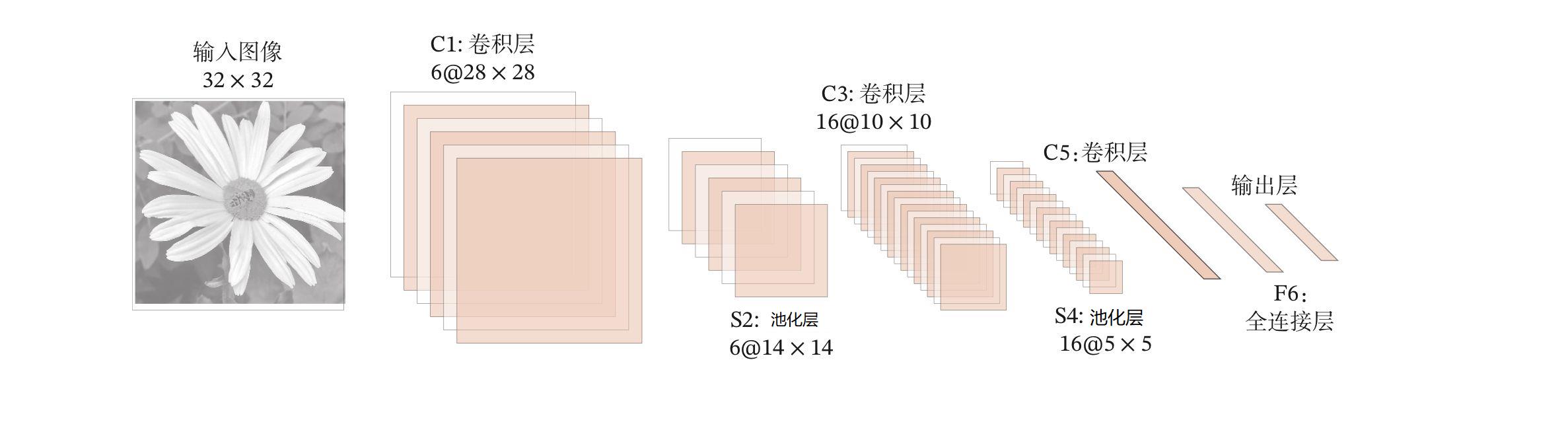
上面这张图就是卷积神经网络的模型了,可以看到卷积神经网络的所有核心层。
卷积层 可以类比为 盲人摸象这一行为,每个盲人就是一个卷积核,也就是盲人的认知,盲人认识到的数据就是对图片的扫描。
池化层 可以类比为 对所有盲人摸象数据的一个总结,将突出特征进行总结数据,压缩数据,要不然盲人记住那么多人的描述数据也太难了
全连接层 可以类比为对大象特征的区分对比,如果满足多少大象特征就可以认为这是一只大象了。
通过以上这些步骤,下次再遇到大象的时候就可以识别出来了,这就是学习的过程。
2、cnn基础模块
上面的都是通俗的理解,希望能get到核心点。下面进入稍微正式点的介绍,不过也不用担心,不会有数学公式,最多只有几行伪代码。
2.1数据输入层

输入层的动作主要是对图片进行预处理。
原因如下:
-
对图片进行大小对齐,要不然在下面卷积的时候会造成数据不一致
-
对数据进行标准化,防止数据区间过大,导致训练收敛慢
-
对数据增强,比如对图片进行翻转,平移等等手段增加数据的多样性
2.2卷积计算层
这一层就是卷积神经网络最重要的一个层次,也是“卷积神经网络”的名字来源。
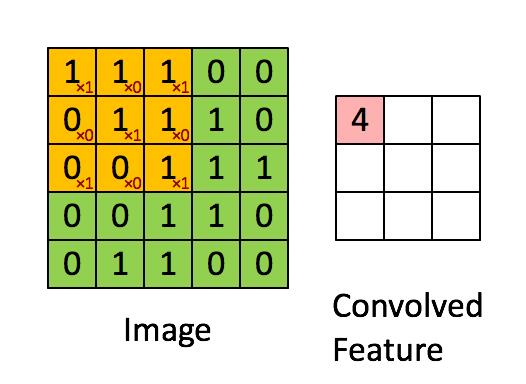
先介绍卷积层遇到的几个名词:
-
深度/depth
深度对应的是卷积操作所需的卷积核个数。如果我们使用三个不同的卷积核对原始图像进行卷积操作,这样就可以生成三个不同的特征图。你可以把这三个特征图看作是堆叠的 矩阵,那么,特征图的“深度”就是三。
-
步长/stride (窗口一次滑动的长度)
步长是我们在输入矩阵上滑动滤波矩阵的像素数。比如上图当步长为 1 时,我们每次移动卷积核一个像素的位置。当步长为 2 时,我们每次移动卷积核会跳过 2 个像素。步长越大,将会得到更小的特征图。
-
零填充
有时在输入矩阵的边缘使用零值进行填充,这样我们就可以对输入图像矩阵的边缘进行滤波。零填充的一大好处是可以让我们控制特征图的大小。主要是为了提取边缘体征。
2.3 池化层 / Pooling layer
2.3.1 池化的两个手段
所谓的池化,就是对特征图片进行压缩,常用的两个手段就是最大值下采样(Max-Pooling)与平均值下采样(Mean-Pooling)
最大池化就是在图片中用每个区域的最大值代表这个区域,
平均池化就是用每个区域平均值代表这个区域。
2.3.2 池化的意义
池化层夹在连续的卷积层中间, 用于压缩数据和参数的量,减小过拟合。
简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。
池化这个词听着很玄乎,引入它的目的就是为了简化卷积层的输出。
通俗地理解,池化层也在卷积层上架了一个窗口,但这个窗口比卷积层的窗口简单许多,不需要参数,它只是对窗口范围内的神经元做简单的操作,如求和,求最大值,把求得的值作为池化层神经元的输入值,
如下图,这是一个2*2的窗口,池化的过程如下图所示:
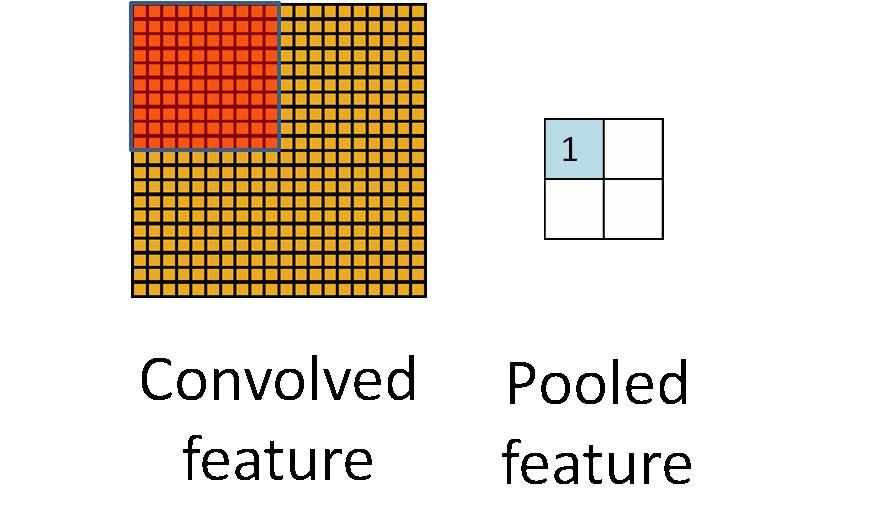
上图中,我们可以看到,原始图片是20x20的,我们对其进行下采样,采样窗口为10x10,最终将其下采样成为一个2x2大小的特征图。
之所以这么做的原因,是因为即使做完了卷积,图像仍然很大(因为卷积核比较小),所以为了降低数据维度,就进行下采样。
之所以能这么做,是因为即使减少了许多数据,特征的统计属性仍能够描述图像,而且由于降低了数据维度,有效地避免了过拟合。
最大池化(max-pooling)保留了每一小块内的最大值,也就是相当于保留了这一块最佳的匹配结果(因为值越接近1表示匹配越好)。也就是说,它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了
2.4 全连接层 / FC layer
全连接层的意义就是对所有的特征进行分类,只不过网络的模型是最简单的全连接,并没有什么特殊,这里直接带过了。
3、cnn特点:权值共享
所谓的权值共享就是一个盲人去摸象的时候,只能他自己看,别人不能提示。
在模型中就是说,给一张输入图片,用一个卷积核去扫这张图,卷积核里面的数就叫权重,这张图每个位置是被卷积核扫描,也就是一个卷积核看到的只是图片的一个侧面。
这也就是为什么卷积层往往会有多个卷积核(甚至几十个,上百个),为了能让CNN看到更多的特征,当然需要多个卷积核(越多盲人看到的侧写阅读),不幸的是
4、cnn架构
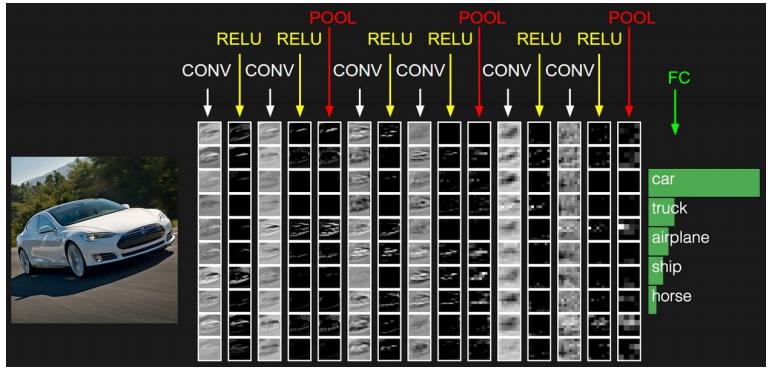
卷积神经网络之典型CNN
•LeNet,这是最早用于数字识别的CNN
•AlexNet, 2012 ILSVRC比赛远超第2名的CNN,比
•LeNet更深,用多层小卷积层叠加替换单大卷积层。
•ZF Net, 2013 ILSVRC比赛冠军
•GoogLeNet, 2014 ILSVRC比赛冠军
•VGGNet, 2014 ILSVRC比赛中的模型,图像识别略差于GoogLeNet,但是在很多图像转化学习问题(比如object detection)上效果奇好
5、搞个例子
因为一直用pytorch 所以这里还是用pytorch 来做,具体的环境安装可以参照之前的文章:
今天还是最经典的数字识别,因为数据集比较好找,也能很好的体现CNN模型的细节。
MNIST 数据集是用作手写体识别的数据集。MNIST 数据集包含 60000 张训练图片,10000 张测试图片。其中每一张图片都是 0~9 中的一个数字。图片尺寸为 28×28。由于数据集中数据相对比较简单,人工标注错误率仅为 0.2%。
我们训练这个网络必须经过4步:
第一步:将输入input向前传播,进行运算后得到输出output
第二步:将output再输入loss函数,计算loss值(是个标量)
第三步:将梯度反向传播到每个参数
第四步:利用下面公式进行权重更新
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=1,
out_channels=16,
kernel_size=3,
stride=1,
padding=1
), #维度变换(1,28,28) --> (16,28,28) 因为有16个卷积核
nn.ReLU(),
nn.MaxPool2d(kernel_size=2) #维度变换(16,28,28) --> (16,14,14) 最大值池化,窗口是2 ,也就是缩小了一倍
)
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=16,
out_channels=32,
kernel_size=3,
stride=1,
padding=1
), #维度变换(16,14,14) --> (32,14,14)
nn.ReLU(),
nn.MaxPool2d(kernel_size=2) #维度变换(32,14,14) --> (32,7,7)
)
self.output = nn.Linear(32*7*7,10)
def forward(self, x):
out = self.conv1(x) #维度变换(Batch,1,28,28) --> (Batch,16,14,14)
out = self.conv2(out) #维度变换(Batch,16,14,14) --> (Batch,32,7,7)
out = out.view(out.size(0),-1) #维度变换(Batch,32,14,14) --> (Batch,32*14*14)||将其展平
out = self.output(out)
return out
cnn = CNN()
print(cnn)模型定义好了,下面开始训练和测试吧,常规操作,没有太多说的,直接看代码。
# 引入库
import torch
from torch import nn, optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 超参数
from src.CNN import CNN
batch_size = 64
learning_rate = 0.02
num_eporches = 20
# 数据准备
data_ft = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.5], [0.5])])
train_dataset = datasets.MNIST("./data", train=True, transform=data_ft, download=True)
test_dataset = datasets.MNIST("./data", train=False, transform=data_ft)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
model = CNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
# 训练模型
epoch = 0
for data in train_loader:
img, label = data
# 与全连接网络不同,卷积网络不需要将所像素矩阵转换成一维矩阵
# img = img.view(img.size(0), -1)
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
else:
img = Variable(img)
label = Variable(label)
out = model(img)
loss = criterion(out, label)
print_loss = loss.data.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch += 1
if epoch % 50 == 0:
print('epoch: , loss: :.4'.format(epoch, loss.data.item()))
# 模型评估
model.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:
img, label = data
# 与全连接网络不同,卷积网络不需要将所像素矩阵转换成一维矩阵
# img = img.view(img.size(0), -1)
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
out = model(img)
loss = criterion(out, label)
eval_loss += loss.data.item() * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print('Test Loss: :.6f, Acc: :.6f'.format(
eval_loss / (len(test_dataset)),
eval_acc / (len(test_dataset))))

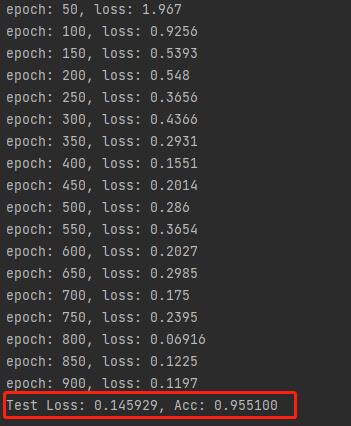
看下训练下效果的记录,可以看到随着训练次数的提升,loss值在一点点的提升。
最终的测试精度达到了95% ,这样的精度已经达到了商用的精度。
总结
卷积神经网络是经典的图形识别模型,基本的概念虽然有点玄乎,但是类比生活中的实例还是很好理解的,先从整体上理解,然后再对其中的细节进行摸索,一步一步的进行分析,希望你能明白。
我们只是站在前人的肩膀上,使用了既成的知识成果,我们不是创造者没有忍受黑暗,我们是使用者,能将知识传播是对创造者最大的尊重。
点赞关注
以上是关于本科生学深度学习-大白话说清楚CNN,没有公式的主要内容,如果未能解决你的问题,请参考以下文章