MySQL系列字符串类型
Posted 猿猿HHH
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL系列字符串类型相关的知识,希望对你有一定的参考价值。
CHAR 和 VARCHAR 的定义
CHAR(N) 用来保存固定长度的字符,N 的范围是 0 ~ 255,请牢记,N 表示的是字符,而不是字节。VARCHAR(N) 用来保存变长字符,N 的范围为 0 ~ 65536, N 表示字符。
在超出 65536 个字符的情况下,可以考虑使用更大的字符类型 TEXT 或 BLOB,两者最大存储长度为 4G,其区别是 BLOB 没有字符集属性,纯属二进制存储。
和 Oracle、Microsoft SQL Server 等传统关系型数据库不同的是,mysql 数据库的 VARCHAR 字符类型,最大能够存储 65536 个字符,所以在 MySQL 数据库下,绝大部分场景使用类型 VARCHAR 就足够了。
字符集
在表结构设计中,除了将列定义为 CHAR 和 VARCHAR 用以存储字符以外,还需要额外定义字符对应的字符集,因为每种字符在不同字符集编码下,对应着不同的二进制值。常见的字符集有 GBK、UTF8,通常推荐把默认字符集设置为 UTF8。
而且随着移动互联网的飞速发展,推荐把 MySQL 的默认字符集设置为 UTF8MB4,否则,某些 emoji 表情字符无法在 UTF8 字符集下存储,比如 emoji 笑脸表情,对应的字符编码为 0xF09F988E:
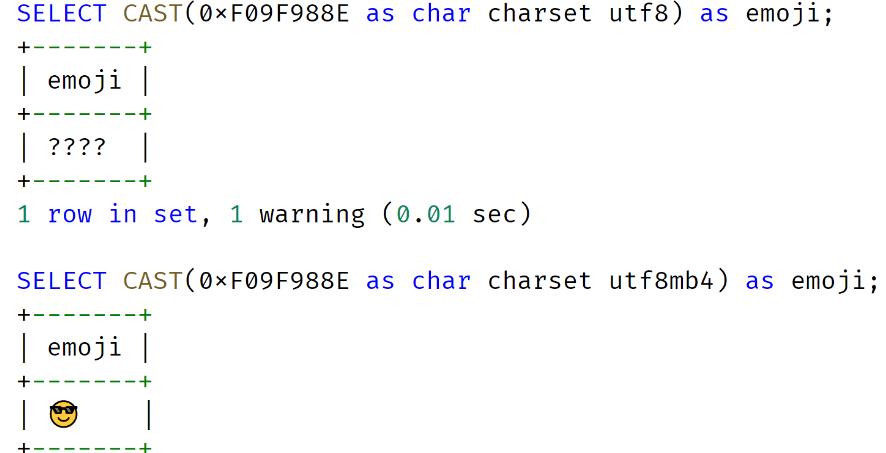

若强行在字符集为 UTF8 的列上插入 emoji 表情字符, MySQL 会抛出如下错误信息:
mysql> SHOW CREATE TABLE emoji_test\\G
*************************** 1. row ***************************
Table: emoji_test
Create Table: CREATE TABLE `emoji_test` (
`a` varchar(100) CHARACTER SET utf8,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.01 sec)
mysql> INSERT INTO emoji_test VALUES (0xF09F988E);
ERROR 1366 (HY000): Incorrect string value: '\\xF0\\x9F\\x98\\x8E' for column 'a' at row 1
包括 MySQL 8.0 版本在内,字符集默认设置成 UTF8MB4,8.0 版本之前默认的字符集为 Latin1。因为不同版本默认字符集的不同,你要显式地在配置文件中进行相关参数的配置:
[mysqld]
character-set-server = utf8mb4
...
另外,不同的字符集,CHAR(N)、VARCHAR(N) 对应最长的字节也不相同。比如 GBK 字符集,1 个字符最大存储 2 个字节,UTF8MB4 字符集 1 个字符最大存储 4 个字节。所以从底层存储内核看,在多字节字符集下,CHAR 和 VARCHAR 底层的实现完全相同,都是变长存储!


从上面的例子可以看到,CHAR(1) 既可以存储 1 个 ‘a’ 字节,也可以存储 4 个字节的 emoji 笑脸表情,因此 CHAR 本质也是变长的。
鉴于目前默认字符集推荐设置为 UTF8MB4,所以在表结构设计时,可以把 CHAR 全部用 VARCHAR 替换,底层存储的本质实现一模一样。
排序规则
排序规则(Collation)是比较和排序字符串的一种规则,每个字符集都会有默认的排序规则,你可以用命令 SHOW CHARSET 来查看:
mysql> SHOW CHARSET LIKE 'utf8%';
+---------+---------------+--------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+---------------+--------------------+--------+
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_0900_ai_ci | 4 |
+---------+---------------+--------------------+--------+
2 rows in set (0.01 sec)
mysql> SHOW COLLATION LIKE 'utf8mb4%';
+----------------------------+---------+-----+---------+----------+---------+---------------+
| Collation | Charset | Id | Default | Compiled | Sortlen | Pad_attribute |
+----------------------------+---------+-----+---------+----------+---------+---------------+
| utf8mb4_0900_ai_ci | utf8mb4 | 255 | Yes | Yes | 0 | NO PAD |
| utf8mb4_0900_as_ci | utf8mb4 | 305 | | Yes | 0 | NO PAD |
| utf8mb4_0900_as_cs | utf8mb4 | 278 | | Yes | 0 | NO PAD |
| utf8mb4_0900_bin | utf8mb4 | 309 | | Yes | 1 | NO PAD |
| utf8mb4_bin | utf8mb4 | 46 | | Yes | 1 | PAD SPACE |
......
排序规则以 _ci 结尾,表示不区分大小写(Case Insentive),_cs 表示大小写敏感,_bin 表示通过存储字符的二进制进行比较。需要注意的是,比较 MySQL 字符串,默认采用不区分大小的排序规则:
mysql> SELECT 'a' = 'A';
+-----------+
| 'a' = 'A' |
+-----------+
| 1 |
+-----------+
1 row in set (0.00 sec)
mysql> SELECT CAST('a' as char) COLLATE utf8mb4_0900_as_cs = CAST('A' as CHAR) COLLATE utf8mb4_0900_as_cs as result;
+--------+
| result |
+--------+
| 0 |
+--------+
1 row in set (0.00 sec)
牢记,绝大部分业务的表结构设计无须设置排序规则为大小写敏感!除非你能明白你的业务真正需要。
正确修改字符集
当然,相信不少业务在设计时没有考虑到字符集对于业务数据存储的影响,所以后期需要进行字符集转换,但很多同学会发现执行如下操作后,依然无法插入 emoji 这类 UTF8MB4 字符:
ALTER TABLE emoji_test CHARSET utf8mb4;
其实,上述修改只是将表的字符集修改为 UTF8MB4,下次新增列时,若不显式地指定字符集,新列的字符集会变更为 UTF8MB4,但对于已经存在的列,其默认字符集并不做修改,你可以通过命令 SHOW CREATE TABLE 确认:
mysql> SHOW CREATE TABLE emoji_test\\G
*************************** 1. row ***************************
Table: emoji_test
Create Table: CREATE TABLE `emoji_test` (
`a` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
可以看到,列 a 的字符集依然是 UTF8,而不是 UTF8MB4。因此,正确修改列字符集的命令应该使用 ALTER TABLE … CONVERT TO…这样才能将之前的列 a 字符集从 UTF8 修改为 UTF8MB4:
mysql> ALTER TABLE emoji_test CONVERT TO CHARSET utf8mb4;
Query OK, 0 rows affected (0.94 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> SHOW CREATE TABLE emoji_test\\G
*************************** 1. row ***************************
Table: emoji_test
Create Table: CREATE TABLE `emoji_test` (
`a` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
总结
字符串是使用最为广泛的数据类型之一,但也是设计最初容易犯错的部分,后期业务跑起来再进行修改,代价将会非常巨大。希望你能反复细读本讲的内容,从而在表结构设计伊始,业务就做好最为充分的准备。
-
CHAR 和 VARCHAR 虽然分别用于存储定长和变长字符,但对于变长字符集(如 GBK、UTF8MB4),其本质是一样的,都是变长,设计时完全可以用 VARCHAR 替代 CHAR;
-
推荐 MySQL 字符集默认设置为 UTF8MB4,可以用于存储 emoji 等扩展字符;
-
排序规则很重要,用于字符的比较和排序,但大部分场景不需要用区分大小写的排序规则;
-
修改表中已有列的字符集,使用命令 ALTER TABLE … CONVERT TO …;
-
用户性别,运行状态等有限值的列,MySQL 8.0.16 版本直接使用 CHECK 约束机制,之前的版本可使用 ENUM 枚举字符串类型,外加 SQL_MODE 的严格模式;
-
业务隐私信息,如密码、手机、信用卡等信息,需要加密。切记简单的MD5算法是可以进行暴力破解,并不安全,推荐使用动态盐+动态加密算法进行隐私数据的存储。
以上是关于MySQL系列字符串类型的主要内容,如果未能解决你的问题,请参考以下文章