基于python实现UI自动化5. selenium实现获取页面元素属性(内容标题URL浏览器名称等)
Posted lht3347
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于python实现UI自动化5. selenium实现获取页面元素属性(内容标题URL浏览器名称等)相关的知识,希望对你有一定的参考价值。
python-UI自动化
1. selenium工具介绍
2. selenium环境搭建
3 Selenium的元素定位
下面来介绍下selenium常见的元素定位,相信通过下面的学习,大家都可以掌握到一定的知识。
3.0 selenium常见8大元素定位
3.0 selenium - webdriver常见8大元素定位
3.1 selenium通过By定位元素
3.2 selenium通过JS定位元素
3.3 JS处理浏览器滚动条
3.4 JS 处理日历控件(删除 readonly 属性)
4. selenium 多表单(iframe/ frame)切换
4 selenium 多表单(iframe/ frame)切换
4.1 例子:以发送163邮箱邮件为例
5. Webdriver实现获取页面元素属性
通过上述的学习,相信大家都对自动化有那么稍微点上手了,但做自动化的时候,用例往往都是需要断言的,断言有些时候需要用到断言浏览器的URL地址、浏览器的标题、文本内容等。
那这些要怎么获取呢?

具体如何获取我们通过下面的案例来学习下吧~~
5.1 获取访问网页的URL地址
相信很多小伙伴都知道URL在哪哈 ^_^
下面通过一个小案例来获取浏览器页面的URL地址。
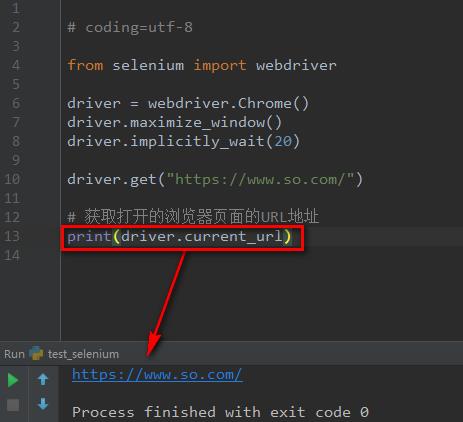
上述代码我们通过driver.current_url函数来获取浏览器当前标签页面打开的URL地址。源代码如下:
# coding=utf-8
from selenium import webdriver
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(20)
driver.get("https://www.so.com/")
# 获取打开的浏览器页面的URL地址,并输出
print(driver.current_url)
5.2 获取网页标题
相信现在的小伙伴们都知道网页的标题在哪里。但不知道的也没关系,下面来看张图就知道了。
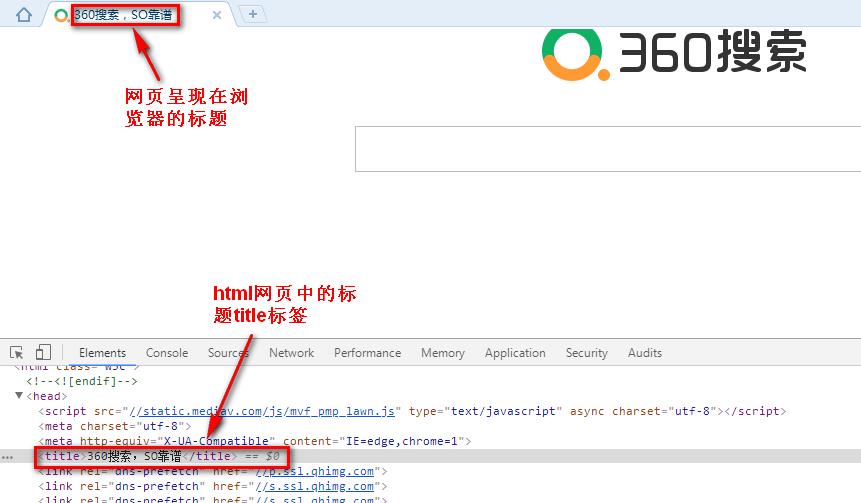
通过上图,我们也可了解到html中设置网页标题的标签是用title来设置。
了解了怎么设置网页标题和网页的标题在哪之后,那我们怎么通过python代码去获取呢?
实际很简单,就直接通过浏览器对象driver.title即可获取到网页打开的标题名称。
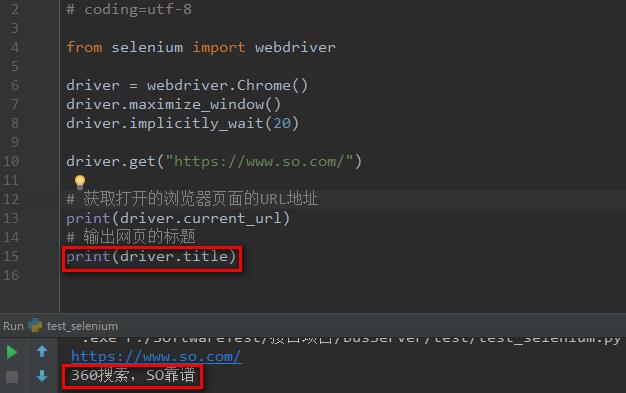
5.3 获取浏览器的名称
一般需要获取浏览器名称是在做浏览器兼容的时获取的。不过获取的方式也很简单,通过driver.name即可获取。
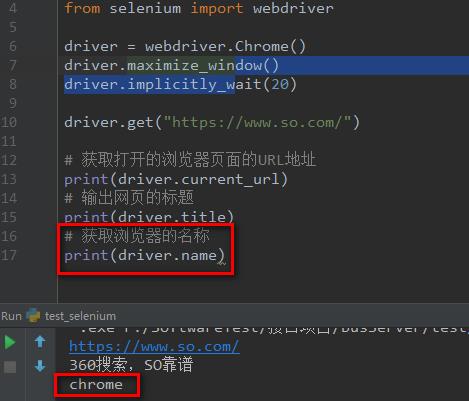
5.4 获取页面元素的文本信息
我们在做自动化的时候,需要通过获取页面元素的某些内容要进行断言,从而来检查自动化用例是否通过。下面这张图可看到页面有好多个文本链接。
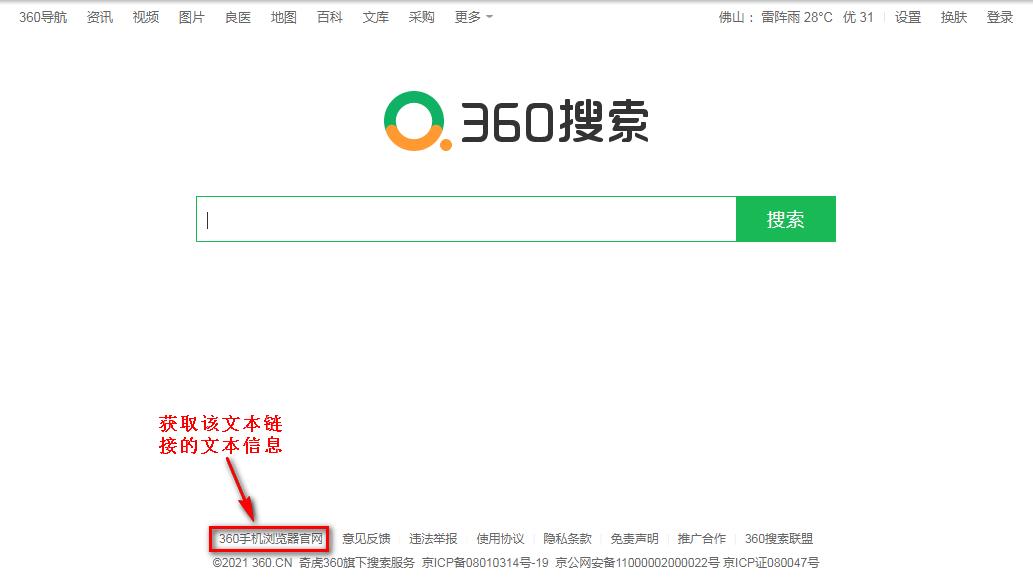
下面通过一个小案例来获取其中一个文本的信息。
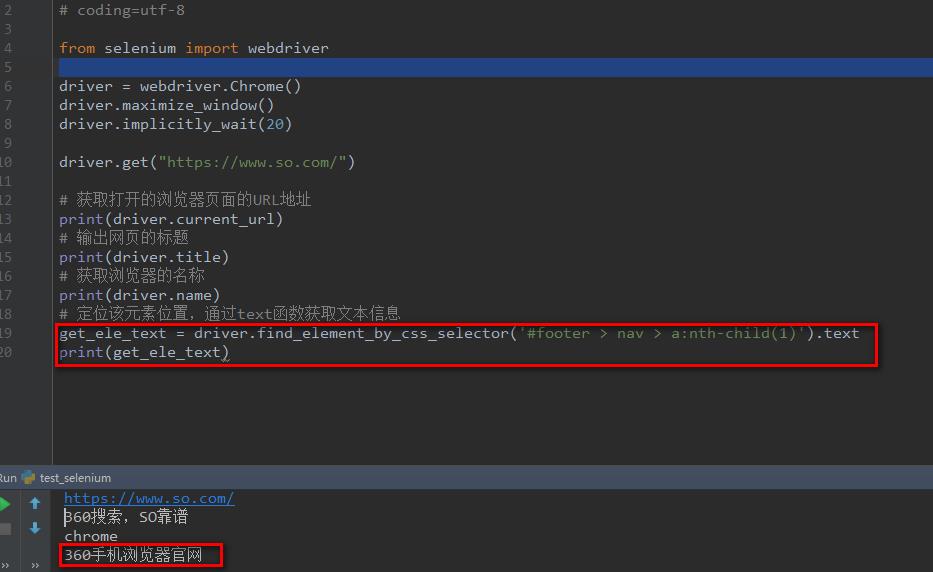
首先:要先通过之前小伙伴们所学到的元素定位去定位该元素的所在位置。
元素定位的这里就不再介绍了,有疑问的同学可以查看我的另一篇文章《3.0 selenium - webdriver常见8大元素定位》
其次:在获取到的元素定位后面,通过text函数获取文本信息。
最后:自己想输出的可以输出,想断言的可以断言。
总而言之,该干嘛就干嘛~
下面附上代码,可自行操作下。
5.5 获取页面元素的标签
上面的例子,我们学会了如何获取页面元素的文本信息,下面的我们来看看该页面元素的文本信息是属于HTML元素标签中的哪一个?
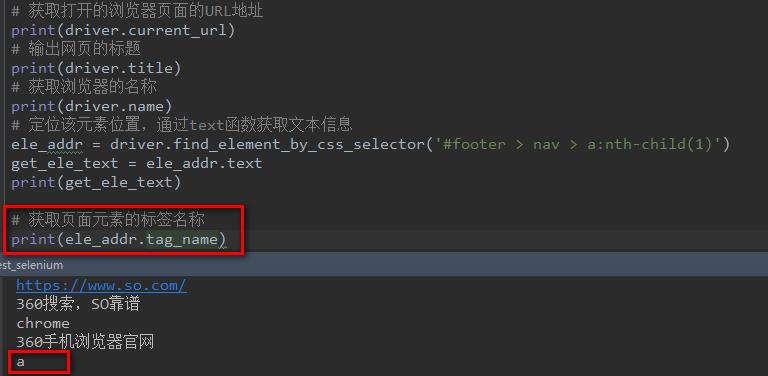
操作的话跟【获取页面元素文本信息】类似,将获取文本信息text函数替换成tag_name函数即可。
5.6 获取元素标签的属性值
学会了以上知识后,难免我们在工作中还会遇到其它获取不到的。
例如:下面的图中显示,页面元素<a>标签里面很多属性,如何获取它的属性值呢?
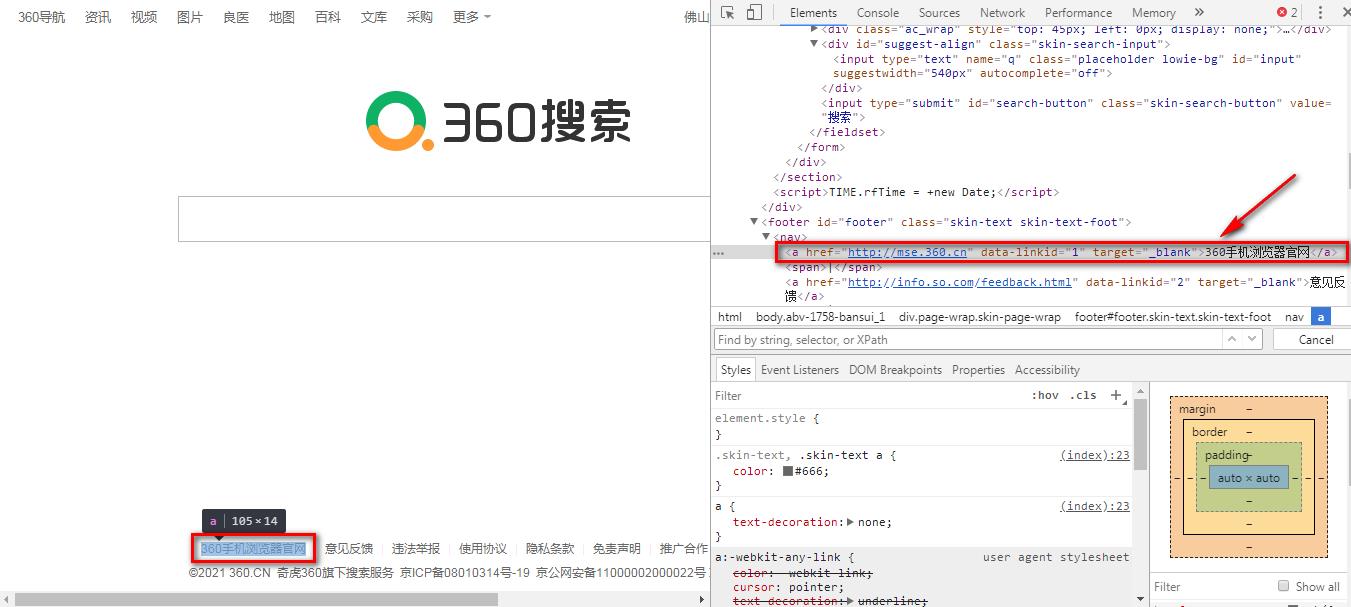
selenium提供了一个get_attribute(属性名称)函数来获取元素标签对应属性的值。
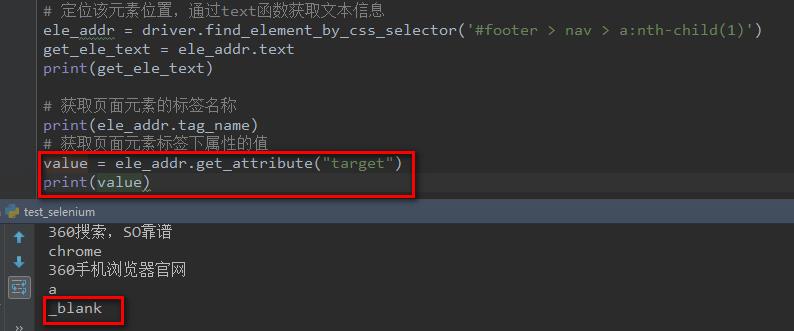
最后,附上本文代码(代码很粗糙,但话糙理不糙),多练习总会进步的。
# coding=utf-8
# 导包
from selenium import webdriver
# 实例化Chrome浏览器对象
driver = webdriver.Chrome()
# 最大化窗口
driver.maximize_window()
# 隐式等待
driver.implicitly_wait(20)
# 加载网址内容
driver.get("https://www.so.com/")
# 获取打开的浏览器页面的URL地址
print(driver.current_url)
# 输出网页的标题
print(driver.title)
# 获取浏览器的名称
print(driver.name)
# 定位该元素位置,通过text函数获取文本信息
ele_addr = driver.find_element_by_css_selector('#footer > nav > a:nth-child(1)')
get_ele_text = ele_addr.text
print(get_ele_text)
# 获取页面元素的标签名称
print(ele_addr.tag_name)
# 获取页面元素标签下属性的值
value = ele_addr.get_attribute("target")
print(value)
结尾
看完之后,觉得文章对你有帮助,请动起你们的小手手点下赞(大拇指)哈(一键三连更好),Thanks♪(・ω・)ノ。

以上是关于基于python实现UI自动化5. selenium实现获取页面元素属性(内容标题URL浏览器名称等)的主要内容,如果未能解决你的问题,请参考以下文章
基于python实现UI自动化5. selenium实现获取页面元素属性(内容标题URL浏览器名称等)
基于python实现UI自动化5. selenium实现获取页面元素属性(内容标题URL浏览器名称等)
基于python实现UI自动化5. selenium实现获取页面元素属性(内容标题URL浏览器名称等)
基于python实现UI自动化2.0 selenium环境搭建