从零开始 MapReduce
Posted javatiange
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零开始 MapReduce相关的知识,希望对你有一定的参考价值。
前言
你将 get 到分布式计算引擎的核心思路,MapReduce 并行度解析
一、MapReduce 的核心思路
1.1 分布式计算引擎
下图描述的是 MapReduce 的几个核心阶段
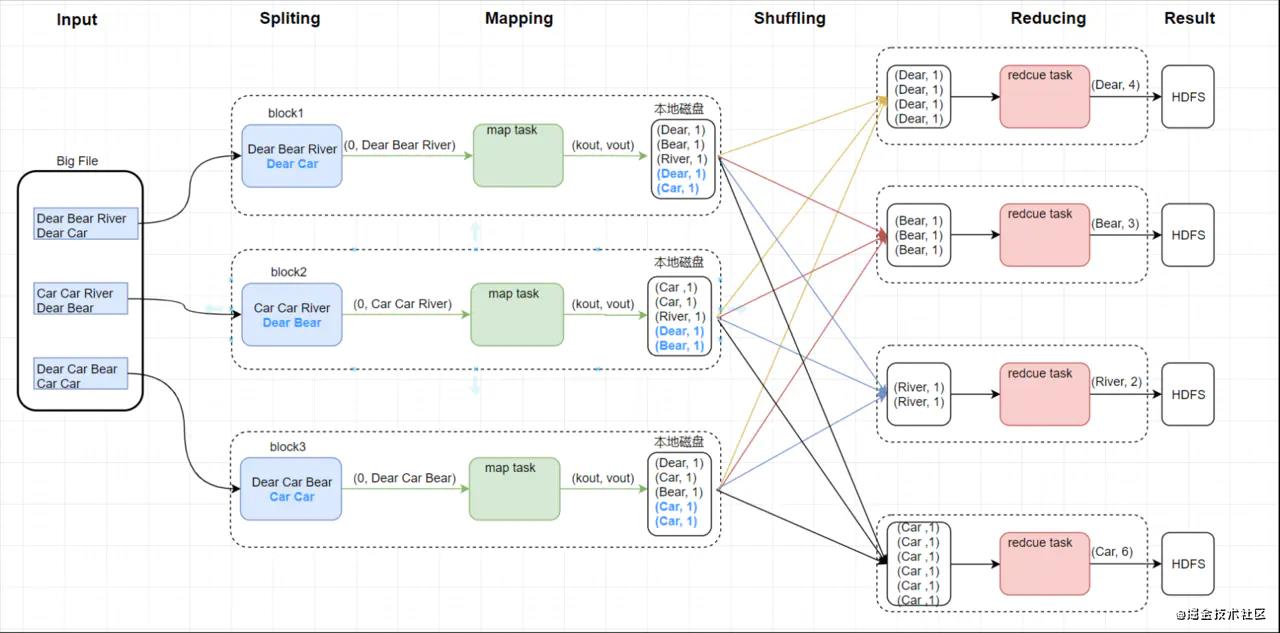
一句话总结分布式处理的核心思路:分而治之 + 并行计算。之后的 Spark 和 Flink 都是基于它的思想所设计的。HDFS也可以一句话总结:分散存储 + 冗余存储。
复杂问题,单台计算搞不定,那么就发挥人多力量的优势:组建一个多服务器组成的集群来搞定分 布式并行计算。核心过程为:
- 第一阶段 Mapper(提取特征的过程):复杂大任务拆分成多个小任务并行执行计算
- 第二阶段 Reducer(执行逻辑的地方):把第一阶段的并行执行的小任务的执行结果进行汇总
但是单机任务转化成分布式计算任务本身就会遇到很多各式各样的问题。
- 数据存储的问题,首先需要搞定海量数据存储的问题。就是我们耳熟能详的 HDFS
- 运算逻辑至少要分为两个阶段,先并发计算(map),然后汇总(reduce)结果
- 这两个阶段的计算如何启动?如何协调?两个阶段必须保证先 map 后 reduce
- 运算程序到底怎么执行?数据找程序还是程序找数据?数据在集群的各个机器里面,但是执行任务的机器上不一定会存在数据,这时候该怎么处理?
- 如何分配两个阶段的多个运算任务?
- 如何管理任务的执行过程中间状态,如何容错?执行完的结果该怎么保存,如果执行任务时机器突然宕机了又怎么办?
- 如何监控和跟踪任务的执行?多个机器会得出计算后的结果,但是我们能不能将先执行完 第一阶段的任务的机器提前拉取到第二阶段?
- 出错如何处理?抛异常?重试?
针对上述问题,MapReduce 都已经帮我们实现好了,除了逻辑功能。
1.2 MapReduce 架构设计
它也是一个大型的责任链模式系统。而且它要保证,不管多复杂的数据种类,不管多复杂的计算类型,不管数据多大,存储在哪里,都应该能使用这个框架执行相关的任务计算。这也是作为框架的通用性!把分布式计算的整个流程都完成,然后制定规范,让用户只需要按照规范去编写对应的业务逻辑。
如果你觉得自己学习效率低,缺乏正确的指导,可以加入资源丰富,学习氛围浓厚的技术圈一起学习交流吧!
[Java架构群]
群内有许多来自一线的技术大牛,也有在小厂或外包公司奋斗的码农,我们致力打造一个平等,高质量的JAVA交流圈子,不一定能短期就让每个人的技术突飞猛进,但从长远来说,眼光,格局,长远发展的方向才是最重要的。
-
首先是数据源的对接问题,MapReduce 的数据读取组件为:
InputFormat + RecordReader -
第一阶段:Mapper,针对原始数据进行改造,提取需要计算的数据(Value),并加上特征(Key)
-
中间阶段:把相同特征的 value 聚合到一起,执行一次第二阶段的逻辑汇总操作
(排序 局部聚合操作 分区操作,还有一个微妙的分组)
-
第二阶段:Reducer
-
数据落地:基本也是从哪来就回到哪,写出组件为:
OutputFormat + RecordWriter
然后所有的组件和流程都是服务于一个叫做 Job 的东西,而且每个组件都是存在默认实现的。比如InputFormat + RecordReader 的默认实现就是 TextInputFormat + LineRecordReader
还有我们提到了排序,聚合,分区,分别对应 Partitioner,Combiner,Sorter
Partitioner:默认组件为 HashPartitioner,当然如果你 reduceTask 只有一个,那它就废了 Sorter:留在 Shuffle 的时候展开 Combiner:局部聚合
1.3 Job 和 Context
我们可以通过 Job 对象来组装好我们的 MapReduce 程序,并提交执行
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setMapperClass(xxx);
job.setReducerClass(xxx);
job.setPartitionerClass(xxxx);
...
job.submit();
在整个 Job 执行的过程中,我们就会生成 MapTask 和 ReduceTask 两种不同的任务,两种任务都会存在一个全局上下文对象 Context
Context 在 MapReduce 里面被称为上下文对象,简单来说,如果你在编写 MapReduce 程序的时候,两个阶段需要读数据,取数据,你就可以使用它完成,下面的那段代码就是经典的使用方式
//判断是否存在下一个对象,是的话就取出来
boolean result = context.nextKeyValue();
inKey = context.getCurrentKey();
inValue = context.getCurrentValue();
(inKey, inValue) ===> (outKey, outValue);
context.write(outKey, outValue);
Context 这个接口存在两个实现类,MapContext 和 ReduceContext
1.4 MapReduce 程序
首先我们现在来说明一下 Job 是怎么被执行的,假设现在任务是由 Yarn 来调度的
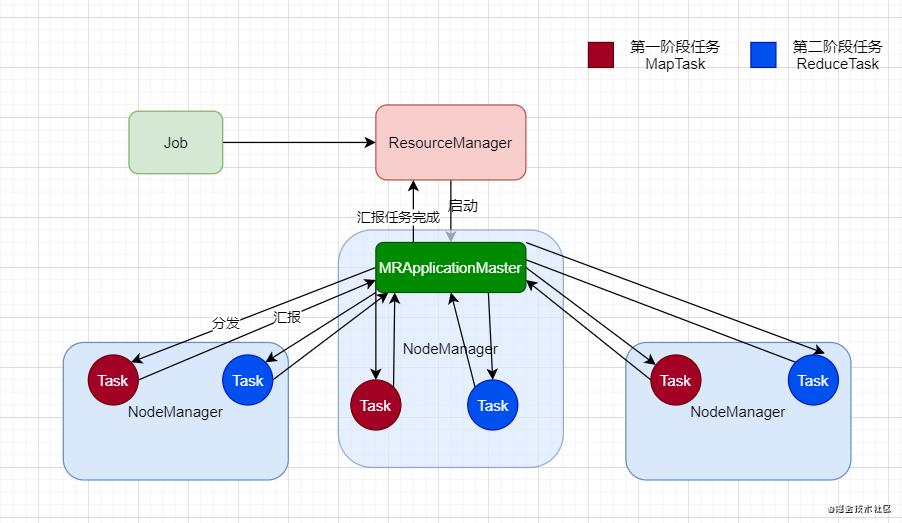
首先这个 Job 提交上来之后,会由 ResourceManager 来判断这个任务是否能够执行,然后如果可以,那 ResourceManager 就会随便找一个比较空闲的节点,先启动一个负责跟踪任务执行,调度,容错的相关处理的组件,我们称呼它为 MRApplicationMaster,它来全权负责两个阶段的任务分发。
此时注意了,MRApplicationMaster 会让3个 NodeManager 分别启动两个Task,MapTask 和 ReduceTask,其实它们是同时启动起来的,MapTask 执行完成后,会向 MRApplicationMaster 汇报,然后 ReduceTask 执行,完成后汇报,整个 Job 执行完成后,ApplicationMaster 会向 RM 汇报,然后任务完成。
当然我们会发现,其实我们可以从客户端那查看 Job 的进度,所以其实 MRApplicationMaster 不仅仅向 RM ,还会向 Client 端汇报进度的。
二、MapReduce 并行度解析
2.1 MapTask 并行度机制
假设现在默认数据块大小为 128M,现在有一个文件 300M,那会启动几个 MapTask,如果是 260M 呢?又会启动几个?
熟悉的小伙伴们可能知道是3,2,感兴趣的可以跳转到源码处查看一下,找到 FileInputFormat 中的 getSplits 方法即可
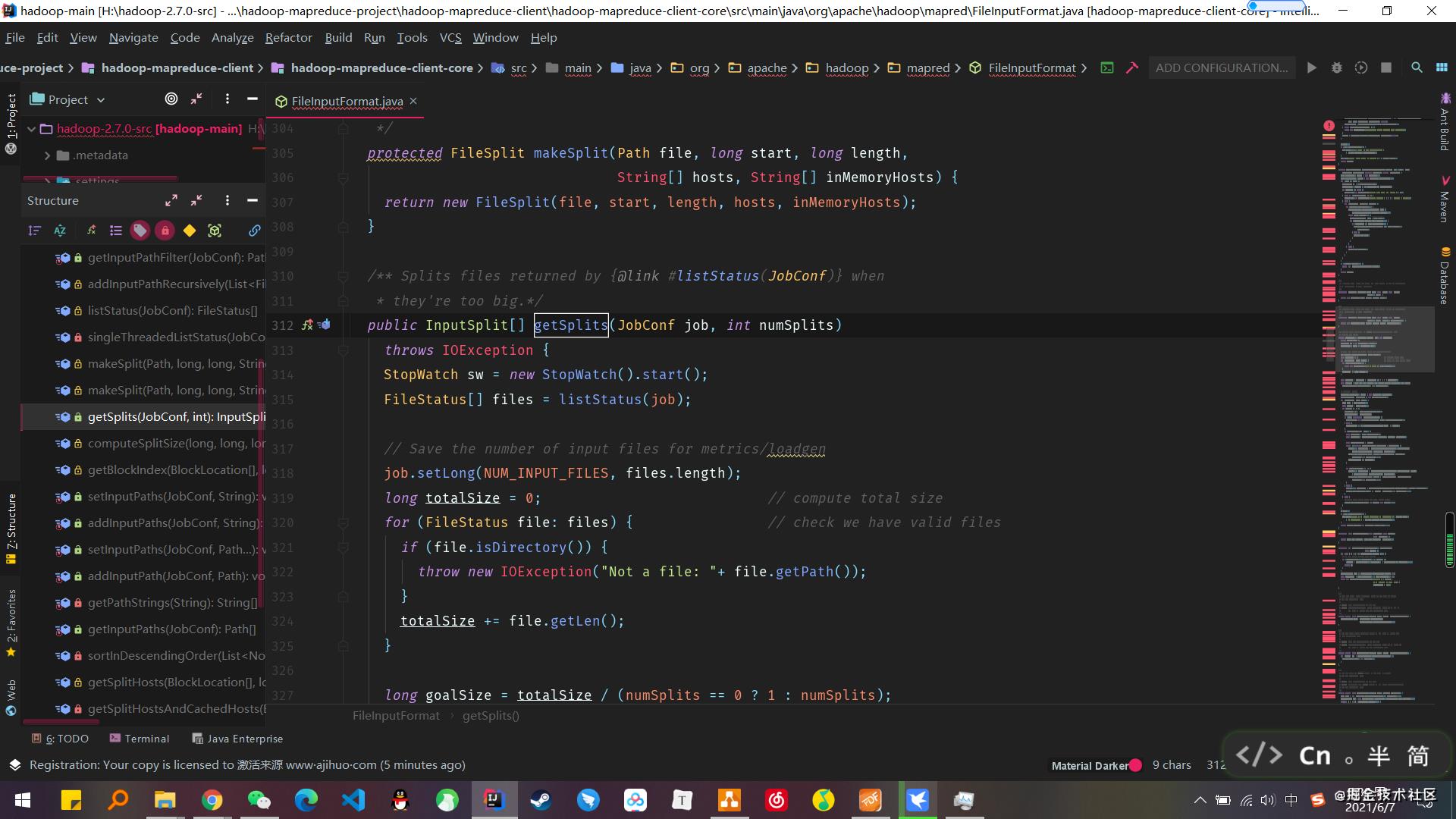
这里我就截取了重点需要看的那部分出来而已,代码不难,简单点说就是 bytesRemaining 这个参数顾名思义就是切分后剩下的大小,这个大小如果除以规定的切块大小,大于1.1,它就会继续帮你进行切分。规定的切块大小由上方的 computeSplitSize 方法决定,其实就是简单地算那3个参数的中位数而已。当然,刚刚提到的操作,都会由 isSplitable 方法进行判断。
所以你就知道了吧,260M = 128M + 128M + 4M,4M 不够 128M 的 0.1,所以它就不会再开启另一个任务了 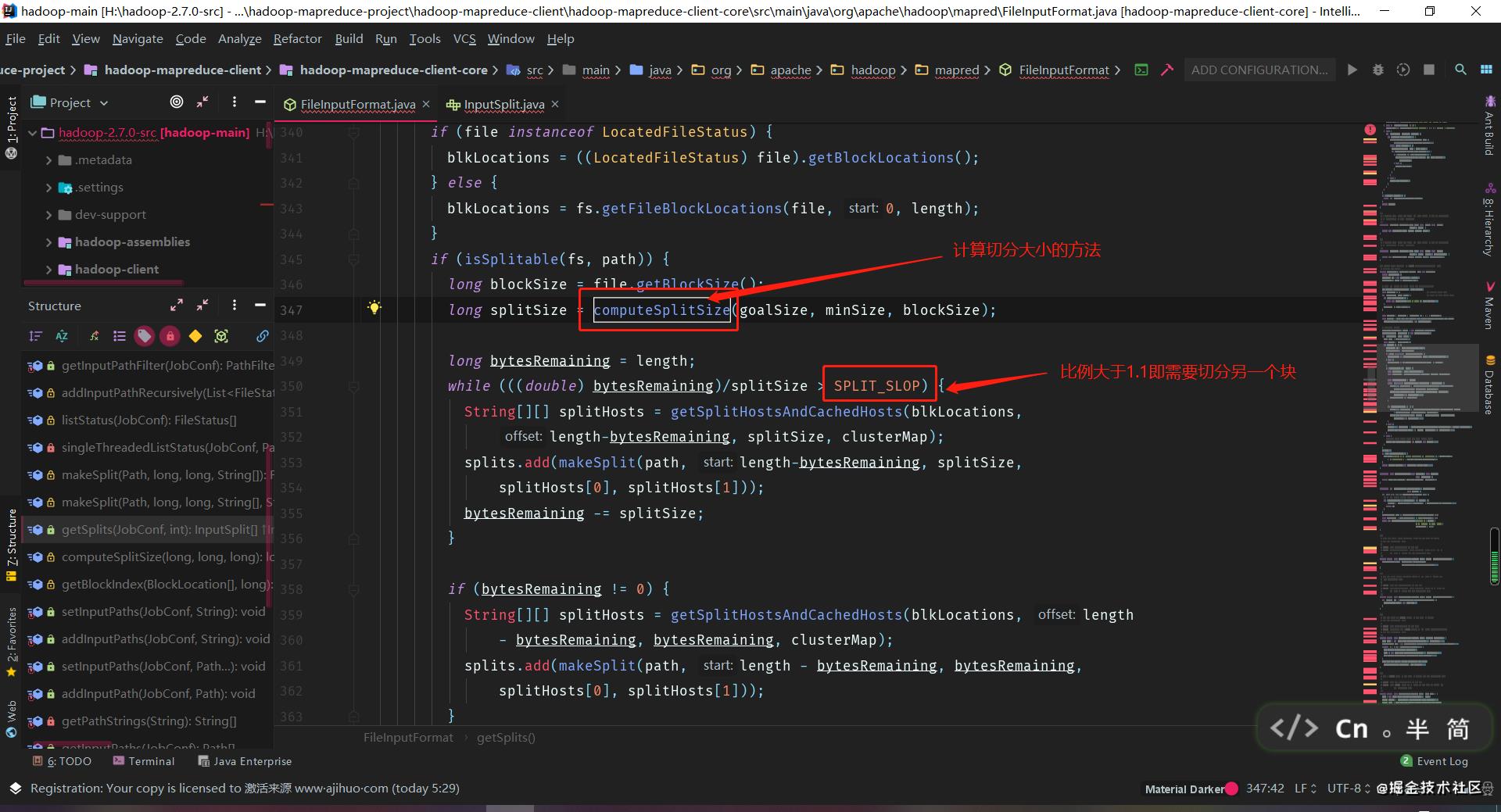
当然这个参数 SPLIT_SLOP 我们是可以点进来看一下的 
如果我们通过调整参数的方式让文件不可拆分,那么不管文件多大都只启动一个 Task 执行,或者你把 isSplitable 的这个判断分支直接搞成 false ,也可以达到这个效果。
这部分源码写的比较清晰明了,所以感兴趣的小伙伴们自行下载源码查看即可,之后还有一个源码版本中 computeSplitSize 方法为这三个参数 splitsize minsize maxsize,minsize 默认值是1,maxsize 默认是 Long 的最大值。我个人感觉这三个参数比2.7.0的源码中的那个 goalsize 好说明一点,goalsize 其实就是一个用户期待大小的值和 blocksize 作对比,其实道理都是一样的。
综上我们可以得出,修改逻辑切片的两个途径就是 computeSplitSize 方法和 isplitable 方法逻辑
第一: 改 isplitable 基本上不太可能改这个
第二: 改 goalSize, minSize, blockSize
而且注意,blocksize 需要修改的话,是要格式化 HDFS 的。还有 splitsize 一般也是不能变的,如果要变,也得严格按照 blocksize * n 的数字去改,不然你可以想想,任务到不同数据块取数据的情况,比如我整出了一个 splitsize = 150 ,我一个 Task 处理 128M 的数据,那我第一个 Task 就会取第一个文件块,和第二个文件块的 22M,第二个任务就会取第二个数据块的 128M,和第三个数据块的 22M ,这样明显是非常不合理的
我们可以看到这3个参数的定义
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
long blockSize = file.getBlockSize();
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, defaultValue:1), minSplitSize);
minsize 的默认值是1 ,goalsize 就是待处理文件块的大小/在job启动时org.apache.hadoop.mapred.JobConf.setNumMapTasks(int n)设置的值,不设置的话,默认就是1,所以一般 goalsize 其实就是待处理文件块的大小,很多人会说,那这个 setNumMapTasks 不就已经是设置多少个 MapTask 的意思吗?其实不是的,它并不是真正的取决条件。现在我们先继续往下说。
再然后 blocksize 就是块的大小。我们可以发现,如果用户想要使用自己期待的值作为 splitsize,但是 computeSplitSize 方法是会取三个参数的中位数作为结果的,所以就算我们设置了比 blocksize 大的 goalsize,取出来的结果也会是 blocksize 的值,这样会保证,我们分割文件的值 splitsize,最大也不会取超过块的大小 blockSize。
如果 goalsize 太小,也可以通过增大 minsize 的值来让 minsize 成为中位数。这样取出来的 splitsize 会变大,那自然 mapper 数就会减少了。
上文中已经提到过了,computeSplitSize 方法就是求这3个参数的中位数,不信你可以点进去查看

先取 goalSize, blockSize 中的小的,再和最后一个 minsize 取大的,这样就得出中位数了。
如果是 maxsize, minSize, blockSize 的版本,最合适的方法就是把 blockSize 修改成为 maxsize, minSize, blockSize 的中位数就好了。比如如果你想调整为 256M,那就把 minsize 设置 256M 即可,如果你想设置 64M,那就把 maxsize 调整为 64M 即可。是不是很简单。
如果文件不可切分,那就只有是数据是压缩的情况,这个是数据源的问题,比如如果数据经过了 lzo 压缩后,需要单独创建索引才能切片。
2.2 ReduceTask 并行度决定机制
ReduceTask 的并行度其实超级简单
job.setNumReduceTasks(4);
好的,直接搞定。当然它还能设置为0,那就直接不运行这个阶段的任务了
但是这个参数其实设置的没有这么随意,因为这个其实关系着 shuffle 阶段数据会分成几个部分,还有尽量不要运行太多的 reduceTask。对大多数 job 来说,最好 reduceTask 的个数最多和集群中的从节点个数持平。这个对于小集群而言,尤其重要。
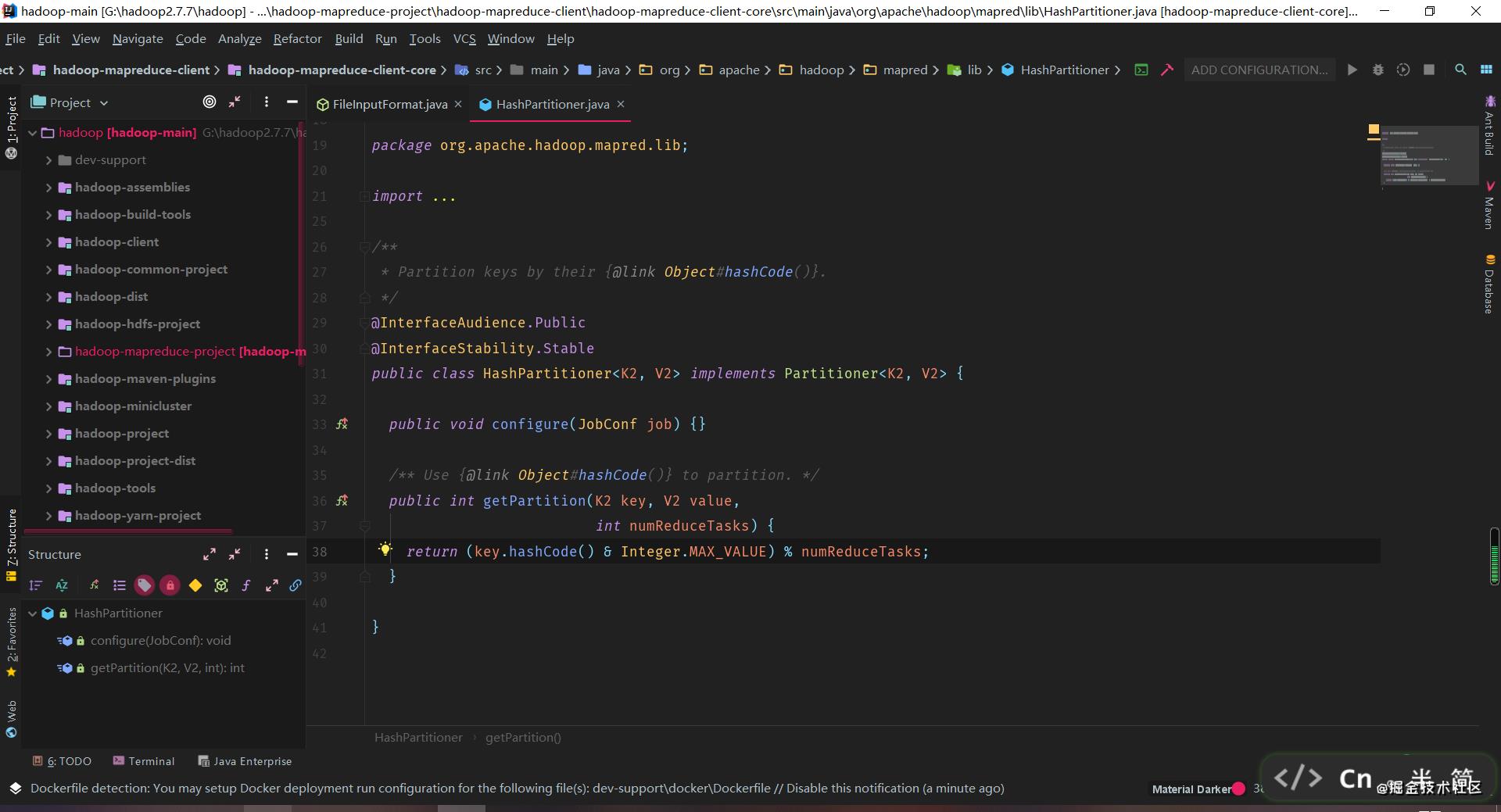
记住,在默认分区器,也就是 HashPartitioner 规则下,我们可以用上面的代码随意指定 ReduceTask 的数量,如果是自定义的分区器,那就一定要逻辑相匹配。
序列化和排序
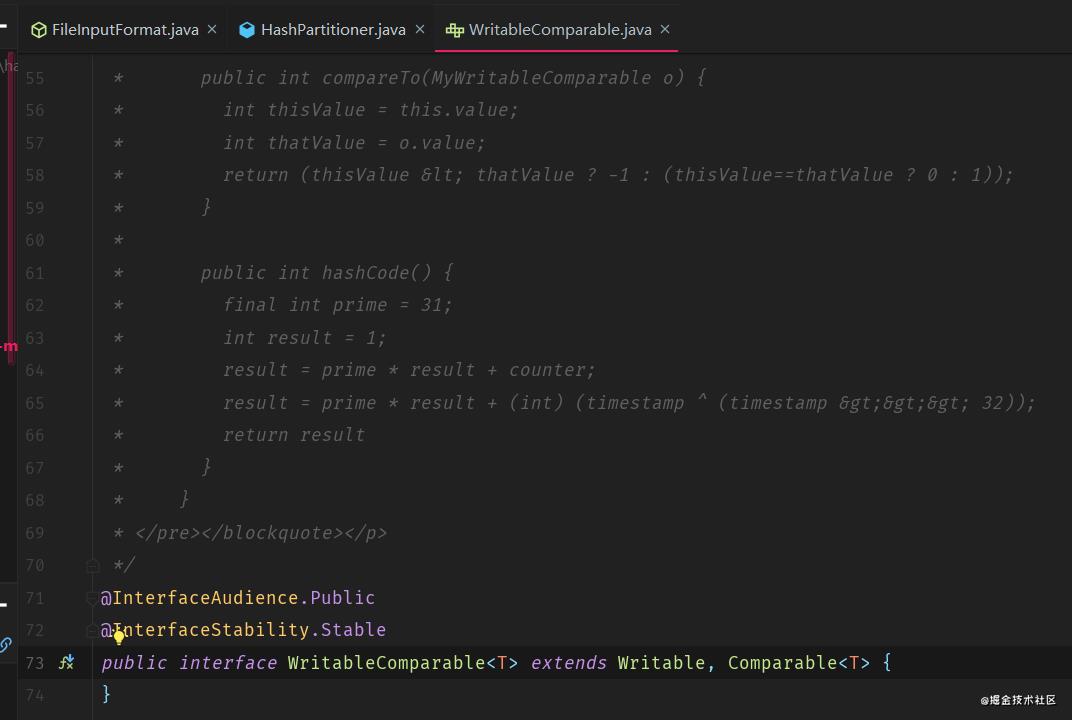
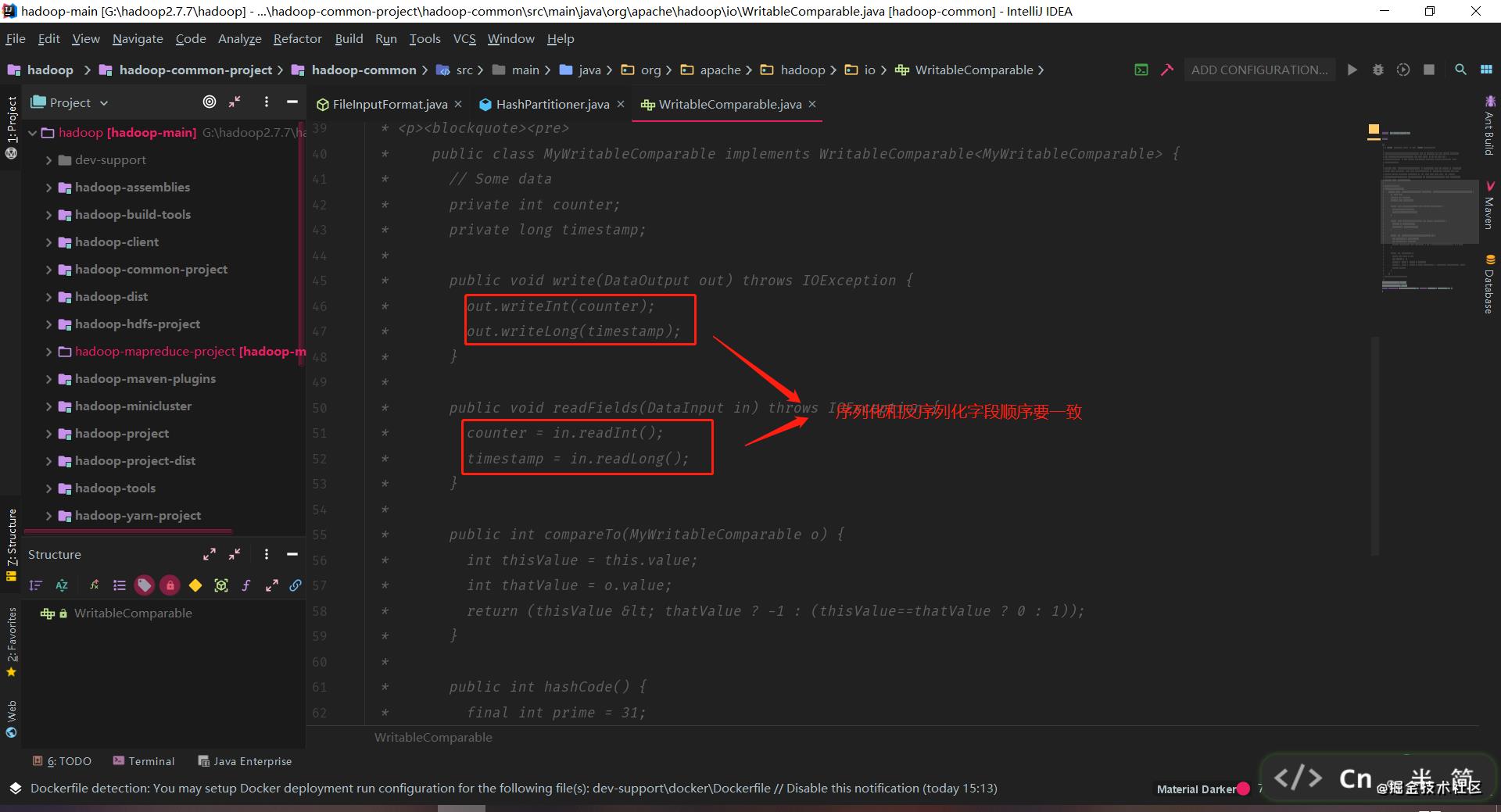
Writable 是序列化和反序列化的接口,而 Comparable 是排序接口,因为 shuffle 阶段是必定会需要进行排序的。所以直接它们连逗号都省略了,搞了一个 WritableComparable 接口
而且源码中自带了 demo,需要了解的直接看源码即可
Finally
碍于篇幅不宜太长所以先这么多,之后会继续更新相关内容。
最后
以下是Java面试1—到5年以上开发必问到的面试问点,也都是一线互联网公司Java面试必备技能,下面是参照阿里年薪50W所需具备的技能图,大家可以参考下!

同时针对这12个技能,我在这整理了一份Java架构进阶面试专题PDF文档(含450题解析,包括Dubbo、Redis、Netty、zookeeper、Spring cloud、分布式、高并发,设计模式,MySQL等知识点解析,内容丰富,图文结合!)
这份专题文档是免费分享的,有需要的朋友可以看向下面来获取!!
需要完整版文档的小伙伴,可以一键三连,下方获取免费领取方式!

以上是关于从零开始 MapReduce的主要内容,如果未能解决你的问题,请参考以下文章