推理引擎Paddle Inference改造三要点,ERNIE时延降低81.3%
Posted OSC开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推理引擎Paddle Inference改造三要点,ERNIE时延降低81.3%相关的知识,希望对你有一定的参考价值。
随着深度学习技术的成熟和人工智能的发展,机器开始变得越来越“聪明”,越来越了解用户的喜好和习惯。
智能音箱
语音助手
这一切的背后都离不开自然语言处理(Natural Language Processing,简称NLP)技术。
近年来对于NLP的研究也在日新月异的变化,有趣的任务和算法更是层出不穷,百度提出知识增强的语义表示模型 ERNIE就是其中的佼佼者。ERNIE在语言推断、语义相似度、命名实体识别、情感分析、问答匹配等各类NLP中文任务上的模型效果全面超越 Bert,成为NLP中文任务中的主流模型,ERNIE 2.0的论文(https://arxiv.org/abs/1907.12412)也被国际人工智能顶级学术会议AAAI-2020收录。
然而在模型效果大幅度提升的同时,模型的计算复杂性也大大增加,这使得ERNIE在推理部署时出现延时高,推理速度不理想的情况,给产业实践带来了极大的挑战。
飞桨开源框架1.8版本中,Paddle Inference在算子融合、TensorRT子图集成和半精度浮点数(Float 16)加速三个方面对ERNIE模型推理进行了全方位优化。
实验表明,在batch=32, layers=12, head_num=12, size_per_head=64的配置下,英伟达T4 ERNIE运行延时从224ms降至41.90ms,时延降低81.3%;在其他配置不变,batch=1的情况下,时延缩减到 2.72ms。进一步在Bert模型上的扩展实验表明,同样条件下,1.8版本相对Tensortflow也具备明显的推理性能优势。
新来的小伙伴可能会疑惑,啥是Paddle Inference?
Paddle Inference是飞桨深度学习框架的推理引擎,通过对不同平台服务器应用场景的深度适配优化,降低时延,提升部署效率,详情请参考:https://mp.weixin.qq.com/s/DX2pM2H2Nq9MCg2eU4sV7g

ERNIE时延降低81.3%,
Paddle Inference如何做到?

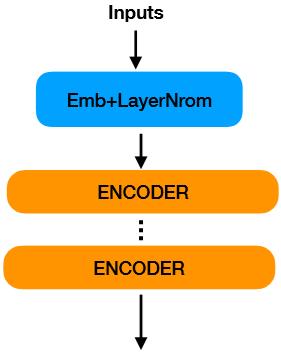
-
模型输入:获取三个输入对应的Embedding,对它们相加并进行了正则化。 -
多个重复的编码结构:每个编码器由self-attention 以及feed-forward操作组成(标准的Ernie模型有12个编码结构)。
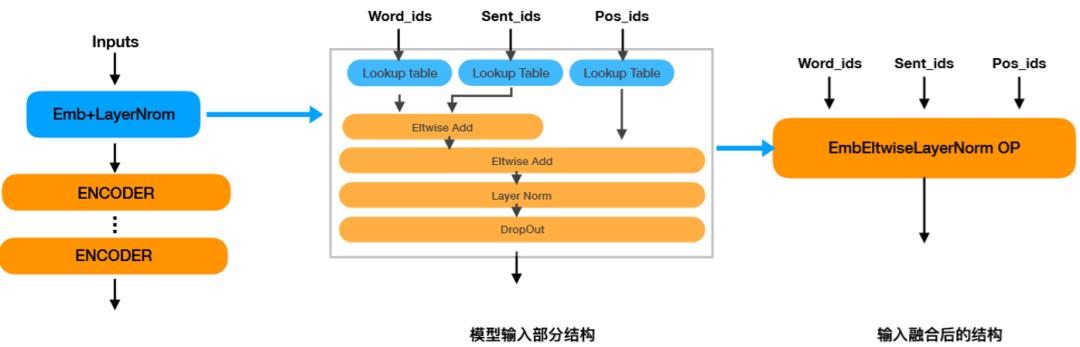
-
模型输入部分结构:ERNIE模型输入部分由7个算子组成。 -
输入融合后的结构:Paddle Inference在图分析阶段对模型输入部分进行算子融合后,输入部分的7个算子融合成了1个EmbEltwiseLayerNorm 算子。
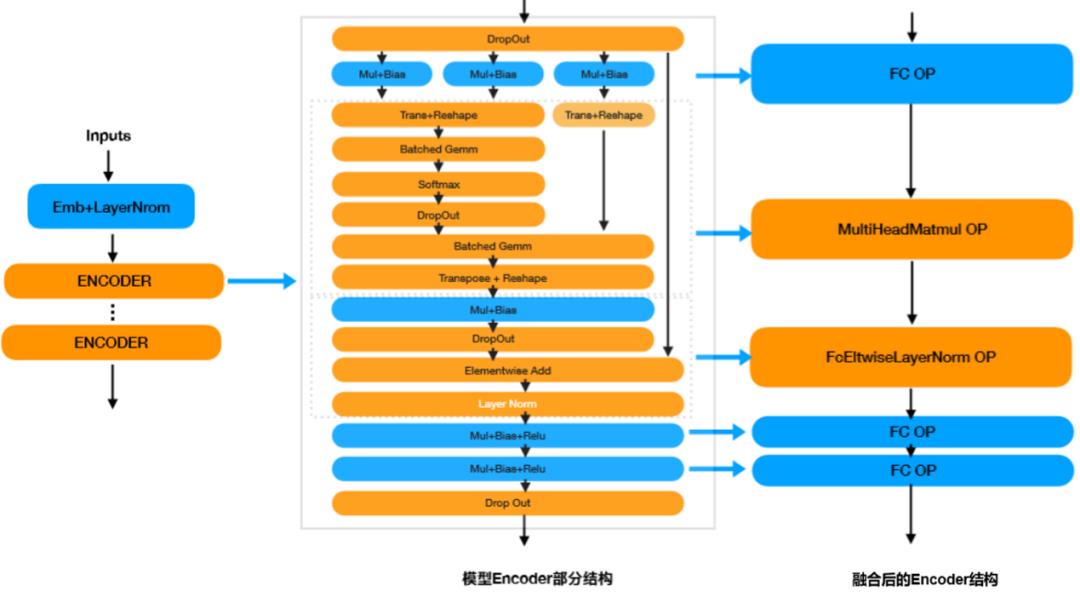
-
模型Encoder部分结构:Ernie的每个模型编码(Encoder)部分由29个算子组成,标准的Ernie总共包含12个编码,由300+个算子组成。 -
融合后的Encoder结构:Paddle Inference将编码部分融合成了由FC、MultiHeadMatmul、FcEltwiseLayerNorm等算子组成的结构。
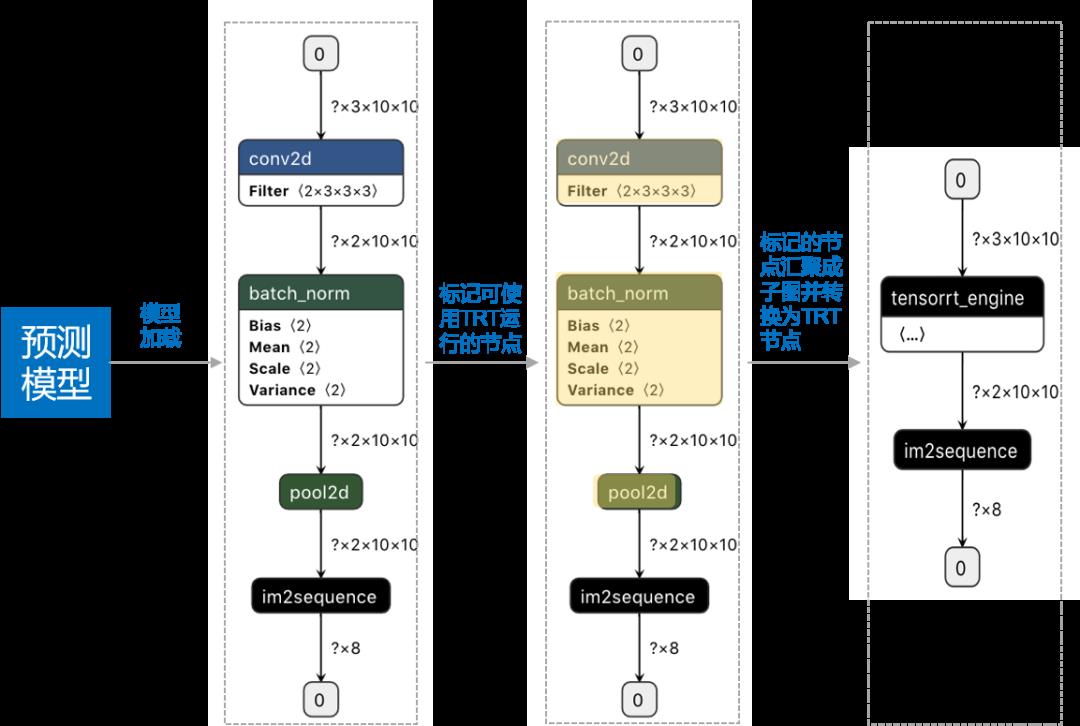
实践出真知,
让我们动手试试看
# 拉取镜像,该镜像预装Paddle 1.8 Python环境,并包含c++的预编译库,lib存放在默认用户目录 ~/ 下。
docker pull hub.baidubce.com/paddlepaddle/paddle:1.8.0-gpu-cuda10.0-cudnn7-trt6
export CUDA_SO=
"$(ls /usr/lib64/libcuda* | xargs -I{} echo '-v {}:{}') $(ls /usr/lib64/libnvidia* | xargs -I{} echo '-v {}:{}')"
export DEVICES=$(ls /dev/nvidia* | xargs -I{}
echo
'--device {}:{}')
export NVIDIA_SMI=
"-v /usr/bin/nvidia-smi:/usr/bin/nvidia-smi"
docker run
$CUDA_SO
$DEVICES
$NVIDIA_SMI --name test_ernie --privileged --security-opt seccomp=unconfined --net=host -v
$PWD:/paddle -it hub.baidubce.com/paddlepaddle/paddle:1.8.0-gpu-cuda10.0-cudnn7-trt6 /bin/bash
# 下载Ernie预测模型
wget https://paddle-inference-dist.bj.bcebos.com/inference_demo/Ernie_inference_model.gz
def create_predictor():
# 配置模型路径
config = AnalysisConfig(
'./ernie/model', ./ernie/params)
config.switch_use_feed_fetch_ops(False)
# 设置开启内存/显存复用
config.enable_memory_optim()
# 设置开启GPU
config.enable_use_gpu(
100,
0)
# 设置使用TensorRT子图,关于TensorRT子图的更多信息请访问:
# https://paddle-inference.readthedocs.io/en/latest/optimize/paddle_trt.html
config.enable_tensorrt_engine(workspace_size =
1<<
30,
max_batch_size=
1, min_subgraph_size=
5,
precision_mode=AnalysisConfig.Precision.Half,
# 开启FP16
use_static=False, use_calib_mode=False)
head_number =
12
names = [
"placeholder_0",
"placeholder_1",
"placeholder_2",
"stack_0.tmp_0"]
min_input_shape = [
1,
1,
1]
max_input_shape = [
100,
128,
1]
opt_input_shape = [
1,
128,
1]
# 设置TensorRT动态shape运行模式,需要提供输入的最小,最大,最优shape
# 最优 shape处于最小最大shape之间,在预测初始化期间,会根据最优shape对OP选择最优的kernel
config.set_trt_dynamic_shape_info(
{names[
0]
:min_input_shape, names[
1]
:min_input_shape, names[
2]
:min_input_shape, names[
3] : [
1, head_number,
1,
1]},
{names[
0]
:max_input_shape, names[
1]
:max_input_shape, names[
2]
:max_input_shape, names[
3] : [
100, head_number,
128,
128]},
{names[
0]
:opt_input_shape, names[
1]
:opt_input_shape, names[
2]
:opt_input_shape, names[
3] : [args.batch, head_number,
128,
128]});
# 创建predictor
predictor = create_paddle_predictor(config)
return predictor
# 运行预测,其中data表示输入的数据
def run(predictor, data):
# copy data to input tensor
input_names = predictor.get_input_names()
# 将data数据设置到输入tensor中
for i, name in enumerate(input_names):
input_tensor = predictor.get_input_tensor(name)
input_tensor.reshape(data[i].shape)
input_tensor.copy_from_cpu(data[i].copy())
# 运行预测
predictor.zero_copy_run()
results = []
# 获取输出数据
output_names = predictor.get_output_names()
for i, name in enumerate(output_names):
output_tensor = predictor.get_output_tensor(name)
output_data = output_tensor.copy_to_cpu()
results.append(output_data)
return results
pred = create_predictor()
# 使用数值为1的数据进行测试
in1 = np.ones((1, 128, 1)).astype(np.int64)
in2 = np.ones((1, 128, 1)).astype(np.int64)
in3 = np.ones((1, 128, 1)).astype(np.int64)
in4 = np.ones((1, 128, 1)).astype(np.float32)
results = run(pred, [in1, in2, in3, in4])
以上是关于推理引擎Paddle Inference改造三要点,ERNIE时延降低81.3%的主要内容,如果未能解决你的问题,请参考以下文章
Paddle Inference震撼升级!全方位适配高性能推理,打通AI应用的最后一公里
百度推出端侧推理引擎 Paddle Lite,支持华为 NPU 在线编译
更强大易用的端侧推理引擎来啦!Paddle Lite 2.0正式发布
百度飞桨重磅推出端侧推理引擎Paddle Lite 支持更多硬件平台