用NBA球员数据学透聚类算法,附源码
Posted 小一的学习笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用NBA球员数据学透聚类算法,附源码相关的知识,希望对你有一定的参考价值。
大家好,我是小一
老读者应该都知道,小一前面写过一个专栏,从原理到实战详细介绍了数据挖掘中的一些算法,感兴趣的读者可以点击:
其中有一个算法在日常工作中比较常用,它就是:聚类算法,例如:样本点的均值聚类、经纬度的密度聚类等等,简单且实用。
今天这篇文章,主要是通过k-means实现对NBA球员的聚类,比较有趣,推荐大家阅读和练手
以下是正文:
正文
今天我们主要用 NBA 球员赛季表现聚类来探讨下 K-Means 算法
K-Means 是一个清晰明白的无监督学习方法,和 KNN 有很多相似点,例如都有超参数 K,前者是 K 个类别,后者是 K 个邻居。
聚类算法是不需要标签的,直接从数据的内在性之中学习最优的分类结果,或者说确定离散标签类型。K-Means 聚类算法是其中最简单、最容易理解的。
简单即高效。我们的目标是学习一个东西,然后把它的思想应用到我们想要探索的场景,以加深对算法的理解。
最优的聚类结果需要满足两个假设:
“簇中心点”(cluster center)是属于该簇的所有的数据点坐标的算术平均值
一个簇的每个点到该簇中心点的距离,比到其他簇中心点的距离短
于是 K-Means 聚类的工作流为
随机猜测一些簇中心点
将样本分配至离其最近的簇中心点上去
将簇中心点设置为所有点坐标的平均值
重复 2 和 3 直至收敛
我们会编码实现 K-Means 算法,并用于 NBA 控卫 2020-21 常规赛季的表现分析中。
找到数据
我们可以从https://www.basketball-reference.com找到我们想要的数据,那就是NBA球员在过去一个赛季的统计数据。
数据获取流程如下
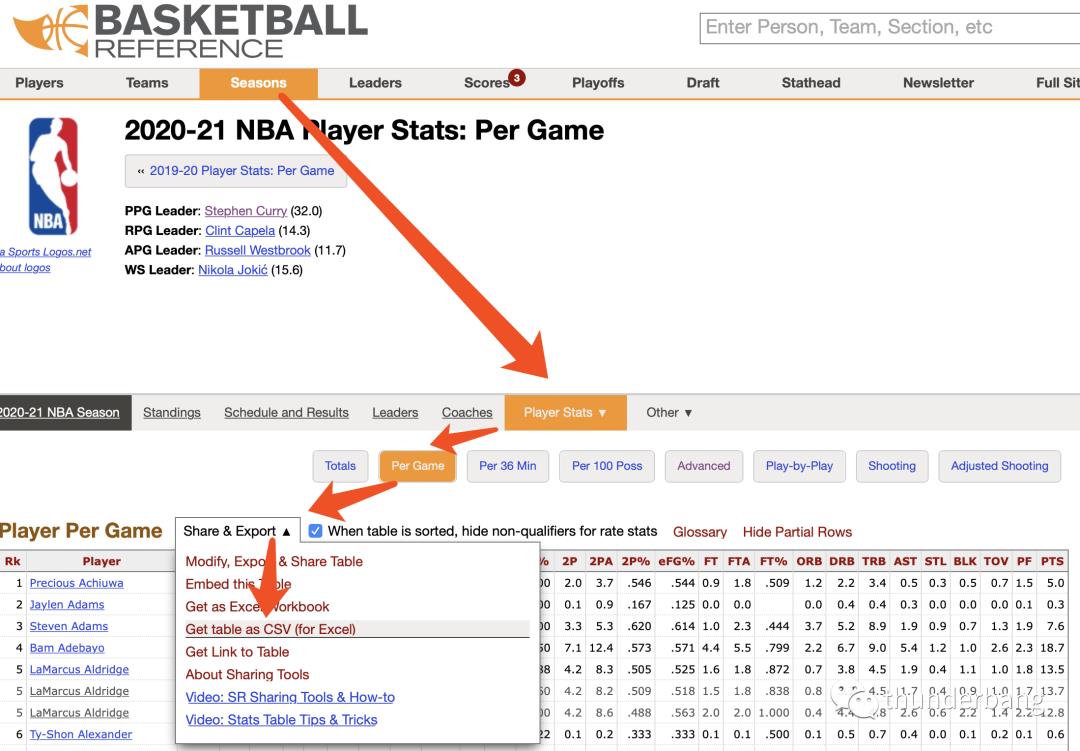
看看数据
# 三剑客来一遍
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
nba = pd.read_csv("nba_2020.csv")
nba.head()
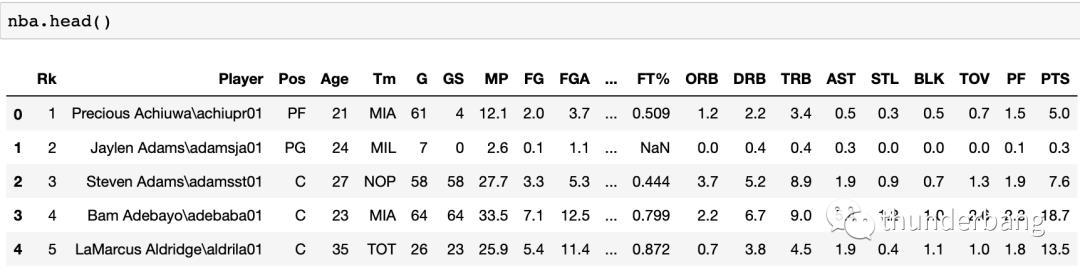
我们发现姓名列有个\,后面跟着不知道是什么的简称,可以处理掉。另外字段名全是简写,我一个球迷有很多都看不懂。
整理了下字段含义,我们看一遍,这样就大概了解了这个数据集有什么了。
Age:年龄(别告诉我你知不知道)
TM(team):球队
Lg(league):联盟
Pos(position):位置
PG(Point Guard):组织后卫
GS(Games Started):首发出场次数
MP(Minutes Played Per Game):场均上场时间
FG(Field Goals Per Game):场均命中数
FGA(Field Goal Attempts Per Game):场均投篮数
FG%(Field Goal Percentage):命中率
3P(3-Point Field Goals Per Game):三分球命中率
3PA (3-Point Field Goal Attempts Per Game):场均三分球投篮数
3P% (3-Point Field Goal Percentage):三分球命中率
2P (2-Point Field Goals Per Game):两分球命中数
2PA (2-Point Field Goal Attempts Per Game):场均两分投篮数
2P% (2-Point Field Goal Percentage):两分球命中率
eFG% (Effective Field Goal Percentage):有效命中率
FT (Free Throws Per Game):场均罚球命中数
FTA (Free Throw Attempts Per Game):场均罚球数
FT% (Free Throw Percentage):罚球命中率
ORB (Offensive Rebounds Per Game):场均进攻篮板数
DRB (Defensive Rebounds Per Game):场均防守篮板数
TRB (Total Rebounds Per Game):总篮板数
AST (Assists Per Game):场均助攻
STL (Steals Per Game):场均抢断
BLK (Blocks Per Game):场均盖帽
TOV (Turnovers Per Game):场均失误
PF (Personal Fouls Per Game):场均个人犯规
PTS (Points Per Game):场均得分
处理数据
# 球员名字取\前面的字符
nba['Player'] = nba['Player'].apply(lambda x: x.split('\\')[0])
# 取控卫PG的样本进行分析
point_guards = nba[nba['Pos'] == 'PG']
# 剔除0失误的控卫数据,0tov意味着场次太少,且0不能被除
point_guards = point_guards[point_guards['TOV'] != 0]
# 定义ATR为助攻失误比,并计算出来
point_guards['ATR'] = point_guards['AST'] / point_guards['TOV']
处理后的数据变成了下面的样子,我们剩下了 124 个控卫数据。
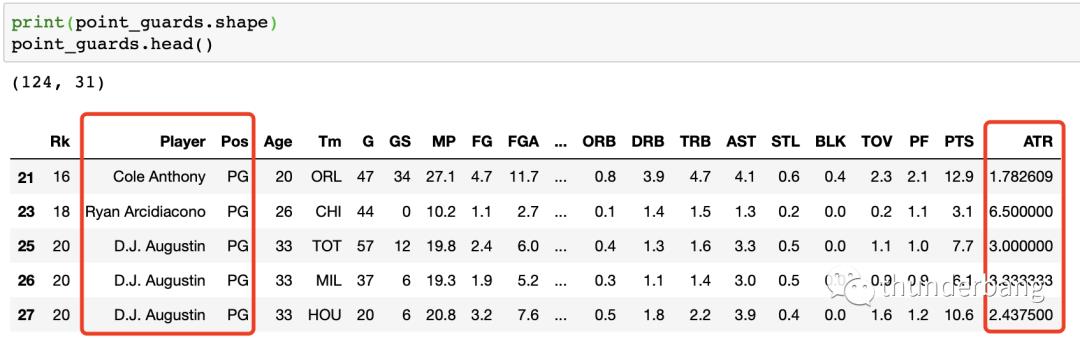
判断一个控卫优不优秀,最重要的两个指标是场均得分和场均助攻失误比,也就是PTS和ATR。下面我们就用这两个关键特征对球员聚类。
探索数据
看下这些球员的场次得分与助攻失误比散点图,这往往是数据分析和建模的第一步。
# 改善下绘图风格
import seaborn as sns
sns.set()
# nba联盟控卫场次得分与助攻失误比散点图
plt.scatter(point_guards['PTS'], point_guards['ATR'], c='y')
plt.title("Point Guards")
plt.xlabel('Points Per Game', fontsize=13)
plt.ylabel('Assist Turnover Ratio', fontsize=13)
plt.show()
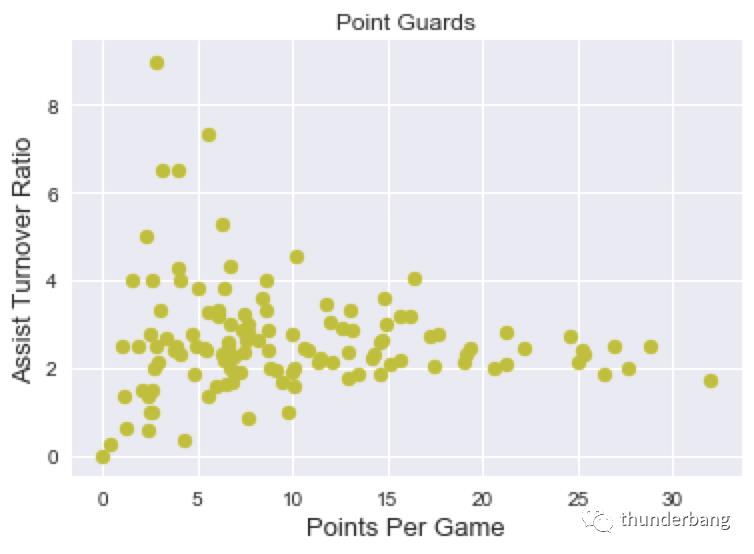
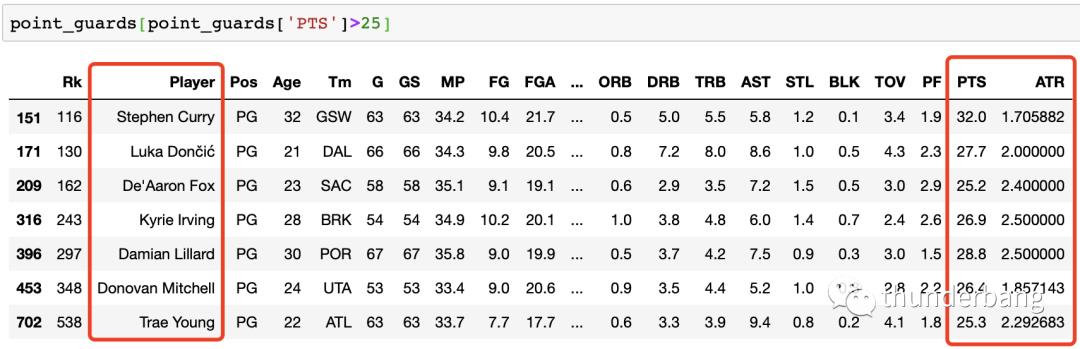
最右边得分超过 30 的你不用猜,就是这个男人。

确认下数据,场均得分大于 25 的过滤出来看下,果然是库里,东契奇、欧文、利拉德等人赫然在列。这些超巨得分是高,但看起来助攻失误比差不多都在平均线上下。这是合理的。
其实有点干的越多错的越多的意思,工作上亦是如此。
看了下助攻失误比超高或超低的,我都不认识就不说了。
我们聚类吧
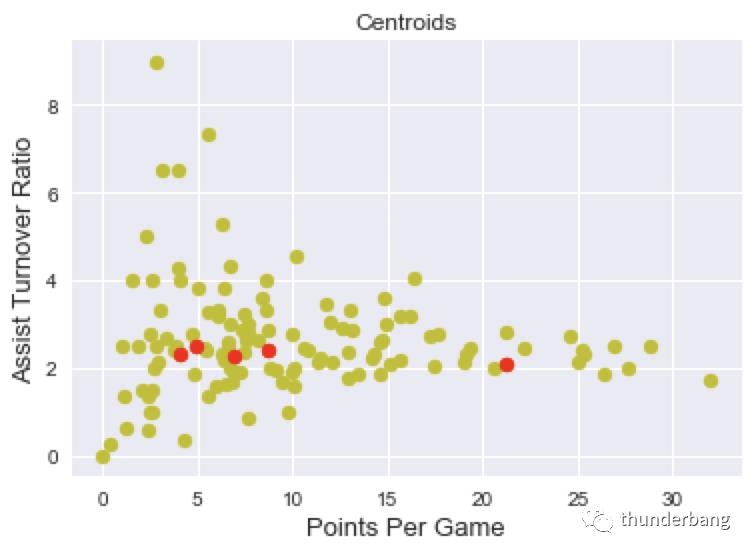
从散点图来看,其实并没有明显的簇,但我们可以人为定义任意个簇。我们还是分成 5 类。于是我们开始做聚类的第一步。
STEP1:随机认定 5 个样本点作为簇的中心点
num_clusters = 5
# 从样本里随机选5个出来作为5个簇的起始中心点
random_initial_points = np.random.choice(point_guards.index, size=num_clusters)
centroids = point_guards.loc[random_initial_points]
# 画出散点图,包括5个随机选取的聚类中心点
plt.scatter(point_guards['PTS'], point_guards['ATR'], c='y')
plt.scatter(centroids['PTS'], centroids['ATR'], c='red')
plt.title("Centroids")
plt.xlabel('Points Per Game', fontsize=13)
plt.ylabel('Assist Turnover Ratio', fontsize=13)
plt.show()
随后就是不断迭代优化簇中心点的过程,为了方便,我们将中心点的坐标存在一个字典里。
def centroids_to_dict(centroids):
dictionary = dict()
# iterating counter we use to generate a cluster_id
counter = 0
# iterate a pandas data frame row-wise using .iterrows()
for index, row in centroids.iterrows():
coordinates = [row['PTS'], row['ATR']]
dictionary[counter] = coordinates
counter += 1
return dictionary
centroids_dict = centroids_to_dict(centroids)
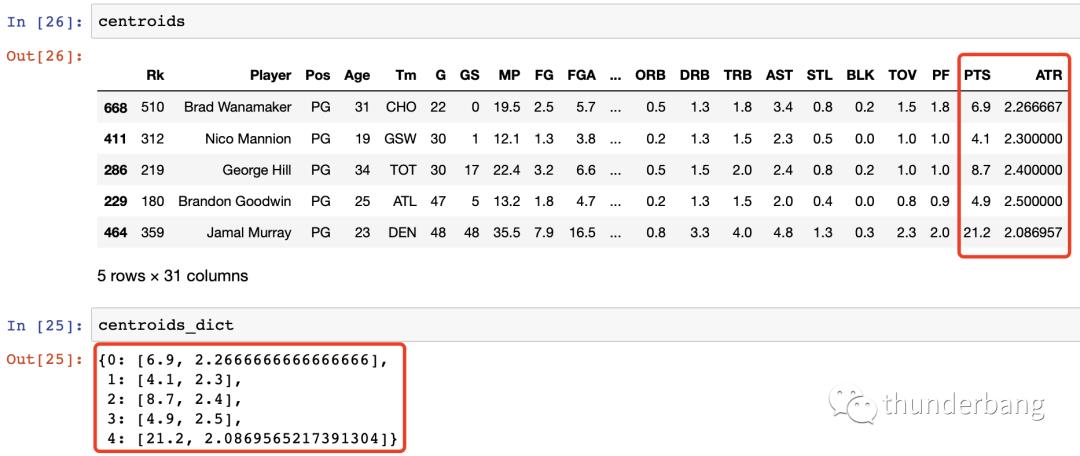
上图我们看到,随机选出来的centroids,我们把它存在了一个centroids_dict里面。
STEP2:将样本分配至离其最近的簇中心点上去
这里涉及两个计算,一个是距离的度量,一个是最小元素的查找。前者我们采用欧拉距离,后者是选择排序的精髓。
先定义好这两个计算函数,如下。
import math
def calculate_distance(centroid, player_values):
root_distance = 0
for x in range(0, len(centroid)):
difference = centroid[x] - player_values[x]
squared_difference = difference**2
root_distance += squared_difference
euclid_distance = math.sqrt(root_distance)
return euclid_distance
def assign_to_cluster(row):
lowest_distance = -1
closest_cluster = -1
for cluster_id, centroid in centroids_dict.items():
df_row = [row['PTS'], row['ATR']]
euclidean_distance = calculate_distance(centroid, df_row)
if lowest_distance == -1:
lowest_distance = euclidean_distance
closest_cluster = cluster_id
elif euclidean_distance < lowest_distance:
lowest_distance = euclidean_distance
closest_cluster = cluster_id
return closest_cluster
执行这两个函数,我们就完成了 STEP2,我们可视化看下完成后的结果。
point_guards['cluster'] = point_guards.apply(lambda row: assign_to_cluster(row), axis=1)
def visualize_clusters(df, num_clusters):
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k']
for n in range(num_clusters):
clustered_df = df[df['cluster'] == n]
plt.scatter(clustered_df['PTS'], clustered_df['ATR'], c=colors[n-1])
plt.xlabel('Points Per Game', fontsize=13)
plt.ylabel('Assist Turnover Ratio', fontsize=13)
plt.show()
visualize_clusters(point_guards, 5)
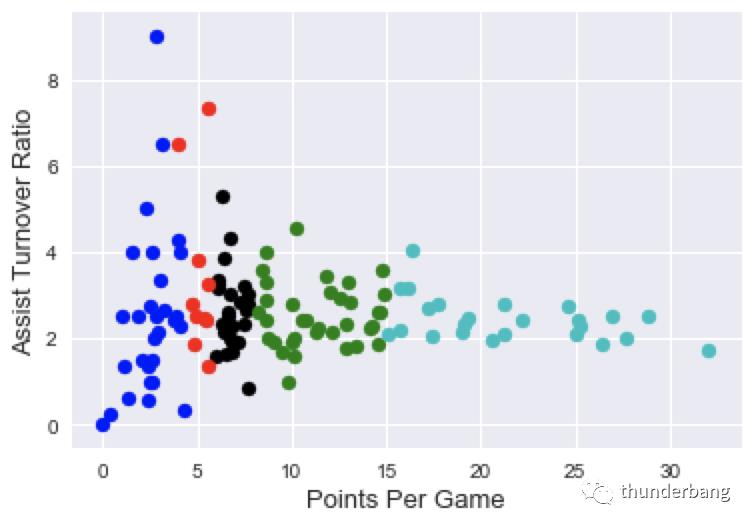
以上,5 个类别分别以不同的颜色标识出来了,但显然这是随机簇的结果,划分的 5 类结果并没有太好。我们还需要 STEP3。
STEP3:将簇中心点设置为所有点坐标的平均值
def recalculate_centroids(df):
new_centroids_dict = dict()
for cluster_id in range(0, num_clusters):
values_in_cluster = df[df['cluster'] == cluster_id]
# Calculate new centroid using mean of values in the cluster
new_centroid = [np.average(values_in_cluster['PTS']), np.average(values_in_cluster['ATR'])]
new_centroids_dict[cluster_id] = new_centroid
return new_centroids_dict
STEP4:重复 2 和 3
# 多次迭代,试试100轮吧
for _ in range(0,100):
centroids_dict = recalculate_centroids(point_guards)
point_guards['cluster'] = point_guards.apply(lambda row: assign_to_cluster(row), axis=1)
visualize_clusters(point_guards, num_clusters)
最终的结果如上,我们看到效果已经得到了很好的优化。高得分的在一个簇,高助攻失误比的在一个簇。
以上,我们写了很多代码。手写算法是为了学习和理解。工程上,我们要充分利用工具和资源。
sklearn 库就包含了我们常用的机器学习算法实现,可以直接用来建模。
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=num_clusters)
kmeans.fit(point_guards[['PTS', 'ATR']])
point_guards['cluster'] = kmeans.labels_
visualize_clusters(point_guards, num_clusters)
短短五行代码就完成了我们从零开始写的百来行代码,效果看起来也很合理。值得说明的是,聚类受起始点的影响,可能不会达到全局最优结果。
以上就是今天的主要内容,感兴趣的读者可以自己试着练下手
往期文章
坚持向暮光所走的人,终将成为耀眼的存在!
期待你的 三连!我们下节见
以上是关于用NBA球员数据学透聚类算法,附源码的主要内容,如果未能解决你的问题,请参考以下文章
Spring Boot整合ElasticSearch和Mysql 附案例源码
机器学习算法精讲20篇-k-means聚类算法应用案例(附示例代码)
基于ssm的NBA球队管理系统[含论文+答辩PPT+任务书+中期检查表+源码等]